This paper introduces the generalized exponential-$ U $ family of distributions as a novel methodological approach to enhance the distributional flexibility of existing classical and modified distributions. The new family is derived by combining the T-$ X $ family method with the exponential model. The paper presents the generalized exponential-Weibull model, an updated version of the Weibull model. Estimators and heavy-tailed characteristics of the proposed method are derived. The new model is applied to three healthcare data sets, including COVID-19 patient survival times and mortality rate data set from Mexico and Holland. The proposed model outperforms other models in terms of analyzing healthcare data sets by evaluating the best model selection measures. The findings suggest that the proposed model holds promise for broader utilization in the area of predicting and modeling healthcare phenomena.
Citation: Mustafa Kamal, Meshayil M. Alsolmi, Nayabuddin, Aned Al Mutairi, Eslam Hussam, Manahil SidAhmed Mustafa, Said G. Nassr. A new distributional approach: estimation, Monte Carlo simulation and applications to the biomedical data sets[J]. Networks and Heterogeneous Media, 2023, 18(4): 1575-1599. doi: 10.3934/nhm.2023069
This paper introduces the generalized exponential-$ U $ family of distributions as a novel methodological approach to enhance the distributional flexibility of existing classical and modified distributions. The new family is derived by combining the T-$ X $ family method with the exponential model. The paper presents the generalized exponential-Weibull model, an updated version of the Weibull model. Estimators and heavy-tailed characteristics of the proposed method are derived. The new model is applied to three healthcare data sets, including COVID-19 patient survival times and mortality rate data set from Mexico and Holland. The proposed model outperforms other models in terms of analyzing healthcare data sets by evaluating the best model selection measures. The findings suggest that the proposed model holds promise for broader utilization in the area of predicting and modeling healthcare phenomena.

| [1] |
B. M. Batubara, The problems of the world of education in the middle of the Covid-19 pandemic, BIRCI-J. Hum. Soc. Sci., 4 (2021), 450–457. https://doi.org/10.33258/birci.v4i1.1626 doi: 10.33258/birci.v4i1.1626

|
| [2] |
D. V. Parums, Long COVID, or post-COVID syndrome, and the global impact on health care. Med. Sci. Monitor., 27 (2021), e933446-1–e933446-2. https://doi.org/10.12659/MSM.933446 doi: 10.12659/MSM.933446
|
| [3] |
M. K. Hassan, M. R. Rabbani, Y. Abdulla, Socioeconomic impact of COVID-19 in MENA region and the role of islamic finance, Int. J. Islamic. Econ. Financ., 4 (2021), 51–78. https://doi.org/10.18196/ijief.v4i1.10466 doi: 10.18196/ijief.v4i1.10466
|
| [4] |
A. K. Patel, S. Mukherjee, M. Leifels, R. Gautam, H. Kaushik, S. Sharma, O. Kumar, Mega festivals like MahaKumbh, a largest mass congregation, facilitated the transmission of SARS-CoV-2 to humans and endangered animals via contaminated water, Int. J. Hyg. Envir. Heal., 237 (2021), 113836. https://doi.org/10.1016/j.ijheh.2021.113836 doi: 10.1016/j.ijheh.2021.113836
|
| [5] |
M. Škare, D. R. Soriano, M. Porada-Rochoń, Impact of COVID-19 on the travel and tourism industry, Technol. Forecast. Soc., 163 (2021), 120469. https://doi.org/10.1016/j.techfore.2020.120469 doi: 10.1016/j.techfore.2020.120469
|
| [6] |
S. Zondi, K. Ombongi, COVID-19, politics and international relations: hopes and impediments, Politikon-UK., 48 (2021), 157–158. https://doi.org/10.1080/02589346.2021.1913800 doi: 10.1080/02589346.2021.1913800
|
| [7] |
S. M. Sayyd, Z. A. Zainuddin, P. M. Seraj, A scientific overview of the impact of COVID-19 pandemic on sports affairs: a systematic review, Phys. Educ. stud., 25 (2021), 221–229. https://doi.org/10.15561/20755279.2021.0403 doi: 10.15561/20755279.2021.0403
|
| [8] |
C. Strong, F. Cannizzo, Pre-existing conditions: Precarity, creative justice and the impact of the COVID-19 pandemic on the Victorian music industries, Perfect. Beat., 21 (2021), 10–24. https://doi.org/10.1558/prbt.19379 doi: 10.1558/prbt.19379
|
| [9] |
S. Singh, R. Kumar, R. Panchal, M. K. Tiwari, Impact of COVID-19 on logistics systems and disruptions in food supply chain, Int. J. Prod. Res., 59 (2021), 1993–2008. https://doi.org/10.1080/00207543.2020.1792000 doi: 10.1080/00207543.2020.1792000
|
| [10] |
C. Elleby, I. P. Domínguez, M. Adenauer, G. Genovese, Impacts of the COVID-19 pandemic on the global agricultural markets, Environ. Resour. Econ., 76 (2020), 1067–1079. https://doi.org/10.1007/s10640-020-00473-6 doi: 10.1007/s10640-020-00473-6
|
| [11] |
M. Zuo, S. K. Khosa, Z. Ahmad, Z. Almaspoor, Comparison of COVID-19 pandemic dynamics in Asian countries with statistical modeling, Comput. Math. Method. M., 2020 (2020), 4296806. https://doi.org/10.1155/2020/4296806 doi: 10.1155/2020/4296806
|
| [12] |
W. Bo, Z. Ahmad, A. R. A. Alanzi, A. I. Al-Omari, E. H. Hafez, S. F. Abdelwahab, The current COVID-19 pandemic in China: an overview and corona data analysis, Alex. Eng. J., 61 (2022), 1369–1381. https://doi.org/10.1016/j.aej.2021.06.025 doi: 10.1016/j.aej.2021.06.025
|
| [13] |
M. Campolieti, A. Ramos, The distribution of COVID-19 mortality, Infect. Dis. Model., 7 (2022), 856–873. https://doi.org/10.1016/j.idm.2022.11.003 doi: 10.1016/j.idm.2022.11.003
|
| [14] |
Á. Briz-Redón, Á. Serrano-Aroca, The effect of climate on the spread of the COVID-19 pandemic: a review of findings, and statistical and modelling techniques, Prog. Phys. Geog., 44 (2020), 591–604. https://doi.org/10.1177/0309133320946302 doi: 10.1177/0309133320946302
|
| [15] |
I. Franch-Pardo, B. M. Napoletano, F. Rosete-Verges, L. Billa, Spatial analysis and GIS in the study of COVID-19. A review, Sci. Total. Environ., 739 (2020), 140033. https://doi.org/10.1016/j.scitotenv.2020.140033 doi: 10.1016/j.scitotenv.2020.140033
|
| [16] |
O. J. Peter, S. Qureshi, A. Yusuf, M. Al-Shomrani, A. A. Idowu, A new mathematical model of COVID-19 using real data from Pakistan, Results. Phys., 24 (2021), 104098. https://doi.org/10.1016/j.rinp.2021.104098 doi: 10.1016/j.rinp.2021.104098
|
| [17] |
A. I. Abioye, O. J. Peter, H. A. Ogunseye, F. A. Oguntolu, K. Oshinubi, A. A. Ibrahim, I. Khan, Mathematical model of COVID-19 in Nigeria with optimal control, Results. Phys., 28 (2021), 104598. https://doi.org/10.1016/j.rinp.2021.104598 doi: 10.1016/j.rinp.2021.104598
|
| [18] |
S. T. M. Thabet, M. S. Abdo, K. Shah, T. Abdeljawad, Study of transmission dynamics of COVID-19 mathematical model under ABC fractional order derivative, Results. Phys., 19 (2020), 103507. https://doi.org/10.1016/j.rinp.2020.103507 doi: 10.1016/j.rinp.2020.103507
|
| [19] |
U. I. Nwosu, C. P. Obite, Modeling Ivory Coast COVID-19 cases: identification of a high-performance model for utilization, Results. Phys., 20 (2021), 103763. https://doi.org/10.1016/j.rinp.2020.103763 doi: 10.1016/j.rinp.2020.103763
|
| [20] |
I. Rahimi, F. Chen, A. H. Gandomi, A review on COVID-19 forecasting models, Neural. Comput. Appl., (2021). https://doi.org/10.1007/s00521-020-05626-8 doi: 10.1007/s00521-020-05626-8
|
| [21] |
M. Fatima, K. J. O'Keefe, W. Wei, S. Arshad, O. Gruebner, Geospatial analysis of COVID-19: a scoping review, Int. J. Env. Res. Pub. He., 18 (2021), 2336. https://doi.org/10.3390/ijerph18052336 doi: 10.3390/ijerph18052336
|
| [22] | R. Kulik, P. Soulier, Heavy-tailed time series, Springer Series in Operations Research and Financial Engineering, New York: Springer-Verlag, 2020. https://doi.org/10.1007/978-1-0716-0737-4 |
| [23] |
M. A. Kouritzin, S. Paul, On almost sure limit theorems for heavy-tailed products of long-range dependent linear processes, Stoch. Proc. Appl., 152 (2022), 208–232. https://doi.org/10.1016/j.spa.2022.06.021 doi: 10.1016/j.spa.2022.06.021
|
| [24] |
W. Zhao, S. K. Khosa, Z. Ahmad, M. Aslam, A. Z. Afify, Type-I heavy tailed family with applications in medicine, engineering and insurance, PLoS. One., 15 (2020), e0237462. https://doi.org/10.1371/journal.pone.0237462 doi: 10.1371/journal.pone.0237462
|
| [25] |
D. Bhati, S. Ravi, On generalized log-Moyal distribution: a new heavy tailed size distribution, Insur. Math. Econ., 79 (2018), 247–259. https://doi.org/10.1016/j.insmatheco.2018.02.002 doi: 10.1016/j.insmatheco.2018.02.002
|
| [26] |
Z. Li, J. Beirlant, S. Meng, Generalizing the log-Moyal distribution and regression models for heavy-tailed loss data, ASTIN. Bull., 51 (2021), 57–99. https://doi.org/10.1017/asb.2020.35 doi: 10.1017/asb.2020.35
|
| [27] |
A. Alzaatreh, C. Lee, F. Famoye, A new method for generating families of continuous distributions, Metron., 71 (2013), 63–79. https://doi.org/10.1007/s40300-013-0007-y doi: 10.1007/s40300-013-0007-y
|
| [28] |
Z. Ahmad, G. G. Hamedani, N. S. Butt, Recent developments in distribution theory: a brief survey and some new generalized classes of distributions, Pak. J. Stat. Oper. Res., 15 (2019), 87–110. https://doi.org/10.18187/pjsor.v15i1.2803 doi: 10.18187/pjsor.v15i1.2803
|
| [29] |
H. A. Jessen, T. Mikosch, Regularly varying functions, Publ. I. Math., 80 (2006), 171–192. https://doi.org/10.2298/PIM0694171H doi: 10.2298/PIM0694171H
|
| [30] |
E. Seneta, Karamata's characterization theorem, feller and regular variation in probability theory, Publ, I. Math., 71 (2002), 79–89. https://doi.org/10.2298/PIM0271079S doi: 10.2298/PIM0271079S
|
| [31] |
S. I. Resnick, Heavy tail modeling and teletraffic data: special invited paper, Ann. Stat., 25 (1997), 1805–1869. https://doi.org/10.1214/aos/1069362376 doi: 10.1214/aos/1069362376
|
| [32] |
M. V. Aarset, How to identify a bathtub hazard rate, IEEE. T. Reliab., 36 (1987), 106–108. https://doi.org/10.1109/TR.1987.5222310 doi: 10.1109/TR.1987.5222310
|
| [33] |
X. Liu, Z. Ahmad, A. M. Gemeay, A. T. Abdulrahman, E. H. Hafez, N. Khalil, Modeling the survival times of the COVID-19 patients with a new statistical model: a case study from China. PLoS. One., 16 (2021), e0254999. https://doi.org/10.1371/journal.pone.0254999 doi: 10.1371/journal.pone.0254999
|
| [34] |
H. M. Almongy, E. M. Almetwally, H. M. Aljohani, A. S. Alghamdi, E. H. Hafez, A new extended rayleigh distribution with applications of COVID-19 data, Results. Phys., 23 (2021), 104012. https://doi.org/10.1016/j.rinp.2021.104012 doi: 10.1016/j.rinp.2021.104012
|
| [35] |
G. M. Cordeiro, E. M. Ortega, S. Nadarajah, The Kumaraswamy Weibull distribution with application to failure data, J. Franklin. I., 347 (2010), 1399–1429. https://doi.org/10.1016/j.jfranklin.2010.06.010 doi: 10.1016/j.jfranklin.2010.06.010
|
| [36] |
A. S. Alghamdi, M. M. Abd El-Raouf, A new alpha power Cosine-Weibull model with applications to hydrological and engineering data, Mathematics-Basel., 11 (2023), 673. https://doi.org/10.3390/math11030673 doi: 10.3390/math11030673
|
| [37] |
A. S. Hassan, S. G. Nassr, Power Lindly-G family of distribution, Ann. Data. Sci., 6 (2019), 189–210. https://doi.org/10.1007/s40745-018-0159-y doi: 10.1007/s40745-018-0159-y
|
| [38] | A. S. Hassan, S. G. Nassr, The Inverse Weibull generator of distributions: properties and applications, J. Data. Sci., 16 (2018), 723–742. |
| [39] | A. S. Hassan, S. G. Nassr, A new generalization of power function distribution: properties and estimation based on censored samples, Thail. Statiet., 18 (2020), 215–234. |
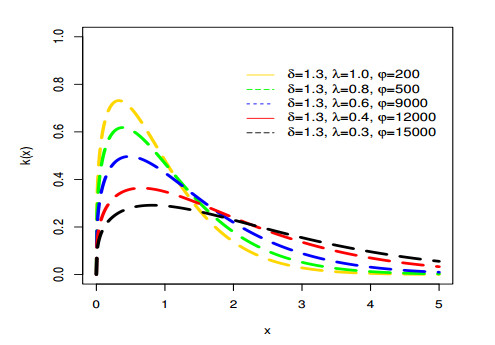
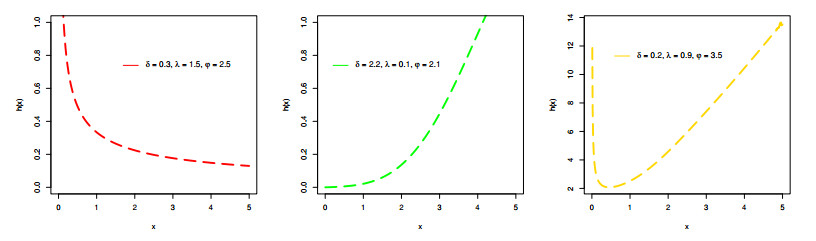
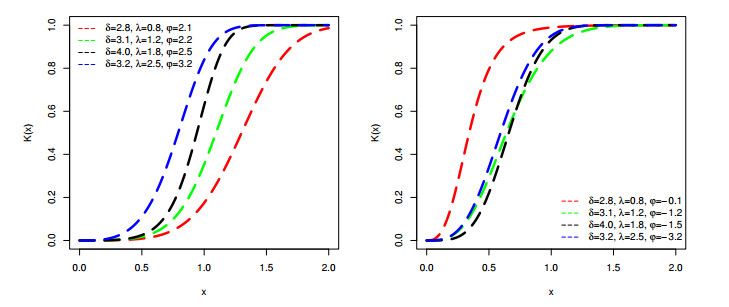
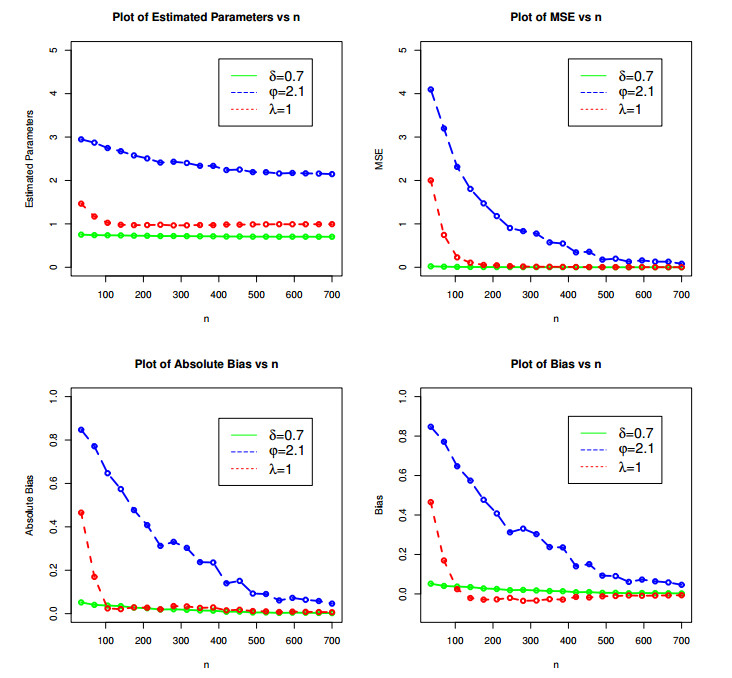
Figures(9) / Tables(6)
Mustafa Kamal, Meshayil M. Alsolmi, Nayabuddin, Aned Al Mutairi, Eslam Hussam, Manahil SidAhmed Mustafa, Said G. Nassr. A new distributional approach: estimation, Monte Carlo simulation and applications to the biomedical data sets[J]. Networks and Heterogeneous Media, 2023, 18(4): 1575-1599. doi: 10.3934/nhm.2023069







 DownLoad:
DownLoad: