Citation: Jing Liu, Wancheng Qiu, Xiaoying Shen, Guangchun Sun. Bioinformatics analysis revealed hub genes and pathways involved in sorafenib resistance in hepatocellular carcinoma[J]. Mathematical Biosciences and Engineering, 2019, 16(6): 6319-6334. doi: 10.3934/mbe.2019315

| [1] | L. A. Torre, F. Bray, R. L. Siegel, et al., Global cancer statistics, 2012, CA. Cancer J. Clin., 65(2015), 87–108. |
| [2] | R. Romagnoli, V. Mazzaferro and J. Bruix, Surgical resection for hepatocellular carcinoma: Moving from what can be done to what is worth doing, Hepatology, 62 (2015), 340–342. |
| [3] | N. F. Esnaola, G. Y. Lauwers, N. Q. Mirza, et al., Predictors of microvascular invasion in patients with hepatocellular carcinoma who are candidates for orthotopic liver transplantation, J. Gastrointest. Surg., 6 (2002), 224–232; discussion 232. |
| [4] | S. D'Angelo, M. Secondulfo, R. De Cristofano, et al., Selection and management of hepatocellular carcinoma patients with sorafenib: recommendations and opinions from an Italian liver unit, Future Oncol., 9 (2013), 485–491. |
| [5] | L. Adnane, P. A. Trail, I. Taylor, et al., Sorafenib (BAY 43-9006, Nexavar), a dual-action inhibitor that targets RAF/MEK/ERK pathway in tumor cells and tyrosine kinases VEGFR/PDGFR in tumor vasculature, Meth. Enzymol., 407 (2006), 597–612. |
| [6] | S. Wilhelm, C. Carter, M. Lynch, et al., Discovery and development of sorafenib: a multikinase inhibitor for treating cancer, Nat. Rev. Drug. Discov., 5 (2006), 835–844. |
| [7] | S. M. Wilhelm, C. Carter, L. Tang, et al., BAY 43-9006 exhibits broad spectrum oral antitumor activity and targets the RAF/MEK/ERK pathway and receptor tyrosine kinases involved in tumor progression and angiogenesis, Cancer Res., 64 (2004), 7099–7109. |
| [8] | O. Waidmann and J. Trojan, Novel drugs in clinical development for hepatocellular carcinoma, Expert Opin. Investig. Drug., 24 (2015), 1075–1082. |
| [9] | M. J. Blivet-Van Eggelpoel, H. Chettouh, L. Fartoux, et al., Epidermal growth factor receptor and HER-3 restrict cell response to sorafenib in hepatocellular carcinoma cells, J. Hepatol., 57 (2012), 108–115. |
| [10] | K. F. Chen, H. L. Chen, W. T. Tai, et al., Activation of phosphatidylinositol 3-kinase/Akt signaling pathway mediates acquired resistance to sorafenib in hepatocellular carcinoma cells, J. Pharmacol. Exp. Ther., 337 (2011), 155–161. |
| [11] | B. Zhai, F. Hu, X. Jiang, et al., Inhibition of Akt reverses the acquired resistance to sorafenib by switching protective autophagy to autophagic cell death in hepatocellular carcinoma, Mol. Cancer Ther., 13 (2014), 1589–1598. |
| [12] | A. K. Chow, L. Ng, C. S. Lam, et al., The Enhanced metastatic potential of hepatocellular carcinoma (HCC) cells with sorafenib resistance, PLoS One, 8 (2013), e78675. |
| [13] | D. Morgenszternand H. L. McLeod, PI3K/Akt/mTOR pathway as a target for cancer therapy, Anticancer Drugs, 16 (2005), 797–803. |
| [14] | A. Parveen, M. S. Akash, K. Rehman, et al., Dual Role of p21 in the Progression of Cancer and Its Treatment, Crit. Rev. Eukaryot. Gene Expr., 26 (2016), 49–62. |
| [15] | J. C. Su, P. H. Tseng, S. H. Wu, et al., SC-2001 overcomes STAT3-mediated sorafenib resistance through RFX-1/SHP-1 activation in hepatocellular carcinoma, Neoplasia, 16 (2014), 595–605. |
| [16] | Z. Xu, Y. Zhou, Y. Cao, et al., Identification of candidate biomarkers and analysis of prognostic values in ovarian cancer by integrated bioinformatics analysis, Med. Oncol., 33 (2016), 130. |
| [17] | Y. Guo, Y. Bao, M. Ma, et al., Identification of key candidate genes and pathways in colorectal cancer by integrated bioinformatical analysis, Int. J. Mol. Sci., 18 (2017). |
| [18] | B. Győrffy, P. Surowiak, J. Budczies, et al., Online survival analysis software to assess the prognostic value of biomarkers using transcriptomic data in non-small-cell lung cancer, PloS One., 8 (2013), e82241. |
| [19] | C. Stottrup, T. Tsang and Y. R. Chin, Upregulation of AKT3 confers resistance to the AKT inhibitor MK2206 in breast cancer, Mol. Cancer Ther., 15 (2016), 1964–1974. |
| [20] | A. Forner, J. M. Llovet and J. Bruix, Hepatocellular carcinoma, Lancet, 379 (2012), 1245–1255. |
| [21] | D. Huang, W. Yuan, H. Li, et al., Identification of key pathways and biomarkers in sorafenib-resistant hepatocellular carcinoma using bioinformatics analysis, Exp. Ther. Med., 16 (2018), 1850–1858. |
| [22] | X. Wang, W. M. Ghareeb, X. Lu, et al., Coexpression network analysis linked H2AFJ to chemoradiation resistance in colorectal cancer, J. Cell. Biochem., (2018). |
| [23] | K. Kohno, M. Chiba, S. Murata, et al., Identification of natural antisense transcripts involved in human colorectal cancer development, Int. J. Oncol., 37 (2010), 1425–1432. |
| [24] | R. Karess, Rod-Zw10-Zwilch: A key player in the spindle checkpoint, Trends Cell Biol., 15 (2005), 386–392. |
| [25] | Y. Yu, Z. Kovacevicand D. R. Richardson, Tuning cell cycle regulation with an iron key, Cell Cycle, 6 (2007), 1982–1994. |
| [26] | A. Fernandez-Vidal, A. Mazarsand S. Manenti, CDC25A: a rebel within the CDC25 phosphatases family?, Anticancer Agents Med. Chem., 8 (2008), 825–831. |
| [27] | M. P. Sacristan, S. Ovejeroand and A. Bueno, Human Cdc14A becomes a cell cycle gene in controlling Cdk1 activity at the G(2)/M transition, Cell Cycle, 10 (2011), 387–391. |
| [28] | M. T. Paulsen, A. M. Starks, F. A. Derheimer, et al., The p53-targeting human phosphatase hCdc14A interacts with the Cdk1/cyclin B complex and is differentially expressed in human cancers, Mol. Cancer, 5 (2006), 25. |
| [29] | F. M. Schmid, K. B. Schou, M. J. Vilhelm, et al., IFT20 modulates ciliary PDGFRalpha signaling by regulating the stability of Cbl E3 ubiquitin ligases, J. Cell. Biol., 217 (2018), 151–161. |
| [30] | H. Dong, H. Guo, L. Xie, et al., The metastasis-associated gene MTA3, a component of the Mi-2/NuRD transcriptional repression complex, predicts prognosis of gastroesophageal junction adenocarcinoma, PLoS One, 8 (2013), e62986. |
| [31] | A. M. Houghton, Mechanistic links between COPD and lung cancer, Nat. Rev. Cancer, 13 (2013), 233–245. |
| [32] | K. Vierlinger, M. H. Mansfeld, O. Koperek, et al., Identification of SERPINA1 as single marker for papillary thyroid carcinoma through microarray meta analysis and quantification of its discriminatory power in independent validation, BMC. Med. Genomics, 4 (2011), 30. |
| [33] | H. J. Chan, H. Li, Z. Liu, et al., SERPINA1 is a direct estrogen receptor target gene and a predictor of survival in breast cancer patients, Oncotarget, 6 (2015), 25815–25827. |
| [34] | C. H. Kwon, H. J. Park, J. H. Choi, et al., Snail and serpinA1 promote tumor progression and predict prognosis in colorectal cancer, Oncotarget, 6 (2015), 20312–20326. |
| [35] | K. Thorsen, F. Mansilla, T. Schepeler, et al., Alternative splicing of SLC39A14 in colorectal cancer is regulated by the Wnt pathway, Mol. Cell. Proteomics, 10 (2011), M110002998. |
| [36] | M. Nilbert and E. Rambech, Beta-catenin activation through mutation is rare in rectal cancer, Cancer Genet. Cytogenet., 128 (2001), 43–45. |
| [37] | S. Yan, C. Zhou, W. Zhang, et al., β-Catenin/TCF pathway upregulates STAT3 expression in human esophageal squamous cell carcinoma, Cancer Lett., 271 (2008), 85–97. |
| [38] | M. Takahashi, T. Tsunoda, M. Seiki, et al., Identification of membrane-type matrix metalloproteinase-1 as a target of the beta-catenin/Tcf4 complex in human colorectal cancers, Oncogene, 21 (2002), 5861–5867. |
| [39] | L. Beneduce, F. Castaldi, M. Marino, et al., Improvement of liver cancer detection with simultaneous assessment of circulating levels of free alpha-fetoprotein (AFP) and AFP-IgM complexes, Int. J. Biol. Markers, 19 (2004), 155–159. |
| [40] | S. X. Li, L. J. Liu, L. W. Dong, et al., CKAP4 inhibited growth and metastasis of hepatocellular carcinoma through regulating EGFR signaling, Tumour Biol., 35 (2014), 7999–8005. |
| [41] | B. J. McMahon, L. Bulkow, A. Harpster, et al., Screening for hepatocellular carcinoma in Alaska natives infected with chronic hepatitis B: a 16-year population-based study, Hepatology, 32 (2000), 842–846. |
| [42] | M. Abu El Makarem, An overview of biomarkers for the diagnosis of hepatocellular carcinoma, Hepat. Mon., 12 (2012), e6122. |
| [43] | W. J. Zheng, M. Yao, M. Fang, et al., Abnormal expression of HMGB-3 is significantly associated with malignant transformation of hepatocytes, World J. Gastroenterol., 24 (2018), 3650–3662. |
| [44] | Z. Jiang, X. Zhai, B. Shi, et al., KIAA1199 overexpression is associated with abnormal expression of EMT markers and is a novel independent prognostic biomarker for hepatocellular carcinoma, Onco. Targets Ther., 11 (2018), 8341–8348. |
| [45] | P. Han, H. Li, X. Jiang, et al., Dual inhibition of Akt and c-Met as a second-line therapy following acquired resistance to sorafenib in hepatocellular carcinoma cells, Mol. Oncol., 11 (2017), 320–334. |
| [46] | C. H. Wu, X. Wu and H. W. Zhang, Inhibition of acquired-resistance hepatocellular carcinoma cell growth by combining sorafenib with phosphoinositide 3-kinase and rat sarcoma inhibitor, J. Surg. Res., 206 (2016), 371–379. |
| [47] | X. Tian, D. Zhou, L. Chen, et al., Polo-like kinase 4 mediates epithelial-mesenchymal transition in neuroblastoma via PI3K/Akt signaling pathway, Cell Death Dis., 9 (2018), 54. |
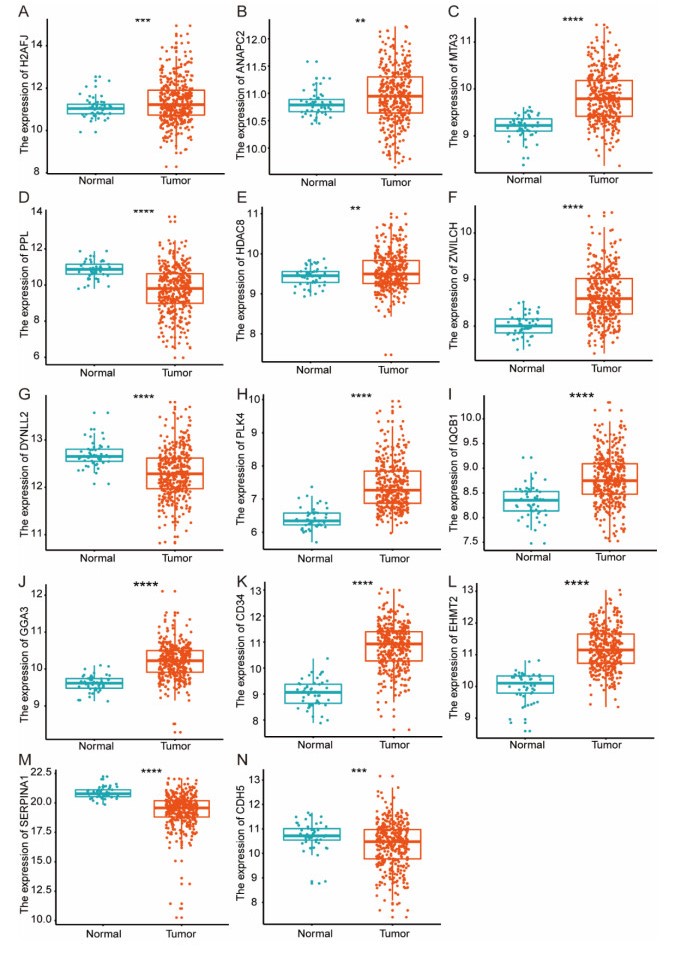

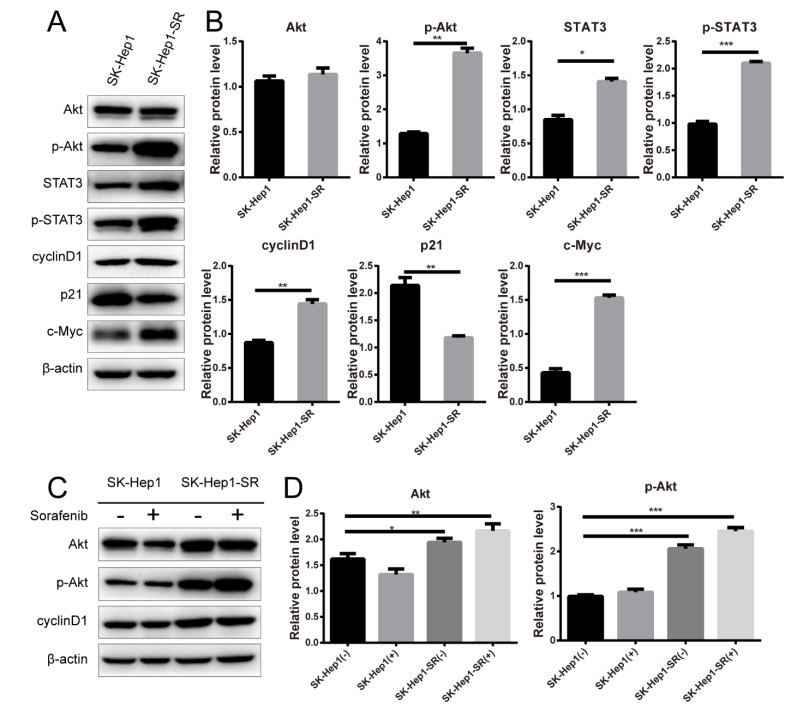
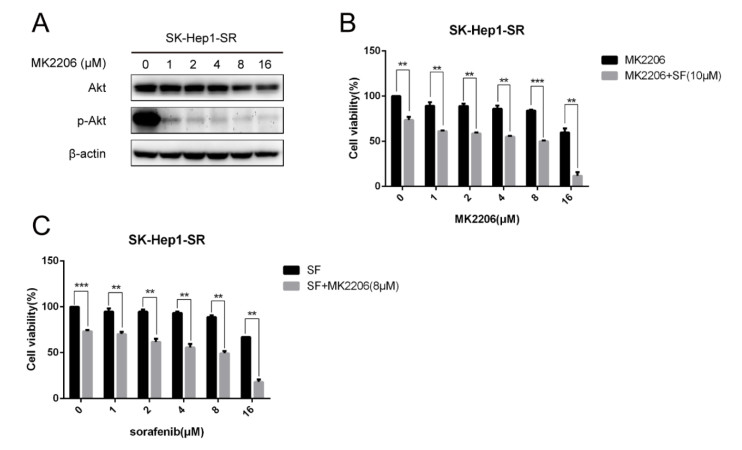
Figures(8)

Jing Liu, Wancheng Qiu, Xiaoying Shen, Guangchun Sun. Bioinformatics analysis revealed hub genes and pathways involved in sorafenib resistance in hepatocellular carcinoma[J]. Mathematical Biosciences and Engineering, 2019, 16(6): 6319-6334. doi: 10.3934/mbe.2019315







 DownLoad:
DownLoad: