Citation: Yan-Xiao Liu , Ching-Nung Yang, Qin-Dong Sun. Enhance embedding capacity for switch map based multi-group EMD data hiding[J]. Mathematical Biosciences and Engineering, 2019, 16(5): 3382-3392. doi: 10.3934/mbe.2019169

| [1] | C. K. Chan and L. M. Cheng, Hiding data in image by simple LSB substitution, Patt. Recogn., 37(2004), 469–474. |
| [2] | R. Z. Wang, C. F. Lin and J. C. Lin, Image hiding by optimal LSB substitution and genetic algo- rithm, Patt. Recogn., 34(2001), 671–683. |
| [3] | S. Dumitrescu, X. Wu and Z. Wang, Detection of LSB steganography via sample pair analysis, IEEE T. Signal Process., 51(2003), 1995–2007. |
| [4] | J. Fridrich, M. Goljan and D. Rui, Detection steganography in color and grayscale images, IEEE Multimedia, 8(2004), 22–28. |
| [5] | A. Westfeld, High capacity despite better steganalysis: F5-a steganographic algorithm, in 4th International Information Hiding Workshop, 2001. |
| [6] | X. L. Li, S. R. Cai, W. M. Zhang, et al., Matrix embedding in finite abelian group, Signal Process., 113(2015), 250–258. |
| [7] | C. Kim, D. Shin, C. N. Yang, et al., Improving capacity of Hamming (n,k)+1 stego-code by using optimized Hamming +k, Digit. Signal Process., 78(2018), 284–293. |
| [8] | W. Zhang, S. Wang and X. Zhang, Improving embedding efficiency of covering codes for applica- tions in steganography, IEEE Commun. Lett., 11(2007), 680–682. |
| [9] | C. Qin, C. C. Chang and Y. P. Chiu, A novel joint data-hiding and compression scheme based on SMVQ and image inpainting, IEEE T. Image Process., 23(2014), 969–978. |
| [10] | X. Zhang and S. Wang, Efficient steganographic embedding by exploiting modification direction, IEEE Commun. Lett., 10(2006), 781–783. |
| [11] | X. Zhang, W. Zhang and S. Wang, Efficient double-layered steganographic embedding, Electron. Lett., 43(2007), 482–483. |
| [12] | X. Zhang, W. Zhang and S. Wang, A double layered "plus-minus one" data embedding scheme, IEEE Signal Proc. Lett., 14(2007), 848–851. |
| [13] | K. H. Jung and K. Y. Yoo, Improved exploiting modification direction method by modulus opera- tion, Int. J. Signal Process. Image Process. Patt., 2(2009), 79–88. |
| [14] | W. C. Kuo and C. C. Wang, Data hiding based on generalized exploiting modification direction method, Imaging Sci. J., 61(2013), 484–490. |
| [15] | W. C. Kuo, C. C. Wang and H. C. Hou, Signed digit data hiding scheme, Inform. Process. Lett., 116(2016), 183–191. |
| [16] | C. C. Wang, W. C. Kuo, Y. C. Huang, et al., A high capacity data hiding scheme based on re- adjusted GEMD, Multimed. Tools Appl., 8(2017), 1–15. |
| [17] | J. Wang, Y. Sun, H. Xu, et al., An improved section-wise exploiting modification direction method, Signal Process., 90(2010), 2954–2964. |
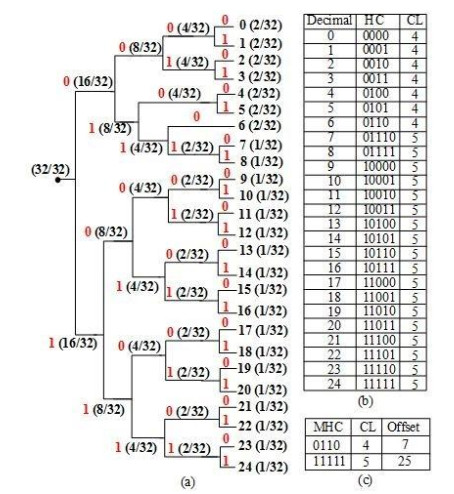
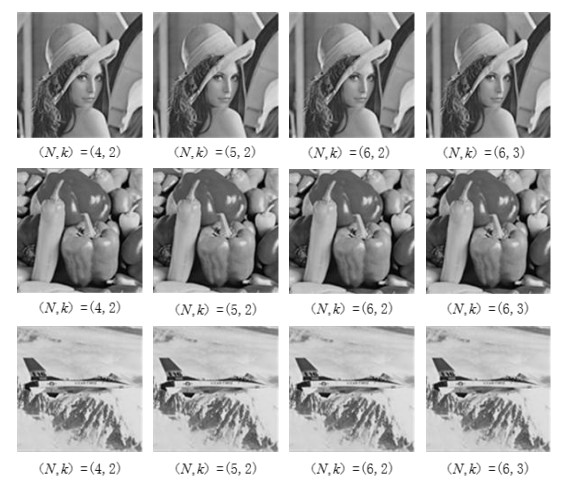
| [18] | X. T. Wang, C. C. Chang, C. C. Lin, et al., A novel multi-group exploiting direction method based on switch map, Signal Process., 92(2012), 1525–1535. |

Figures(3) / Tables(5)

Yan-Xiao Liu , Ching-Nung Yang, Qin-Dong Sun. Enhance embedding capacity for switch map based multi-group EMD data hiding[J]. Mathematical Biosciences and Engineering, 2019, 16(5): 3382-3392. doi: 10.3934/mbe.2019169







 DownLoad:
DownLoad: