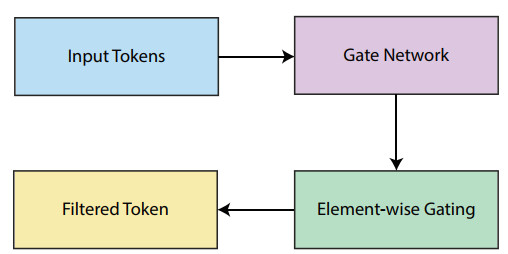
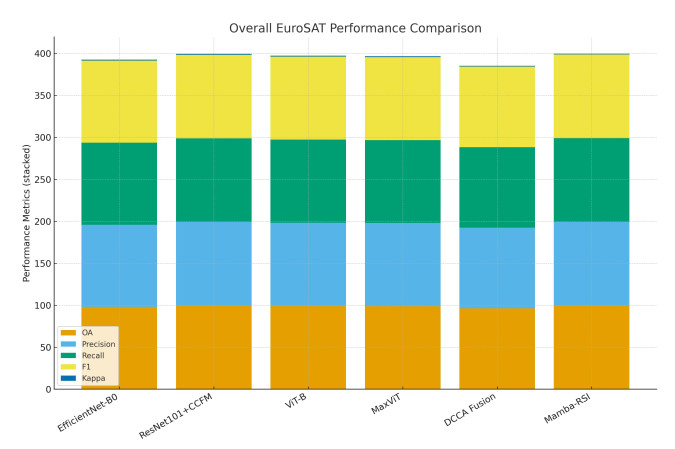
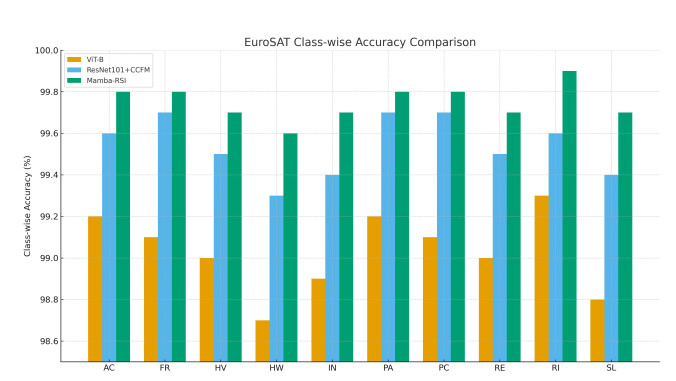
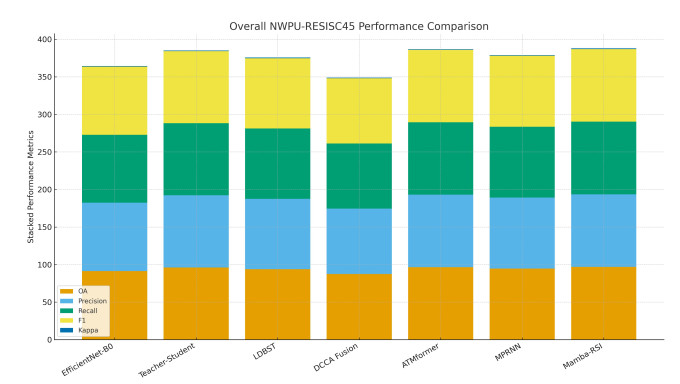
Accurate and efficient land-use and land-cover (LULC) classification from remote sensing imagery remains challenging. This is because it requires capturing long-range spatial dependencies while maintaining computational scalability. Recent transformer-based models improve global context modeling. However, they suffer from quadratic complexity and are limited in applicability to high-resolution imagery. We introduce Mamba-RSI: a linear-time, state-space deep learning framework using selective recursion, hierarchical multi-scale feature extraction, and lightweight global representations. Mamba-RSI captures both fine-grained spectral/texture information and coarse structural patterns with significantly less computational overhead than existing quadratic self-attention transformers. Extensive experimentation on EuroSAT and NWPU-RESISC45 demonstrated that Mamba-RSI achieves state-of-the-art performance. It achieved 99.72% accuracy on EuroSAT and 96.84% on RESISC45. This represents a +0.40% improvement over the strongest transformer baseline, ATMformer, on EuroSAT, a +0.29% improvement on RESISC45, and more than +0.53% over ViT-B on EuroSAT. Robustness tests under severe Gaussian noise ($ \sigma = 0.10 $) showed that Mamba-RSI maintains 97.43% accuracy. MaxViT, by comparison, maintains 94.01% in the same setting. Mamba-RSI also preserves 91.15% accuracy under 30% patch occlusion, outperforming ViT-B by +7.41%. Mamba-RSI provides an attractive blend of accuracy, robustness, and efficiency. It serves as a scalable foundation for new insights into remote sensing analytics and LULC mapping systems.
Citation: Wiem Abdelbaki, Wided Bouchelligua, Inzamam Mashood Nasir, Sara Tehsin, Hend Alshaya. Mamba-RSI: a state-space deep learning framework for efficient land-use and land-cover classification in remote sensing imagery[J]. AIMS Mathematics, 2026, 11(3): 5600-5647. doi: 10.3934/math.2026231
Accurate and efficient land-use and land-cover (LULC) classification from remote sensing imagery remains challenging. This is because it requires capturing long-range spatial dependencies while maintaining computational scalability. Recent transformer-based models improve global context modeling. However, they suffer from quadratic complexity and are limited in applicability to high-resolution imagery. We introduce Mamba-RSI: a linear-time, state-space deep learning framework using selective recursion, hierarchical multi-scale feature extraction, and lightweight global representations. Mamba-RSI captures both fine-grained spectral/texture information and coarse structural patterns with significantly less computational overhead than existing quadratic self-attention transformers. Extensive experimentation on EuroSAT and NWPU-RESISC45 demonstrated that Mamba-RSI achieves state-of-the-art performance. It achieved 99.72% accuracy on EuroSAT and 96.84% on RESISC45. This represents a +0.40% improvement over the strongest transformer baseline, ATMformer, on EuroSAT, a +0.29% improvement on RESISC45, and more than +0.53% over ViT-B on EuroSAT. Robustness tests under severe Gaussian noise ($ \sigma = 0.10 $) showed that Mamba-RSI maintains 97.43% accuracy. MaxViT, by comparison, maintains 94.01% in the same setting. Mamba-RSI also preserves 91.15% accuracy under 30% patch occlusion, outperforming ViT-B by +7.41%. Mamba-RSI provides an attractive blend of accuracy, robustness, and efficiency. It serves as a scalable foundation for new insights into remote sensing analytics and LULC mapping systems.

| [1] |
G. Foody, Status of land cover classification accuracy assessment, Remote Sens. Environ., 80 (2002), 185–201. https://doi.org/10.1016/S0034-4257(01)00295-4 doi: 10.1016/S0034-4257(01)00295-4

|
| [2] |
X. Zhu, D. Tuia, L. Mou, G. Xia, L. Zhang, F. Xu, et al., Deep learning in remote sensing: a comprehensive review and list of resources, IEEE Geosc. Rem. Sen. M., 5 (2017), 8–36. https://doi.org/10.1109/MGRS.2017.2762307 doi: 10.1109/MGRS.2017.2762307
|
| [3] |
J. Peng, Y. Huang, W. Sun, N. Chen, Y. Ning, Q. Du, Domain adaptation in remote sensing image classification: a survey, IEEE J-STARS, 15 (2022), 9842–9859. https://doi.org/10.1109/JSTARS.2022.3220875 doi: 10.1109/JSTARS.2022.3220875
|
| [4] |
G. Cheng, J. Han, X. Lu, Remote sensing image scene classification: benchmark and state of the art, Proce. IEEE, 105 (2017), 1865–1883. https://doi.org/10.1109/JPROC.2017.2675998 doi: 10.1109/JPROC.2017.2675998
|
| [5] | A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, et al., An image is worth 16x16 words: transformers for image recognition at scale, arXiv: 2010.11929. https://doi.org/10.48550/arXiv.2010.11929 |
| [6] |
F. Jannat, A. Willis, Improving classification of remotely sensed images with the swin transformer, Proceedings of SoutheastCon 2022, 2022,611–618. https://doi.org/10.1109/SoutheastCon48659.2022.9764016 doi: 10.1109/SoutheastCon48659.2022.9764016
|
| [7] | Z. Liu, Y. Lin, Y. Cao, H. Hu, Y. Wei, Z. Zhang, et al., Swin transformer: hierarchical vision transformer using shifted windows, Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2021, 10012–10022. |
| [8] | T. Darcet, M. Oquab, J. Mairal, P. Bojanowski, Vision transformers need registers, arXiv: 2309.16588. https://doi.org/10.48550/arXiv.2309.16588 |
| [9] | A. Gu, K. Goel, C. Ré, Efficiently modeling long sequences with structured state-spaces, arXiv: 2111.00396. https://doi.org/10.48550/arXiv.2111.00396 |
| [10] | A. Gu, T. Dao, Mamba: linear-time sequence modeling with selective state-spaces, Proceedings of First Conference on Language Modeling, 2024, 1–32. |
| [11] | A. Gu, I. Johnson, K. Goel, K. Saab, T. Dao, A. Rudra, et al., Combining recurrent, convolutional, and continuous-time models with linear state-space layers, Proceedings of the 35th International Conference on Neural Information Processing Systems, 2021,572–585. |
| [12] | M. Poli, S. Massaroli, E. Nguyen, D. Fu, T. Dao, S. Baccus, et al., Hyena hierarchy: towards larger convolutional language models, Proceedings of the 40th International Conference on Machine Learning, 2023, 28043–28078. |
| [13] |
X. Huang, H. Wang, X. Li, A multi-scale semantic feature fusion method for remote sensing crop classification, Comput. Electron. Agr., 224 (2024), 109185. https://doi.org/10.1016/j.compag.2024.109185 doi: 10.1016/j.compag.2024.109185
|
| [14] |
H. Zhao, J. Shi, X. Qi, X. Wang, J. Jia, Pyramid scene parsing network, Proceedings of IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017, 2881–2890. https://doi.org/10.1109/CVPR.2017.660 doi: 10.1109/CVPR.2017.660
|
| [15] |
W. Wang, W. Chen, Q. Qiu, L. Chen, B. Wu, B. Lin, et al., Crossformer++: a versatile vision transformer hinging on cross-scale attention, IEEE Trans. Pattern Anal., 46 (2024), 3123–3136. https://doi.org/10.1109/TPAMI.2023.3341806 doi: 10.1109/TPAMI.2023.3341806
|
| [16] | J. Yang, C. Li, P. Zhang, X. Dai, B. Xiao, L. Yuan, et al., Focal self-attention for local-global interactions in vision transformers, arXiv: 2107.00641. https://doi.org/10.48550/arXiv.2107.00641 |
| [17] |
A. Aksoy, M. Ravanbakhsh, B. Demir, Multi-label noise robust collaborative learning for remote sensing image classification, IEEE Trans. Neur. Net. Lear., 35 (2024), 6438–6451. https://doi.org/10.1109/TNNLS.2022.3209992 doi: 10.1109/TNNLS.2022.3209992
|
| [18] |
P. Helber, B. Bischke, A. Dengel, D. Borth, Eurosat: a novel dataset and deep learning benchmark for land use and land cover classification, IEEE J-STARS, 12 (2019), 2217–2226. https://doi.org/10.1109/JSTARS.2019.2918242 doi: 10.1109/JSTARS.2019.2918242
|
| [19] |
S. Yousafzai, I. Nasir, S. Tehsin, N. Fitriyani, M. Syafrudin, Fltrans-net: transformer-based feature learning network for wheat head detection, Comput. Electron. Agr., 229 (2025), 109706. https://doi.org/10.1016/j.compag.2024.109706 doi: 10.1016/j.compag.2024.109706
|
| [20] |
D. Malik, T. Shah, S. Tehsin, I. Nasir, N. Fitriyani, M. Syafrudin, Block cipher nonlinear component generation via hybrid pseudo-random binary sequence for image encryption, Mathematics, 12 (2024), 2302. https://doi.org/10.3390/math12152302 doi: 10.3390/math12152302
|
| [21] |
I. Nasir, M. Alrasheedi, N. Alreshidi, Mfan: multi-feature attention network for breast cancer classification, Mathematics, 12 (2024), 3639. https://doi.org/10.3390/math12233639 doi: 10.3390/math12233639
|
| [22] |
Q. Ouyang, Study on high-resolution remote sensing image scene classification using transfer learning, Int. J. Energy, 3 (2023), 85–89. https://doi.org/10.54097/ije.v3i1.10764 doi: 10.54097/ije.v3i1.10764
|
| [23] |
R. Ghosh, X. Jia, L. Yin, C. Lin, Z. Jin, V. Kumar, Clustering augmented self-supervised learning: an application to land cover mapping, Proceedings of the 30th International Conference on Advances in Geographic Information Systems, 2022, 1–10. https://doi.org/10.1145/3557915.3560937 doi: 10.1145/3557915.3560937
|
| [24] | S. Kunwar, J. Ferdush, Mapping of land use and land cover (lulc) using eurosat and transfer learning, arXiv: 2401.02424. https://doi.org/10.48550/arXiv.2401.02424 |
| [25] |
J. Yao, B. Zhang, C. Li, D. Hong, J. Chanussot, Extended vision transformer (exvit) for land use and land cover classification: a multimodal deep learning framework, IEEE Trans. Geosci. Remote, 61 (2023), 5514415. https://doi.org/10.1109/TGRS.2023.3284671 doi: 10.1109/TGRS.2023.3284671
|
| [26] |
L. Pham, C. Le, D. Ngo, A. Nguyen, J. Lampert, A. Schindler, et al., A light-weight deep learning model for remote sensing image classification, Proceedings of International Symposium on Image and Signal Processing and Analysis (ISPA), 2023, 1–6. https://doi.org/10.1109/ISPA58351.2023.10279679 doi: 10.1109/ISPA58351.2023.10279679
|
| [27] |
F. Zheng, S. Lin, W. Zhou, H. Huang, A lightweight dual-branch swin transformer for remote sensing scene classification, Remote Sens., 15 (2023), 2865. https://doi.org/10.3390/rs15112865 doi: 10.3390/rs15112865
|
| [28] |
S. Chaib, H. Liu, Y. Gu, H. Yao, Deep feature fusion for vhr remote sensing scene classification, IEEE Trans. Geosci. Remote, 55 (2017), 4775–4784. https://doi.org/10.1109/TGRS.2017.2700322 doi: 10.1109/TGRS.2017.2700322
|
| [29] |
W. Hu, C. Lan, T. Chen, S. Liu, L. Yin, L. Wang, Scene classification of remote sensing image based on multi-path reconfigurable neural network, Land, 13 (2024), 1718. https://doi.org/10.3390/land13101718 doi: 10.3390/land13101718
|
| [30] |
Y. Niu, Z. Song, Q. Luo, G. Chen, M. Ma, F. Li, Atmformer: an adaptive token merging vision transformer for remote sensing image scene classification, Remote Sens., 17 (2025), 660. https://doi.org/10.3390/rs17040660 doi: 10.3390/rs17040660
|
| [31] |
Y. Zhang, Y. Zhao, J. Wang, Z. Xu, D. Liu, Dual attention transformers: adaptive linear and hybrid cross attention for remote sensing scene classification, IET Image Process., 19 (2025), e70076. https://doi.org/10.1049/ipr2.70076 doi: 10.1049/ipr2.70076
|
| [32] | C. Li, R. Wang, X. Yang, D. Chu, X. Han, X. Chu, Rsrwkv: a linear-complexity 2D attention mechanism for efficient remote sensing vision task, IEEE Trans. Circ. Syst. Vid., in press. https://doi.org/10.1109/TCSVT.2025.3636726 |
| [33] |
M. Ahangarha, H. Rezvan, M. Valadan Zoej, F. Youssefi, Employing transfer learning in land-use land-cover for risk management. Int. Arch. Photogramm. Remote Sens. Spatial Inf. Sci., XLVIII-3/W3-2024 (2024), 1–7. https://doi.org/10.5194/isprs-archives-XLVIII-3-W3-2024-1-2024 doi: 10.5194/isprs-archives-XLVIII-3-W3-2024-1-2024
|


Figures(18) / Tables(29)

Wiem Abdelbaki, Wided Bouchelligua, Inzamam Mashood Nasir, Sara Tehsin, Hend Alshaya. Mamba-RSI: a state-space deep learning framework for efficient land-use and land-cover classification in remote sensing imagery[J]. AIMS Mathematics, 2026, 11(3): 5600-5647. doi: 10.3934/math.2026231







 DownLoad:
DownLoad: