Early diagnosis of heart disease is vital for reducing mortality and improving patient outcomes; yet, accurate prediction remains a significant challenge owing to the complexity and high dimensionality of medical data. Data preprocessing is essential for overcoming these issues by cleaning, transforming, reducing, and balancing data to provide reliable inputs for feature selection and classification. This study introduces an improved chi-square ($ \chi^{2} $) feature selection framework combined with multiple classifiers to enhance predictive performance. Our method was applied to Cleveland heart disease and diabetes datasets, where numeric attributes were discretized into categorical values, enabling $ \chi^{2} $ to select the most informative features while eliminating redundancy. Several classifiers, including support vector machine (SVM), logistic regression (LR), K-nearest neighbors (KNN), and naive Bayes (NB), were trained using both the reduced subset and the complete feature set. Results show that the preprocessing include $ \chi^{2} $ feature selection, achieved the highest performance. On the Cleveland dataset, the model attained a mean accuracy of 93.72%, precision of 94.01%, recall of 93.72%, F1-score of 93.74%, and an area under the curve(AUC) of 97.87%, while on the diabetes dataset, it achieved mean values of 93.55% accuracy, 94.23% precision, 93.55% recall, 93.48% F1-score, and an AUC 93.53%. The main contribution of this work lies in integrating discretization with $ \chi^{2} $ based selection to produce a compact and discriminative feature subset. With a minimal number of selected features, the proposed approach delivers robust, accurate, and computationally efficient heart disease prediction, outperforming existing methods.
Citation: Heba Nayl, Elkhateeb S. Aly, Amira Rezk, M. E. Fares. Improved chi-square feature selection for robust heart disease data classification[J]. AIMS Mathematics, 2026, 11(1): 2682-2701. doi: 10.3934/math.2026108
Early diagnosis of heart disease is vital for reducing mortality and improving patient outcomes; yet, accurate prediction remains a significant challenge owing to the complexity and high dimensionality of medical data. Data preprocessing is essential for overcoming these issues by cleaning, transforming, reducing, and balancing data to provide reliable inputs for feature selection and classification. This study introduces an improved chi-square ($ \chi^{2} $) feature selection framework combined with multiple classifiers to enhance predictive performance. Our method was applied to Cleveland heart disease and diabetes datasets, where numeric attributes were discretized into categorical values, enabling $ \chi^{2} $ to select the most informative features while eliminating redundancy. Several classifiers, including support vector machine (SVM), logistic regression (LR), K-nearest neighbors (KNN), and naive Bayes (NB), were trained using both the reduced subset and the complete feature set. Results show that the preprocessing include $ \chi^{2} $ feature selection, achieved the highest performance. On the Cleveland dataset, the model attained a mean accuracy of 93.72%, precision of 94.01%, recall of 93.72%, F1-score of 93.74%, and an area under the curve(AUC) of 97.87%, while on the diabetes dataset, it achieved mean values of 93.55% accuracy, 94.23% precision, 93.55% recall, 93.48% F1-score, and an AUC 93.53%. The main contribution of this work lies in integrating discretization with $ \chi^{2} $ based selection to produce a compact and discriminative feature subset. With a minimal number of selected features, the proposed approach delivers robust, accurate, and computationally efficient heart disease prediction, outperforming existing methods.

| [1] | World Health Organization (WHO), Cardiovascular diseases, World Health Organization office, 2025. Available from: https://www.who.int/health-topics/cardiovascular-diseases/#tab = tab_1. |
| [2] | H. Ahmed, E. M. Younis, A. Hendawi, A. A. Ali, Heart disease identification from patients' social posts, machine learning solution on Spark, Future Gener. Comp. Sy., 111, (2020), 714–722. https://doi.org/10.1016/j.future.2019.09.056 |
| [3] |
Y. Hao, M. Usama, J. Yang, M. S. Hossain, A. Ghoneim, Recurrent convolutional neural network based multimodal disease risk prediction, Future Gener. Comp. Sy., 92 (2019), 76–83. https://doi.org/10.1016/j.future.2018.09.031 doi: 10.1016/j.future.2018.09.031

|
| [4] |
T. S. Brisimi, R. Chen, T. Mela, A. Olshevsky, I. C. Paschalidis, W. Shi, Federated learning of predictive models from federated electronic health records, Int. J. Med. Inform., 112 (2018), 59–67. https://doi.org/10.1016/j.ijmedinf.2018.01.007 doi: 10.1016/j.ijmedinf.2018.01.007
|
| [5] |
S. Wadhawan, R. Maini, A systematic review on prediction techniques for cardiac disease, Int. J. Inf. Technol. Sy., 15 (2022), 1–33. https://doi.org/10.4018/IJITSA.290001 doi: 10.4018/IJITSA.290001
|
| [6] |
D. Han, X. Yang, G. Li, S. Wang, Z. Wang, J. Zhao, Highway traffic speed prediction in rainy environment based on APSO-GRU, J. Adv. Transport., 2021 (2021), 4060740. https://doi.org/10.1155/2021/4060740 doi: 10.1155/2021/4060740
|
| [7] |
K. A. Lara Hernandez, T. Rienmüller, D. Baumgartner, C. Baumgartner, Deep learning in spatiotemporal cardiac imaging: a review of methodologies and clinical usability, Comput. Biol. Med., 130 (2021), 104200. https://doi.org/10.1016/j.compbiomed.2020.104200 doi: 10.1016/j.compbiomed.2020.104200
|
| [8] |
M. Juhola, H. Joutsijoki, K. Penttinen, D. Shah, R. P. Pölönen, K. Aalto-Setälä, Data analytics for cardiac diseases, Comput. Biol. Med., 142 (2022), 105218. https://doi.org/10.1016/j.compbiomed.2022.105218 doi: 10.1016/j.compbiomed.2022.105218
|
| [9] |
A. Bommert, X. Sun, B. Bischl, J. Rahnenführer, M. Lang, Benchmark for filter methods for feature selection in high-dimensional classification data, Comput. Stat. Data Anal., 143 (2020), 106839. https://doi.org/10.1016/j.csda.2019.106839 doi: 10.1016/j.csda.2019.106839
|
| [10] |
M. Labani, P. Moradi, F. Ahmadizar, M. Jalili, A novel multivariate filter method for feature selection in text classification problems, Eng. Appl. Artif. Intel., 70 (2018), 25–37. https://doi.org/10.1016/j.engappai.2017.12.014 doi: 10.1016/j.engappai.2017.12.014
|
| [11] |
N. Pudjihartono, T. Fadason, A. Kempa-Liehr, J. O'Sullivan, A review of feature selection methods for machine learning-based disease risk prediction, Front. Bioinform., 2 (2022), 927312. https://doi.org/10.3389/fbinf.2022.927312 doi: 10.3389/fbinf.2022.927312
|
| [12] |
A. Mustaqeem, S. M. Anwar, M. Majid, Multiclass classification of cardiac arrhythmia using improved feature selection and SVM invariants, Comput. Math. Method. Med., 2018 (2018), 7310496. https://doi.org/10.1155/2018/7310496 doi: 10.1155/2018/7310496
|
| [13] | V. Çetin, O. Yıldız, A comprehensive review on data preprocessing techniques in data analysis, Pamukkale Üniversitesi Mühendislik Bilimleri Dergisi, 28 (2022), 299–312. |
| [14] |
P. Yıldırım, D. Birant, Application of data mining techniques in cloud computing: a literature review, Pamukkale Univ. J. Eng. Sci., 24 (2018), 336–343. https://doi.org/10.5505/pajes.2017.65642 doi: 10.5505/pajes.2017.65642
|
| [15] | I. A. Venkatkumar, S. J. K. Shardaben, Comparative study of data mining clustering algorithms, Proceedings of International Conference on Data Science and Engineering (ICDSE), 2016, 1–7. https://doi.org/10.1109/ICDSE.2016.7823946 |
| [16] |
B. Çığşar, D. Ünal, Comparison of data mining classification algorithms determining the default risk, Scientific Programming, 2019 (2019), 8706505. https://doi.org/10.1155/2019/8706505 doi: 10.1155/2019/8706505
|
| [17] | S. Umadevi, K. S. J. Marseline, A survey on data mining classification algorithms, Proceedings of International Conference on Signal Processing and Communication (ICSPC), 2017,264–268. https://doi.org/10.1109/CSPC.2017.8305851 |
| [18] | S. Ajibade, A. Adediran, An overview of big data visualization techniques in data mining, International Journal of Computer Science and Information Technology Research, 4 (2016), 105–113. |
| [19] | A. Kunjir, H. Sawant, N. Shaikh, Data mining and visualization for prediction of multiple diseases in healthcare, Proceedings of International Conference on Big Data Analytics and Computational Intelligence (ICBDAC), 2017,329–334. https://doi.org/10.1109/ICBDACI.2017.8070858 |
| [20] | X. Zhou, C. Yang, N. Meng, Method of knowledge representation on spatial classification, Proceedings of Sixth International Conference on Fuzzy Systems and Knowledge Discovery, 2009,237–240. https://doi.org/10.1109/FSKD.2009.775 |
| [21] | Y. Guowei, L. Xinghua, T. Xuyan, A new knowledge representation based matter element system and the related extension reasoning, Proceedings of International Conference on Natural Language Processing and Knowledge Engineering, 2003, 89–94. https://doi.org/10.1109/NLPKE.2003.1275874 |
| [22] |
F. Ali, S. El-Sappagh, S. R. Islam, D. Kwak, A. Ali, M. Imran, et al., A smart healthcare monitoring system for heart disease prediction based on ensemble deep learning and feature fusion, Inform. Fusion, 63 (2020), 208–222. https://doi.org/10.1016/j.inffus.2020.06.008 doi: 10.1016/j.inffus.2020.06.008
|
| [23] |
I. Tougui, A. Jilbab, J. El Mhamdi, Heart disease classification using data mining tools and machine learning techniques, Health Technol., 10 (2020), 1137–1144. https://doi.org/10.1007/s12553-020-00438-1 doi: 10.1007/s12553-020-00438-1
|
| [24] |
S. Kalagotla, S. Gangashetty, K. Giridhar, A novel stacking technique for prediction of diabetes, Comput. Biol. Med., 135 (2021), 104554. https://doi.org/10.1016/j.compbiomed.2021.104554 doi: 10.1016/j.compbiomed.2021.104554
|
| [25] |
C. Latha, S. Jeeva, Improving the accuracy of prediction of heart disease risk based on ensemble classification techniques, Informatics in Medicine Unlocked, 16 (2019), 100203. https://doi.org/10.1016/j.imu.2019.100203 doi: 10.1016/j.imu.2019.100203
|
| [26] |
T. Parhizkar, E. Rafieipour, A. Parhizkar, Evaluation and improvement of energy consumption prediction models using principal component analysis based feature reduction, J. Clean. Prod., 279 (2021), 123866. https://doi.org/10.1016/j.jclepro.2020.123866 doi: 10.1016/j.jclepro.2020.123866
|
| [27] |
R. R. Sarra, A. M. Dinar, M. A. Mohammed, K. H. Abdulkareem, Enhanced heart disease prediction based on machine learning and $\chi^2$ statistical optimal feature selection model, Designs, 6 (2022), 87. https://doi.org/10.3390/designs6050087 doi: 10.3390/designs6050087
|
| [28] |
R. Kapila, S. Saleti, Federated learning-based disease prediction: a fusion approach with feature selection and extraction, Biomed. Signal Proces., 100 (2025), 106961. https://doi.org/10.1016/j.bspc.2024.106961 doi: 10.1016/j.bspc.2024.106961
|
| [29] | S. García, J. Luengo, F. Herrera, Data preprocessing in data mining, Cham: Springer, 2015. https://doi.org/10.1007/978-3-319-10247-4 |
| [30] |
J. Luengo, S. García, F. Herrera, On the choice of the best imputation methods for missing values considering three groups of classification methods, Knowl. Inf. Syst., 32 (2012), 77–108. https://doi.org/10.1007/s10115-011-0424-2 doi: 10.1007/s10115-011-0424-2
|
| [31] |
A. Smiti, A critical overview of outlier detection methods, Comput. Sci. Rev., 38 (2020), 100306. https://doi.org/10.1016/j.cosrev.2020.100306 doi: 10.1016/j.cosrev.2020.100306
|
| [32] | A. Boukerche, L. Zheng, O. Alfandi, Outlier detection: methods, models, and classification, ACM Comput. Surv., 53 (2020), 55. https://doi.org/10.1145/3381028 |
| [33] |
H. A. Sturges, The choice of a class interval, J. Amer. Stat. Assoc., 21 (1926), 65–66. https://doi.org/10.1080/01621459.1926.10502161 doi: 10.1080/01621459.1926.10502161
|
| [34] |
Z. Chuan, W. Yusoff, M. Aziz, A. Senawi, T. Ken, A comparison study between Doane's and Freedman-Diaconis' binning rule in characterizing potential water resources availability, J. Phys.: Conf. Ser., 1366 (2019), 012103. https://doi.org/10.1088/1742-6596/1366/1/012103 doi: 10.1088/1742-6596/1366/1/012103
|
| [35] | D. Scott, Scott's rule, Wiley Comput. Stat., 2 (2010), 497–502. https://doi.org/10.1002/wics.103 |
| [36] | P. Muhammad Ali, R. Faraj, Data normalization and standardization: a technical report, Machine Learning Technical Report, 1 (2014), 1–6. |
| [37] |
A. Alizadeh Naeini, M. Babadi, S. Homayouni, Assessment of normalization techniques on the accuracy of hyperspectral data clustering, Int. Arch. Photogramm. Remote Sens. Spatial Inf. Sci., XLII-4/W4 (2017), 27–30. https://doi.org/10.5194/isprs-archives-XLII-4-W4-27-2017 doi: 10.5194/isprs-archives-XLII-4-W4-27-2017
|
| [38] |
N. V. Chawla, K. W. Bowyer, L. O. Hall, W. P. Kegelmeyer, SMOTE: synthetic minority over-sampling technique, J. Artif. Intell. Res., 16 (2002), 321–357. https://doi.org/10.1613/jair.953 doi: 10.1613/jair.953
|
| [39] |
W. Yue, Z. Wang, H. Chen, A. Payne, X. Liu, Machine learning with applications in breast cancer diagnosis and prognosis, Designs, 2 (2018), 13. https://doi.org/10.3390/designs2020013 doi: 10.3390/designs2020013
|
| [40] |
F. Aliyar Vellameeran, T. Brindha, A new variant of deep belief network assisted with optimal feature selection for heart disease diagnosis using IoT wearable medical devices, Comput. Method. Biomec., 25 (2022), 387–411. https://doi.org/10.1080/10255842.2021.1955360 doi: 10.1080/10255842.2021.1955360
|
| [41] |
L. Ali, C. Zhu, M. Zhou, Y. Liu, Early diagnosis of Parkinson's disease from multiple voice recordings by simultaneous sample and feature selection, Expert Syst. Appl., 137 (2019), 22–28. https://doi.org/10.1016/j.eswa.2019.06.052 doi: 10.1016/j.eswa.2019.06.052
|
| [42] | H. Liu, R. Setiono, Chi2: feature selection and discretization of numeric attributes, Proceedings of the 7th IEEE International Conference on Tools with Artificial Intelligence, 1995,388–391. https://doi.org/10.1109/TAI.1995.479783 |
| [43] |
D. Colquhoun, The reproducibility of research and the misinterpretation of p-values, R. Soc. Open Sci., 4 (2017), 171085. https://doi.org/10.1098/rsos.171085 doi: 10.1098/rsos.171085
|
| [44] |
Ž. Vujović, Classification model evaluation metrics, Int. J. Adv. Comput. Sci., 12 (2021), 599–606. https://doi.org/10.14569/IJACSA.2021.0120670 doi: 10.14569/IJACSA.2021.0120670
|
| [45] | N. Boyko, K. Boksho, Application of the naive Bayesian classifier in work on sentimental analysis of medical data, Proceedings of 3rd International Conference on Informatics and Data-Driven Medicine, 2020, 1–12. |
| [46] | B. Tarle, R. Tajanpure, S. Jena, Medical data classification using different optimization techniques: a survey, IJRET, 5 (2016), 101–108. |
| [47] |
M. Brameier, W. Banzhaf, A comparison of linear genetic programming and neural networks in medical data mining, IEEE Trans. Evolut. Comput., 5 (2001), 17–26. https://doi.org/10.1109/4235.910462 doi: 10.1109/4235.910462
|
| [48] | P. Tang, M. Tseng, Medical data mining using BGA and RGA for weighting of features in fuzzy k-NN classification, Proceedings of International Conference on Machine Learning and Cybernetics, 2009, 3070–3075. https://doi.org/10.1109/ICMLC.2009.5212633 |
| [49] | V. Sneha Latha, P. Y. L. Swetha, M. Bhavya, G. Geetha, D. K. Suhasini, Combined methodology of the classification rules for medical data-sets, International Journal of Engineering Trends and Technology, 3 (2012), 32–36. |
| [50] | M. Islam, M. Chowdhury, S. Khan, Medical image classification using an efficient data mining technique, Proceedings of 7th Asia-Pacific Complex Systems Conference, 2004, 34–42. |
| [51] | Y. Xing, J. Wang, Z. Zhao, Combination data mining methods with new medical data to predicting outcome of coronary heart disease, Proceedings of International Conference on Convergence Information Technology, 2007,868–872. https://doi.org/10.1109/ICCIT.2007.204 |
| [52] | M. Samb, F. Camara, S. Ndiaye, Y. Slimani, M. Esseghir, A novel RFE-SVM-based feature selection approach for classification, International Journal of Advanced Science and Technology, 43 (2012), 27–36. |
| [53] |
T. Rymarczyk, E. Kozłowski, G. Kłosowski, K. Niderla, Logistic regression for machine learning in process tomography, Sensors, 19 (2019), 3400. https://doi.org/10.3390/s19153400 doi: 10.3390/s19153400
|
| [54] | P. Komarek, Logistic regression for data mining and high-dimensional classification, Ph.D Thesis, Carnegie Mellon University, 2004. |
| [55] |
M. Shokouhifar, M. Hasanvand, E. Moharamkhani, F. Werner, Ensemble heuristic-metaheuristic feature fusion learning for heart disease diagnosis using tabular data, Algorithms, 17 (2024), 34. https://doi.org/10.3390/a17010034 doi: 10.3390/a17010034
|
| [56] | A. Prakash, O. Vignesh, R. Rani, S. Abinayaa, An ensemble technique for early prediction of type 2 diabetes mellitus–a normalization approach, Turkish Journal of Computer and Mathematics Education, 12 (2021), 2136–2143. |
| [57] |
S. Kumari, D. Kumar, M. Mittal, An ensemble approach for classification and prediction of diabetes mellitus using soft voting classifier, International Journal of Cognitive Computing in Engineering, 2 (2021), 40–46. https://doi.org/10.1016/j.ijcce.2021.01.001 doi: 10.1016/j.ijcce.2021.01.001
|
| [58] |
P. Rajendra, S. Latifi, Prediction of diabetes using logistic regression and ensemble techniques, Computer Methods and Programs in Biomedicine Update, 1 (2021), 100032. https://doi.org/10.1016/j.cmpbup.2021.100032 doi: 10.1016/j.cmpbup.2021.100032
|
| [59] |
R. Aggrawal, S. Pal, Sequential feature selection and machine learning algorithm-based patient's death events prediction and diagnosis in heart disease, SN Comput. Sci., 1 (2020), 344. https://doi.org/10.1007/s42979-020-00370-1 doi: 10.1007/s42979-020-00370-1
|
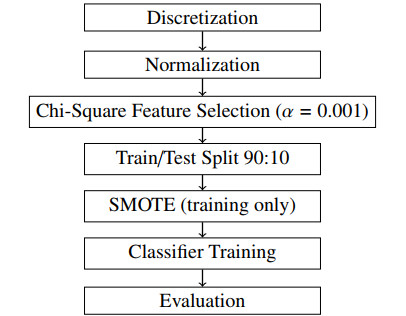
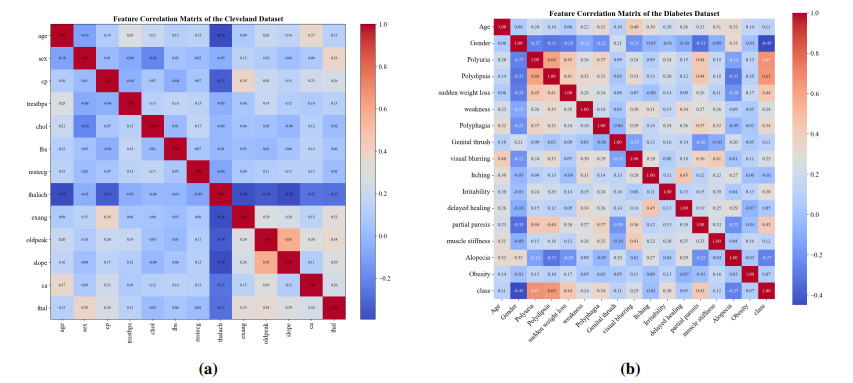
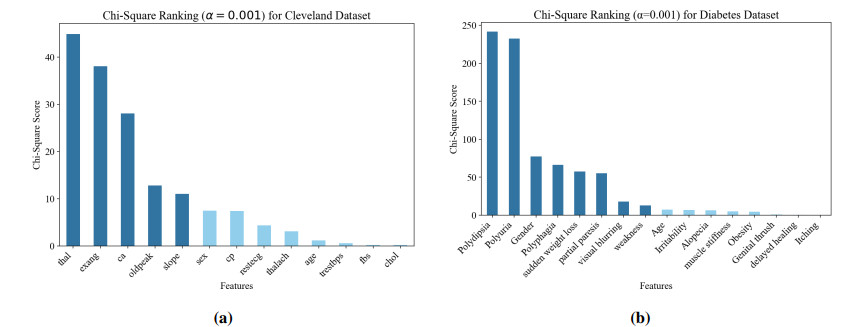
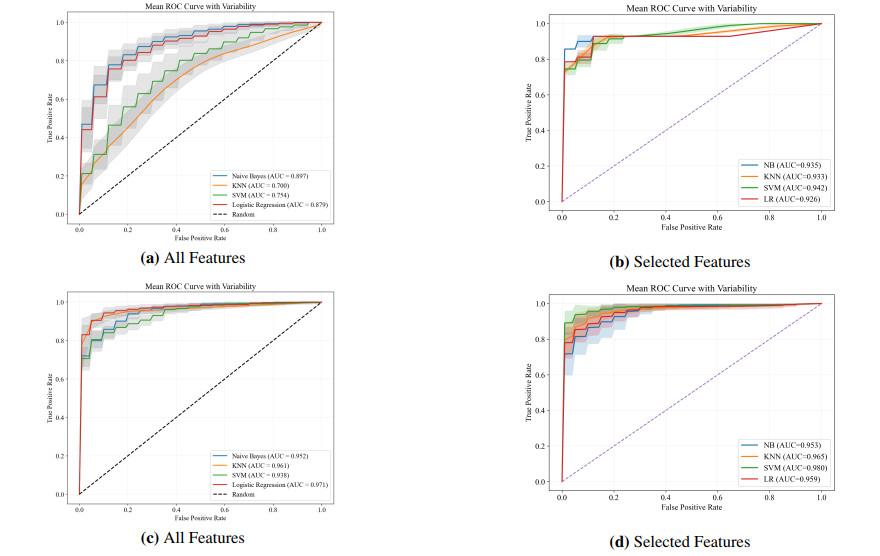
Figures(4) / Tables(8)

Heba Nayl, Elkhateeb S. Aly, Amira Rezk, M. E. Fares. Improved chi-square feature selection for robust heart disease data classification[J]. AIMS Mathematics, 2026, 11(1): 2682-2701. doi: 10.3934/math.2026108







 DownLoad:
DownLoad: