In this paper, we first introduce a preconditioned primal–dual gradient algorithm based on conjugate duality theory. This algorithm is designed to solve a composite optimization problem whose objective function consists of two summands: a continuously differentiable nonconvex function and the composition of a nonsmooth nonconvex function with a linear operator. Under mild conditions, we prove that any cluster point of the generated sequence is a critical point of the composite optimization problem. Under the Kurdyka–Łojasiewicz property, we establish the global convergence and convergence rates for the iterates. Second, for nonconvex finite-sum optimization, we propose a stochastic algorithm that combines the preconditioned primal–dual gradient algorithm with a class of variance-reduced stochastic gradient estimators. Almost sure global convergence and expected convergence rates are derived by relying on the Kurdyka–Łojasiewicz inequality. Finally, preliminary numerical results are presented to demonstrate the effectiveness of the proposed algorithms.
Citation: Jiahong Guo. Preconditioned primal–dual gradient methods for nonconvex composite and finite-sum optimization[J]. AIMS Mathematics, 2026, 11(1): 2188-2226. doi: 10.3934/math.2026089
In this paper, we first introduce a preconditioned primal–dual gradient algorithm based on conjugate duality theory. This algorithm is designed to solve a composite optimization problem whose objective function consists of two summands: a continuously differentiable nonconvex function and the composition of a nonsmooth nonconvex function with a linear operator. Under mild conditions, we prove that any cluster point of the generated sequence is a critical point of the composite optimization problem. Under the Kurdyka–Łojasiewicz property, we establish the global convergence and convergence rates for the iterates. Second, for nonconvex finite-sum optimization, we propose a stochastic algorithm that combines the preconditioned primal–dual gradient algorithm with a class of variance-reduced stochastic gradient estimators. Almost sure global convergence and expected convergence rates are derived by relying on the Kurdyka–Łojasiewicz inequality. Finally, preliminary numerical results are presented to demonstrate the effectiveness of the proposed algorithms.

| [1] |
F. Wen, L. Chu, P. Liu, R. C. Qiu, A survey on nonconvex regularization-based sparse and low-rank recovery in signal processing, statistics, and machine learning, IEEE Access, 6 (2018), 69883–69906. https://doi.org/10.1109/ACCESS.2018.2880454 doi: 10.1109/ACCESS.2018.2880454

|
| [2] |
H. Attouch, J. Bolte, B. F. Svaiter, Convergence of descent methods for semi-algebraic and tame problems: Proximal algorithms, forward-backward splitting, and regularized Gauss-Seidel methods, Math. Program., 137 (2013), 91–129. https://doi.org/10.1007/s10107-011-0484-9 doi: 10.1007/s10107-011-0484-9
|
| [3] |
G. Li, T. K. Pong, Global convergence of splitting methods for nonconvex composite optimization, SIAM J. Optim., 25 (2015), 2434–2460. https://doi.org/10.1137/140998135 doi: 10.1137/140998135
|
| [4] |
A. Themelis, L. Stella, P. Patrinos, Forward-backward envelope for the sum of two nonconvex functions: Further properties and nonmonotone linesearch algorithms, SIAM J. Optim., 28 (2018), 2274–2303. https://doi.org/10.1137/16M1080240 doi: 10.1137/16M1080240
|
| [5] |
J. Bolte, S. Sabach, M. Teboulle, Nonconvex Lagrangian-based optimization: Monitoring schemes and global convergence, Math. Oper. Res., 43 (2018), 1210–1232. https://doi.org/10.1287/moor.2017.0900 doi: 10.1287/moor.2017.0900
|
| [6] |
R. I. Boţ, D. K. Nguyen, The proximal alternating direction method of multipliers in the nonconvex setting: Convergence analysis and rates, Math. Oper. Res., 45 (2020), 682–712. https://doi.org/10.1287/moor.2019.1008 doi: 10.1287/moor.2019.1008
|
| [7] |
A. M. Tillmann, D. Bienstock, A. Lodi, A. Schwartz, Cardinality minimization, constraints, and regularization: A survey, SIAM Rev., 66 (2024), 403–477. https://doi.org/10.1137/21M142770X doi: 10.1137/21M142770X
|
| [8] |
R. H. Byrd, J. Nocedal, F. Oztoprak, An inexact successive quadratic approximation method for $\ell_1$ regularized optimization, Math. Program., 157 (2016), 375–396. https://doi.org/10.1007/s10107-015-0941-y doi: 10.1007/s10107-015-0941-y
|
| [9] |
S. Bonettini, I. Loris, F. Porta, M. Prato, S. Rebegoldi, On the convergence of a linesearch based proximal-gradient method for nonconvex optimization, Inverse Probl., 33 (2017), 055005. https://doi.org/10.1088/1361-6420/aa5bfd doi: 10.1088/1361-6420/aa5bfd
|
| [10] |
S. Bonettini, M. Prato, S. Rebegoldi, Convergence of inexact forward-backward algorithms using the forward-backward envelope, SIAM J. Optim., 30 (2020), 3069–3097. https://doi.org/10.1137/19M1254155 doi: 10.1137/19M1254155
|
| [11] |
A. Chambolle, T. Pock, A first-order primal–dual algorithm for convex problems with applications to imaging, J. Math. Imaging Vision, 40 (2011), 120–145. https://doi.org/10.1007/s10851-010-0251-1 doi: 10.1007/s10851-010-0251-1
|
| [12] | T. Pock, A. Chambolle, Diagonal preconditioning for first order primal–dual algorithms in convex optimization, In: 2011 International Conference on Computer Vision, 2011, 1762–1769. |
| [13] |
Y. Liu, Y. Xu, W. Yin, Acceleration of primal–dual methods by preconditioning and simple subproblem procedures, J. Sci. Comput., 86 (2021), 1–34. https://doi.org/10.1007/s10915-020-01371-1 doi: 10.1007/s10915-020-01371-1
|
| [14] | T. Hastie, R. Tibshirani, J. Friedman, The Elements of Statistical Learning, 2 Eds., New York: Springer, 2009, https://doi.org/10.1007/978-0-387-84858-7 |
| [15] |
F. Bian, J. Liang, X. Zhang, A stochastic alternating direction method of multipliers for non-smooth and non-convex optimization, Inverse Probl., 37 (2021), 075009. https://doi.org/10.1088/1361-6420/ac0966 doi: 10.1088/1361-6420/ac0966
|
| [16] |
L. Bottou, F. E. Curtis, J. Nocedal, Optimization methods for large-scale machine learning, SIAM Rev., 60 (2018), 223–311. https://doi.org/10.1137/16M1080173 doi: 10.1137/16M1080173
|
| [17] | G. Lan, First-Order and Stochastic Optimization Methods for Machine Learning, Berlin: Springer, 2020. https://doi.org/10.1007/978-3-030-39568-1 |
| [18] |
A. Chambolle, M. J. Ehrhardt, P. Richtárik, C. B. Schönlieb, Stochastic primal–dual hybrid gradient algorithm with arbitrary sampling and imaging applications, SIAM J. Optim., 28 (2018), 2783–2808. https://doi.org/10.1137/17M1134834 doi: 10.1137/17M1134834
|
| [19] |
J. Bai, W. W. Hager, H. Zhang, An inexact accelerated stochastic ADMM for separable convex optimization, Comput. Optim. Appl., 81 (2022), 479–518. https://doi.org/10.1007/s10589-021-00338-8 doi: 10.1007/s10589-021-00338-8
|
| [20] |
J. Bai, F. Bian, X. Chang, L. Du, Accelerated stochastic Peaceman-Rachford method for empirical risk minimization, J. Oper. Res. Soc. China, 11 (2023), 783–807. https://doi.org/10.1007/s40305-023-00470-8 doi: 10.1007/s40305-023-00470-8
|
| [21] |
J. Bai, Y. Chen, X. Yu, H. Zhang, Generalized asymmetric forward-backward-adjoint algorithms for convex-concave saddle-point problem, J. Sci. Comput., 102 (2025), 80. https://doi.org/10.1007/s10915-025-02802-7 doi: 10.1007/s10915-025-02802-7
|
| [22] |
M. Schmidt, N. Le Roux, F. Bach, Minimizing finite sums with the stochastic average gradient, Math. Program., 162 (2017), 83–112. https://doi.org/10.1007/s10107-016-1030-6 doi: 10.1007/s10107-016-1030-6
|
| [23] | A. Defazio, F. Bach, S. Lacoste-Julien, SAGA: A fast incremental gradient method with support for non-strongly convex composite objectives, Adv. Neural Inform. Proc. Syst., 2 (2014), 1646–1654. |
| [24] | R. Johnson, T. Zhang, Accelerating stochastic gradient descent using predictive variance reduction, In: Proceedings of the 27th International Conference on Neural Information Processing Systems, 1 (2013), 315–323. |
| [25] | L. M. Nguyen, J. Liu, K. Scheinberg, M. Taká, SARAH: A novel method for machine learning problems using stochastic recursive gradient, In: Proceedings of the 34th International Conference on Machine Learning, 70 (2017), 2613–2621. |
| [26] | Z. Li, J. Li, A simple proximal stochastic gradient method for nonsmooth nonconvex optimization, Adv. Neural Inform. Proc. Syst., 31 (2018), 5569–5579. |
| [27] | N. H. Pham, L. M. Nguyen, D. T. Phan, Q. Tran-Dinh, Proxsarah: An efficient algorithmic framework for stochastic composite nonconvex optimization, J. Mach. Learn. Res., 21 (2020), 1–48. |
| [28] |
G. Fort, E. Moulines, Stochastic variable metric proximal gradient with variance reduction for non-convex composite optimization, Stat. Comput., 33 (2023), 65. https://doi.org/10.1007/s11222-023-10230-6 doi: 10.1007/s11222-023-10230-6
|
| [29] | C. Fang, C. J. Li, Z. Lin, T. Zhang, SPIDER: Near-optimal non-convex optimization via stochastic path-integrated differential estimator, In: Advances in Neural Information Processing Systems, 31 (2018), 687–697. |
| [30] |
A. Milzarek, X. Xiao, S. Cen, Z. Wen, M. Ulbrich, A stochastic semismooth Newton method for nonsmooth nonconvex optimization, SIAM J. Optim., 29 (2019), 2916–2948. https://doi.org/10.1137/18M1181249 doi: 10.1137/18M1181249
|
| [31] |
X. Wang, X. Chen, Complexity of finite-sum optimization with nonsmooth composite functions and non-lipschitz regularization, SIAM J. Optim., 34 (2024), 2472–2502. https://doi.org/10.1137/23M1546701 doi: 10.1137/23M1546701
|
| [32] | Y. Xu, R. Jin, T. Yang, Non-asymptotic analysis of stochastic methods for non-smooth non-convex regularized problems, Adv. Neural Inform. Proc. Syst., 32 (2019), 2630–2640. |
| [33] |
P. Latafat, A. Themelis, P. Patrinos, Block-coordinate and incremental aggregated proximal gradient methods for nonsmooth nonconvex problems, Math. Program., 193 (2022), 195–224. https://doi.org/10.1007/s10107-020-01599-7 doi: 10.1007/s10107-020-01599-7
|
| [34] | J. Qiu, X. Li, A. Milzarek, A new random reshuffling method for nonsmooth nonconvex finite-sum optimization, J. Mach. Learn. Res., 26 (2025), 1–46. |
| [35] |
Y. Zeng, J. Bai, S. Wang, Z. Wang, X. Shen, A hybrid stochastic alternating direction method of multipliers for nonconvex and nonsmooth composite optimization, Eur. J. Oper. Res., 329 (2026), 63–78. https://doi.org/10.1016/j.ejor.2025.10.024 doi: 10.1016/j.ejor.2025.10.024
|
| [36] |
D. Driggs, J. Tang, J. Liang, M. Davies, C. B. Schönlieb, A stochastic proximal alternating minimization for nonsmooth and nonconvex optimization, SIAM J. Imaging Sci., 14 (2021), 1932–1970. https://doi.org/10.1137/20M1387213 doi: 10.1137/20M1387213
|
| [37] | A. Beck, First-Order Methods in Optimization, Philadelphia: SIAM, 2017. https://doi.org/10.1137/1.9781611974997 |
| [38] | R. T. Rockafellar, Convex Analysis, Princeton: Princeton University Press, 1970. https://doi.org/10.1515/9781400873173 |
| [39] | J. F. Bonnans, A. Shapiro, Perturbation Analysis of Optimization Problems, New York: Springer-Verlag, 2000. https://doi.org/10.1007/978-1-4612-1394-9 |
| [40] |
H. Attouch, J. Bolte, P. Redont, A. Soubeyran, Proximal alternating minimization and projection methods for nonconvex problems: An approach based on the Kurdyka-Łojasiewicz inequality, Math. Program., 35 (2010), 5–16. https://doi.org/10.1287/moor.1100.0449 doi: 10.1287/moor.1100.0449
|
| [41] |
J. Bolte, S. Sabach, M. Teboulle, Proximal alternating linearized minimization for nonconvex and nonsmooth problems, Math. Program., 146 (2014), 459–494. https://doi.org/10.1007/s10107-013-0701-9 doi: 10.1007/s10107-013-0701-9
|
| [42] |
H. Attouch, J. Bolte, On the convergence of the proximal algorithm for nonsmooth functions involving analytic features, Math. Program., 116 (2009), 5–16. https://doi.org/10.1007/s10107-007-0133-5 doi: 10.1007/s10107-007-0133-5
|
| [43] |
R. I. Boţ, E. R. Csetnek, D. K. Nguyen, A proximal minimization algorithm for structured nonconvex and nonsmooth problems, SIAM J. Optim., 29 (2019), 1300–1328. https://doi.org/10.1137/18M1190689 doi: 10.1137/18M1190689
|
| [44] | R. T. Rockafellar, R. J. B. Wets, Variational Analysis, Berlin: Springer-Verlag, 1998. https://doi.org/10.1007/978-3-642-02431-3 |
| [45] |
X. Li, A. Milzarek, J. Qiu, Convergence of random reshuffling under the Kurdyka-Łojasiewicz inequality, SIAM J. Optim., 33 (2023), 1092–1120. https://doi.org/10.1137/21M1468048 doi: 10.1137/21M1468048
|
| [46] |
D. Davis, D. Drusvyatskiy, S. Kakade, J. D. Lee, Stochastic subgradient method converges on tame functions, Found. Comput. Math., 20 (2020), 119–154. https://doi.org/10.1007/s10208-018-09409-5 doi: 10.1007/s10208-018-09409-5
|
| [47] | D. Davis, The asynchronous PALM algorithm for nonsmooth nonconvex problems, preprint paper, 2016. https://doi.org/10.48550/arXiv.1604.00526 |
| [48] |
J. Friedman, T. Hastie, R. Tibshirani, Sparse inverse covariance estimation with the graphical lasso, Biostatistics, 9 (2008), 432–441. https://doi.org/10.1093/biostatistics/kxm045 doi: 10.1093/biostatistics/kxm045
|
| [49] | I. Guyon, S. Gunn, A. Ben-Hur, G. Dror, Result analysis of the NIPS 2003 feature selection challenge, Adv. Neural Inform. Proc. Syst., 2004,545–552. |
| [50] | D. P. Bertsekas, Convex Optimization Algorithms, Belmont: Athena Scientific, 2015. |
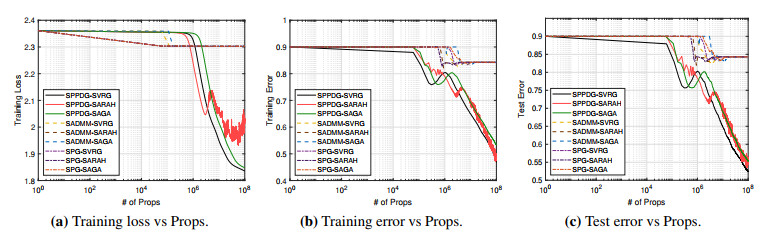
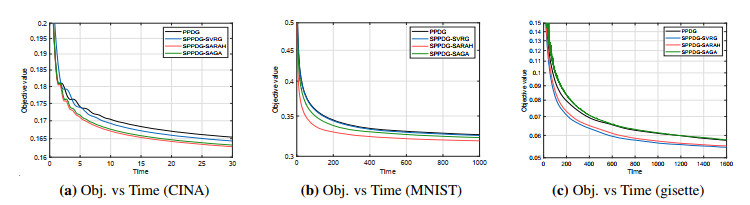
Figures(2)

Jiahong Guo. Preconditioned primal–dual gradient methods for nonconvex composite and finite-sum optimization[J]. AIMS Mathematics, 2026, 11(1): 2188-2226. doi: 10.3934/math.2026089







 DownLoad:
DownLoad: