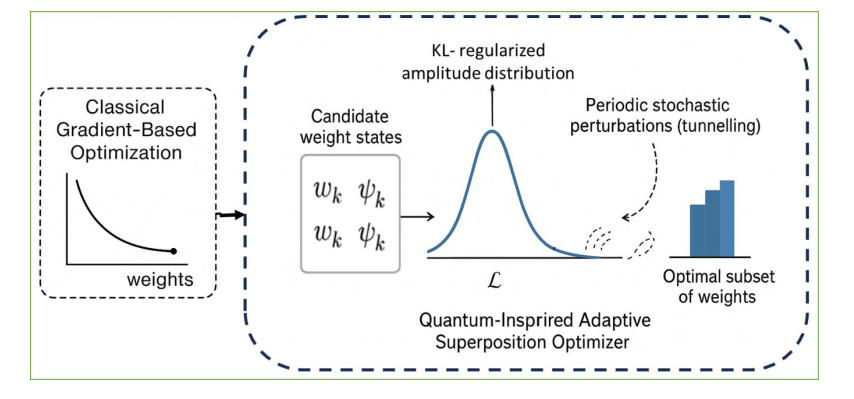
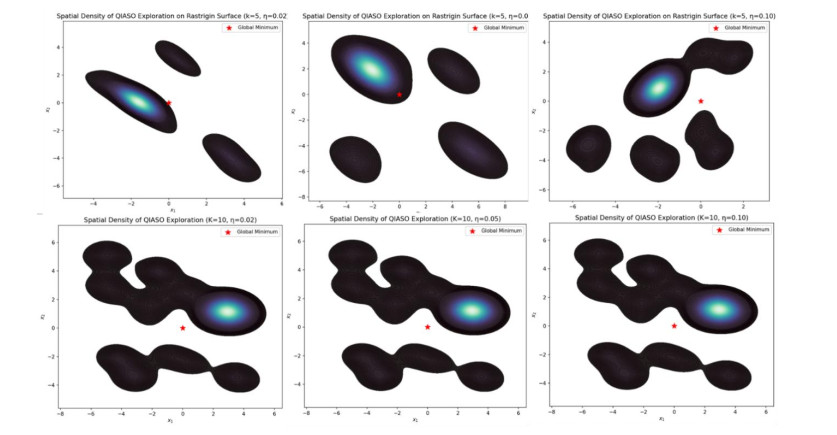
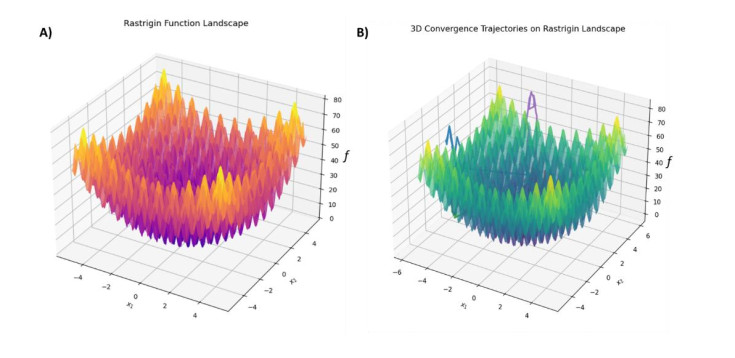
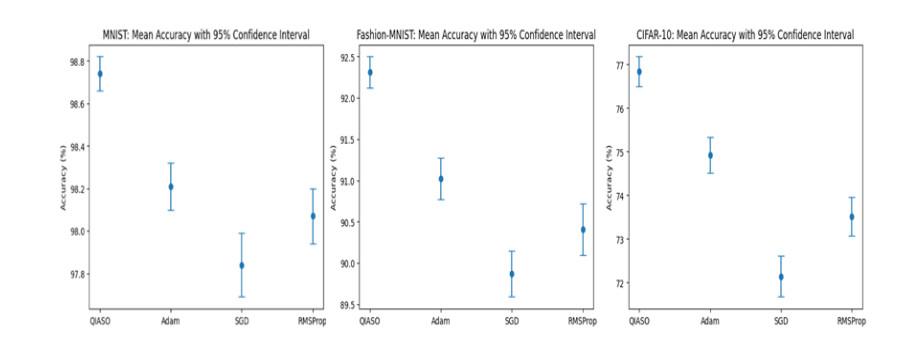
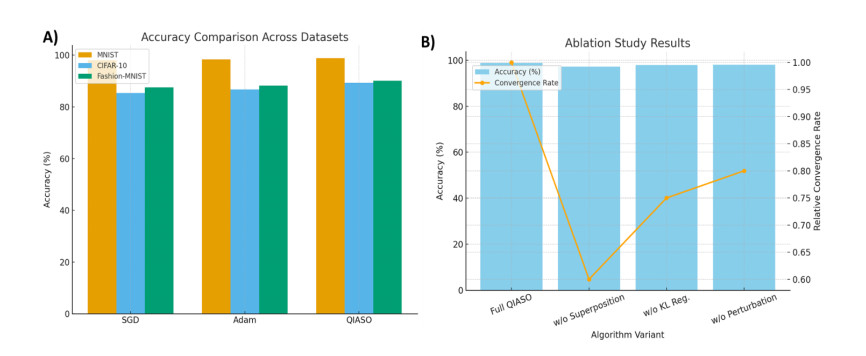
Training deep neural networks is often hindered by the fragility of gradient-based methods, which suffer from vanishing or exploding gradients, sensitivity to initialization, and entrapment in poor local minima. In response to these shortcomings, we introduce a new gradient-free algorithm called Quantum-Inspired Adaptive Superposition Optimization (QIASO), which views weight learning as a probabilistic superposition of candidate solutions, a fundamentally new optimization approach. In contrast to being dedicated to a single weight ensemble, QIASO maintains a distribution over several candidates, which are amplified and suppressed according to dynamically changing weights assigned to them. The variational formulation of the amplitude evolution leads to a KL-regularized formulation of their evolution, which generalizes statistical physics, information geometry, and online optimization viewpoints. To prevent invalid convergence, QIASO incorporates a stochastic perturbation operator based on quantum tunnelling into the optimizer, enabling the optimization process to overcome local minima on the loss surface and converge to the optimal solution. We provide theoretical bounds, monotone convergence of loss reduction, and almost-sure convergence to local optima with mild assumptions. Complexity analysis via empirical techniques suggests that QIASO scales more efficiently than Grover-based quantum-inspired algorithms and incurs no overhead in gradient computation compared to ADAM. The overall findings indicated that QIASO is a viable option for neural training, particularly when combined with other paradigms that utilise either large-scale or gradient-free approaches.
Citation: Irsa Sajjad, Mashail M. AL Sobhi. The quantum-inspired adaptive superposition optimization for neural network training[J]. AIMS Mathematics, 2026, 11(1): 243-271. doi: 10.3934/math.2026010
Training deep neural networks is often hindered by the fragility of gradient-based methods, which suffer from vanishing or exploding gradients, sensitivity to initialization, and entrapment in poor local minima. In response to these shortcomings, we introduce a new gradient-free algorithm called Quantum-Inspired Adaptive Superposition Optimization (QIASO), which views weight learning as a probabilistic superposition of candidate solutions, a fundamentally new optimization approach. In contrast to being dedicated to a single weight ensemble, QIASO maintains a distribution over several candidates, which are amplified and suppressed according to dynamically changing weights assigned to them. The variational formulation of the amplitude evolution leads to a KL-regularized formulation of their evolution, which generalizes statistical physics, information geometry, and online optimization viewpoints. To prevent invalid convergence, QIASO incorporates a stochastic perturbation operator based on quantum tunnelling into the optimizer, enabling the optimization process to overcome local minima on the loss surface and converge to the optimal solution. We provide theoretical bounds, monotone convergence of loss reduction, and almost-sure convergence to local optima with mild assumptions. Complexity analysis via empirical techniques suggests that QIASO scales more efficiently than Grover-based quantum-inspired algorithms and incurs no overhead in gradient computation compared to ADAM. The overall findings indicated that QIASO is a viable option for neural training, particularly when combined with other paradigms that utilise either large-scale or gradient-free approaches.

| [1] |
N. A. AL Ajmi, M. Shoaib, Optimization strategies in quantum machine learning: A performance analysis, Appl. Sci. , 15 (2025), 4493.https://doi.org/10.3390/app15084493 doi: 10.3390/app15084493

|
| [2] |
T. Albash, D. A. Lidar, Adiabatic quantum computation, Rev. Mod. Phys. , 90 (2018), 015002.https://doi.org/10.1103/RevModPhys.90.015002 doi: 10.1103/RevModPhys.90.015002
|
| [3] |
A. Beck, M. Teboulle, Mirror descent and nonlinear projected subgradient methods for convex optimization, Oper. Res. Lett. , 31 (2003), 167–175.https://doi.org/10.1016/S0167-6377(02)00231-6 doi: 10.1016/S0167-6377(02)00231-6
|
| [4] | J. Bergstra, Y. Bengio, Random search for hyper-parameter optimization, J. Mach. Learn. Res. , 13 (2012), 281–305. |
| [5] |
Y. Bengio, P. Simard, P. Frasconi, Learning long-term dependencies with gradient descent is difficult, IEEE Trans. Neural Netw. , 5 (1994), 157–166.https://doi.org/10.1109/72.279181 doi: 10.1109/72.279181
|
| [6] |
J. Biamonte, P. Wittek, N. Pancotti, P. Rebentrost, N. Wiebe, S. Lloyd, Quantum machine learning, Nature, 549 (2017), 195–202.https://doi.org/10.1038/nature23474 doi: 10.1038/nature23474
|
| [7] |
S. Bubeck, Convex optimization: Algorithms and complexity, Found. Trends Mach. Learn. , 8 (2015), 231–357.https://doi.org/10.1561/2200000050 doi: 10.1561/2200000050
|
| [8] | S. Y. Chang, M. Cerezo, A primer on quantum machine learning, arXiv: 2511.15969, 2025.https://doi.org/10.48550/arXiv.2511.15969 |
| [9] | A. Das, B. Chakrabarti, Quantum annealing and related optimization methods, Berlin: Springer, 2005.https://doi.org/10.1007/11526216 |
| [10] | J. Duchi, E. Hazan, Y. Singer, Adaptive subgradient methods for online learning and stochastic optimization, J. Mach. Learn. Res. , 12 (2011), 2121–2159. |
| [11] | E. Farhi, J. Goldstone, S. Gutmann, M. Sipser, Quantum computation by adiabatic evolution, arXiv: quant-ph/0001106, 2000.https://doi.org/10.48550/arXiv.quant-ph/0001106 |
| [12] | E. Hazan, Introduction to online convex optimization, The MIT Press, 2022. |
| [13] |
J. Heaton, Ian Goodfellow, Yoshua Bengio, and Aaron Courville: Deep learning, Genet. Program. Evolvable Mach. , 19 (2018), 305–307.https://doi.org/10.1007/s10710-017-9314-z doi: 10.1007/s10710-017-9314-z
|
| [14] |
T. Kadowaki, H. Nishimori, Quantum annealing in the transverse Ising model, Phys. Rev. E, 58 (1998), 5355–5363.https://doi.org/10.1103/PhysRevE.58.5355 doi: 10.1103/PhysRevE.58.5355
|
| [15] | D. Kingma, J. B. Adam, A method for stochastic optimization, In: International conference on learning representations (ICLR), 2015. |
| [16] |
J. Kivinen, M. K. Warmuth, Exponentiated gradient versus gradient descent for linear predictors, Inf. Comput. , 132 (1997), 1–63.https://doi.org/10.1006/inco.1996.2612 doi: 10.1006/inco.1996.2612
|
| [17] | A. Krizhevsky, G. Hinton, Learning multiple layers of features from tiny images, 2009. |
| [18] |
S. Kirkpatrick, C. D. Gelatt, M. P. Vecchi, Optimization by simulated annealing, Science, 220 (1983), 671–680.https://doi.org/10.1126/science.220.4598.671 doi: 10.1126/science.220.4598.671
|
| [19] | Y. LeCun, Y. Bengio, Convolutional networks for images, speech, and time series, In: The handbook of brain theory and neural networks, Cambridge: MIT Press, 1998. |
| [20] | S. Li, M. S. Salek, B. Roy, Y. Wang, M. Chowdhury, Quantum-inspired weight-constrained neural network: Reducing variable numbers by 100x compared to standard neural networks, arXiv preprint arXiv: 2412.19355, 2024.https://doi.org/10.48550/arXiv.2412.19355 |
| [21] | S. Liu, B. Kailkhura, P. Y. Chen, P. Ting, S. Chang, L. Amini, Zeroth-order stochastic variance reduction for nonconvex optimization, In: 32nd Conference on neural information processing systems (NeurIPS 2018), 2018. |
| [22] | M. Mohseni, P. Rebentrost, S. Lloyd, A. Aspuru-Guzik, Environment-assisted quantum walks in photosynthetic energy transfer, J. Chem. Phys., 129 (2008), 174106.https://doi.org/10.1063/1.3002335 |
| [23] |
S. M. A. Rizvi, U. I. Paracha, U. Khalid, K. Lee, H. Shin, Quantum machine learning: Towards hybrid quantum-classical vision models, Mathematics, 13 (2025), 2645.https://doi.org/10.3390/math13162645 doi: 10.3390/math13162645
|
| [24] |
H. Sajjad, M. Alshanbari, M. M. A. Almazah, H. Louati, S. Rauf, Adaptive Grover-driven optimization for quantum-inspired deep learning: A gradient-free training framework, AIMS Mathematics, 10 (2025), 26568–26592.https://doi.org/10.3934/math.20251168 doi: 10.3934/math.20251168
|
| [25] | T. Salimans, J. Ho, X. Chen, S. Sidor, I. Sutskever, Evolution strategies as a scalable alternative to reinforcement learning, arXiv preprint arXiv: 1703.03864, 2017.https://doi.org/10.48550/arXiv.1703.03864 |
| [26] | M. Schuld, F. Petruccione, Supervised learning with quantum computers, Cham: Springer, 2018.https://doi.org/10.1007/978-3-319-96424-9 |
| [27] |
T. Si, P. B. C. Miranda, U. Nandi, N. D. Jana, U. Maulik, S. Mallik, et al., QSHO: Quantum spotted hyena optimizer for global optimization, Artif. Intell. Rev. , 58 (2025), 71.https://doi.org/10.1007/s10462-024-11072-y doi: 10.1007/s10462-024-11072-y
|
| [28] | D. Wierstra, T. Schaul, T. Glasmachers, Y. Sun, J. Peters, J. Schmidhuber, Natural evolution strategies, J. Mach. Learn. Res. , 15 (2014), 949–980. |
| [29] | H. Xiao, K. Rasul, R. Vollgraf, Fashion-MNIST: A novel image dataset for benchmarking machine learning algorithms, arXiv preprint arXiv: 1708.07747, 2017.https://doi.org/10.48550/arXiv.1708.07747 |
| [30] | R. Zhang, Z. Jiao, H. Zhang, X. Li, Manifold neural network with non-gradient optimization, IEEE Trans. Pattern Anal. Mach. Intell. , 45 (2022), 3986–3993. |
Figures(8) / Tables(6)

Irsa Sajjad, Mashail M. AL Sobhi. The quantum-inspired adaptive superposition optimization for neural network training[J]. AIMS Mathematics, 2026, 11(1): 243-271. doi: 10.3934/math.2026010







 DownLoad:
DownLoad: