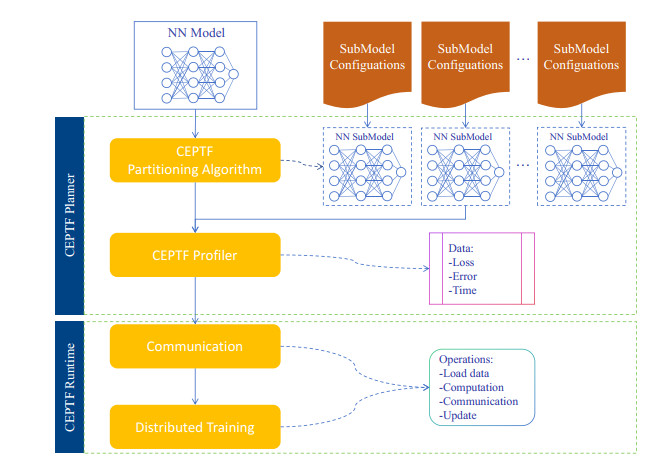
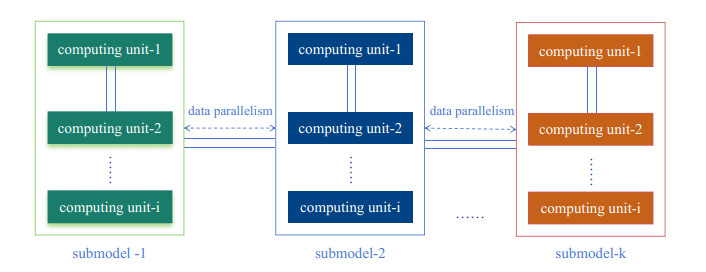
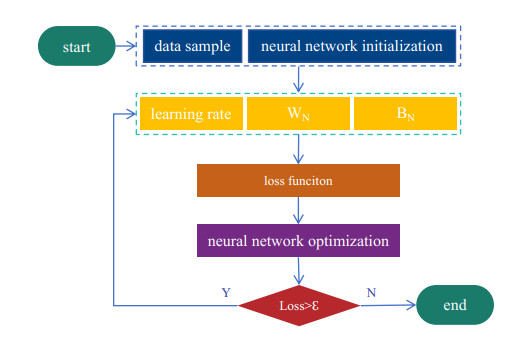
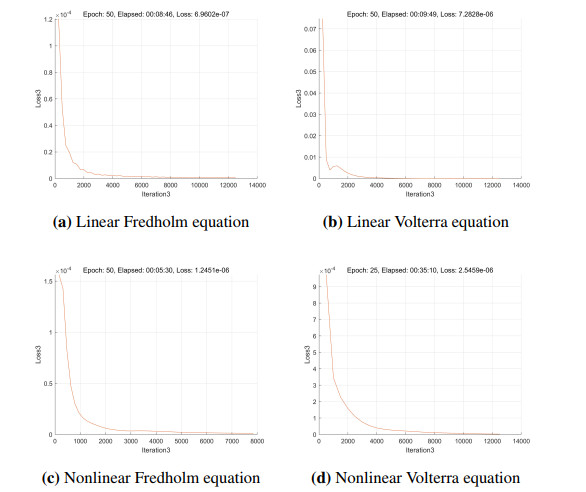
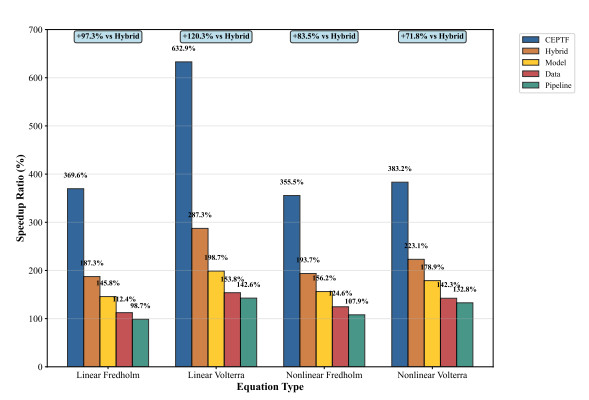
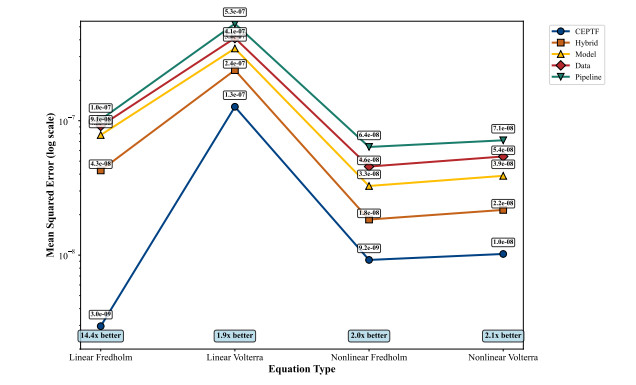
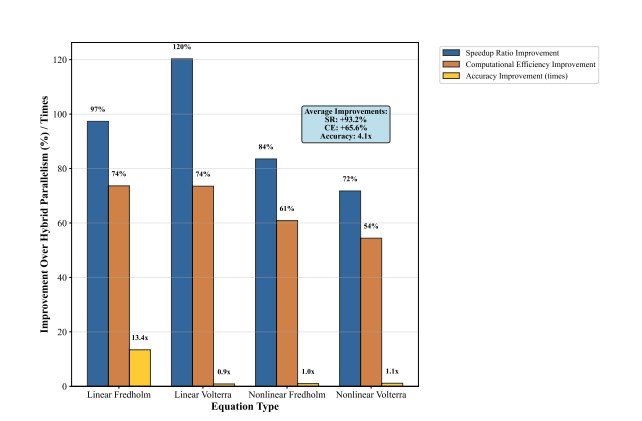
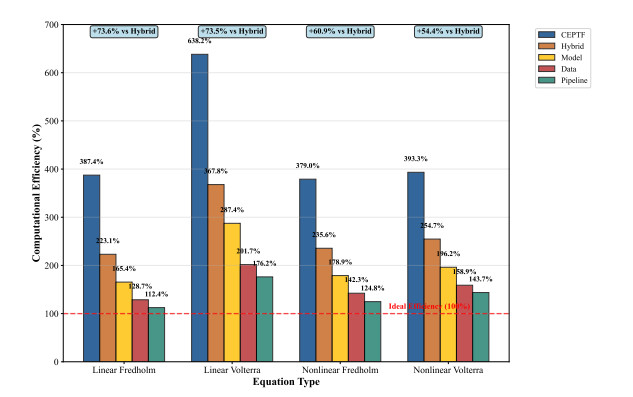
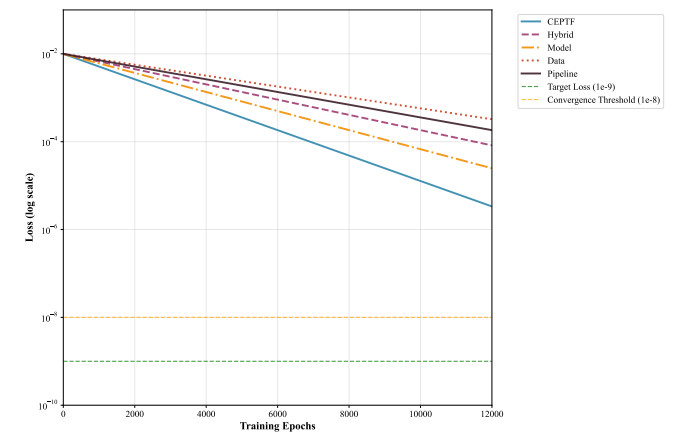
Solving integral equations via deep learning encounters significant computational bottlenecks when order-reduction techniques transform problems into strongly coupled differential systems requiring multi-network collaborative training. While achieving high accuracy, existing distributed training paradigms exhibit fundamental limitations. Data parallelism suffers from prohibitive gradient synchronization overhead in multi-network coupling scenarios, while pipeline parallelism struggles with bubble inefficiencies in the shallow architectures typical of scientific computing. To overcome these challenges, we proposed the computationally efficient parallel training framework (CEPTF), which introduces three key innovations. A unified computational efficiency metric balancing acceleration gains with resource costs, mathematical-aware dynamic partitioning that adapts to equation structure and hardware constraints, and hybrid parallelism integrating optimized communication topologies with constraint-preserving synchronization. Comprehensive validation across linear/nonlinear Fredholm/Volterra equations demonstrates that CEPTF achieves 3.18$ \times $ to 6.32$ \times $ acceleration (318.6%–632.9% speedup ratio) while maintaining solution accuracy of $ 10^{-7} $ to $ 10^{-9} $ magnitude, outperforming established parallel paradigms by 1.8$ \times $ to 3.2$ \times $ in speedup ratios and 42%–67% in computational efficiency. The framework's adaptability to heterogeneous computing environments and robust performance under challenging conditions, including singular kernels and irregular domains, establishes a new paradigm for scalable scientific machine learning.
Citation: Zhiyuan Ren, Dong Liu, Zhen Liao, Shijie Zhou, Qihe Liu. A computationally efficient parallel training framework for solving integral equations using deep learning methods[J]. AIMS Mathematics, 2025, 10(10): 24115-24152. doi: 10.3934/math.20251070
Solving integral equations via deep learning encounters significant computational bottlenecks when order-reduction techniques transform problems into strongly coupled differential systems requiring multi-network collaborative training. While achieving high accuracy, existing distributed training paradigms exhibit fundamental limitations. Data parallelism suffers from prohibitive gradient synchronization overhead in multi-network coupling scenarios, while pipeline parallelism struggles with bubble inefficiencies in the shallow architectures typical of scientific computing. To overcome these challenges, we proposed the computationally efficient parallel training framework (CEPTF), which introduces three key innovations. A unified computational efficiency metric balancing acceleration gains with resource costs, mathematical-aware dynamic partitioning that adapts to equation structure and hardware constraints, and hybrid parallelism integrating optimized communication topologies with constraint-preserving synchronization. Comprehensive validation across linear/nonlinear Fredholm/Volterra equations demonstrates that CEPTF achieves 3.18$ \times $ to 6.32$ \times $ acceleration (318.6%–632.9% speedup ratio) while maintaining solution accuracy of $ 10^{-7} $ to $ 10^{-9} $ magnitude, outperforming established parallel paradigms by 1.8$ \times $ to 3.2$ \times $ in speedup ratios and 42%–67% in computational efficiency. The framework's adaptability to heterogeneous computing environments and robust performance under challenging conditions, including singular kernels and irregular domains, establishes a new paradigm for scalable scientific machine learning.

| [1] |
A. Voulodimos, N. Doulamis, A. D. Doulamis, E. Protopapadakis, Deep learning for computer vision: A brief review, Comput. Intell. Neurosc., 2018 (2018), 7068349. http://doi.org/10.1155/2018/7068349 doi: 10.1155/2018/7068349

|
| [2] |
S. P. González-Sabbagh, A. Robles-Kelly, A survey on underwater computer vision, ACM Comput. Surv., 55 (2023), 1–39. http://doi.org/10.1145/3578516 doi: 10.1145/3578516
|
| [3] |
X. Zhao, L. M. Wang, Y. F. Zhang, X. M. Han, M. Deveci, M. Parmar, A review of convolutional neural networks in computer vision, Artif. Intell. Rev., 57 (2024), 99. https://doi.org/10.1007/s10462-024-10721-6 doi: 10.1007/s10462-024-10721-6
|
| [4] |
J. P. Bharadiya, A comprehensive survey of deep learning techniques for natural language processing, European Journal of Technology, 7 (2023), 58–66. http://doi.org/10.47672/ejt.1473 doi: 10.47672/ejt.1473
|
| [5] |
D. Khurana, A. Koli, K. Khatter, S. Singh, Natural language processing: state of the art, current trends and challenges, Multimed. Tools Appl., 82 (2023), 3713–3744. http://doi.org/10.1007/S11042-022-13428-4 doi: 10.1007/S11042-022-13428-4
|
| [6] |
W. Khan, A. Daud, K. Khan, S. Muhammad, R. Haq, Exploring the frontiers of deep learning and natural language processing: A comprehensive overview of key challenges and emerging trends, Natural Language Processing Journal, 4 (2023), 100026. https://doi.org/10.1016/j.nlp.2023.100026 doi: 10.1016/j.nlp.2023.100026
|
| [7] | J. Z. Wang, P. P. Huang, H. Zhao, Z. B. Zhang, B. Q. Zhao, D. L. Lee, Billion-scale commodity embedding for e-commerce recommendation in Alibaba, Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining (KDD 2018), London, United Kingdom, 2018, 839–848. http://doi.org/10.1145/3219819.3219890 |
| [8] |
Z. H. Zhao, W. Q. Fan, J. T. Li, Y. Q. Liu, X. W. Mei, Y. Q. Wang, Recommender systems in the era of large language models (LLMs), IEEE T. Knowl. Data En., 36 (2024), 6889–6907. http://doi.org/10.1109/TKDE.2024.3392335 doi: 10.1109/TKDE.2024.3392335
|
| [9] | T. B. Brown, B. Mann, N. Ryder, M. Subbiah, J. Kaplan, P. Dhariwal, et al., Language models are few-shot learners, Proceedings of the 34th International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 2020, 1877–1901. |
| [10] | R. Yang, L. Song, Y. W. Li, S. J. Zhao, Y. X. Ge, X. Li, et al., Gpt4tools: Teaching large language model to use tools via self-instruction, Proceedings of the 37th International Conference on Neural Information Processing Systems, New Orleans, LA, USA, 2023, 71995–72007. |
| [11] | S. L. Zhang, P. Z. Sun, S. F. Chen, M. Xiao, W. Q. Shao, W. W. Zhang, et al., Gpt4roi: Instruction tuning large language model on region-of-interest, Computer Vision–ECCV 2024 Workshops, Cham: Springer, 2025, 52–70. https://doi.org/10.1007/978-3-031-91813-1_4 |
| [12] | C. Beck, M. Hutzenthaler, A. Jentzen, B. Kuckuck, An overview on deep learning-based approximation methods for partial differential equations, 2022, arXiv: 2012.12348. |
| [13] | S. D. Huang, W. T. Feng, C. W. Tang, J. C. Lv, Partial differential equations meet deep neural networks: A survey, 2022, arXiv: 2211.05567. |
| [14] |
N. D. Lawrence, J. Montgomery, Accelerating AI for science: open data science for science, R. Soc. Open Sci., 11 (2024), 231130. https://doi.org/10.1098/rsos.231130 doi: 10.1098/rsos.231130
|
| [15] | A. Kukker, S. Dhar, V. Singh, V. Amitabh, S. Likhite, Deep learning for pulmonary disease identification, 2023 14th International Conference on Computing Communication and Networking Technologies (ICCCNT), Delhi, India, 2023, 1–6. http://doi.org/10.1109/ICCCNT56998.2023.10307502 |
| [16] | S. Parihar, A. Kukker, S. Dhar, V. Amitabh, V. Singh, V. Krishna, Biomedical image classification using deep reinforcement learning, 2024 Fourth International Conference on Advances in Electrical, Computing, Communication and Sustainable Technologies (ICAECT), Bhilai, India, 2024, 1–8. http://doi.org/10.1109/ICAECT60202.2024.10468733 |
| [17] | G. Pandey, R. Sharma, A. Kukker, Solanaceae family plants disease classification using machine learning techniques, 2023 IEEE Pune Section International Conference (PuneCon), Pune, India, 2023, 1–6. http://doi.org/10.1109/PuneCon58714.2023.10450081 |
| [18] | J. W. Shi, S. Y. Sun, Multiple integral solution method based on physical information neural networks, Journal of Naval University of Engineering, 36 (2024), 86–91. |
| [19] |
D. Liu, Q. L. Chen, X. Q. Wang, Deep learning solution method for transforming original functions of linear integral equations, Chinese Journal of Computational Physics, 41 (2024), 651–662. http://doi.org/10.19596/j.cnki.1001-246x.8813 doi: 10.19596/j.cnki.1001-246x.8813
|
| [20] |
D. Liu, Q. L. Chen, Z. X. Pang, M. K. Luo, S. M. Zhong, Repeated antiderivative transformation iterative deep learning solution method (R-AIM) for multi-dimensional continuity integral equations, Scientia Sinica Mathematica, 55 (2025), 1727–1746. https://doi.org/10.1360/SSM-2024-0040 doi: 10.1360/SSM-2024-0040
|
| [21] | K. Y. Tian, L. B. Qiao, B. H. Liu, G. Q. J. Jiang, S. S. Li, D. S. Li, A survey on memory-efficient large-scale model training in AI for science, 2025, arXiv: 2501.11847. |
| [22] |
Z. C. Wang, K. Liang, X. G. Bao, T. H. Wu, Quantum speedup for solving the minimum vertex cover problem based on Grover search algorithm, Quantum Inf. Process., 22 (2023), 271. https://doi.org/10.1007/s11128-023-04010-4 doi: 10.1007/s11128-023-04010-4
|
| [23] |
Y. Guan, T. T. Fang, D. K. Zhang, C. M. Jin, Solving Fredholm integral equations using deep learning, International Journal of Applied and Computational Mathematics, 8 (2022), 87. https://doi.org/10.1007/s40819-022-01288-3 doi: 10.1007/s40819-022-01288-3
|
| [24] |
R. Guo, T. Shan, X. Q. Song, M. K. Li, F. Yang, S. H. Xu, et al., Physics embedded deep neural network for solving volume integral equation: 2-D case, IEEE T. Antenn. Propag., 70 (2021), 6135–6147. http://doi.org/10.1109/TAP.2021.3070152 doi: 10.1109/TAP.2021.3070152
|
| [25] | J. Sun, Y. H. Liu, Y. Z. Wang, Z. H. Yao, X. P. Zheng, BINN: A deep learning approach for computational mechanics problems based on boundary integral equations, 2023, arXiv: 2301.04480. |
| [26] |
M. Raissi, P. Perdikaris, G. E. Karniadakis, Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations, J. Comput. Phys., 378 (2019), 686–707. http://doi.org/10.1016/J.JCP.2018.10.045 doi: 10.1016/J.JCP.2018.10.045
|
| [27] | W. M. Han, K. E. Atkinson, Theoretical numerical analysis: A functional analysis framework, 3 Eds., New York: Springer, 2009. https://doi.org/10.1007/978-1-4419-0458-4 |
| [28] |
Belytschko, TED, The finite element method: linear static and dynamic finite element analysis, Computer-Aided Civil and Infrastructure Engineering, 4 (1989), 245–246. https://doi.org/10.1111/j.1467-8667.1989.tb00025.x doi: 10.1111/j.1467-8667.1989.tb00025.x
|
| [29] | M. Li, D. G. Andersen, J. W. Park, A. J. Smola, A. Ahmed, V. Josifovski, et al., Scaling distributed machine learning with the parameter server, Proceedings of the 11th USENIX Symposium on Operating Systems Design and Implementation, Broomfield, CO, 2014, 583–598. |
| [30] | W. Dai, A. Kumar, J. L. Wei, Q. R. Ho, G. Gibson, E. P. Xing, High-performance distributed ML at scale through parameter server consistency models, Proceedings of the AAAI Conference on Artificial Intelligence, Austin, Texas, 2015, 79–87. |
| [31] | A. Sergeev, M. Del Balso, Horovod: fast and easy distributed deep learning in TensorFlow, 2018, arXiv: 1802.05799. |
| [32] | J. K. Kim, Q. R. Ho, S. Lee, X. Zheng, W. Dai, G. A. Gibson, et al., STRADS: a distributed framework for scheduled model parallel machine learning, Proceedings of the Eleventh European Conference on Computer Systems, London, United Kingdom, 2016, 1–16. http://doi.org/10.1145/2901318.2901331 |
| [33] | C.-C. Chen, C.-L. Yang, H.-Y. Cheng, Efficient and robust parallel DNN training through model parallelism on multi-GPU platform, 2019, arXiv: 1809.02839. |
| [34] | S. Lee, J. K. Kim, X. Zheng, Q. R. Ho, G. A. Gibson, E. P. Xing, On model parallelization and scheduling strategies for distributed machine learning, Proceedings of the 28th International Conference on Neural Information Processing Systems, Montreal, Quebec, Canada, 2014, 2834–2842. |
| [35] | D. Narayanan, A. Harlap, A. Phanishayee, V. Seshadri, N. R. Devanur, G. R. Ganger, et al., PipeDream: Generalized pipeline parallelism for DNN training, Proceedings of the 27th ACM Symposium on Operating Systems Principles, Huntsville, ON, Canada, 2019, 1–15. http://doi.org/10.1145/3341301.3359646 |
| [36] | Y. P. Huang, Y. L. Cheng, A. Bapna, O. Firat, M. X. Chen, D. H. Chen, et al., GPipe: Efficient training of giant neural networks using pipeline parallelism, Proceedings of the 33rd International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 2019, 103–112. |
| [37] | J. Zhan, J. H. Zhang, Pipe-Torch: Pipeline-based distributed deep learning in a GPU cluster with heterogeneous networking, 2019 Seventh International Conference on Advanced Cloud and Big Data (CBD), Suzhou, China, 2019, 55–60. http://doi.org/10.1109/CBD.2019.00020 |
| [38] | C. Oh, Z. Zheng, X. P. Shen, J. D. Zhai, Y. M. Yi, GOPipe: A granularity-oblivious programming framework for pipelined stencil executions on GPU, Proceedings of the International Conference on Parallel Architectures and Compilation Techniques, Virtual Event, GA, USA, 2020, 43–54. https://doi.org/10.1145/3410463.3414656 |
| [39] | Z. Zheng, C. Oh, J. D. Zhai, X. P. Shen, Y. M. Yi, W. G. Chen, VersaPipe: A versatile programming framework for pipelined computing on GPU, 2017 50th Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), Boston, MA, USA, 2017, 587–599. |
| [40] | B. W. Yang, J. Zhang, J. Li, C. Ré, C. R. Aberger, C. De Sa, PipeMare: Asynchronous pipeline parallel DNN training, Proceedings of the Fourth Conference on Machine Learning and Systems (MLSys 2021), San Jose, CA, USA, 2021, 269–296. |
| [41] |
X. Wu, Z. C. Wang, T. H. Wu, X. G. Bao, Solving the family traveling salesperson problem in the Adleman–Lipton model based on DNA computing, IEEE T. NanoBiosci., 21 (2021), 75–85. http://doi.org/10.1109/TNB.2021.3109067 doi: 10.1109/TNB.2021.3109067
|
| [42] | X. Y. Ye, Z. Q. Lai, S. W. Li, L. Cai, D. Sun, L. B. Qiao, et al., Hippie: A data-paralleled pipeline approach to improve memory-efficiency and scalability for large DNN training, Proceedings of the 50th International Conference on Parallel Processing, Lemont, IL, USA, 2021, 1–10. http://doi.org/10.1145/3472456.3472497 |
| [43] |
D. S. Li, S. W. Li, Z. Q. Lai, Y. Q. Fu, X. Y. Ye, L. Cai, et al., A memory-efficient hybrid parallel framework for deep neural network training, IEEE T. Parall. Distr., 35 (2024), 577–591. http://doi.org/10.1109/TPDS.2023.3343570 doi: 10.1109/TPDS.2023.3343570
|
| [44] |
D. S. Hulbert, S. Reich, Asymptotic behavior of solutions to nonlinear Volterra integral equations, J. Math. Anal. Appl., 104 (1984), 155–172. https://doi.org/10.1016/0022-247X(84)90040-4 doi: 10.1016/0022-247X(84)90040-4
|
| [45] |
L. Yuan, Y.-Q. Ni, X.-Y. Deng, S. Hao, A-PINN: Auxiliary physics informed neural networks for forward and inverse problems of nonlinear integro-differential equations, J. Comput. Phys., 462 (2022), 111260. http://doi.org/10.1016/J.JCP.2022.111260 doi: 10.1016/J.JCP.2022.111260
|
| [46] |
N. Bonneel, D. Coeurjolly, J.-C. Iehl, V. Ostromoukhov, Sobol sequences with guaranteed-quality 2D projections, ACM T. Graphic., 44 (2025), 1–16. https://doi.org/10.1145/3730821 doi: 10.1145/3730821
|
| [47] | A. G. Baydin, B. A. Pearlmutter, A. A. Radul, J. M. Siskind, Automatic differentiation in machine learning: A survey, J. Mach. Learn. Res., 18 (2017), 1–43. |
| [48] |
Z. Q. Lai, S. W. Li, X. D. Tang, K. S. Ge, W. J. Liu, Y. B. Duan, et al., Merak: An efficient distributed DNN training framework with automated 3D parallelism for giant foundation models, IEEE T. Parall. Distr., 34 (2023), 1466–1478. http://doi.org/10.1109/TPDS.2023.3247001 doi: 10.1109/TPDS.2023.3247001
|
| [49] |
C. K. Gitonga, L. G. Mugao, Domain-adaptive pretraining of transformer-based language models on mdical texts: A high-performance computing experiment, European Journal of Information Technologies and Computer Science, 5 (2025), 1–9. https://doi.org/10.24018/compute.2025.5.2.149 doi: 10.24018/compute.2025.5.2.149
|

Figures(12) / Tables(10)

Zhiyuan Ren, Dong Liu, Zhen Liao, Shijie Zhou, Qihe Liu. A computationally efficient parallel training framework for solving integral equations using deep learning methods[J]. AIMS Mathematics, 2025, 10(10): 24115-24152. doi: 10.3934/math.20251070







 DownLoad:
DownLoad: