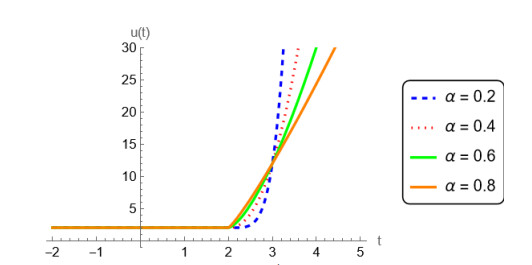
In this study, we investigate the stability and asymptotic stability properties of Caputo fractional time-dependent systems with delay by employing vector Lyapunov functions. Utilizing the Caputo fractional Dini derivative on Lyapunov-like functions, along with a new comparison theorem and differential inequalities, we derive and prove sufficient conditions for the stability and asymptotic stability of these complex systems. An example is included to showcase the method's practicality and to specifically illustrate its advantages over scalar Lyapunov functions. Our results improves, extends, and generalizes several existing findings in the literature.
Citation: Jonas Ogar Achuobi, Edet Peter Akpan, Reny George, Austine Efut Ofem. Stability analysis of Caputo fractional time-dependent systems with delay using vector lyapunov functions[J]. AIMS Mathematics, 2024, 9(10): 28079-28099. doi: 10.3934/math.20241362
In this study, we investigate the stability and asymptotic stability properties of Caputo fractional time-dependent systems with delay by employing vector Lyapunov functions. Utilizing the Caputo fractional Dini derivative on Lyapunov-like functions, along with a new comparison theorem and differential inequalities, we derive and prove sufficient conditions for the stability and asymptotic stability of these complex systems. An example is included to showcase the method's practicality and to specifically illustrate its advantages over scalar Lyapunov functions. Our results improves, extends, and generalizes several existing findings in the literature.

| [1] |
J. B. Hu, G. P. Lu, S. B. Zhang, L. D. Zhao, Lyapunov stability theorem about fractional system without and with delay, Commun. Nonlinear Sci. Numer. Simul., 20 (2015), 905–913. https://doi.org/10.1016/j.cnsns.2014.05.013 doi: 10.1016/j.cnsns.2014.05.013

|
| [2] | A. A. Kilbas, H. M. Srivastava, J. J. Trujillo, Theory and applications of fractional differential equations, Elsevier, 2006. |
| [3] | K. S. Miller, B. Ross, An introduction to the fractional calculus and fractional differential equations, New York: Wiley, 1993. |
| [4] | I. Podlubny, Fractional differential equations: An introduction to fractional derivatives, fractional differential equations, to methods of their solution and some of their applications, San Diego: Academic Press, 1999. |
| [5] |
R. P. Agarwal, Y. Zhou, Y. He, Existence of fractional neutral functional differential equations, Comput. Math. Appl., 59 (2010), 1095–1100. https://doi.org/10.1016/j.camwa.2009.05.010 doi: 10.1016/j.camwa.2009.05.010
|
| [6] |
M. Benchohra, J. Henderson, S. K. Ntouyas, A. Ouahab, Existence results for fractional order functional differential equations with infinite delay, J. Math. Anal. Appl., 338 (2008), 1340–1350. https://doi.org/10.1016/j.jmaa.2007.06.021 doi: 10.1016/j.jmaa.2007.06.021
|
| [7] |
A. Chauhan, J. Dabas, Local and global existence of mild solution to an impulsive fractional functional integro-differential equation with nonlocal condition, Commun. Nonlinear Sci. Numer. Simul., 19 (2014), 821–829. https://doi.org/10.1016/j.cnsns.2013.07.025 doi: 10.1016/j.cnsns.2013.07.025
|
| [8] |
T. Jankowski, Existence results to delay fractional differential equations with nonlinear boundary conditions, Appl. Math. Comput., 219 (2013), 9155–9164. https://doi.org/10.1016/j.amc.2013.03.045 doi: 10.1016/j.amc.2013.03.045
|
| [9] |
W. Deng, C. Li, J. Lü, Stability analysis of linear fractional differential system with multiple time delays, Nonlinear Dyn., 48 (2007), 409–416. https://doi.org/10.1007/s11071-006-9094-0 doi: 10.1007/s11071-006-9094-0
|
| [10] |
J. Čermák, Z. Došlá, T. Kisela, Fractional differential equations with a constant delay: Stability and asymptotics of solutions, Appl. Math. Comput., 298 (2017), 336–350. https://doi.org/10.1016/j.amc.2016.11.016 doi: 10.1016/j.amc.2016.11.016
|
| [11] |
H. T. Tuan, H. Trinh, A linearized stability theorem for nonlinear delay fractional differential equations, IEEE Trans. Automat. Control, 63 (2018), 3180–3186. https://doi.org/10.1109/TAC.2018.2791485 doi: 10.1109/TAC.2018.2791485
|
| [12] |
M. Li, J. Wang, Exploring delayed Mittag-Leffler type matrix functions to study finite time stability of fractional delay differential equations, Appl. Math. Comput., 324 (2018), 254–265. https://doi.org/10.1016/j.amc.2017.11.063 doi: 10.1016/j.amc.2017.11.063
|
| [13] |
N. T. Thanh, V. N. Phat, P. Niamsup, New finite-time stability analysis of singular fractional differential equations with time-varying delay, Fract. Calc. Appl. Anal., 23 (2020), 504–519. https://doi.org/10.1515/fca-2020-0024 doi: 10.1515/fca-2020-0024
|
| [14] |
Y. Chen, K. L. Moore, Analytical stability bound for a class of delayed fractional-order dynamic systems, Nonlinear Dyn., 29 (2002), 191–200. https://doi.org/10.1023/A:1016591006562 doi: 10.1023/A:1016591006562
|
| [15] |
E. Kaslik, S. Sivasundaram, Analytical and numerical methods for the stability analysis of linear fractional delay differential equation, J. Comput. Appl. Math., 236 (2012), 4027–4041. https://doi.org/10.1016/j.cam.2012.03.010 doi: 10.1016/j.cam.2012.03.010
|
| [16] |
M. P. Lazarevic, Finite time stability analysis of PD$\alpha$ fractional control of robotic time-delay systems, Mech. Res. Commun., 33 (2006), 269–279. https://doi.org/10.1016/j.mechrescom.2005.08.010 doi: 10.1016/j.mechrescom.2005.08.010
|
| [17] |
A. Mesbahi, M. Haeri, Stability of linear time invariant fractional delay systems of retardee type in the space of delay parameters, Automatica, 49 (2013), 1287–1294. https://doi.org/10.1016/j.automatica.2013.01.041 doi: 10.1016/j.automatica.2013.01.041
|
| [18] |
S. B. Bhalekar, Stability analysis of a class of fractional delay differential equations, Pramana J. Phys., 81 (2013), 215–224. https://doi.org/10.1007/s12043-013-0569-5 doi: 10.1007/s12043-013-0569-5
|
| [19] |
V. Lakshmikantham, Theory of fractional functional differential equations, Nonlinear Anal. Theory Methods Appl., 69 (2008), 3337–3343. https://doi.org/10.1016/j.na.2007.09.025 doi: 10.1016/j.na.2007.09.025
|
| [20] |
I. Stamova, Global Mittag-Leffler stability and synchronization of impulsive fractional-order neural networks with time-varying delays, Nonlinear Dyn., 77 (2014), 1251–1260. https://doi.org/10.1007/s11071-014-1375-4 doi: 10.1007/s11071-014-1375-4
|
| [21] | S. J. Sadati, R. Ghaderi, N. Ranjbar, Some fractional comparison results and stability theorem for fractional time delay systems, Rom. Rep. Phys., 65 (2013), 94–102. |
| [22] | R. Agarwal, R. Almeida, S. Hristova, D. O'Regan, Caputo fractional differential equation with state dependent delay and practical stability, Dyn. Syst. Appl., 28 (2019), 715–742. |
| [23] |
Y. Li, Y. Chen, I. Podlubny, Stability of fractional-order nonlinear dynamic systems: Lyapunov direct method and generalized Mittag-Leffler stability, Comput. Math. Appl., 59 (2010), 1810–1821. https://doi.org/10.1016/j.camwa.2009.08.019 doi: 10.1016/j.camwa.2009.08.019
|
| [24] |
R. Agarwal, S. Hristova, D. O'Regan, Lyapunov functions and strict stability of Caputo fractional differential equations, Adv. Differ. Equ., 2015 (2015), 346. https://doi.org/10.1186/s13662-015-0674-5 doi: 10.1186/s13662-015-0674-5
|
| [25] |
R. Agarwal, S. Hristova, D. O'regan, Lyapunov functions and stability of Caputo fractional differential equations with delays, Differ. Equ. Dyn. Syst., 30 (2022), 513–534. https://doi.org/10.1007/s12591-018-0434-6 doi: 10.1007/s12591-018-0434-6
|
| [26] |
R. Agarwal, D. O'Regan, S. Hristova, Stability of Caputo fractional differential equations by Lyapunov functions, Appl. Math., 60 (2015), 653–676. https://doi.org/10.1007/s10492-015-0116-4 doi: 10.1007/s10492-015-0116-4
|
| [27] |
R. Agarwal, S. Hristova, D. O'Regan, A survey of Lyapunov functions, stability and impulsive Caputo fractional differential equations, Fract. Calc. Appl. Anal., 19 (2016), 290–318. https://doi.org/10.1515/fca-2016-0017 doi: 10.1515/fca-2016-0017
|
| [28] |
R. Agarwal, D. O'Regan, S. Hristova, M. Cicek, Practical stability with respect to initial time difference for Caputo fractional differential equations, Commun. Nonlinear Sci. Numer. Simul., 42 (2017), 106–120. https://doi.org/10.1016/j.cnsns.2016.05.005 doi: 10.1016/j.cnsns.2016.05.005
|
| [29] | W. M. Haddad, V. Chellaboina, Nonlinear dynamical systems and control: A Lyapunov-based approach, Princeton University Press, 2008. |
| [30] | H. K. Khalil, Control of nonlinear systems, New York: Prentice Hall, 2002. |
| [31] |
K. S. Narendra, J. Balakrishnan, A common Lyapunov function for stable LTI systems with commuting A-matrices, IEEE Trans. Automat. Control, 39 (1994), 2469–2471. https://doi.org/10.1109/9.362846 doi: 10.1109/9.362846
|
| [32] |
S. Raghavan, J. K. Hedrick, Observer design for a class of nonlinear systems, Int. J. Control, 59 (1994), 515–528. https://doi.org/10.1080/00207179408923090 doi: 10.1080/00207179408923090
|
| [33] |
E. P. Akpan, On the $\phi_0$-stability of functional differential equations, Aequationes Math., 52 (1996), 81–104. https://doi.org/10.1007/BF01818328 doi: 10.1007/BF01818328
|
Figures(1)

Jonas Ogar Achuobi, Edet Peter Akpan, Reny George, Austine Efut Ofem. Stability analysis of Caputo fractional time-dependent systems with delay using vector lyapunov functions[J]. AIMS Mathematics, 2024, 9(10): 28079-28099. doi: 10.3934/math.20241362







 DownLoad:
DownLoad: