Citation: Attia Ahmed, Sandu Adrian. A Hybrid Monte Carlo Sampling Filter for Non-Gaussian Data Assimilation[J]. AIMS Geosciences, 2015, 3(1): 41-78. doi: 10.3934/geosci.2015.1.41

| [1] | Ades M, Van Leeuwen PJ (2015) The equivalent-weights particle filter in a high-dimensional system.Quarterly J Royal Meteorological Society 141: 484-503. |
| [2] | Alexander F, Eyink G, Restrepo J (2005) Accelerated Monte Carlo for optimal estimation of time series.J Statistical Physics 119: 1331-1345. |
| [3] | Attia A, Sandu A (2014) A Sampling Filter for Non-Gaussian Data Assimilation.Cornell University, arXiv Preprint arXiv . |
| [4] | Anderson JL (1996) A method for producing and evaluating probabilistic forecasts from ensemble model integrations.J Climate 9: 1518-1530. |
| [5] | Anderson JL (2001) An ensemble adjustment Kalman filter for data assimilation.Monthly Weather Rev 129: 2884-2903. |
| [6] | Bennett A, Chua B (1994) Open-ocean modeling as an inverse problem: the primitive equations.Monthly Weather Rev 122: 1326-1336. |
| [7] | Beskos A, Pillai N, Roberts G, Sanz-Serna JM, Stuart A (2013) Optimal tuning of the hybrid Monte Carlo algorithm.Bernoulli 19: 1501-1534. |
| [8] | Beskos A, Pinski FJ, Sanz-Serna JM, Stuart A (2011) Hybrid Monte Carlo on Hilbert spaces.Stochastic Processes Applications 121. |
| [9] | Bishop CH, Etherton BJ, and Majumdar SJ (2001) Adaptive sampling with the ensemble transform Kalman filter. Part I: Theoretical aspects.Monthly Weather Rev 129: 420-436. |
| [10] | Blanes S, Casas F, Sanz-Serna JM (2014) Numerical integrators for the hybrid Monte Carlo method.SIAM J on Scientific Computing 36: A1556-A1580. |
| [11] | Burgers G, Van Leeuwen PJ, Evensen G (1998) Analysis scheme in the ensemble Kalman filter.Monthly Weather Rev 126: 1719-1724. |
| [12] | Chorin A, Morzfeld M, Tu X (2010) Implicit particle filters for data assimilation.Communications in Applied Mathematics and Computational Sci 5: 221-240. |
| [13] | Cohn SE (1997) An introduction to estimation theory.J Meteorological Society of Japan 75: 257-288. |
| [14] | S. L. Cotter and M. Dashti and A. M. Stuart (2012) Variational data assimilation using targeted random walks.Inter J numerical methods in fluids 68: 403-421. |
| [15] | Doucet A, De Freitas N, Gordon NJ (2001) An introduction to sequential Monte Carlo methods.Series Statistics For Engineering and Information Sci. Springer . |
| [16] | Duane S, Kennedy AD, Pendleton BJ, and Roweth D (1987) Hybrid Monte Carlo.Physics Letters B 195: 216-222. |
| [17] | Evensen G (1994) Sequential data assimilation with a nonlinear quasi-geostrophic model using Monte Carlo methods to forecast error statistics.J Geophysical Res: Oceans 99: 10143-10162. |
| [18] | Evensen G (2003) The ensemble Kalman filter: Theoretical formulation and practical implementation.Ocean Dynamics 53: 343-367. |
| [19] | Evensen G (2007) Data assimilation: The ensemble Kalman filter.Springer . |
| [20] | Fisher M, Courtier P (1995) Estimating the covariance matrices of analysis and forecast error in variational data assimilation.European Center for Medium-Range Weather Forecasts . |
| [21] | Girolami M, Calderhead B (2011) Riemann manifold Langevin and Hamiltonian Monte Carlo methods.J Royal Statistical Society: Series B (Statistical Methodology) 73: 123-214. |
| [22] | Gordon Neil, Salmond D, Smith A (1993) Novel approach to nonlinear/non-Gaussian Bayesian state estimation.IEE Proceedings F (Radar and Signal Processing) 140: 107-113. |
| [23] | Gu Y, Oliver D (2001) An iterative ensemble Kalman filter for multiphase fluid flow data assimilation.Spe Journal 12: 438-446. |
| [24] | Hamill TM, Whitaker JS, Snyder C (2001) Distance-dependent filtering of background error covariance estimates in an ensemble Kalman filter.Monthly Weather Rev 129: 2776-2790. |
| [25] | Hoffman MD, Gelman A (2014) The no-U-turn sampler: Adaptively setting path lengths in Hamiltonian Monte Carlo.The J Machine Learning Res 15: 1593-1623. |
| [26] | Houtekamer PL, Mitchell HL (1998) Data assimilation using an ensemble Kalman filter technique.Monthly Weather Rev 126: 796-811. |
| [27] | Houtekamer PL, Mitchell HL (2001) A sequential ensemble Kalman filter for atmospheric data assimilation.Monthly Weather Rev 129: 123-137. |
| [28] | Jardak M, Navon IM, Zupanski M (2010) Comparison of sequential data assimilation methods for the Kuramoto-Sivashinsky equation.Inter J Numerical Methods in Fluids 62: 374-402. |
| [29] | Jardak M, Navon IM, Zupanski M (2013) Comparison of Ensemble Data Assimilation methods for the shallow water equations model in the presence of nonlinear observation operators.Submitted to Tellus . |
| [30] | Kalman RE (1960) A new approach to linear filtering and prediction problems.J Fluids Engineering 82: 35-45. |
| [31] | Kalman RE, Bucy RS (1961) New results in linear filtering and prediction theory.J Fluids Engineering 83: 95-108. |
| [32] | Kalnay E (2002) Atmospheric modeling, data assimilation and predictability.Cambridge University Press . |
| [33] | Kalnay E, Yang S-C (2010) Accelerating the spin-up of ensemble Kalman filtering.Quarterly J Royal Meteorological Society 136: 1644-1651. |
| [34] | Kitagawa G (1996) Monte Carlo filter and smoother for non-Gaussian nonlinear state space models.J Computational and Graphical Statistics 5: 1-25. |
| [35] | Law K and Stuart A (2012) Evaluating data assimilation algorithms.Monthly Weather Rev 140: 3757-3782. |
| [36] | Liu JS (2008) Monte Carlo strategies in scientific computing.Springer . |
| [37] | Lorenc AC (1986) Analysis methods for numerical weather prediction.Quarterly J Royal Meteorological Society 112: 1177-1194. |
| [38] | Lorenz EN (1996) Predictability: A problem partly solved. Proc.Seminar on Predictability 1. |
| [39] | Lorenz EN, Emanuel KA (1998) Optimal sites for supplementary weather observations: Simulation with a small model.J Atmospheric Sciences 55: 399-414. |
| [40] | Metropolis N, Rosenbluth AW, Rosenbluth MN, Teller AH, Teller E (1953) Equation of state calculations by fast computing machines.J Chemical Phys 21: 1087-1092. |
| [41] | Nakano S, Ueno G, Higuchi T (2007) Merging particle filter for sequential data assimilation.Nonlinear Processes in Geophys 14: 395-408. |
| [42] | Neal RM (1993) Probabilistic inference using Markov chain Monte Carlo methods.Department of Computer Science, University of Toronto Toronto, Ontario, Canada . |
| [43] | Neal RM (2011) MCMC using Hamiltonian dynamics.Handbook of Markov Chain Monte Carlo . |
| [44] | Neta B, Giraldo FX, Navon IM (1997) Analysis of the Turkel-Zwas scheme for the twodimensional shallow water equations in spherical coordinates.J Computational Phys 133: 102-112. |
| [45] | Nino Ruiz ED, Sandu A, Anderson JL (2014) An efficient implementation of the ensemble Kalman filter based on an iterative Sherman–Morrison formula.Statistics and Computing 1-17. |
| [46] | Ott E, Hunt BR, Szunyogh I, Zimin AV, Kostelich EJ, Corazza M, Kalnay E, Patil DJ, Yorke JA (2004) A local ensemble kalman filter for atmospheric data assimilation.Tellus A 56: 415-428. |
| [47] | Sakov P, Oliver D, Bertino L (2012) An iterative EnKF for strongly nonlinear systems.Monthly Weather Rev 140: 1988-2004. |
| [48] | Sanz-Serna JM (2014) Markov chain Monte Carlo and numerical differential equations.Current Challenges in Stability Issues for Numerical Differential Equations 39-88. |
| [49] | Sanz-Serna JM, Calvo MP (1994) Numerical Hamiltonian problems Applied Mathema Mathematical Computation.Chapman & Hall London . |
| [50] | Simon E, Bertino L (2009) Application of the Gaussian anamorphosis to assimilation in a 3-D coupled physical-ecosystem model of the North Atlantic with the EnKF: a twin experiment.Ocean Science 5: 495-510. |
| [51] | Snyder C, Bengtsson T, Bickel P, Anderson J (2008) Obstacles to high-dimensional particle filtering.Monthly Weather Rev 136: 4629-4640. |
| [52] | St-Cyr A, Jablonowski C, Dennis JM, Tufo HM, Thomas SJ (2007) A comparison of two shallow water models with nonconforming adaptive grids.Monthly Weather Rev 136: 1898-1922. |
| [53] | Talagrand O, Vautard R, Strauss B (1997) Evaluation of probabilistic prediction systems.Proc. ECMWF Workshop on Predictability 1-25. |
| [54] | Tierney L (1994) Markov chains for exploring posterior distributions.The Ann Statistics 1701-1728. |
| [55] | Tippett MK, Anderson JL, Bishop CH, Hamill TM, Whitaker JS (2003) Ensemble square root filters.Monthly Weather Rev 131: 1485-1490. |
| [56] | Van Leeuwen PJ (2009) Particle filtering in geophysical systems.Monthly Weather Rev 137: 4089-4114. |
| [57] | Van Leeuwen PJ (2010) Nonlinear data assimilation in geosciences: an extremely efficient particle filter.Quarterly J Royal Meteorological Society 136: 1991-1999. |
| [58] | Van Leeuwen PJ (2011) Efficient nonlinear data-assimilation in geophysical fluid dynamics.Computers & Fluids 46: 52-58. |
| [59] | Whitaker JS, Hamill TM (2002) Ensemble data assimilation without perturbed observations.Monthly Weather Rev 130: 1913-1924. |
| [60] | Zupanski M (2005) Maximum likelihood ensemble filter: Theoretical aspects.Monthly Weather Rev 133: 1710-1726. |
| [61] | Zupanski M, Navon IM, Zupanski D (2008) The maximum likelihood ensemble filter as a nondifferentiable minimization algorithm.Quarterly J Royal Meteorological Society 134: 1039-1050. |
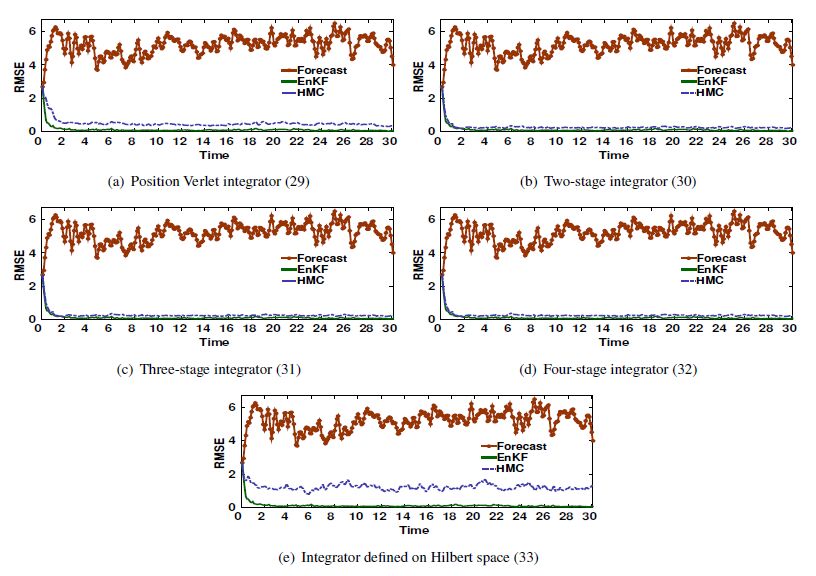
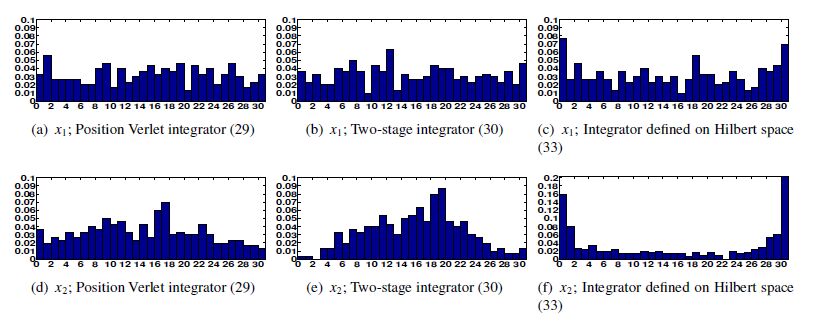
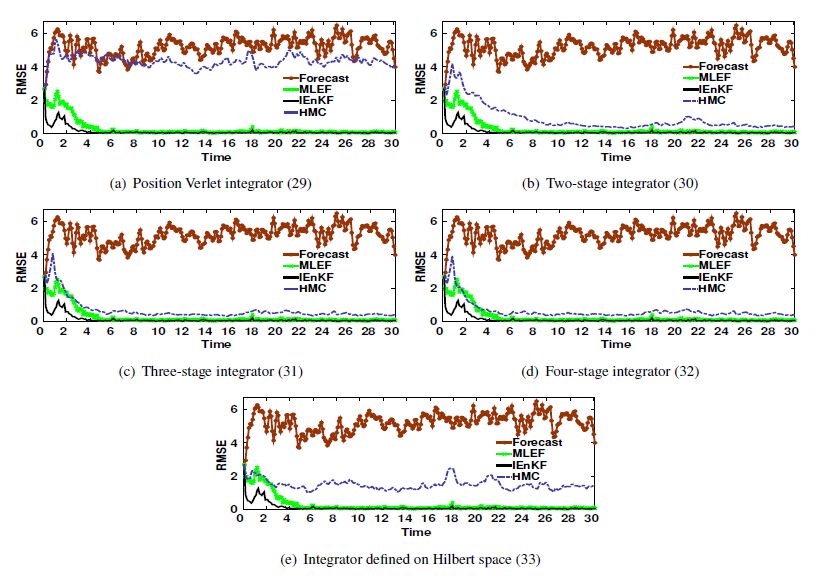
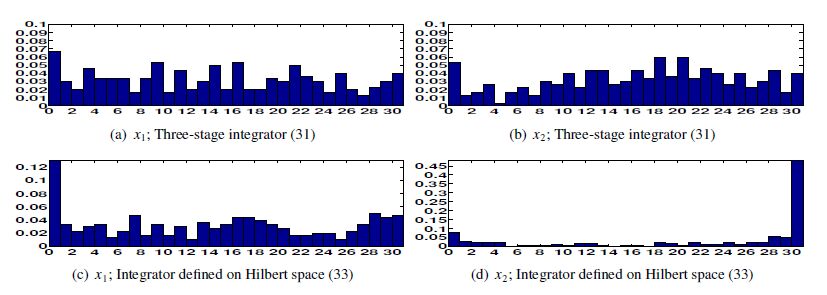
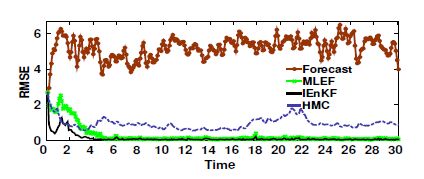

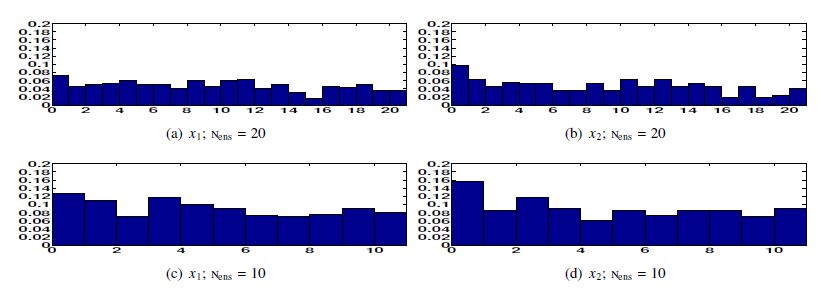
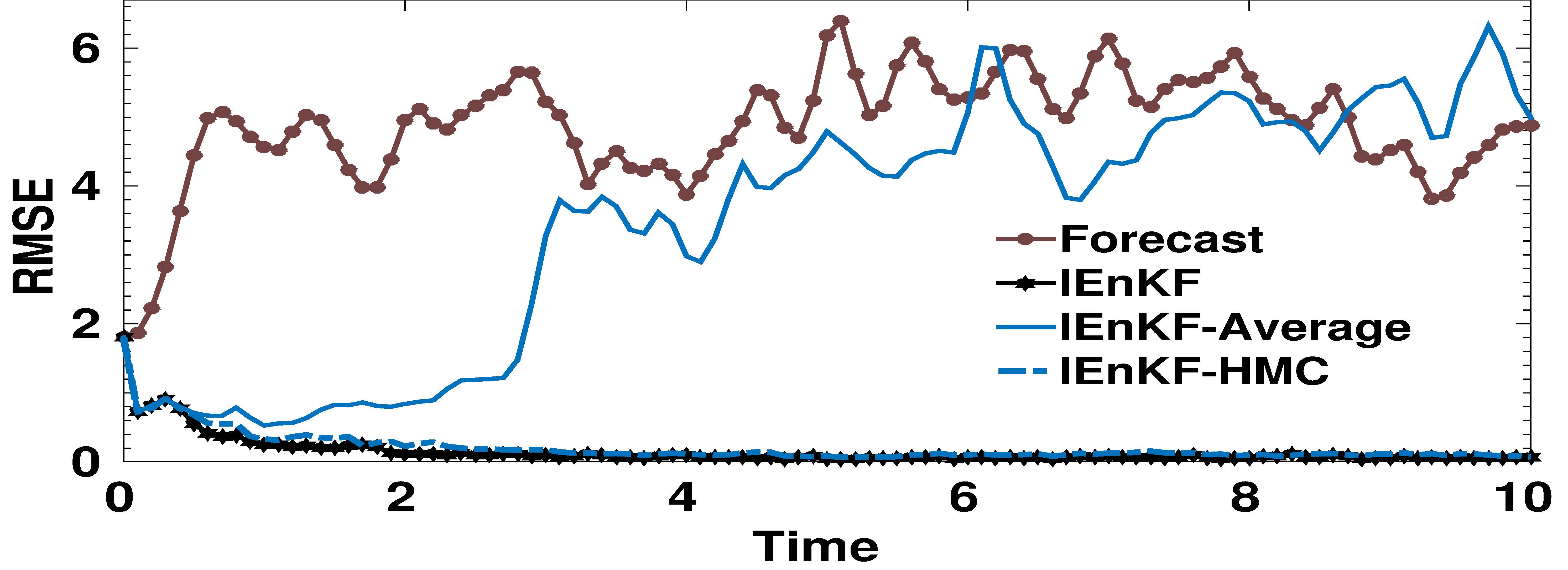
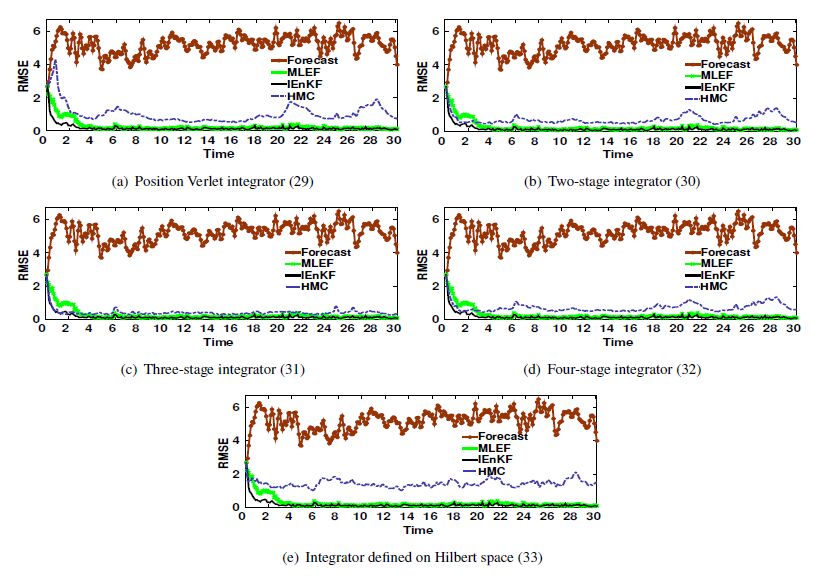

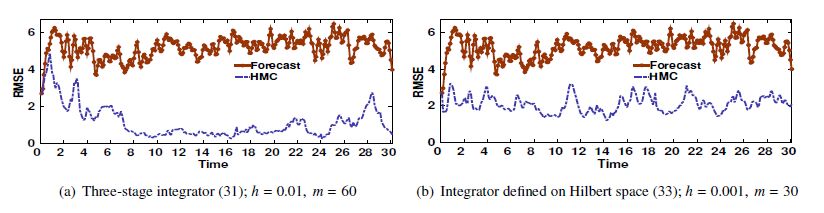
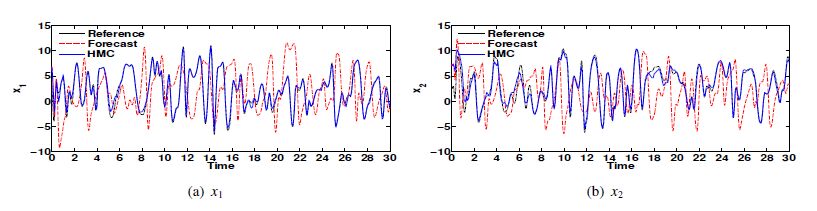
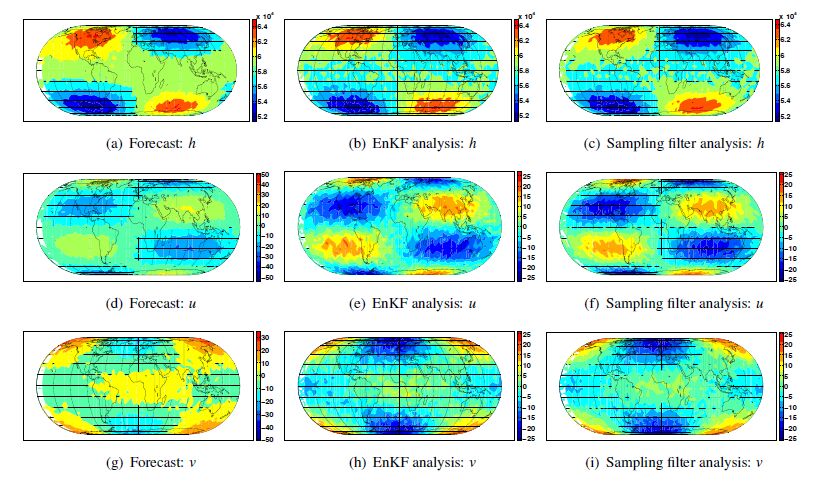
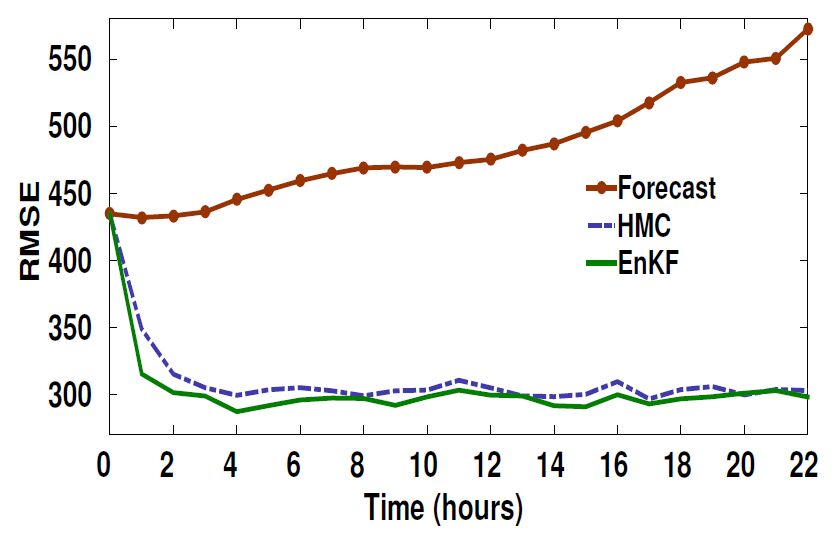
Figures(17) / Tables(3)

Attia Ahmed, Sandu Adrian. A Hybrid Monte Carlo Sampling Filter for Non-Gaussian Data Assimilation[J]. AIMS Geosciences, 2015, 3(1): 41-78. doi: 10.3934/geosci.2015.1.41







 DownLoad:
DownLoad: