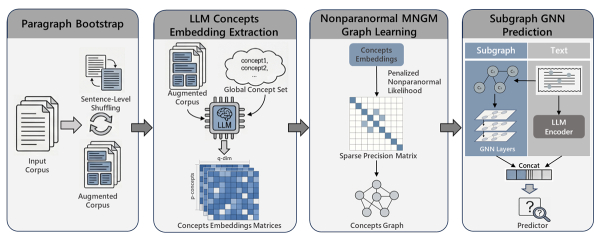
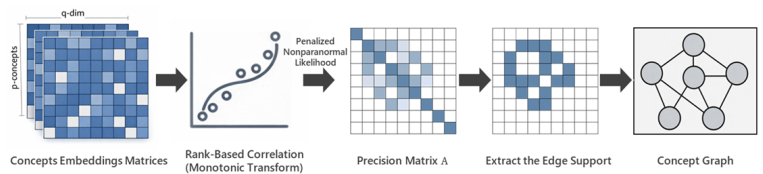
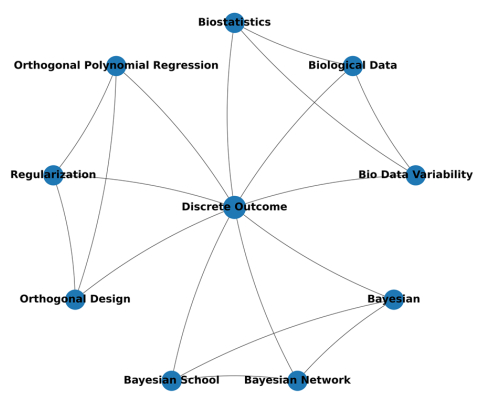
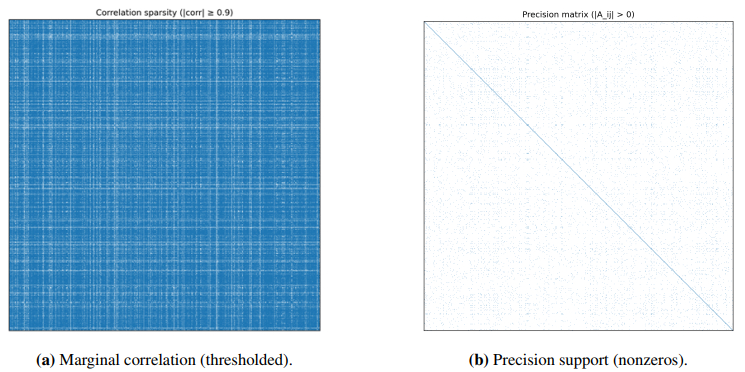
Learning conditional dependence structure among latent concepts from unstructured text can provide an interpretable graph prior for downstream models. Existing methods estimate such a concept graph by modeling GloVe-style concept embeddings as matrix-normal observations with sparse row/column precision matrices, but its Gaussian assumption is usually not satisfied for modern neural embeddings. In this paper, we extend this framework to a nonparanormal matrix-normal graphical model, allowing monotone marginal transformations while preserving the conditional-independence interpretation of the row/column precision matrix. We construct matrix-valued concept embeddings from language model representations and estimate sparse row/column precision matrices via a penalized likelihood that replaces sample covariances with rank-based correlation estimates, improving the robustness in cases with skewness and heavy tails. The resulting concept graph is defined by the support of the row precision matrix and is used as a structural prior for downstream prediction. Experiments on a salary-prediction task show that the proposed nonparanormal precision graph consistently reduces absolute-error risk and improves stability over competitors. Ablations further indicate that performance gains stem from meaningful conditional-dependence structure, rather than merely from increased model capacity.
Citation: Jizheng Lai, Jianxin Yin. Learning nonparanormal concept graphs from language representations[J]. Electronic Research Archive, 2026, 34(5): 2947-2973. doi: 10.3934/era.2026134
Learning conditional dependence structure among latent concepts from unstructured text can provide an interpretable graph prior for downstream models. Existing methods estimate such a concept graph by modeling GloVe-style concept embeddings as matrix-normal observations with sparse row/column precision matrices, but its Gaussian assumption is usually not satisfied for modern neural embeddings. In this paper, we extend this framework to a nonparanormal matrix-normal graphical model, allowing monotone marginal transformations while preserving the conditional-independence interpretation of the row/column precision matrix. We construct matrix-valued concept embeddings from language model representations and estimate sparse row/column precision matrices via a penalized likelihood that replaces sample covariances with rank-based correlation estimates, improving the robustness in cases with skewness and heavy tails. The resulting concept graph is defined by the support of the row precision matrix and is used as a structural prior for downstream prediction. Experiments on a salary-prediction task show that the proposed nonparanormal precision graph consistently reduces absolute-error risk and improves stability over competitors. Ablations further indicate that performance gains stem from meaningful conditional-dependence structure, rather than merely from increased model capacity.

| [1] | L. Ouyang, J. Wu, X. Jiang, D. Almeida, C. L. Wainwright, P. Mishkin, et al., Training language models to follow instructions with human feedback, in Proceedings of the 36th International Conference on Neural Information Processing Systems, (2022), 27730–27744. |
| [2] | J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman, et al., GPT-4 technical report, preprint, arXiv: 2303.08774. |
| [3] | A. Yang, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, et al., Qwen2.5 technical report, preprint, arXiv: 2412.15115. |
| [4] | H. Touvron, L. Martin, K. Stone, P. Albert, A. Almahairi, Y. Babaei, et al., Llama 2: Open foundation and fine-tuned chat models, preprint, arXiv: 2307.09288. |
| [5] | R. Bommasani, D. A. Hudson, E. Adeli, R. Altman, S. Arora, S. von Arx, et al., On the opportunities and risks of foundation models, preprint, arXiv: 2108.07258. |
| [6] | S. Minaee, T. Mikolov, N. Nikzad, M. Chenaghlu, R. Socher, X. Amatriain, et al., Large language models: A survey, preprint, arXiv: 2402.06196. |
| [7] | N. Godey, É. de la Clergerie, B. Sagot, Is anisotropy inherent to transformers? preprint, arXiv: 2306.07656. |
| [8] | J. Wei, X. Wang, D. Schuurmans, M. Bosma, B. Ichter, F. Xia, et al., Chain-of-thought prompting elicits reasoning in large language models, in Advances in Neural Information Processing Systems 35 (NeurIPS 2022), (2022), 1–14. |
| [9] | F. Stollenwerk, T. Stollenwerk, Better embeddings with coupled Adam, in Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics, 1 (2025), 27219–27236. https://doi.org/10.18653/v1/2025.acl-long.1321 |
| [10] | H. Liu, J. Lafferty, L. Wasserman, The nonparanormal: Semiparametric estimation of high dimensional undirected graphs, J. Mach. Learn. Res., 10 (2009), 2295–2328. |
| [11] | G. Di Luzio, G. Morelli, Dynamic conditional SKEPTIC, preprint, arXiv: 2512.11648. |
| [12] |
J. Lai, J. Yin, Learning conditional dependence graph for concepts via matrix normal graphical model, Stat. Interface, 17 (2024), 187–198. https://doi.org/10.4310/23-SII784 doi: 10.4310/23-SII784

|
| [13] |
Y. Ning, H. Liu, High-dimensional semiparametric bigraphical models, Biometrika, 100 (2013), 655–670. https://doi.org/10.1093/biomet/ast009 doi: 10.1093/biomet/ast009
|
| [14] |
L. Li, Y. Yu, W. Liang, F. Zou, A novel approach for estimating multi-attribute Gaussian copula graphical models, Stat. Probab. Lett., 222 (2025), 110413. https://doi.org/10.1016/j.spl.2025.110413 doi: 10.1016/j.spl.2025.110413
|
| [15] | T. N. Kipf, M. Welling, Semi-supervised classification with graph convolutional networks, preprint, arXiv: 1609.02907. |
| [16] | W. L. Hamilton, R. Ying, J. Leskovec, Inductive representation learning on large graphs, in Proceedings of the 31st International Conference on Neural Information Processing Systems, (2017), 1025–1035. |
| [17] | P. Veličković, G. Cucurull, A. Casanova, A. Romero, P. Liò, Y. Bengio, Graph attention networks, in 6th International Conference on Learning Representations Iclr 2018 Conference Track Proceedings, (2018), 1–12. https://doi.org/10.17863/CAM.48429 |
| [18] |
L. Chen, X. Zhu, G. Zhu, Exploiting attributes and keywords for session-based recommendation with multi-view graph neural network, Expert Syst. Appl., 296 (2026), 128990. https://doi.org/10.1016/j.eswa.2025.128990 doi: 10.1016/j.eswa.2025.128990
|
| [19] |
W. Liang, J. Cao, L. Chen, Y. Wang, J. Wu, A. Beheshti, et al., Crime prediction with missing data via spatiotemporal regularized tensor decomposition, IEEE Trans. Big Data, 9 (2023), 1392–1407. https://doi.org/10.1109/TBDATA.2023.3283098 doi: 10.1109/TBDATA.2023.3283098
|
| [20] |
J. Yin, H. Li, Model selection and estimation in the matrix normal graphical model, J. Multivar. Anal., 107 (2012), 119–140. https://doi.org/10.1016/j.jmva.2012.01.005 doi: 10.1016/j.jmva.2012.01.005
|
| [21] |
Y. Zhang, J. Song, E. C. C. Tsang, Y. Yu, Dual-branch graph transformer for node classification, Electron. Res. Arch., 33 (2025), 1093–1119. https://doi.org/10.3934/era.2025049 doi: 10.3934/era.2025049
|
| [22] |
Y. Tan, S. Li, Z. Li, A privacy preserving recommendation and fraud detection method based on graph convolution, Electron. Res. Arch., 31 (2023), 7559–7577. https://doi.org/10.3934/era.2023382 doi: 10.3934/era.2023382
|
| [23] |
C. Yang, J. Wang, S. Wei, X. Yu, A feature fusion-based attention graph convolutional network for 3D classification and segmentation, Electron. Res. Arch., 31 (2023), 7365–7384. https://doi.org/10.3934/era.2023373 doi: 10.3934/era.2023373
|
| [24] | S. Luan, C. Hua, M. Xu, Q. Lu, J. Zhu, X. Chang, et al., When do graph neural networks help with node classification? Investigating the homophily principle on node distinguishability, in Advances in Neural Information Processing Systems 36 (NeurIPS 2023), (2023), 1–13. |
| [25] | S. Luan, C. Hua, Q. Lu, J. Zhu, M. Zhao, S. Zhang, et al., Revisiting heterophily for graph neural networks, in Advances in Neural Information Processing Systems 35 (NeurIPS 2022), (2022), 1–14. |
Figures(4) / Tables(7)
Jizheng Lai, Jianxin Yin. Learning nonparanormal concept graphs from language representations[J]. Electronic Research Archive, 2026, 34(5): 2947-2973. doi: 10.3934/era.2026134







 DownLoad:
DownLoad: