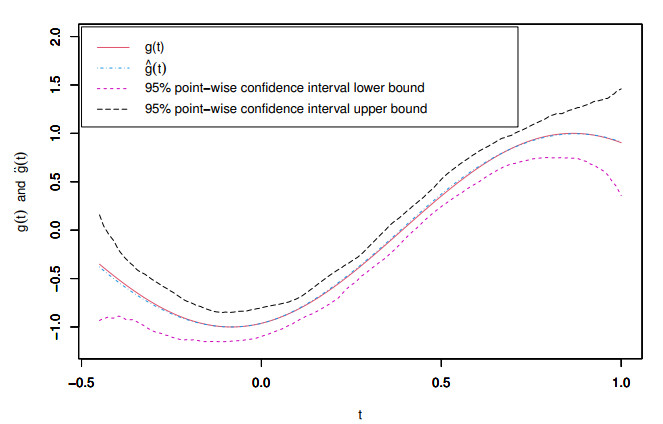
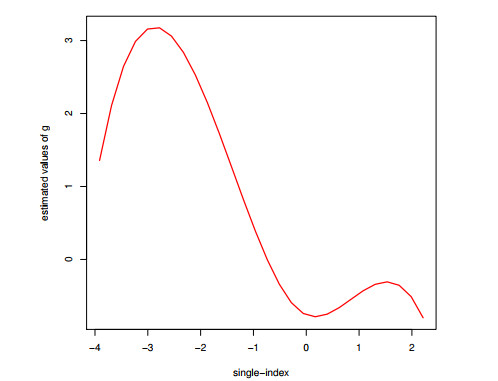
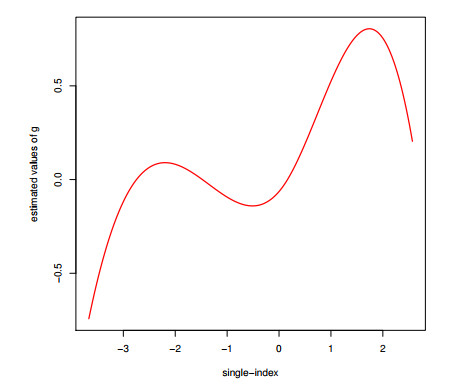
Possible dependence across spatial units is a relevant issue in many areas in practice. In this paper, we consider the partially linear single-index spatial autoregressive model to analyze the dependence of the spatial units and suggest an estimation method. An algorithm procedure is proposed to estimate the link function for the single index and the parameters in the single index, as well as the parameters in the linear component and the spatial parameter of the model. The nonparametric function is estimated based on B-spline approximation. The Nelder-Mead iteration algorithm is adopted to calculate the parametric and nonparametric parts simultaneously in the optimization. The asymptotic properties of parameter and function estimates are established. Monte Carlo simulation studies are conducted to investigate the performance of the proposed estimation methodology and calculation procedure. Furthermore, we use the proposed method to analyze air quality data and rural household income data in China.
Citation: Lei Liu, Jun Dai. Estimation of partially linear single-index spatial autoregressive model using B-splines[J]. Electronic Research Archive, 2024, 32(12): 6822-6846. doi: 10.3934/era.2024319
Possible dependence across spatial units is a relevant issue in many areas in practice. In this paper, we consider the partially linear single-index spatial autoregressive model to analyze the dependence of the spatial units and suggest an estimation method. An algorithm procedure is proposed to estimate the link function for the single index and the parameters in the single index, as well as the parameters in the linear component and the spatial parameter of the model. The nonparametric function is estimated based on B-spline approximation. The Nelder-Mead iteration algorithm is adopted to calculate the parametric and nonparametric parts simultaneously in the optimization. The asymptotic properties of parameter and function estimates are established. Monte Carlo simulation studies are conducted to investigate the performance of the proposed estimation methodology and calculation procedure. Furthermore, we use the proposed method to analyze air quality data and rural household income data in China.

| [1] |
L. F. Lee, Asymptotic distributions of quasi-maximum likelihood estimators for spatial autoregressive models, Econometrica, 72 (2004), 1899–1925. https://doi.org/10.1111/j.1468-0262.2004.00558.x doi: 10.1111/j.1468-0262.2004.00558.x

|
| [2] |
L. F. Lee, Consistency and efficiency of least squares estimation for mixed regressive, spatial autoregressive models, Econometric Theory, 18 (2002), 252–277. https://doi.org/10.1017/S0266466602182028 doi: 10.1017/S0266466602182028
|
| [3] |
H. H. Kelejian, I. R. Prucha, A generalized spatial two-stage least squares procedure for estimating a spatial autoregressive model with autoregressive disturbances, J. Real Estate Finance Econ., 17 (1998), 99–121. https://doi.org/10.1023/A:1007707430416 doi: 10.1023/A:1007707430416
|
| [4] |
L. F. Lee, Best spatial two stage least squares estimators for a spatial autoregressive model with autoregressive disturbances, Econometric Rev., 22 (2003), 307–335. https://doi.org/10.1081/ETC-120025891 doi: 10.1081/ETC-120025891
|
| [5] |
L. J. Su, Semiparametric GMM estimation of spatial autoregressive models, J. Econometrics, 167 (2012), 543–560. https://doi.org/10.1016/j.jeconom.2011.09.034 doi: 10.1016/j.jeconom.2011.09.034
|
| [6] |
X. Xu, L. F. Lee, Maximum likelihood estimation of a spatial autoregressive tobit model, J. Econometrics, 188 (2015), 264–280. https://doi.org/10.1016/j.jeconom.2015.05.004 doi: 10.1016/j.jeconom.2015.05.004
|
| [7] |
L. J. Su, S. N. Jin, Profile quasi-maximum likelihood estimation of partially linear spatial autoregressive models, J. Econometrics, 157 (2010), 18–33. https://doi.org/10.1016/j.jeconom.2009.10.033 doi: 10.1016/j.jeconom.2009.10.033
|
| [8] |
J. Du, X. Q. Sun, R. Y. Cao, Z. Z. Zhang, Statistical inference for partially linear additive spatial autoregressive models, Spat. Stat., 25 (2018), 52–67. https://doi.org/10.1016/j.spasta.2018.04.008 doi: 10.1016/j.spasta.2018.04.008
|
| [9] |
J. L. Wang, L. G. Xue, L. X. Zhu, Y. S. Chong, Estimation for a partial-linear single-index model, Ann. Stat., 38 (2010), 246–274. https://doi.org/10.1214/09-AOS712 doi: 10.1214/09-AOS712
|
| [10] |
S. L. Cheng, J. B. Chen, Estimation of partially linear single-index spatial autoregressive model, Stat. Pap., 62 (2021), 495–531. https://doi.org/10.1007/s00362-019-01105-y doi: 10.1007/s00362-019-01105-y
|
| [11] | C. De Boor, A Practical Guide to Splines, Springer, 1978. |
| [12] |
Y. Zhang, C. X. Xia, L. R. Zeng, B-spline estimation for varying-coefficient single-index model, Chin. J. Appl. Prob. Stat., 29 (2013), 433–442. https://doi.org/10.3969/j.issn.1001-4268.2013.09.008 doi: 10.3969/j.issn.1001-4268.2013.09.008
|
| [13] |
R. Q. Tian, M. J. Xia, D. K. Xu, Profile quasi-maximum likelihood estimation for semiparametric varying-coefficient spatial autoregressive panel models with fixed effects, Stat. Pap., 65 (2024), 5109–5143. https://doi.org/10.1007/s00362-024-01586-6 doi: 10.1007/s00362-024-01586-6
|
| [14] |
R. J. Carroll, J. Q. Fan, I. Gijbels, M. P. Wand, Generalized partially linear single-index models, J. Am. Stat. Assoc., 92 (1997), 477–489. https://doi.org/10.1080/01621459.1997.10474001 doi: 10.1080/01621459.1997.10474001
|
| [15] |
P. Yu, J. Du, Z. Z. Zhang, Single-index partially functional linear regression model, Stat. Pap., 61 (2020), 1107–1123. https://doi.org/10.1007/s00362-018-0980-6 doi: 10.1007/s00362-018-0980-6
|
| [16] |
A. C. Case, Spatial patterns in household demand, Econometrica, 59 (1991), 953–965. https://doi.org/10.2307/2938168 doi: 10.2307/2938168
|
| [17] |
E. Y. Wu, S. L. Kuo, A study on the use of a statistical analysis model to monitor air pollution status in an air quality total quantity control district, Atmosphere, 4 (2013), 349–364. https://doi.org/10.3390/atmos4040349 doi: 10.3390/atmos4040349
|
| [18] |
L. Chen, H. Y. Long, J. H. Xu, B. Q. Wu, Z. Hang, T. Xing, et al. Deep citywide multisource data fusion-based air quality estimation, IEEE Trans. Cybern., 54 (2024), 111–122. https://doi.org/10.1109/TCYB.2023.3245618 doi: 10.1109/TCYB.2023.3245618
|
| [19] |
J. Wang, L. J. Yang, Efficient and fast spline-backfitted kernel smoothing of additive models, Ann. Inst. Stat. Math., 61 (2009), 663–690. https://doi.org/10.1007/s10463-007-0157-x doi: 10.1007/s10463-007-0157-x
|
| [20] | L. J. Su, Z. L. Yang, Instrumental Variable Quantile Estimation of Spatial Autoregressive Models, 2011. Available from: https://ink.library.smu.edu.sg/soe_research/1074 |
| [21] |
T. F. Xie, R. Y. Cao, J. Du, Variable selection for spatial autoregressive models with a diverging number of parameters, Stat. Pap., 61 (2020), 1125–1145. https://doi.org/10.1007/s00362-018-0984-2 doi: 10.1007/s00362-018-0984-2
|
| [22] | L. L. Schumaker, Spline Functions, Wiley, 1981. |
| [23] |
H. H. Kelejian, I. R. Prucha, Specification and estimation of spatial autoregressive models with autoregressive and heteroscedastic disturbances, J. Econometrics, 157 (2010), 53–67. https://doi.org/10.1016/j.jeconom.2009.10.025 doi: 10.1016/j.jeconom.2009.10.025
|
Figures(3) / Tables(13)
Lei Liu, Jun Dai. Estimation of partially linear single-index spatial autoregressive model using B-splines[J]. Electronic Research Archive, 2024, 32(12): 6822-6846. doi: 10.3934/era.2024319







 DownLoad:
DownLoad: