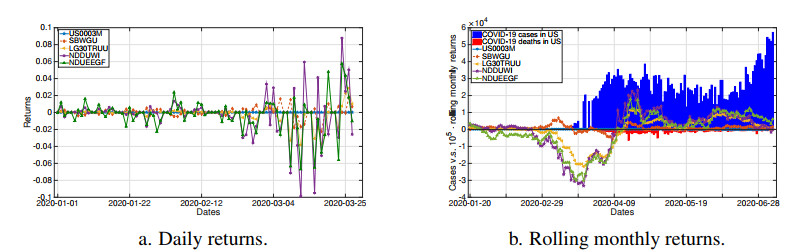
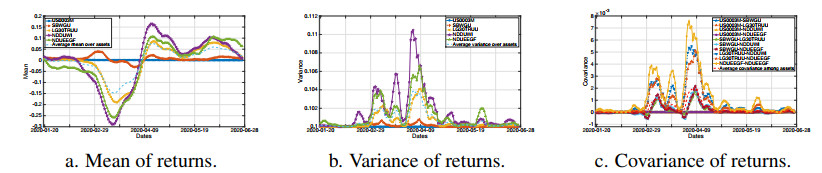
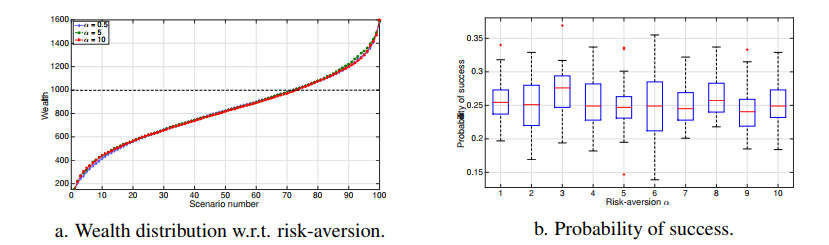
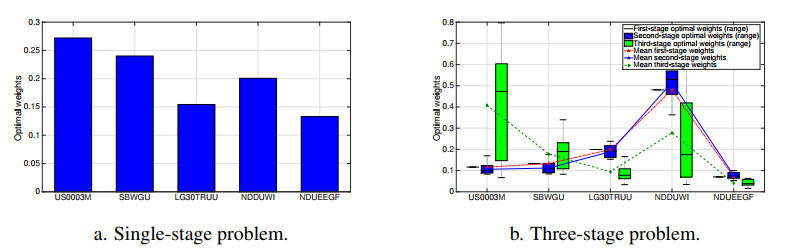
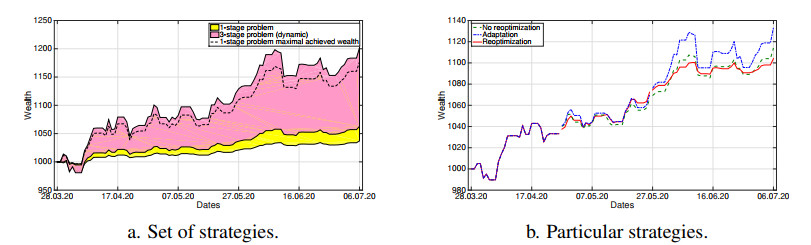
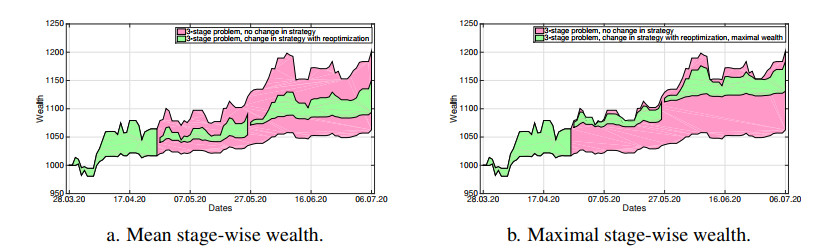
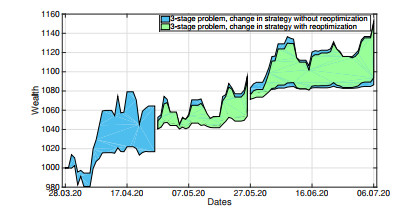
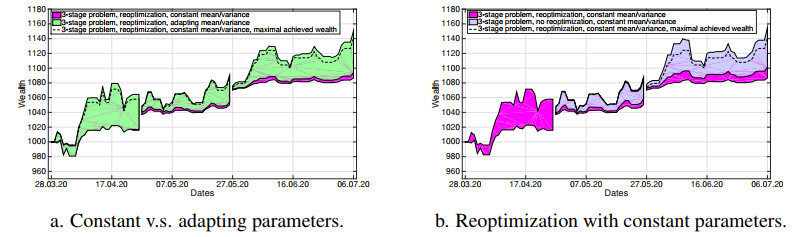
The COVID-19 pandemic has demonstrated the importance and value of multi-period asset allocation strategies responding to rapid changes in market behavior. In this article, we formulate and solve a multi-stage stochastic optimization problem, choosing the indices' optimal weights dynamically in line with a customized data-driven Bellman's procedure. We use basic asset classes (equities, fixed income, cash and cash equivalents) and five corresponding indices for the development of optimal strategies. In our multi-period setup, the probability model describing the uncertainty about the value of asset returns changes over time and is scenario-specific. Given a high enough variation of model parameters, this allows to account for possible crises events. In this article, we construct optimal allocation strategies accounting for the influence of the COVID-19 pandemic on financial returns. We observe that the growth in the number of infections influences financial markets and makes assets' behavior more dependent. Solving the multi-stage asset allocation problem dynamically, we (i) propose a fully data-driven method to estimate time-varying conditional probability models and (ii) we implement the optimal quantization procedure for the scenario approximation. We consider optimality of quantization methods in the sense of minimal distances between continuous-state distributions and their discrete approximations. Minimizing the well-known Kantorovich-Wasserstein distance at each time stage, we bound the approximation error, enhancing accuracy of the decision-making. Using the first-stage allocation strategy developed via our method, we observe ca. 10% wealth growth on average out-of-sample with a maximum of ca. 20% and a minimum of ca. 5% over a three-month period. Further, we demonstrate that monthly reoptimization aids in reducing uncertainty at a cost of maximal wealth. Also, we show that optimistically offsetted distribution parameters lead to a reduction in out-of-sample wealth due to the COVID-19 crisis.
Citation: Anna Timonina-Farkas. COVID-19: data-driven dynamic asset allocation in times of pandemic[J]. Quantitative Finance and Economics, 2021, 5(2): 198-227. doi: 10.3934/QFE.2021009
The COVID-19 pandemic has demonstrated the importance and value of multi-period asset allocation strategies responding to rapid changes in market behavior. In this article, we formulate and solve a multi-stage stochastic optimization problem, choosing the indices' optimal weights dynamically in line with a customized data-driven Bellman's procedure. We use basic asset classes (equities, fixed income, cash and cash equivalents) and five corresponding indices for the development of optimal strategies. In our multi-period setup, the probability model describing the uncertainty about the value of asset returns changes over time and is scenario-specific. Given a high enough variation of model parameters, this allows to account for possible crises events. In this article, we construct optimal allocation strategies accounting for the influence of the COVID-19 pandemic on financial returns. We observe that the growth in the number of infections influences financial markets and makes assets' behavior more dependent. Solving the multi-stage asset allocation problem dynamically, we (i) propose a fully data-driven method to estimate time-varying conditional probability models and (ii) we implement the optimal quantization procedure for the scenario approximation. We consider optimality of quantization methods in the sense of minimal distances between continuous-state distributions and their discrete approximations. Minimizing the well-known Kantorovich-Wasserstein distance at each time stage, we bound the approximation error, enhancing accuracy of the decision-making. Using the first-stage allocation strategy developed via our method, we observe ca. 10% wealth growth on average out-of-sample with a maximum of ca. 20% and a minimum of ca. 5% over a three-month period. Further, we demonstrate that monthly reoptimization aids in reducing uncertainty at a cost of maximal wealth. Also, we show that optimistically offsetted distribution parameters lead to a reduction in out-of-sample wealth due to the COVID-19 crisis.

| [1] | Bellman RE (1956) Dynamic Programming, Princeton University Press, Princeton, New Jersey. |
| [2] | Bertsekas DP (1976) Dynamic Programming and Stochastic Control, Academic Press, New York. |
| [3] | Bertsekas DP (2007) Dynamic Programming and Optimal Control. Athena Sci 2. |
| [4] | Bertsimas D, Shtern S, Sturt B (2020) A data-driven approach to multi-stage stochastic linear optimization. [In press]. |
| [5] | Boyd S (2009) L1 trend filtering. SIAM Rev. |
| [6] | Dreyfus SE (1965) Dynamic Programming and the Calculus of Variations, Academic Press, New York. |
| [7] | Ermoliev Y, Marti K, Pflug GC (2004) Lecture Notes in Economics and Mathematical Systems, Dynamic Stochastic Optimization, Springer Verlag ISBN 3-540-40506-2. |
| [8] | Fishman G (1995) Monte Carlo: Concepts, Algorithms, and Applications, Springer, New York. |
| [9] |
Fort JC, Pagés G(2002) Asymptotics of Optimal Quantizers for Some Scalar Distributions. J Comput Appl Math 146: 253–275. doi: 10.1016/S0377-0427(02)00359-X

|
| [10] | Graf S, Luschgy H (2000) Foundations of Quantization for Probability Distributions. Lect Notes Math, Springer, Berlin. |
| [11] | Hanasusanto G, Kuhn D (2013) Robust Data-Driven Dynamic Programming. NIPS Proceedings 26. |
| [12] |
Heitsch H, Römisch W (2009) Scenario Tree Modeling for Multi-stage Stochastic Programs. Mathe Program 118: 371–406. doi: 10.1007/s10107-007-0197-2
|
| [13] | Hoffmann AOI, Delre SA, von Eije JH, et al. (2005) Stock Price Dynamics in Artificial Multi-Agent Stock Markets, Faculty of Management and Organization, University of Groningen Press. |
| [14] | Hou K(2007) Industry Information Diffusion and the Lead-lag Effect in Stock Returns, Oxford University Press. |
| [15] |
Johnson SA, Stedinger JR, Shoemaker CA, et al. (1993) Numerical Solution of Continuous-state Dynamic Programs using Linear and Spline Interpolation. Oper Res 41: 484–500. doi: 10.1287/opre.41.3.484
|
| [16] | Kantorovich L (1942) On the Translocation of Masses. C.R. (Doklady) Acad Sci URSS (N.S.) 37: 199–201. |
| [17] |
Keshavarz A, Boyd S(2012) Quadratic Approximate Dynamic Programming for Input-affine Systems. Int J Robust Nonlinear Control 24: 432–449. doi: 10.1002/rnc.2894
|
| [18] | Lipster R, Shiryayev AN(1978) Statistics of Random Processes, Springer-Verlag 2, New York. |
| [19] |
Mirkov R, Pflug GC (2007) Tree Approximations of Stochastic Dynamic Programs. SIAM J Optim 18: 1082–1105. doi: 10.1137/060658552
|
| [20] | Mirkov R (2008) Tree Approximations of Dynamic Stochastic Programs: Theory and Applications, VDM Verlag, 1–176. |
| [21] |
Nadaraya ÉA (1964) On Estimating Regression. Theory Prob Appl 9: 141–142. doi: 10.1137/1109020
|
| [22] |
Pflug GC (2001) Scenario Tree Generation for Multiperiod Financial Optimization by Optimal Discretization. Math Program 89: 251–257. doi: 10.1007/PL00011398
|
| [23] | Pflug GC, Römisch W(2007) Modeling, Measuring and Managing Risk, World Scientific Publishing, 1–301. |
| [24] |
Pflug GC (2010) Version-independence and Nested Distributions in Multi-stage Stochastic Optimization. SIAM J Optim 20: 1406–1420. doi: 10.1137/080718401
|
| [25] | Pflug GC, Pichler A (2011) Approximations for Probability Distributions and Stochastic Optimization Problems, Springer Handbook on Stochastic Optimization Methods in Finance and Energy, G. Consigli, M. Dempster, M. Bertocchi eds., Int. Series in OR and Management Science 163: 343–387. |
| [26] |
Pflug GC, Pichler A (2012) A Distance for Multi-Stage Stochastic Optimization Models. SIAM J optim 22: 1–23. doi: 10.1137/110825054
|
| [27] | Powell W (2007) Approximate Dynamic Programming: Solving the Curses of Dimensionality, Wiley-Blackwell. |
| [28] | Römisch W (2010) Scenario Generation. Wiley Encyclopedia of Operations Research and Management Science, J.J. Cochran ed., Wiley. |
| [29] |
Rosen JB, Marcia RF (2004) Convex Quadratic Approximation. Comput Optim Appl 28: 173–184. doi: 10.1023/B:COAP.0000026883.13660.84
|
| [30] | Safvenblad P (1997) Lead-lag Effect when Prices Reveal Cross-Security Information, Stockholm School of Economics Press. |
| [31] | Shapiro A, Dentcheva D, Ruszczyński A (2009) Lectures on Stochastic Programming: Modeling and Theory, MPS-SIAM Series on Optimization, 9. |
| [32] | Timonina A (2013) Multi-stage Stochastic Optimization: the Distance Between Stochastic Scenario Processes, Springer-Verlag Berlin Heidelberg. |
| [33] | Timonina A (2014) Approximation of Continuous-state Scenario Processes in Multi-stage Stochastic Optimization and its Applications. Wien Univ Diss. |
| [34] | Timonina-Farkas A, Pflug GC (2017) Stochastic Dynamic Programming Using Optimal Quantizers. Optimization Online. Available from: http://www.optimization-online.org/DB_HTML/2017/10/6269.html. |
| [35] | Lo AW, Mackinlay CA (1989) When are Contrarian Profits Due to Stock Market Overreaction? NBER Working Paper No. W2977. Available from: http://ssrn.com/abstract=227214. |
| [36] | Veronesi P (1999) Stock Market Overreaction to Bad News in Good Times: A Rational Expectations Equilibrium Model. Rev Financ Stud. |
| [37] | Villani C (2003) Topics in Optimal Transportation, Graduate Studies in Mathematics, American Mathematical Society, 58, Providence, RI. |
| [38] | Watson S, Geoffrey (1964) Smooth Regression Analysis. Sankhya: Indian J Stat 26: 359–372. |
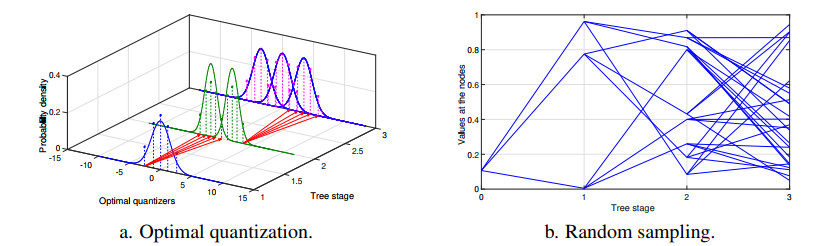
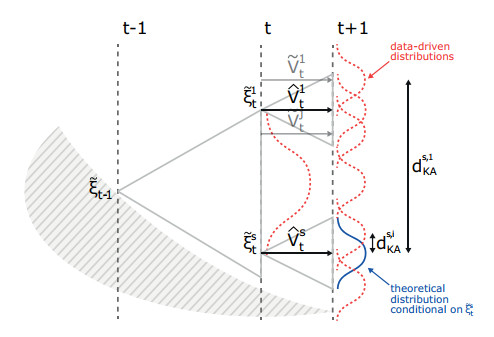
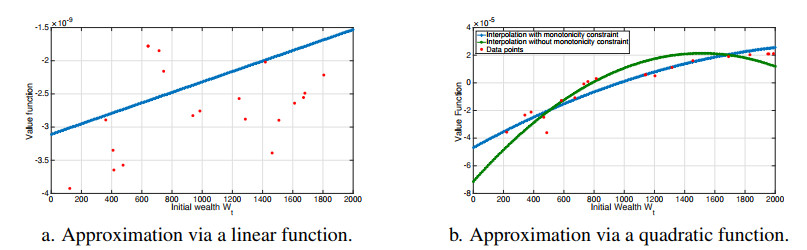
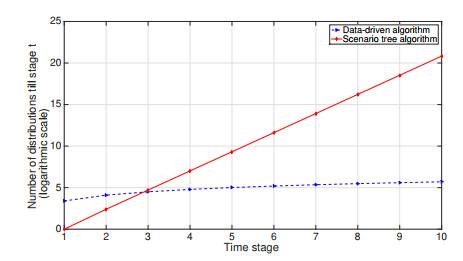
Figures(16) / Tables(1)

Anna Timonina-Farkas. COVID-19: data-driven dynamic asset allocation in times of pandemic[J]. Quantitative Finance and Economics, 2021, 5(2): 198-227. doi: 10.3934/QFE.2021009







 DownLoad:
DownLoad: