Citation: David E. Bernholdt, Mark R. Cianciosa, David L. Green, Kody J.H. Law, Alexander Litvinenko, Jin M. Park. Comparing theory based and higher-order reduced models for fusion simulation data[J]. Big Data and Information Analytics, 2018, 3(2): 41-53. doi: 10.3934/bdia.2018006

| [1] | Christopher MB (2006) Pattern recognition and machine learning. J Electron Imaging 16: 140–155. |
| [2] | Boyd S, Vandenberghe V (2004) Convex optimization, Cambridge university press. |
| [3] | Goodfellow I, Bengio Y, Courville A (2016) Deep Learning, MIT Press. |
| [4] | Kushner H, Yin GG (2003) Stochastic approximation and recursive algorithms and applications, Springer Science & Business Media, 35. |
| [5] |
Mallat S (2016) Understanding deep convolutional networks. Phil Trans R Soc A 374: 20150203. doi: 10.1098/rsta.2015.0203

|
| [6] | Moosavi-Dezfooli SM, Fawzi A, Frossard P (2016) Deepfool: A simple and accurate method to fool deep neural networks, In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2574–2582. |
| [7] | Murphy KP (2014) Machine learning: A probabilistic perspective. CHANCE 27: 62–63. |
| [8] |
Park JM, Ferron JR , Holcomb CT, et al. (2018) Integrated modeling of high βn steady state scenario on diii-d. Phys Plasmas 25: 012506. doi: 10.1063/1.5013021
|
| [9] | Park JM, Staebler G, Snyder PB, et al. (2018) Theory-based scaling of energy confinement time for future reactor design. Available from: http://ocs.ciemat.es/EPS2018ABS/pdf/P5.1096.pdf. |
| [10] | Rasmussen CE (2003) Gaussian processes in machine learning, MIT Press. |
| [11] | Robbins H, Monro S (1951) A stochastic approximation method. Ann Math Stat: 400–407. |
| [12] |
Snyder PB, Burrell KH,Wilson HR, et al. (2007) Stability and dynamics of the edge pedestal in the low collisionality regime: Physics mechanisms for steady-state elm-free operation. Nucl Fusion 47: 961. doi: 10.1088/0029-5515/47/8/030
|
| [13] |
Staebler GM, Kinsey JE, Waltz RE (2007) A theory-based transport model with comprehensive physics. Phys Plasmas 14: 055909. doi: 10.1063/1.2436852
|


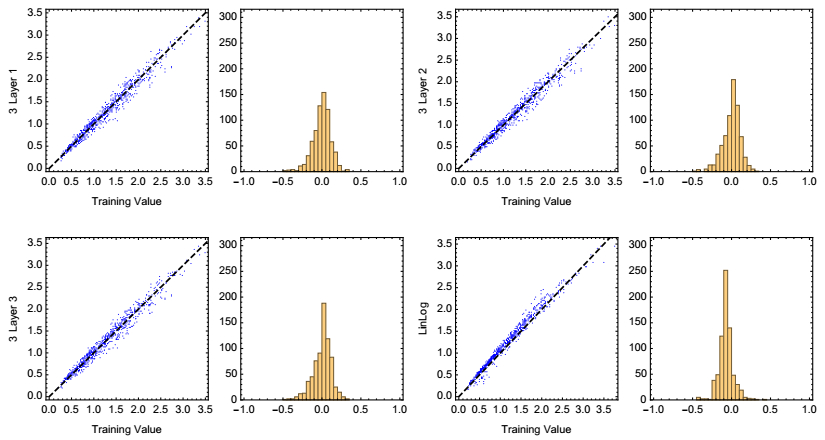
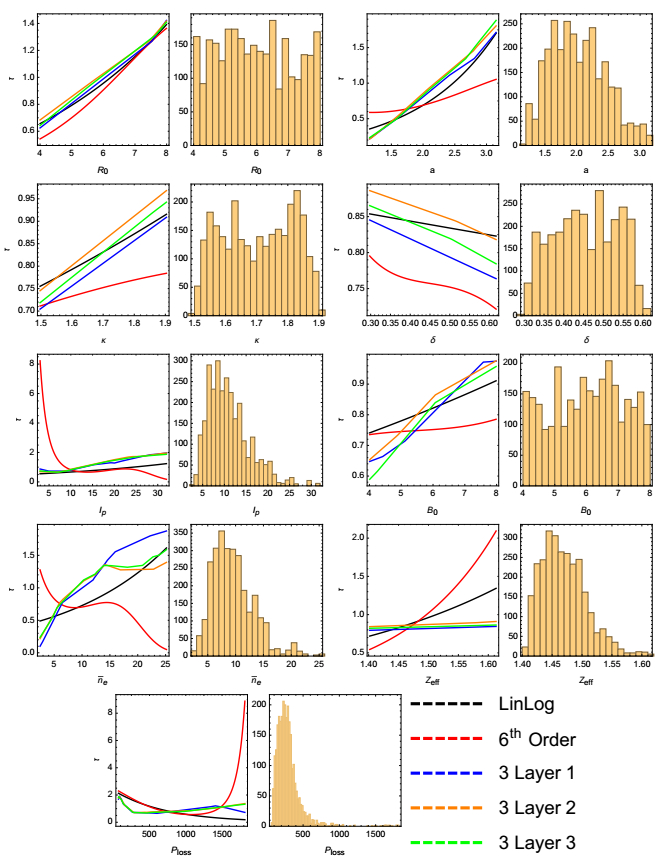
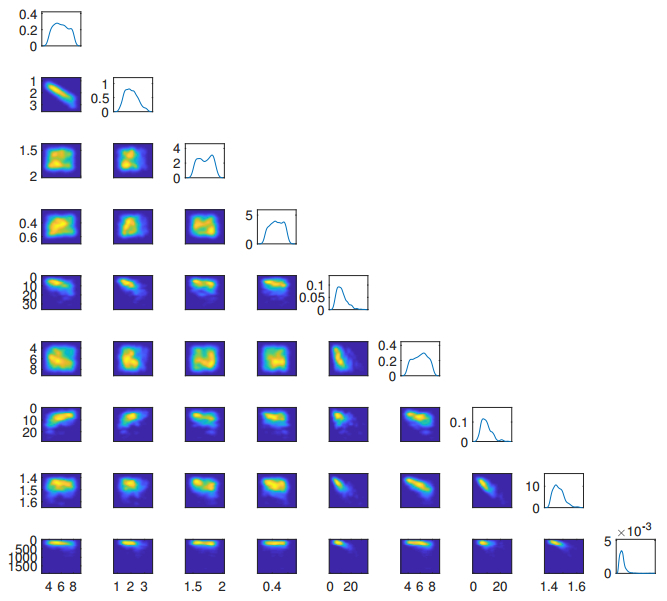
Figures(5) / Tables(2)

David E. Bernholdt, Mark R. Cianciosa, David L. Green, Kody J.H. Law, Alexander Litvinenko, Jin M. Park. Comparing theory based and higher-order reduced models for fusion simulation data[J]. Big Data and Information Analytics, 2018, 3(2): 41-53. doi: 10.3934/bdia.2018006









 DownLoad:
DownLoad: