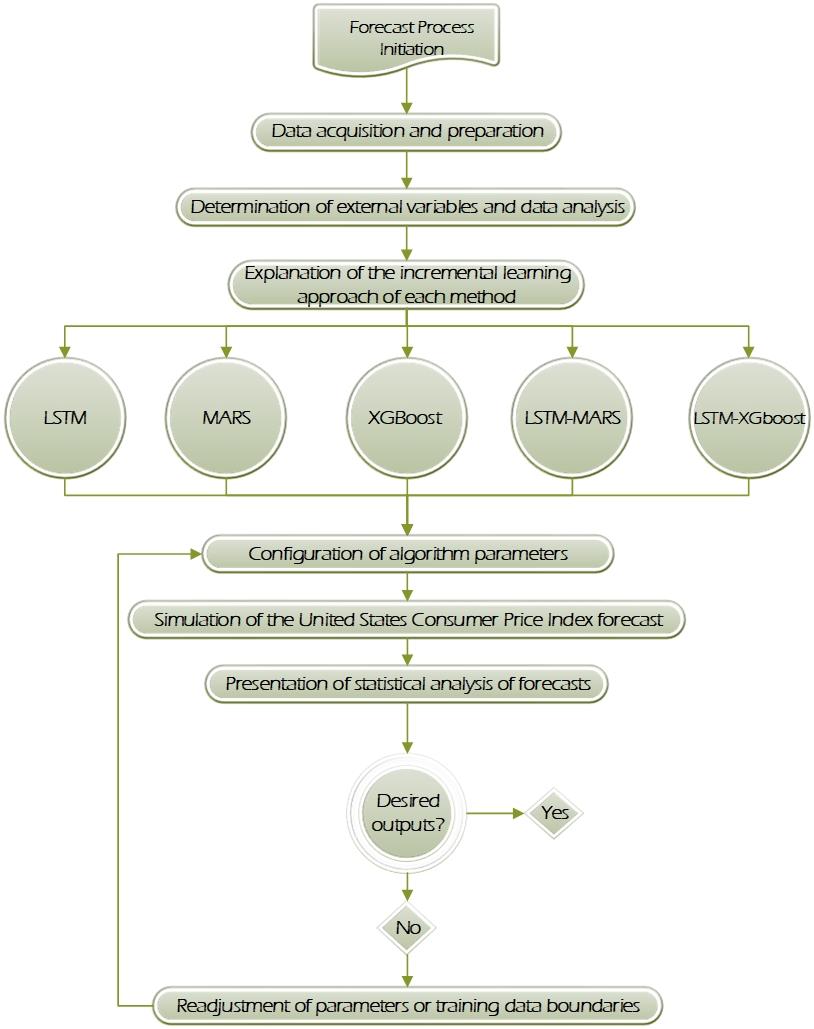
This study aims to apply advanced machine-learning models and hybrid approaches to improve the forecasting accuracy of the US Consumer Price Index (CPI). The study examined the performance of LSTM, MARS, XGBoost, LSTM-MARS, and LSTM-XGBoost models using a large time-series data from January 1974 to October 2023. The data were combined with key economic indicators of the US, and the hyperparameters of the forecasting models were optimized using genetic algorithm and Bayesian optimization methods. According to the VAR model results, variables such as past values of CPI, oil prices (OP), and gross domestic product (GDP) have strong and significant effects on CPI. In particular, the LSTM-XGBoost model provided superior accuracy in CPI forecasts compared with other models and was found to perform the best by establishing strong relationships with variables such as the federal funds rate (FFER) and GDP. These results suggest that hybrid approaches can significantly improve economic forecasts and provide valuable insights for policymakers, investors, and market analysts.
Citation: Yunus Emre Gur. Development and application of machine learning models in US consumer price index forecasting: Analysis of a hybrid approach[J]. Data Science in Finance and Economics, 2024, 4(4): 469-513. doi: 10.3934/DSFE.2024020
This study aims to apply advanced machine-learning models and hybrid approaches to improve the forecasting accuracy of the US Consumer Price Index (CPI). The study examined the performance of LSTM, MARS, XGBoost, LSTM-MARS, and LSTM-XGBoost models using a large time-series data from January 1974 to October 2023. The data were combined with key economic indicators of the US, and the hyperparameters of the forecasting models were optimized using genetic algorithm and Bayesian optimization methods. According to the VAR model results, variables such as past values of CPI, oil prices (OP), and gross domestic product (GDP) have strong and significant effects on CPI. In particular, the LSTM-XGBoost model provided superior accuracy in CPI forecasts compared with other models and was found to perform the best by establishing strong relationships with variables such as the federal funds rate (FFER) and GDP. These results suggest that hybrid approaches can significantly improve economic forecasts and provide valuable insights for policymakers, investors, and market analysts.

| [1] |
Adhikari DR, Stevens DP (2024) Effect of federal funds rate on cpi and ppi. J Appl Bus Econ 26. https://doi.org/10.33423/jabe.v26i1.6887 doi: 10.33423/jabe.v26i1.6887

|
| [2] |
Aghaabbasi M, Ali M, Jasiński M, et al. (2023) On hyperparameter optimization of machine learning methods using a bayesian optimization algorithm to predict work travel mode choice. IEEE Access 11: 19762–19774. https://doi.org/10.1109/access.2023.3247448 doi: 10.1109/access.2023.3247448
|
| [3] |
Ahmed N, Assadi M, Zhang Q, et al. (2023) Assessing impact of borehole field data's input parameters on hybrid deep learning models for heating and cooling forecasting: a local and global explainable ai analysis. IOP Conference Series: Materials Science and Engineering 1294: 012056. https://doi.org/10.1088/1757-899x/1294/1/012056 doi: 10.1088/1757-899x/1294/1/012056
|
| [4] | Akbulut H (2022) Forecasting inflation in Turkey: A comparison of time-series and machine learning models. Econ J Emerg Market 14. |
| [5] |
Alhendawy HAA, Abdallah Mostafa MG, Elgohari MI, et al. (2023) Determinants of renewable energy production in egypt new approach: machine learning algorithms. Int J Energy Econ Policy 13: 679–689. https://doi.org/10.32479/ijeep.14985 doi: 10.32479/ijeep.14985
|
| [6] |
Ali M, Apriliana T, Fathonah AN (2023) The Effect of Money Supply and Bank Indonesia Rate on Consumer Price Index in Indonesia 2018–2022. J Ekonomi Bisnis Entrep 17: 488–497. https://doi.org/10.55208/jebe.v17i2.471 doi: 10.55208/jebe.v17i2.471
|
| [7] |
Alibabaei K, Gaspar PD, Lima TM (2021) Modeling soil water content and reference evapotranspiration from climate data using deep learning method. Appl Sci 11: 5029. https://doi.org/10.3390/app11115029 doi: 10.3390/app11115029
|
| [8] |
Alim M, Ye G, Guan P, et al. (2020) Comparison of arima model and xgboost model for prediction of human brucellosis in mainland China: a time-series study. BMJ Open 10: e039676. https://doi.org/10.1136/bmjopen-2020-039676 doi: 10.1136/bmjopen-2020-039676
|
| [9] |
Alizadeh M, Beheshti MTH, Ramezani A, et al. (2023) An optimized hybrid methodology for short‐term traffic forecasting in telecommunication networks. T Emerg Telecommun T 34: e4860. https://doi.org/10.1002/ett.4860 doi: 10.1002/ett.4860
|
| [10] |
Alizamir M, Shiri J, Fard AF, et al. (2023) Improving the accuracy of daily solar radiation prediction by climatic data using an efficient hybrid deep learning model: Long short-term memory (LSTM) network coupled with wavelet transform. Eng Appl Artif Intell 123: 106199. https://doi.org/10.1016/j.engappai.2023.106199 doi: 10.1016/j.engappai.2023.106199
|
| [11] |
Alshahrani SM, Alrayes FS, Alqahtani H, et al. (2023) Iot-cloud assisted botnet detection using rat swarm optimizer with deep learning. Cmc-Comput Mater Con 74: 3085–3100. https://doi.org/10.32604/cmc.2023.032972 doi: 10.32604/cmc.2023.032972
|
| [12] |
Amalu HI, Agbasi LO, Olife LU, et al. (2021) Responsiveness of service sector growth to financial development in nigeria: evidence from 1981–2019. J Adv Res Econ Adm Sci 2: 1–12. https://doi.org/10.47631/jareas.v2i3.305 doi: 10.47631/jareas.v2i3.305
|
| [13] |
Amin J, Sharif M, Raza M, et al. (2020) Brain tumor detection: a long short-term memory (LSTM)-based learning model. Neural Comput Appl 32: 15965–15973. https://doi.org/10.1007/s00521-019-04650-7 doi: 10.1007/s00521-019-04650-7
|
| [14] |
Ampomah EK, Nyame G, Qin Z, et al. (2021) Stock market prediction with gaussian naïve bayes machine learning algorithm. Informatica 45. https://doi.org/10.31449/inf.v45i2.3407 doi: 10.31449/inf.v45i2.3407
|
| [15] |
Anagnostis A, Moustakidis S, Papageorgiou EI, et al. (2022) A hybrid bimodal lstm architecture for cascading thermal energy storage modelling. Energies 15: 1959. https://doi.org/10.3390/en15061959 doi: 10.3390/en15061959
|
| [16] |
Araujo GS, Gaglianone WP (2023) Machine learning methods for inflation forecasting in Brazil: New contenders versus classical models. Lat Am J Cent Bank 4: 100087. https://doi.org/10.1016/j.latcb.2023.100087 doi: 10.1016/j.latcb.2023.100087
|
| [17] |
Arnone M, Romelli D (2013) Dynamic central bank independence indices and inflation rate: A new empirical exploration. J Financ Stabil 9: 385–398. https://doi.org/10.1016/j.jfs.2013.03.002 doi: 10.1016/j.jfs.2013.03.002
|
| [18] |
Arthur CK, Temeng VA, Ziggah YY (2020) Multivariate Adaptive Regression Splines (MARS) approach to blast-induced ground vibration prediction. Int J Min Reclam Env 34: 198–222. https://doi.org/10.1080/17480930.2019.1577940 doi: 10.1080/17480930.2019.1577940
|
| [19] |
Attoh-Okine NO, Cooger K, Mensah S (2009) Multivariate adaptive regression (MARS) and hinged hyperplanes (HHP) for doweled pavement performance modeling. Constr Build Maters 23: 3020–3023. https://doi.org/10.1016/j.conbuildmat.2009.04.010 doi: 10.1016/j.conbuildmat.2009.04.010
|
| [20] |
Balocchi R, Menicucci D, Santarcangelo L, et al. (2004) Deriving the respiratory sinus arrhythmia from the heartbeat time series using empirical mode decomposition. Chaos Soliton Fract 20: 171–177. https://doi.org/10.1016/s0960-0779(03)00441-7 doi: 10.1016/s0960-0779(03)00441-7
|
| [21] |
Balshi MS, McGuire AD, Duffy P, et al. (2009) Assessing the response of area burned to changing climate in western boreal North America using a Multivariate Adaptive Regression Splines (MARS) approach. Global Change Biol 15: 578–600. https://doi.org/10.1111/j.1365-2486.2008.01679.x doi: 10.1111/j.1365-2486.2008.01679.x
|
| [22] | Bandara K, Hyndman R, Bergmeir C (2021) Mstl: a seasonal-trend decomposition algorithm for time series with multiple seasonal patterns. https://doi.org/10.48550/arxiv.2107.13462 |
| [23] |
Bandara WMS, De Mel WAR (2024) Evaluating the Efficacy of Supervised Machine Learning Models in Inflation Forecasting in Sri Lanka. Am J Appl Stat Econ 3: 51–60. https://doi.org/10.54536/ajase.v3i1.2385 doi: 10.54536/ajase.v3i1.2385
|
| [24] |
Barkan O, Benchimol J, Caspi I, et al. (2023) Forecasting CPI inflation components with hierarchical recurrent neural networks. Int J Forecast 39: 1145–1162. https://doi.org/10.1016/j.ijforecast.2022.04.009 doi: 10.1016/j.ijforecast.2022.04.009
|
| [25] |
Baybuza I (2018) Inflation forecasting using machine learning methods. Russ J Money Financ 77: 42–59. https://doi.org/10.31477/rjmf.201804.42 doi: 10.31477/rjmf.201804.42
|
| [26] | Bhanja S, Das A (2021) Deep neural network for multivariate time-series forecasting. In: Proceedings of International Conference on Frontiers in Computing and Systems : COMSYS 2020 (267–277). Springer Singapore. https://doi.org/10.1007/978-981-15-7834-2_25 |
| [27] |
Bhati BS, Chugh G, Al‐Turjman F, et al. (2020) An improved ensemble based intrusion detection technique using xgboost. T Emerg Telecommun T 32: e4076. https://doi.org/10.1002/ett.4076 doi: 10.1002/ett.4076
|
| [28] |
Bouktif S, Fiaz A, Ouni A, et al. (2020). Multi-sequence lstm-rnn deep learning and metaheuristics for electric load forecasting. Energies 13: 391. https://doi.org/10.3390/en13020391 doi: 10.3390/en13020391
|
| [29] |
Brzan PP, Obradovic Z, Stiglic G (2017) Contribution of temporal data to predictive performance in 30-day readmission of morbidly obese patients. Peer J 5 e3230. https://doi.org/10.7287/peerj.3230v0.1/reviews/2 doi: 10.7287/peerj.3230v0.1/reviews/2
|
| [30] |
Budiharto W (2021) Data science approach to stock prices forecasting in Indonesia during Covid-19 using Long Short-Term Memory (LSTM). J Big Data 8: 1–9. https://doi.org/10.1186/s40537-021-00430-0 doi: 10.1186/s40537-021-00430-0
|
| [31] | Cahyono ND, Sumpeno S, Setiiadi E (2023) Multivariate Time Series for Customs Revenue Forecasting Using LSTM Neural Networks. In: 2023 International Conference on Information Technology and Computing (ICITCOM), 357–362. https://doi.org/10.1109/ICITCOM60176.2023.10442562 |
| [32] |
Cain MK, Zhang Z, Yuan KH (2017) Univariate and multivariate skewness and kurtosis for measuring nonnormality: Prevalence, influence and estimation. Behav Res Methods 49: 1716–1735. https://doi.org/10.3758/s13428-016-0814-1 doi: 10.3758/s13428-016-0814-1
|
| [33] |
Cao L, Li Y, Zhang J, et al. (2020) Electrical load prediction of healthcare buildings through single and ensemble learning. Energy Rep 6: 2751–2767. https://doi.org/10.1016/j.egyr.2020.10.005 doi: 10.1016/j.egyr.2020.10.005
|
| [34] |
Chen S (2023) Multiple stock prediction based on linear and non-linear machine learning regression methods. Advances in Economics, Management and Political Sciences 46: 225–232. https://doi.org/10.54254/2754-1169/46/20230343 doi: 10.54254/2754-1169/46/20230343
|
| [35] | Chen T, Guestrin C (2016) Xgboost: a scalable tree boosting system. In: Proceedings of the 22nd acm sigkdd international conference on knowledge discovery and data mining. https://doi.org/10.48550/arxiv.1603.02754 |
| [36] |
Choi JY, Lee B (2018) Combining lstm network ensemble via adaptive weighting for improved time series forecasting. Math Probl Eng 2018: 1–8. https://doi.org/10.1155/2018/2470171 doi: 10.1155/2018/2470171
|
| [37] |
Choudhary K, Jha GK, Kumar RR, et al. (2019) Agricultural commodity price analysis using ensemble empirical mode decomposition: a case study of daily potato price series. Indian J Agr Sci 89: 882–886. https://doi.org/10.56093/ijas.v89i5.89682 doi: 10.56093/ijas.v89i5.89682
|
| [38] |
Correa E (2023) Effect of unemployment, inflation and foreign direct investment on economic growth in sub-saharan africa. J Dev Econ 8: 297–315. https://doi.org/10.20473/jde.v8i2.47283 doi: 10.20473/jde.v8i2.47283
|
| [39] | Coulibaly P, Baldwin CK (2005) Nonstationary hydrological time series forecasting using nonlinear dynamic methods. J Hydrol 307: 164–174. |
| [40] |
Cui Q, Rong S, Zhang B (2023) Advancing the comprehension of consumer price index and influencing factors: insight into the mechanism based on prediction machine learning models. Adv Econ Manage Res 7: 125–125. https://doi.org/10.56028/aemr.7.1.125.2023 doi: 10.56028/aemr.7.1.125.2023
|
| [41] |
DeJong DN, Nankervis JC, Savin NE, et al. (1992). The power problems of unit root test in time series with autoregressive errors. J Econometrics 53: 323–343. https://doi.org/10.1016/0304-4076(92)90090-E doi: 10.1016/0304-4076(92)90090-E
|
| [42] |
Delage O, Portafaix T, Benchérif H, et al. (2022). Empirical adaptive wavelet decomposition (eawd): an adaptive decomposition for the variability analysis of observation time series in atmospheric science. Nonlinear Proc Geoph 29: 265–277. https://doi.org/10.5194/npg-29-265-2022 doi: 10.5194/npg-29-265-2022
|
| [43] | Dhamo D, Dhamo X, Spahiu A, et al. (2022) PV production forecasting using machine learning and deep learning techniques: Albanian case study. Adv Eng Days 5: 68–70. |
| [44] |
Dickey DA, Fuller WA (1981) Likelihood ratio statistics for autoregressive time series with a unit root. Econometrica: J Econom Soc 1057–1072. https://doi.org/10.2307/1912517 doi: 10.2307/1912517
|
| [45] |
Dinh TN, Thirunavukkarasu GS, Seyedmahmoudian M, et al. (2023). Predicting Commercial Building Energy Consumption Using a Multivariate Multilayered Long-Short Term Memory Time-Series Model. Appl Sci 13: 7775. https://doi.org/10.3390/app13137775 doi: 10.3390/app13137775
|
| [46] |
Djordjević K, Jordović-Pavlović MI, Ćojbašić Ž, et al. (2022) Influence of data scaling and normalization on overall neural network performances in photoacoustics. Opt Quant Electron 54. https://doi.org/10.1007/s11082-022-03799-1 doi: 10.1007/s11082-022-03799-1
|
| [47] |
Elgui K, Bianchi P, Portier F, et al. (2020) Learning methods for rssi-based geolocation: a comparative study. Pervasive Mob Comput 67: 101199. https://doi.org/10.1016/j.pmcj.2020.101199 doi: 10.1016/j.pmcj.2020.101199
|
| [48] |
Enke D, Mehdiyev N (2014) A hybrid neuro-fuzzy model to forecast inflation. Proc Comput Sci 36: 254–260. https://doi.org/10.1016/j.procs.2014.09.088. doi: 10.1016/j.procs.2014.09.088
|
| [49] |
Fan C, Zhang D, Zhang C (2010) On sample size of the kruskal-wallis test with application to a mouse peritoneal cavity study. Biometrics 67: 213–224. https://doi.org/10.1111/j.1541-0420.2010.01407.x doi: 10.1111/j.1541-0420.2010.01407.x
|
| [50] |
Farsi B, Amayri M, Bouguila N, et al. (2021) On short-term load forecasting using machine learning techniques and a novel parallel deep lstm-cnn approach. IEEE Access 9: 31191–31212. https://doi.org/10.1109/access.2021.3060290 doi: 10.1109/access.2021.3060290
|
| [51] |
Feng H (2024) Analysis and Forecast of CPI in China Based on LSTM and VAR Model. Advances in Digital Economy and Data Analysis Technology The 2nd International Conference on Internet Finance and Digital Economy, Kuala Lumpur Malaysia, 339–357. https://doi.org/10.1142/9789811267505_0025 doi: 10.1142/9789811267505_0025
|
| [52] |
Feurer M, Springenberg JT, Hutter F (2015) Initializing bayesian hyperparameter optimization via meta-learning. Proceedings of the AAAI Conference on Artificial Intelligence 29. https://doi.org/10.1609/aaai.v29i1.9354 doi: 10.1609/aaai.v29i1.9354
|
| [53] | Friedman JH (1991) Multivariate adaptive regression splines. Annals Stat 19: 1–67. |
| [54] | Friedman J, Hastie T, Tibshirani R (2010) Regularization paths for generalized linear models via coordinate descent. J Stat Software 33: 1–22. |
| [55] |
Gao Z, Kuruoglu EE (2023) Attention based hybrid parametric and neural network models for non‐stationary time series prediction. Expert Syst 41. https://doi.org/10.1111/exsy.13419 doi: 10.1111/exsy.13419
|
| [56] | Gastinger J, Nicolas S, Stepić D, et al. (2021) A study on ensemble learning for time series forecasting and the need for meta-learning. In: 2021 International Joint Conference on Neural Networks (IJCNN), 1–8. https://doi.org/10.48550/arxiv.2104.11475 |
| [57] |
Gil-Cordero E, Rondán-Cataluña FJ, Sigüenza-Morales D (2020) Private label and macroeconomic indicators: Europe and USA. Adm Sci 10: 91. https://doi.org/10.3390/admsci10040091 doi: 10.3390/admsci10040091
|
| [58] |
Greenland S, Senn S, Rothman KJ, et al. (2016) Statistical tests, p values, confidence intervals, and power: a guide to misinterpretations. Eur J Epidemiol 31: 337–350. https://doi.org/10.1007/s10654-016-0149-3 doi: 10.1007/s10654-016-0149-3
|
| [59] |
Groeneveld RA, Meeden G (1984) Measuring skewness and kurtosis. J Roy Stat Soc Series D 33: 391–399. https://doi.org/10.2307/2987742. doi: 10.2307/2987742
|
| [60] |
Guo Y, Strauss VY, Prieto-Alhambra D, et al. (2022) Use of machine learning for comparing disease risk scores and propensity scores under complex confounding and large sample size scenarios: a simulation study. medRxiv 1–12. https://doi.org/10.1101/2022.02.03.22270151 doi: 10.1101/2022.02.03.22270151
|
| [61] | Hajdini I, Knotek II ES, Leer J, et al. (2024) Indirect consumer inflation expectations: Theory and evidence. J Monetary Econ 103568. |
| [62] |
Hao J, Feng Q, Li J, et al. (2023) A bi‐level ensemble learning approach to complex time series forecasting: taking exchange rates as an example. J Forecasting 42: 1385–1406. https://doi.org/10.1002/for.2971 doi: 10.1002/for.2971
|
| [63] |
Harding M, Lamarche C (2021) Small steps with big data: using machine learning in energy and environmental economics. Annu Rev Resour Econ 13: 469–488. https://doi.org/10.1146/annurev-resource-100920-034117 doi: 10.1146/annurev-resource-100920-034117
|
| [64] | Hasanah SH (2021) Multivariate Adaptive Regression Splines (MARS) for Modeling The Student Status at Universitas Terbuka. J Mat MANTIK 7: 51–58. |
| [65] | Hauke J, Kossowski T (2011) Comparison of values of Pearson's and Spearman's correlation coefficients on the same sets of data. Quaest Geogr 30: 87–93. |
| [66] |
He Y, Zeng X, Li H, et al. (2022) Application of lstm model optimized by individual-ordering-based adaptive genetic algorithm in stock forecasting. Int J Intell Comput 16: 277–294. https://doi.org/10.1108/ijicc-04-2022-0104 doi: 10.1108/ijicc-04-2022-0104
|
| [67] |
Henderi H (2021) Comparison of min-max normalization and z-score normalization in the k-nearest neighbor (knn) algorithm to test the accuracy of types of breast cancer. IJIIS: Int J Inf Inf Syst 4: 13–20. https://doi.org/10.47738/ijiis.v4i1.73 doi: 10.47738/ijiis.v4i1.73
|
| [68] | Hossain MS, Mitra R (2017) The determinants of price inflation in the United States: a multivariate dynamic cointegration and causal analysis. J Dev Areas 51: 153–175. https://www.jstor.org/stable/26415701 |
| [69] |
Ibrahim A, Mirjalili S, El-Said M, et al. (2021) Wind speed ensemble forecasting based on deep learning using adaptive dynamic optimization algorithm. IEEE Access 9: 125787–125804. https://doi.org/10.1109/access.2021.3111408 doi: 10.1109/access.2021.3111408
|
| [70] |
Imbens GW, Athey S (2021) Breiman's two cultures: a perspective from econometrics. Obs Stud 7: 127–133. https://doi.org/10.1353/obs.2021.0028 doi: 10.1353/obs.2021.0028
|
| [71] |
Imron M, Utami WD, Khaulasari H, et al. (2022) Arima model of outlier detection for forecasting consumer price index (cpi). BAREKENG: J Ilmu Matematika Dan Terapan 16: 1259–1270. https://doi.org/10.30598/barekengvol16iss4pp1259-1270 doi: 10.30598/barekengvol16iss4pp1259-1270
|
| [72] |
Islam H, Islam MS, Saha S, et al. (2024) Impact of macroeconomic factors on performance of banks in bangladesh. J Ekon. https://doi.org/10.58251/ekonomi.1467784 doi: 10.58251/ekonomi.1467784
|
| [73] |
Iqbal Z, Akbar M, Amjad W (2021) Nexus of gold price-exchange rate-interest rate-oil price: lessons for monetary policy in pakistan. Int J Bus Manag 16: 1–16. https://doi.org/10.52015/nijbm.v16i1.50 doi: 10.52015/nijbm.v16i1.50
|
| [74] | Ivașcu C (2023) Can Machine Learning Models Predict Inflation? In: Proceedings of the International Conference on Business Excellence, 17: 1748–1756. |
| [75] |
Jaber AM, Ismail MT, Altaher AM (2014) Empirical mode decomposition combined with local linear quantile regression for automatic boundary correction. Abstr Appl Anal 2014: 1–8. https://doi.org/10.1155/2014/731827 doi: 10.1155/2014/731827
|
| [76] |
Jadiya AK, Chaudhary A, Thakur R (2020) Polymorphic sbd preprocessor: a preprocessing approach for social big data. Indian J Comput Syst Sci Eng 11: 953–961. https://doi.org/10.21817/indjcse/2020/v11i6/201106169 doi: 10.21817/indjcse/2020/v11i6/201106169
|
| [77] |
Jakubik J, Nazemi A, Geyer-Schulz A, et al. (2023) Incorporating financial news for forecasting Bitcoin prices based on long short-term memory networks. Quant Financ 23: 335–349. https://doi.org/10.1080/14697688.2022.2130085 doi: 10.1080/14697688.2022.2130085
|
| [78] |
Khan A, Kandel J, Tayara H, et al. (2024) Predicting the bandgap and efficiency of perovskite solar cells using machine learning methods. Mol Inform 43. https://doi.org/10.1002/minf.202300217 doi: 10.1002/minf.202300217
|
| [79] | Knotek ES, Mitchell J, Pedemonte MO, et al. (2024) The effects of interest rate increases on consumers' inflation expectations: the roles of informedness and compliance. Working Paper 24 –01 Federal Reserve Bank of Cleveland. https://doi.org/10.26509/frbc-wp-202401 |
| [80] |
Jin Q, Fan X, Liu J, et al. (2019) Using extreme gradient boosting to predict changes in tropical cyclone intensity over the western north pacific. Atmosphere 10: 341. https://doi.org/10.3390/atmos10060341 doi: 10.3390/atmos10060341
|
| [81] |
Johansen S (2009) Cointegration: Overview and development. Handbook Financ Time Ser 671–693. https://doi.org/10.1007/978-3-540-71297-8_29 doi: 10.1007/978-3-540-71297-8_29
|
| [82] |
Jung HS, Lee SH, Lee H, et al. (2023) Predicting bitcoin trends through machine learning using sentiment analysis with technical indicators. Comput Syst Sci Eng 46: 2231–2246. https://doi.org/10.32604/csse.2023.034466 doi: 10.32604/csse.2023.034466
|
| [83] |
Jurado S, Nebot À, Mugica F, et al. (2015) Hybrid methodologies for electricity load forecasting: entropy-based feature selection with machine learning and soft computing techniques. Energy 86: 276–291. https://doi.org/10.1016/j.energy.2015.04.039 doi: 10.1016/j.energy.2015.04.039
|
| [84] |
Khandelwal I, Adhikari R, Verma G (2015) Time series forecasting using hybrid arima and ann models based on dwt decomposition. Procedia Comput Sci 48: 173–179. https://doi.org/10.1016/j.procs.2015.04.167 doi: 10.1016/j.procs.2015.04.167
|
| [85] | Khodabakhsh A, Ari I, Bakır M, et al. (2020) Forecasting multivariate time-series data using LSTM and mini-batches. In: Data Science: From Research to Application, 121–129. Springer. https://doi.org/10.1007/978-3-030-37309-2_10 |
| [86] |
Kilian L, Zhou X (2021) The impact of rising oil prices on u. s. inflation and inflation expectations in 2020-23. Energy Econ 113: 106228. https://doi.org/10.2139/ssrn.3980337 doi: 10.2139/ssrn.3980337
|
| [87] |
Kitani R, Iwata S (2023) Verification of interpretability of phase-resolved partial discharge using a cnn with shap. IEEE Access 11: 4752–4762. https://doi.org/10.1109/access.2023.3236315 doi: 10.1109/access.2023.3236315
|
| [88] | Kumar SD, Subha DP (2019) Prediction of depression from EEG signal using long short term memory (LSTM). In: 2019 3rd International Conference on Trends in Electronics and Informatics (ICOEI), 1248–1253. https://doi.org/10.1109/ICOEI.2019.8862560 |
| [89] |
Kunstmann L, Pina D, Silva F, et al. (2021) Online deep learning hyperparameter tuning based on provenance analysis. J Inf Data Manage 12. https://doi.org/10.5753/jidm.2021.1924 doi: 10.5753/jidm.2021.1924
|
| [90] |
Lee K, Ayyasamy MV, Ji Y, et al. (2022) A comparison of explainable artificial intelligence methods in the phase classification of multi-principal element alloys. Sci Rep 12: 11591. https://doi.org/10.1038/s41598-022-15618-4 doi: 10.1038/s41598-022-15618-4
|
| [91] |
Lees T, Buechel M, Anderson B, et al. (2021) Benchmarking data-driven rainfall–runoff models in Great Britain: a comparison of long short-term memory (LSTM)-based models with four lumped conceptual models. Hydrol Earth Syst Sci 25: 5517–5534. https://doi.org/10.5194/hess-25-5517-2021 doi: 10.5194/hess-25-5517-2021
|
| [92] |
Lewis PA, Ray BK (1997) Modeling long-range dependence, nonlinearity, and periodic phenomena in sea surface temperatures using TSMARS. J Am Stat Assoc 92: 881–893. https://doi.org/10.1080/01621459.1997.10474043 doi: 10.1080/01621459.1997.10474043
|
| [93] |
Lewis PA, Stevens JG (1991) Nonlinear modeling of time series using multivariate adaptive regression splines (MARS). J Am Stat Assoc 86: 864–877. https://doi.org/10.1080/01621459.1991.10475126 doi: 10.1080/01621459.1991.10475126
|
| [94] |
Li G, Yang N (2022) A hybrid sarima‐lstm model for air temperature forecasting. Adv Theor Simul 6. https://doi.org/10.1002/adts.202200502 doi: 10.1002/adts.202200502
|
| [95] |
Li P, Zhang JS (2018) A new hybrid method for China's energy supply security forecasting based on ARIMA and XGBoost. Energies 11: 1687. https://doi.org/10.3390/en11071687 doi: 10.3390/en11071687
|
| [96] |
Li S, Huang H, Lu W (2021) A neural networks based method for multivariate time-series forecasting. IEEE Access 9: 63915–63924. https://doi.org/10.1109/access.2021.3075063 doi: 10.1109/access.2021.3075063
|
| [97] |
Li T, Hua M, Wu X (2020) A hybrid cnn-lstm model for forecasting particulate matter (pm2.5). IEEE Access 8: 26933–26940. https://doi.org/10.1109/access.2020.2971348 doi: 10.1109/access.2020.2971348
|
| [98] | Li X, Huo H, Liu Z (2022) Analysis and prediction of pm2.5 concentration based on lstm-xgboost-svr model. https://doi.org/10.21203/rs.3.rs-2158285/v1 |
| [99] |
Liu Z (2023) Review on the influence of machine learning methods and data science on the economics. Appl Comput Eng 22: 137–141. https://doi.org/10.54254/2755-2721/22/20231208 doi: 10.54254/2755-2721/22/20231208
|
| [100] |
Liu Y, Yang Y, Chin RJ, et al. (2023) Long Short-Term Memory (LSTM) Based Model for Flood Forecasting in Xiangjiang River. J Civil Eng 27: 5030–5040. https://doi.org/10.1007/s12205-023-2469-7 doi: 10.1007/s12205-023-2469-7
|
| [101] |
Lv C, An S, Qiao B, et al. (2021) Time series analysis of hemorrhagic fever with renal syndrome in mainland china by using an xgboost forecasting model. Bmc Infect Dis 21. https://doi.org/10.1186/s12879-021-06503-y doi: 10.1186/s12879-021-06503-y
|
| [102] |
Medeiros MC, Vasconcelos GF, Veiga Á, et al. (2019) Forecasting inflation in a data-rich environment: the benefits of machine learning methods. J Bus Econ Stat 39: 98–119. https://doi.org/10.1080/07350015.2019.1637745 doi: 10.1080/07350015.2019.1637745
|
| [103] |
Mitchell DJB (1999) Review of Getting Prices Right: The Debate over the Consumer Price Index, by D. Baker. Ind Labor Relat Rev 52: 317–318. https://doi.org/10.2307/2525170 doi: 10.2307/2525170
|
| [104] | Mohammed AA, Immanuel PJ, Roobini MS (2023) Forecasting Consumer Price Index (CPI) Using Deep Learning and Hybrid Ensemble Technique. 2023 International Conference on Advances in Computing, Communication and Applied Informatics (ACCAI), Chennai, India, 1–8. https://doi.org/10.1109/ACCAI58221.2023.10200153 |
| [105] |
Mohan S, Hutson A, MacDonald I, et al. (2019) Impact of macroeconomic indicators on housing prices. Int J Hous Mark Anal 12: 1055–1071. https://doi.org/10.1108/IJHMA-09-2018-0070 doi: 10.1108/IJHMA-09-2018-0070
|
| [106] |
Mulenga M, Kareem SA, Sabri AQM, et al. (2021) Stacking and chaining of normalization methods in deep learning-based classification of colorectal cancer using gut microbiome data. IEEE Access 9: 97296–97319. https://doi.org/10.1109/access.2021.3094529 doi: 10.1109/access.2021.3094529
|
| [107] |
Murat N (2023) Outlier detection in statistical modeling via multivariate adaptive regression splines. Commun Stat-Simul C 52: 3379–3390. https://doi.org/10.1080/03610918.2021.2007400 doi: 10.1080/03610918.2021.2007400
|
| [108] |
Muruganandam NS, Arumugam U (2023) Dynamic ensemble multivariate time series forecasting model for pm2.5. Comput Syst Sci Eng 44: 979–989. https://doi.org/10.32604/csse.2023.024943 doi: 10.32604/csse.2023.024943
|
| [109] |
Naidu S, Pandaram A, Chand A (2017) A Johansen cointegration test for the relationship between remittances and economic growth of Japan. Mod Appl Sci 11: 137–151. https://doi.org/10.5539/mas.v11n10p137 doi: 10.5539/mas.v11n10p137
|
| [110] |
Naser AH, Badr AH, Henedy SN, et al. (2022) Application of Multivariate Adaptive Regression Splines (MARS) approach in prediction of compressive strength of eco-friendly concrete. Case Stud Constr Mat 17: e01262. https://doi.org/10.1016/j.cscm.2022.e01262 doi: 10.1016/j.cscm.2022.e01262
|
| [111] |
Nguyen LT, Chung HH, Tuliao KV, et al. (2020) Using xgboost and skip-gram model to predict online review popularity. SAGE Open 10: 215824402098331. https://doi.org/10.1177/2158244020983316 doi: 10.1177/2158244020983316
|
| [112] | Nguyen TT, Nguyen HG, Lee JY, et al. (2023) The consumer price index prediction using machine learning approaches: Evidence from the United States. Heliyon 9. |
| [113] |
Njenga JK (2024) Analysis and Forecasting of Consumer Price Index (CPI) in Kenya and South Africa using Holt Winter Model. Asian J Econ Bus Account 24: 322–331. https://doi.org/10.9734/ajeba/2024/v24i41283 doi: 10.9734/ajeba/2024/v24i41283
|
| [114] |
Noorunnahar M, Chowdhury AH, Mila FA. (2023) A tree based extreme gradient boosting (xgboost) machine learning model to forecast the annual rice production in bangladesh. Plos One 18: e0283452. https://doi.org/10.1371/journal.pone.0283452 doi: 10.1371/journal.pone.0283452
|
| [115] | Pan J, Zhang Z, Peters S, et al. (2023) Cerebrovascular disease case identification in inpatient electronic medical record data using natural language processing. https://doi.org/10.21203/rs.3.rs-2640617/v1 |
| [116] | Paparoditis E, Politis DN (2018) The asymptotic size and power of the augmented Dickey–Fuller test for a unit root. Econ Rev 37: 955–973. |
| [117] |
Papíková L, Papík M (2022) Effects of classification, feature selection, and resampling methods on bankruptcy prediction of small and medium‐sized enterprises. Intell Syst Account Financ Manage 29: 254–281. https://doi.org/10.1002/isaf.1521 doi: 10.1002/isaf.1521
|
| [118] |
Park HJ, Kim Y, Kim HY (2022) Stock market forecasting using a multi-task approach integrating long short-term memory and the random forest framework. Appl Soft Comput 114: 108106. https://doi.org/10.1016/j.asoc.2021.108106 doi: 10.1016/j.asoc.2021.108106
|
| [119] |
Phillips PC, Perron P (1988) Testing for a unit root in time series regression. Biometrika 75: 335–346. https://doi.org/10.1093/biomet/75.2.335 doi: 10.1093/biomet/75.2.335
|
| [120] | Poh CW, Tan R (1997) Performance of Johansen's cointegration test. In: East Asian Economic Issues: Volume III, 402–414. |
| [121] |
Porcher R, Thomas G (2003) Order determination in nonlinear time series by penalized least-squares. Commun Stat-Simul C 32: 1115–1129. https://doi.org/10.1081/SAC-120023881 doi: 10.1081/SAC-120023881
|
| [122] |
Qinghe Z, Wen X, Huang B, et al. (2022) Optimised extreme gradient boosting model for short term electric load demand forecasting of regional grid system. Sci Rep 12: 19282. https://doi.org/10.1038/s41598-022-22024-3 doi: 10.1038/s41598-022-22024-3
|
| [123] |
Radev L, Golitsis P, Mitreva M. (2023) Economic and financial determinants of gold etf price volatility on the u. s. futures market (comex). J Econ 8: 12–26. https://doi.org/10.46763/joe2382012r doi: 10.46763/joe2382012r
|
| [124] |
Raheem Ahmed R, Vveinhardt J, Štreimikienė D, et al. (2017) Estimation of long-run relationship of inflation (cpi & wpi), and oil prices with kse-100 index: Evidence from johansen multivariate cointegration approach. Technol Econ Dev Econ 23: 567–588. https://doi.org/10.3846/20294913.2017.1289422 doi: 10.3846/20294913.2017.1289422
|
| [125] |
Reddy S, Akashdeep S, Harshvardhan R, et al. (2022) Stacking Deep learning and Machine learning models for short-term energy consumption forecasting. Adv Eng Inform 52: 101542. https://doi.org/10.1016/j.aei.2022.101542 doi: 10.1016/j.aei.2022.101542
|
| [126] | Reed SB (2014) One hundred years of price change: The Consumer Price Index and the American inflation experience. Monthly Lab Rev 137: 1. |
| [127] |
Rezaie-Balf M, Zahmatkesh Z, Kim S (2017) Soft computing techniques for rainfall-runoff simulation: local non–parametric paradigm vs. model classification methods. Water Resour Manag 31: 3843–3865. https://doi.org/10.1007/s11269-017-1711-9 doi: 10.1007/s11269-017-1711-9
|
| [128] | Ribeiro MHDM, Silva RG, Mariani VC, et al. (2021) Dengue cases forecasting based on extreme gradient boosting ensemble with coyote optimization. Anais Do 15. Congresso Brasileiro De Inteligência Computacional. https://doi.org/10.21528/cbic2021-36 |
| [129] |
Ribeiro MHDM, Stefenon SF, Lima JD, et al. (2020) Electricity price forecasting based on self-adaptive decomposition and heterogeneous ensemble learning. Energies 13: 5190. https://doi.org/10.3390/en13195190 doi: 10.3390/en13195190
|
| [130] | Rippy D (2014) The first hundred years of the Consumer Price Index: a methodological and political history. Monthly Lab Rev 137: 1. |
| [131] | Rosado R, Abreu AJ, Arencibia JC, et al. (2021) Consumer price index forecasting based on univariate time series and a deep neural network. In: International Workshop on Artificial Intelligence and Pattern Recognition, 33–42. Cham: Springer. https://doi.org/10.1007/978-3-030-89691-1_4 |
| [132] |
Rodríguez-Pérez R, Bajorath J (2020) Interpretation of machine learning models using shapley values: application to compound potency and multi-target activity predictions. J Comput Aid Mol Des 34: 1013–1026. https://doi.org/10.1007/s10822-020-00314-0 doi: 10.1007/s10822-020-00314-0
|
| [133] |
Sagheer A, Kotb M (2019) Unsupervised pre-training of a deep LSTM-based stacked autoencoder for multivariate time series forecasting problems. Sci Rep 9: 19038. https://doi.org/10.1038/s41598-019-55320-6 doi: 10.1038/s41598-019-55320-6
|
| [134] | Saputra AW, Wibawa AP, Pujianto U, et al. (2022) LSTM-based Multivariate Time-Series Analysis: A Case of Journal Visitors Forecasting. ILKOM J Ilm 14: 57–62. |
| [135] |
Sarangi PK, Sahoo AK, Sinha S (2022) Modeling consumer price index: a machine learning approach. Macromol Sym 401. https://doi.org/10.1002/masy.202100349 doi: 10.1002/masy.202100349
|
| [136] |
Setyanto A, Laksito A, Alarfaj F, et al. (2022). Arabic language opinion mining based on long short-term memory (LSTM). Appl Sci 12: 4140. https://doi.org/10.3390/app12094140 doi: 10.3390/app12094140
|
| [137] |
Shahbaz M, Khraief N, Mahalik MK (2020) Investigating the environmental Kuznets's curve for Sweden: Evidence from multivariate adaptive regression splines (MARS). Empir Econ 59: 1883–1902. https://doi.org/10.1007/s00181-019-01698-1 doi: 10.1007/s00181-019-01698-1
|
| [138] |
Sharda VN, Prasher SO, Patel RM, et al. (2008) Performance of Multivariate Adaptive Regression Splines (MARS) in predicting runoff in mid-Himalayan micro-watersheds with limited data/Performances de régressions par splines multiples et adaptives (MARS) pour la prévision d'écoulement au sein de micro-bassins versants Himalayens d'altitudes intermédiaires avec peu de données. Hydrolog Sci J 53: 1165–1175. https://doi.org/10.1623/hysj.53.6.1165 doi: 10.1623/hysj.53.6.1165
|
| [139] |
Sharma SS (2016) Can consumer price index predict gold price returns? Econ Model 55: 269–278. https://doi.org/10.1016/j.econmod.2016.02.014 doi: 10.1016/j.econmod.2016.02.014
|
| [140] |
Shi F, Lu S, Gu J, et al. (2022) Modeling and evaluation of the permeate flux in forward osmosis process with machine learning. Ind Eng Chem Res 61: 18045–18056. https://doi.org/10.1021/acs.iecr.2c03064 doi: 10.1021/acs.iecr.2c03064
|
| [141] |
Shiferaw Y (2023) An understanding of how gdp, unemployment and inflation interact and change across time and frequency. Economies 11: 131. https://doi.org/10.3390/economies11050131 doi: 10.3390/economies11050131
|
| [142] | Siami-Namini S, Tavakoli N, Namin AS (2019) The performance of LSTM and BiLSTM in forecasting time series. In: 2019 IEEE International conference on big data (Big Data), 3285–3292, IEEE. |
| [143] |
Sibai N, El-Moursy F, Sibai A (2024) Forecasting the consumer price index: a comparative study of machine learning methods. Int J Comput Digit Syst 15: 487–497. https://doi.org/10.12785/ijcds/150137 doi: 10.12785/ijcds/150137
|
| [144] | Simsek AI (2024) Improving the Performance of Stock Price Prediction: A Comparative Study of Random Forest, XGBoost, and Stacked Generalization Approaches. In: Revolutionizing the Global Stock Market: Harnessing Blockchain for Enhanced Adaptability, 83–99. IGI Global. |
| [145] | Subhani MI (2009) Relationship between Consumer Price Index (CPI) and government bonds. S Asian J Manage Sci 3: 11–17. |
| [146] |
Sukarsa IM, Pinata NNP, Rusjayanthi NKD, et al. (2021) Estimation of gourami supplies using gradient boosting decision tree method of xgboost. TEM J 144–151. https://doi.org/10.18421/tem101-17 doi: 10.18421/tem101-17
|
| [147] | Sumita S, Nakagawa H, Tsuchiya T (2023) Xtune: an xai-based hyperparameter tuning method for time-series forecasting using deep learning. https://doi.org/10.21203/rs.3.rs-3008932/v1Shimon |
| [148] | Sun Y, Tian L (2022) Research on stock prediction based on simulated annealing algorithm and ensemble neural learning. Third International Conference on Computer Science and Communication Technology (ICCSCT 2022). https://doi.org/10.1117/12.2663138 |
| [149] |
Tan KR, Seng JJB, Kwan YH, et al. (2021) Evaluation of machine learning methods developed for prediction of diabetes complications: a systematic review. J Diabetes Sci Techn 17: 474–489. https://doi.org/10.1177/19322968211056917 doi: 10.1177/19322968211056917
|
| [150] |
Temür AS, Yildiz Ş (2021) Comparison of forecasting performance of arima lstm and hybrid models for the sales volume budget of a manufacturing enterprise. Istanb Bus Res 50: 15–46. https://doi.org/10.26650/ibr.2021.51.0117 doi: 10.26650/ibr.2021.51.0117
|
| [151] |
Thapa KB (2023) Macroeconomic determinants of the stock market in nepal: an empirical analysis. NCC J 8: 65–73. https://doi.org/10.3126/nccj.v8i1.63087 doi: 10.3126/nccj.v8i1.63087
|
| [152] |
Tian L, Feng L, Sun Y, et al. (2021) Forecast of lstm-xgboost in stock price based on bayesian optimization. Intell Autom Soft Comput 29: 855–868. https://doi.org/10.32604/iasc.2021.016805 doi: 10.32604/iasc.2021.016805
|
| [153] |
Toraman C, Basarir Ç (2014) The long run relationship between stock market capitalization rate and interest rate: Co-integration approach. Procedia-Soc Behav Sci 143: 1070–1073. https://doi.org/10.1016/j.sbspro.2014.07.557 doi: 10.1016/j.sbspro.2014.07.557
|
| [154] |
Upadhyaya Y, Kharel K (2022) Inflation with gdp, unemployment and remittances: an outline of the joint effect on nepalese economy. Interd J Manage Soc Sci 3: 154–163. https://doi.org/10.3126/ijmss.v3i1.50244 doi: 10.3126/ijmss.v3i1.50244
|
| [155] |
Utama ABP, Wibawa AP, Muladi M, et al. (2022) Pso based hyperparameter tuning of cnn multivariate time- series analysis. J Online Inform 7: 193–202. https://doi.org/10.15575/join.v7i2.858 doi: 10.15575/join.v7i2.858
|
| [156] |
Varian HR (2014) Big data: New tricks for econometrics. J Econ Perspect 28: 3–28. https://doi.org/10.1257/jep.28.2.3 doi: 10.1257/jep.28.2.3
|
| [157] |
Vasco-Carofilis RA, Gutiérrez–Naranjo MA, Cárdenas‐Montes M (2020) Pbil for optimizing hyperparameters of convolutional neural networks and stl decomposition. Lect Notes Comput Sci 147–159. https://doi.org/10.1007/978-3-030-61705-9_13 doi: 10.1007/978-3-030-61705-9_13
|
| [158] |
Vlachas PR, Byeon W, Wan Z, et al. (2018) Data-driven forecasting of high-dimensional chaotic systems with long short-term memory networks. P Roy Soc A-Math Phy 474: 20170844. https://doi.org/10.1098/rspa.2017.0844 doi: 10.1098/rspa.2017.0844
|
| [159] |
Wan R, Mei S, Wang J, et al. (2019) Multivariate temporal convolutional network: A deep neural networks approach for multivariate time series forecasting. Electronics 8: 876. https://doi.org/10.3390/electronics8080876 doi: 10.3390/electronics8080876
|
| [160] |
Wang L, Zhao L (2022) Digital economy meets artificial intelligence: forecasting economic conditions based on big data analytics. Mob Inf Syst 2022: 1–9. https://doi.org/10.1155/2022/7014874 doi: 10.1155/2022/7014874
|
| [161] |
Wang L, Haofei Z, Su J, et al. (2013) An arima‐ann hybrid model for time series forecasting. Syst Res Behav Sci 30: 244–259. https://doi.org/10.1002/sres.2179 doi: 10.1002/sres.2179
|
| [162] |
Wang W, Shi Y, Lyu G, et al. (2017) Electricity consumption prediction using xgboost based on discrete wavelet transform. DEStech T Comput Sci Eng. https://doi.org/10.12783/dtcse/aiea2017/15003 doi: 10.12783/dtcse/aiea2017/15003
|
| [163] |
Wang Y, Ye G (2020) Forecasting method of stock market volatility in time series data based on mixed model of arima and xgboost. China Commun 17: 205–221. https://doi.org/10.23919/jcc.2020.03.017 doi: 10.23919/jcc.2020.03.017
|
| [164] |
Wang Y, Bao F, Hua Q, et al. (2021). Short-term solar power forecasting: a combined long short-term memory and gaussian process regression method. Sustainability 13: 3665. https://doi.org/10.3390/su13073665 doi: 10.3390/su13073665
|
| [165] |
Wei B, Yue J, Rao Y (2017) A deep learning framework for financial time series using stacked autoencoders and long-short term memory. Plos One 12: e0180944. https://doi.org/10.1371/journal.pone.0180944 doi: 10.1371/journal.pone.0180944
|
| [166] | Weinzierl M (2014) Seesaws and social security benefits indexing(No. w20671). National Bureau of Economic Research, Cambridge. |
| [167] |
Widiputra H, Mailangkay ABL, Gautama E (2021) Multivariate cnn-lstm model for multiple parallel financial time-series prediction. Complexity 2021: 1–14. https://doi.org/10.1155/2021/9903518 doi: 10.1155/2021/9903518
|
| [168] |
Qureshi M, Khan A, Daniyal M, et al. (2023) A comparative analysis of traditional sarima and machine learning models for cpi data modelling in pakistan. Appl Comput Intell S 2023: 1–10. https://doi.org/10.1155/2023/3236617 doi: 10.1155/2023/3236617
|
| [169] |
Xiao C, Wang Y, Wang S (2023) Machine learning to set hyperparameters for overlapping community detection algorithms. J Eng 2023. https://doi.org/10.1049/tje2.12292 doi: 10.1049/tje2.12292
|
| [170] |
Xu J, He J, Gu J, et al. (2022) Financial Time Series Prediction Based on XGBoost and Generative Adversarial Networks. Int J Circ Syst Signal Process 16: 637–645. https://doi.org/10.46300/9106.2022.16.79 doi: 10.46300/9106.2022.16.79
|
| [171] |
Yang C, Guo S (2021) Inflation prediction method based on deep learning. Comput Intel Neurosc 2021. https://doi.org/10.1155/2021/1071145 doi: 10.1155/2021/1071145
|
| [172] |
Yang L, Shami A (2020) On hyperparameter optimization of machine learning algorithms: theory and practice. Neurocomputing 415: 295–316. https://doi.org/10.1016/j.neucom.2020.07.061 doi: 10.1016/j.neucom.2020.07.061
|
| [173] |
Ye M, Mohammed KS, Tiwari S, et al. (2023) The effect of the global supply chain and oil prices on the inflation rates in advanced economies and emerging markets. Geo J 58: 2805–2817. https://doi.org/10.1002/gj.4742 doi: 10.1002/gj.4742
|
| [174] |
Yilmazkuday H (2024) Pass‐through of shocks into different u.s. prices. Rev Int Econ 32: 1300–1315. https://doi.org/10.1111/roie.12726 doi: 10.1111/roie.12726
|
| [175] |
Yildiz M, Ozdemir L (2022) Determination of the sensitivity of stock index to macroeconomic and psychological factors by MARS method, in: Insurance and Risk Management for Disruptions in Social, Economic and Environmental Systems: Decision and Control Allocations within New Domains of Risk. Emerald Publishing Limited 2022: 81–105. https://doi.org/10.1108/978-1-80117-139-720211005 doi: 10.1108/978-1-80117-139-720211005
|
| [176] |
Yuan M, Yang N, Qian Z, et al. (2020) What makes an online review more helpful: an interpretation framework using xgboost and shap values. J Theor Appl El Comm 16: 466–490. https://doi.org/10.3390/jtaer16030029 doi: 10.3390/jtaer16030029
|
| [177] |
Zahara SS, Ilmiddaviq MB (2020) Consumer price index prediction using Long Short Term Memory (LSTM) based cloud computing. J Phys 1456: 1–8, IOP Publishing. https://doi.org/10.1088/1742-6596/1456/1/012022 doi: 10.1088/1742-6596/1456/1/012022
|
| [178] |
Zazo R, Lozano-Diez A, Gonzalez-Dominguez J, et al. (2016) Language identification in short utterances using long short-term memory (LSTM) recurrent neural networks. PloS One 11: e0146917. https://doi.org/10.1371/journal.pone.0146917 doi: 10.1371/journal.pone.0146917
|
| [179] | Zhai N, Yao P, Zhou X (2020) Multivariate time series forecast in industrial process based on XGBoost and GRU. In: 2020 IEEE 9th Joint International Information Technology and Artificial Intelligence Conference (ITAIC) 9: 1397–1400. |
| [180] |
Zhang J, Meng Y, Jin W (2021) A novel hybrid deep learning model for sugar price forecasting based on time series decomposition. Math Probl Eng 2021: 1–9. https://doi.org/10.1155/2021/6507688 doi: 10.1155/2021/6507688
|
| [181] |
Zhang J, Wen J, Yang Z (2022) China's GDP forecasting using Long Short Term Memory Recurrent Neural Network and Hidden Markov Model. Plos One 17: e0269529. https://doi.org/10.1371/journal.pone.0269529 doi: 10.1371/journal.pone.0269529
|
| [182] |
Zhang X, Yang E (2024) Have housing value indicators changed during COVID? Housing value prediction based on unemployment, construction spending, and housing consumer price index. Int J Hous Mark Anal 17: 242–260. https://doi.org/10.1108/IJHMA-01-2023-0015 doi: 10.1108/IJHMA-01-2023-0015
|
| [183] |
Zhou S, Zhou L, Mao M, et al. (2019) An optimized heterogeneous structure lstm network for electricity price forecasting. IEEE Access 7: 108161–108173. https://doi.org/10.1109/access.2019.2932999 doi: 10.1109/access.2019.2932999
|
| [184] | Zhou X, Pranolo A, Mao Y (2023) AB-LSTM: Attention Bidirectional Long Short-Term Memory for Multivariate Time-Series Forecasting. In: 2023 International Conference on Computer, Electronics & Electrical Engineering & their Applications (IC2E3), 1–6. |
| [185] | Zhou Z, Song Z, Ren T (2022) Predicting China's CPI by Scanner Big Data. arXiv preprint arXiv: 2211.16641. |
| [186] |
Zhu C, Ma X, Zhang C, et al. (2023) Information granules-based long-term forecasting of time series via BPNN under three-way decision framework. Inf Sci 634: 696–715. https://doi.org/10.1016/j.ins.2023.03.133 doi: 10.1016/j.ins.2023.03.133
|








Figures(9) / Tables(14)
Yunus Emre Gur. Development and application of machine learning models in US consumer price index forecasting: Analysis of a hybrid approach[J]. Data Science in Finance and Economics, 2024, 4(4): 469-513. doi: 10.3934/DSFE.2024020







 DownLoad:
DownLoad: