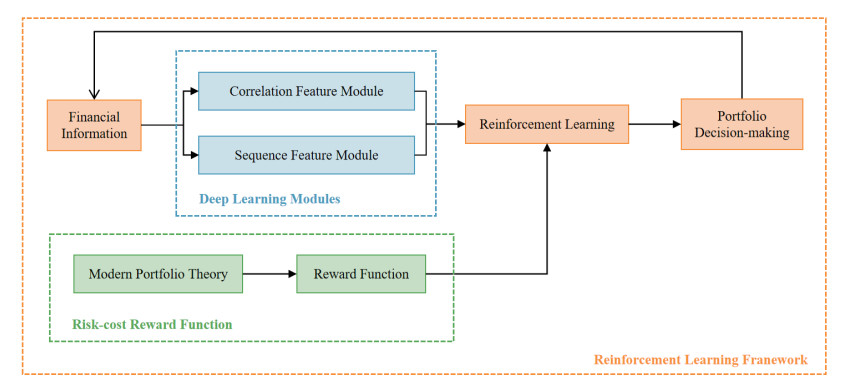
Portfolio optimization is an important financial task that has received widespread attention in the field of artificial intelligence. In this paper, a novel deep portfolio optimization (DPO) framework was proposed, combining deep learning and reinforcement learning with modern portfolio theory. DPO not only has the advantages of machine learning methods in investment decision-making, but also retains the essence of modern portfolio theory in portfolio optimization. Additionaly, it was crucial to simultaneously consider the time series and complex asset correlations of financial market information. Therefore, in order to improve DPO performance, features of assets information were extracted and fused. In addition, a novel risk-cost reward function was proposed, which realized optimal portfolio decision-making considering transaction cost and risk factors through reinforcement learning. Our results showed the superiority and generalization of the DPO framework for portfolio optimization tasks. Experiments conducted on two real-world datasets validated that DPO achieved the highest accumulative portfolio value compared to other strategies, demonstrating strong profitability. Its Sharpe ratio and maximum drawdown also performed excellently, indicating good economic benefits and achieving a trade-off between portfolio returns and risk. Additionally, the extraction and fusion of financial information features can significantly improve the applicability and effectiveness of DPO.
Citation: Ruyu Yan, Jiafei Jin, Kun Han. Reinforcement learning for deep portfolio optimization[J]. Electronic Research Archive, 2024, 32(9): 5176-5200. doi: 10.3934/era.2024239
Portfolio optimization is an important financial task that has received widespread attention in the field of artificial intelligence. In this paper, a novel deep portfolio optimization (DPO) framework was proposed, combining deep learning and reinforcement learning with modern portfolio theory. DPO not only has the advantages of machine learning methods in investment decision-making, but also retains the essence of modern portfolio theory in portfolio optimization. Additionaly, it was crucial to simultaneously consider the time series and complex asset correlations of financial market information. Therefore, in order to improve DPO performance, features of assets information were extracted and fused. In addition, a novel risk-cost reward function was proposed, which realized optimal portfolio decision-making considering transaction cost and risk factors through reinforcement learning. Our results showed the superiority and generalization of the DPO framework for portfolio optimization tasks. Experiments conducted on two real-world datasets validated that DPO achieved the highest accumulative portfolio value compared to other strategies, demonstrating strong profitability. Its Sharpe ratio and maximum drawdown also performed excellently, indicating good economic benefits and achieving a trade-off between portfolio returns and risk. Additionally, the extraction and fusion of financial information features can significantly improve the applicability and effectiveness of DPO.

| [1] | Z. Jiang, D. Xu, J. Liang, A deep reinforcement learning framework for the financial Portfolio management problem, preprint, arXiv: 1706.10059. |
| [2] |
S. Gu, B. Kelly, D. Xiu, Empirical asset pricing via machine learning, Rev. Financ. Stud., 33 (2020), 2223–2273. https://doi.org/10.1093/rfs/hhaa009 doi: 10.1093/rfs/hhaa009

|
| [3] |
M. Leippold, Q. Wang, W. Zhou, Machine learning in the Chinese stock market, J. Financ. Econ., 145 (2022), 64–82. https://doi.org/10.1016/j.jfineco.2021.08.017 doi: 10.1016/j.jfineco.2021.08.017
|
| [4] | H. Markowitz, Portfolio selection, J. Financ., 7 (1952), 71–91. |
| [5] |
A. V. Olivares-Nadal, V. DeMiguel, Technical note—A robust perspective on transaction costs in portfolio optimization, Oper. Res., 66 (2018), 733–739. https://doi.org/10.1287/opre.2017.1699 doi: 10.1287/opre.2017.1699
|
| [6] |
C. H. Hsieh, On asymptotic log-optimal portfolio optimization, Automatica, 151 (2023), 110901. https://doi.org/10.1016/j.automatica.2023.110901 doi: 10.1016/j.automatica.2023.110901
|
| [7] |
R. Kan, X. Wang, G. Zhou, Optimal portfolio choice with estimation risk: No risk-free asset case, Manage. Sci., 68 (2022), 2047–2068. https://doi.org/10.1287/mnsc.2021.3989 doi: 10.1287/mnsc.2021.3989
|
| [8] |
S. Almahdi, S. Y. Yang, An adaptive portfolio trading system: A risk-return portfolio optimization using recurrent reinforcement learning with expected maximum drawdown, Expert Syst. Appl., 87 (2017), 267–279. https://doi.org/10.1016/j.eswa.2017.06.023 doi: 10.1016/j.eswa.2017.06.023
|
| [9] |
Y. Zhang, P. Zhao, Q. Wu, B. Li, J. Huang, M. Tan, Cost-sensitive portfolio selection via deep reinforcement learning, IEEE T. Knowl. Data Eng., 34 (2020), 236–248. https://doi.org/10.1109/TKDE.2020.2979700 doi: 10.1109/TKDE.2020.2979700
|
| [10] | W. F. Sharpe, Capital asset prices: A theory of market equilibrium under conditions of risk, J. Financ., 19 (1964), 425–442. https://onlinelibrary.wiley.com/doi/pdf/10.1111/j.1540-6261.1964.tb02865.x |
| [11] |
B. V. de M. Mendes, R. C. Lavrado, Implementing and testing the maximum drawdown at risk, Financ. Res. Lett., 22 (2017), 95–100. https://doi.org/10.1016/j.frl.2017.06.001 doi: 10.1016/j.frl.2017.06.001
|
| [12] | E. F. Fama, Efficient capital markets: A review of theory and empirical work, J. Financ., 25 (1970), 383–417. https://jstor.66557.net/stable/pdf/2325486 |
| [13] |
J. Schmidhuber, Deep learning in neural networks: An overview, Neural Networks, 61 (2015), 85–117. https://doi.org/10.1016/j.neunet.2014.09.003 doi: 10.1016/j.neunet.2014.09.003
|
| [14] |
T. Fischer, C. Krauss, Deep learning with long short-term memory networks for financial market predictions, Eur. J. Oper. Res., 270 (2018), 654–669. https://doi.org/ 10.1016/j.ejor.2017.11.054 doi: 10.1016/j.ejor.2017.11.054
|
| [15] |
A. Vidal, W. Kristjanpoller, Gold volatility prediction using a CNN-LSTM approach, Expert Syst. Appl., 157 (2020), 113481. https://doi.org/10.1016/j.eswa.2020.113481 doi: 10.1016/j.eswa.2020.113481
|
| [16] |
Y. Ma, R. Han, W. Wang, Portfolio optimization with return prediction using deep learning and machine learning, Expert Syst. Appl., 165 (2021), 113973. https://doi.org/10.1016/j.eswa.2020.113973 doi: 10.1016/j.eswa.2020.113973
|
| [17] |
T. H. Nguyen, K. Shirai, J. Velcin, Sentiment analysis on social media for stock movement prediction, Expert Syst. Appl., 42 (2015), 9603–9611. https://doi.org/10.1016/j.eswa.2015.07.052 doi: 10.1016/j.eswa.2015.07.052
|
| [18] | L. Chen, H. Zhang, J. Xiao, X. He, S. Pu, S. F. Chang, Counterfactual critic multi-agent training for scene graph generation, in Proceedings of the IEEE/CVF International Conference on Computer Vision, (ICCV), (2019), 4613–4623. https://doi.org/10.1109/ICCV.2019.00471 |
| [19] |
J. Jang, N. Seong, Deep reinforcement learning for stock portfolio optimization by connecting with modern portfolio theory, Expert Syst. Appl., 218 (2023), 119556. https://doi.org/10.1016/j.eswa.2023.119556 doi: 10.1016/j.eswa.2023.119556
|
| [20] |
P. Beraldi, A. Violi, M. Ferrara, C. Ciancio, B. A. Pansera, Dealing with complex transaction costs in portfolio management, Ann. Oper. Res., 299 (2021), 7–22. https://doi.org/10.1007/s10479-019-03210-5 doi: 10.1007/s10479-019-03210-5
|
| [21] |
Y. Ma, Z. Li, Robust portfolio choice with limited attention, Electron. Res. Arch., 31 (2023), 3666–3687. https://doi.org/10.3934/era.2023186 doi: 10.3934/era.2023186
|
| [22] |
M. García-Galicia, A. A. Carsteanu, J. B. Clempner, Continuous-time reinforcement learning approach for portfolio management with time penalization, Expert Syst. Appl., 129 (2019), 27–36. https://doi.org/10.1016/j.eswa.2019.03.055 doi: 10.1016/j.eswa.2019.03.055
|
| [23] | H. M. Markowitz, Foundations of portfolio theory, J. Financ., 46 (1991), 469–477. https://www.jstor.org/stable/2328831 |
| [24] |
G. Y. Ban, N. El Karoui, A. E. Lim, Machine learning and portfolio optimization, Manage. Sci., 64 (2018), 1136–1154. https://doi.org/10.1287/mnsc.2016.2644 doi: 10.1287/mnsc.2016.2644
|
| [25] | Y. Ye, H. Pei, B. Wang, P. Y. Chen, Y. Zhu, J. Xiao, et al., Reinforcement-learning based portfolio management with augmented asset movement prediction states, in Proceedings of the AAAI Conference on Artificial Intelligence, (AAAI), (2020), 1112–1119. https://doi.org/10.1609/aaai.v34i01.5462 |
| [26] | A. Borodin, R. El-Yaniv, V. Gogan, Can we learn to beat the best stock, J. Artif. Intell. Res., (NeurIPS), 21 (2004), 579–594. |
| [27] | L. Gao, W. Zhang, Weighted moving average passive aggressive algorithm for online portfolio selection, in 2013 5th International Conference on Intelligent Human-Machine Systems and Cybernetics, IEEE (IHMSC), (2013), 327–330. https://doi.org/10.1109/IHMSC.2013.84 |
| [28] |
D. Huang, J. Zhou, B. Li, S. C. Hoi, S. Zhou, Robust median reversion strategy for online portfolio selection, IEEE T. Knowl. Data Eng., 28 (2016), 2480–2493. https://doi.org/10.1109/TKDE.2016.2563433 doi: 10.1109/TKDE.2016.2563433
|





Figures(6) / Tables(4)
Ruyu Yan, Jiafei Jin, Kun Han. Reinforcement learning for deep portfolio optimization[J]. Electronic Research Archive, 2024, 32(9): 5176-5200. doi: 10.3934/era.2024239







 DownLoad:
DownLoad: