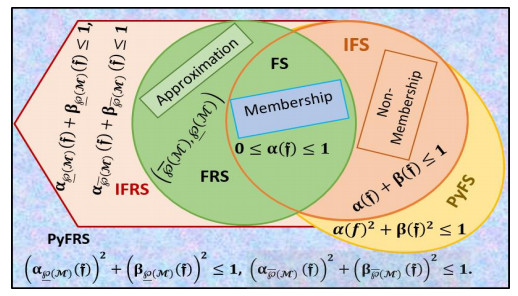
In real life, with the trend of outsourcing logistics activities, choosing a third-party logistics (3PL) provider has become an inevitable choice for shippers. One of the most difficult decisions logistics consumers are facing the selecting the 3PL provider that best meets their needs. Decision making (DM) is an important in dealing with such situations because it allows them to make reliable decisions in a short period of time, as incorrect decisions can result in huge financial losses. In this regard, this article provides a new multi criteria group decision making method (MCGDM) under Pythagorean fuzzy rough (PyFR) set. A series of new PyFR Einstein weighted averaging aggregation operators and their basic aspects are described in depth. To evaluate the weights of decision experts and criteria weights we established the PyFR entropy measure. Further, using multiple aggregation methods based on PyFR information, a novel algorithm is offered to solve issues with ambiguous or insufficient data to obtain reliable and preferable results. First, decision-experts use PyFR sets to represent their evaluation information on alternatives based on the criteria. Then, apply all these proposed PyFR Einstein aggregation lists to rank all alternatives and find the best optimal result. Finally, to demonstrate the feasibility of the proposed PyFR decision system, a real example of choosing a 3PL is given.
Citation: Shougi S. Abosuliman, Abbas Qadir, Saleem Abdullah. Multi criteria group decision (MCGDM) for selecting third-party logistics provider (3PL) under Pythagorean fuzzy rough Einstein aggregators and entropy measures[J]. AIMS Mathematics, 2023, 8(8): 18040-18065. doi: 10.3934/math.2023917
In real life, with the trend of outsourcing logistics activities, choosing a third-party logistics (3PL) provider has become an inevitable choice for shippers. One of the most difficult decisions logistics consumers are facing the selecting the 3PL provider that best meets their needs. Decision making (DM) is an important in dealing with such situations because it allows them to make reliable decisions in a short period of time, as incorrect decisions can result in huge financial losses. In this regard, this article provides a new multi criteria group decision making method (MCGDM) under Pythagorean fuzzy rough (PyFR) set. A series of new PyFR Einstein weighted averaging aggregation operators and their basic aspects are described in depth. To evaluate the weights of decision experts and criteria weights we established the PyFR entropy measure. Further, using multiple aggregation methods based on PyFR information, a novel algorithm is offered to solve issues with ambiguous or insufficient data to obtain reliable and preferable results. First, decision-experts use PyFR sets to represent their evaluation information on alternatives based on the criteria. Then, apply all these proposed PyFR Einstein aggregation lists to rank all alternatives and find the best optimal result. Finally, to demonstrate the feasibility of the proposed PyFR decision system, a real example of choosing a 3PL is given.

| [1] |
C. N. Wang, N. A. T. Nguyen, T. T. Dang, C. M. Lu, A compromised decision-making approach to third-party logistics selection in sustainable supply chain using fuzzy AHP and fuzzy VIKOR methods, Mathematics, 9 (2021), 886. https://doi.org/10.3390/math9080886 doi: 10.3390/math9080886

|
| [2] |
L. A. Zadeh, Fuzzy sets, Inf. Control, 8 (1965), 338–353. https://doi.org/10.1016/S0019-9958(65)90241-X doi: 10.1016/S0019-9958(65)90241-X
|
| [3] |
J. Wang, X. Zhang, J. Dai, J. Zhan, TI-fuzzy neighborhood measures and generalized Choquet integrals for granular structure reduction and decision making, Fuzzy Sets Syst., 2023, 108512. https://doi.org/10.1016/j.fss.2023.03.015 doi: 10.1016/j.fss.2023.03.015
|
| [4] |
J. Wang, X. Zhang, Q. Hu, Three-way fuzzy sets and their applications (Ⅱ), Axioms, 11 (2022), 532. https://doi.org/10.3390/axioms11100532 doi: 10.3390/axioms11100532
|
| [5] | K. T. Atanassov, Intuitionistic fuzzy sets, Physica Heidelberg, 1999. https://doi.org/10.1007/978-3-7908-1870-3 |
| [6] |
E. Szmidt, J. Kacprzyk, Distances between intuitionistic fuzzy sets, Fuzzy Sets Syst., 114 (2000), 505–518. https://doi.org/10.1016/S0165-0114(98)00244-9 doi: 10.1016/S0165-0114(98)00244-9
|
| [7] |
F. Wang, S. Wan, Possibility degree and divergence degree based method for interval-valued intuitionistic fuzzy multi-attribute group decision making, Expert Syst. Appl., 141 (2020), 112929. https://doi.org/10.1016/j.eswa.2019.112929 doi: 10.1016/j.eswa.2019.112929
|
| [8] |
Z. Xu, Intuitionistic fuzzy aggregation operators, IEEE Trans. Fuzzy Syst., 15 (2007), 1179–1187. https://doi.org/10.1109/TFUZZ.2006.890678 doi: 10.1109/TFUZZ.2006.890678
|
| [9] |
Y. Xu, H. Wang, The induced generalized aggregation operators for intuitionistic fuzzy sets and their application in group decision making, Appl. Soft Comput., 12 (2012), 1168–1179. https://doi.org/10.1016/j.asoc.2011.11.003 doi: 10.1016/j.asoc.2011.11.003
|
| [10] |
H. Zhao, Z. Xu, M. Ni, S. Liu, Generalized aggregation operators for intuitionistic fuzzy sets, Int. J. Intell. Syst., 25 (2010), 1–30. https://doi.org/10.1002/int.20386 doi: 10.1002/int.20386
|
| [11] |
I. K. Vlachos, G. D. Sergiadis, Intuitionistic fuzzy information–Applications to pattern recognition, Pattern Recognit. Lett., 28 (2007), 197–206. https://doi.org/10.1016/j.patrec.2006.07.004 doi: 10.1016/j.patrec.2006.07.004
|
| [12] |
S. K. De, R. Biswas, A. R. Roy, An application of intuitionistic fuzzy sets in medical diagnosis, Fuzzy Sets Syst., 117 (2001), 209–213. https://doi.org/10.1016/S0165-0114(98)00235-8 doi: 10.1016/S0165-0114(98)00235-8
|
| [13] |
R. R. Yager, Pythagorean fuzzy subsets, 2013 joint IFSA world congress and NAFIPS annual meeting (IFSA/NAFIPS), 2013, 57–61. https://doi.org/10.1109/IFSA-NAFIPS.2013.6608375 doi: 10.1109/IFSA-NAFIPS.2013.6608375
|
| [14] |
R. R. Yager, Pythagorean membership grades in multicriteria decision making, IEEE Trans. Fuzzy Syst., 22 (2013), 958–965. https://doi.org/10.1109/TFUZZ.2013.2278989 doi: 10.1109/TFUZZ.2013.2278989
|
| [15] |
L. Fei, Y. Deng, Multi-criteria decision making in Pythagorean fuzzy environment, Appl. Intell., 50 (2020), 537–561. https://doi.org/10.1007/s10489-019-01532-2 doi: 10.1007/s10489-019-01532-2
|
| [16] |
X. Peng, Y. Yang, Some results for Pythagorean fuzzy sets, Int. J. Intell. Syst., 30 (2015), 1133–1160. https://doi.org/10.1002/int.21738 doi: 10.1002/int.21738
|
| [17] |
A. A. Khan, S. Ashraf, S. Abdullah, M. Qiyas, J. Luo, S. U. Khan, Pythagorean fuzzy Dombi aggregation operators and their application in decision support system, Symmetry, 11 (2019), 383. https://doi.org/10.3390/sym11030383 doi: 10.3390/sym11030383
|
| [18] |
G. Wei, M. Lu, Pythagorean fuzzy power aggregation operators in multiple attribute decision making, Int. J. Intell. Syst., 33 (2018), 169–186. https://doi.org/10.1002/int.21946 doi: 10.1002/int.21946
|
| [19] |
S. Ashraf, S. Abdullah, S. Khan, Fuzzy decision support modeling for internet finance soft power evaluation based on sine trigonometric Pythagorean fuzzy information, J. Ambient Intell. Humanized Comput., 12 (2021), 3101–3119. https://doi.org/10.1007/s12652-020-02471-4 doi: 10.1007/s12652-020-02471-4
|
| [20] |
X. Zhang, A novel approach based on similarity measure for Pythagorean fuzzy multiple criteria group decision making, Int. J. Intell. Syst., 31 (2016), 593–611. https://doi.org/10.1002/int.21796 doi: 10.1002/int.21796
|
| [21] |
K. Rahman, S. Abdullah, R. Ahmed, M. Ullah, Pythagorean fuzzy Einstein weighted geometric aggregation operator and their application to multiple attribute group decision making, J. Intell. Fuzzy Syst., 33 (2017), 635–647. https://doi.org/10.3233/JIFS-16797 doi: 10.3233/JIFS-16797
|
| [22] |
P. Rani, A. R. Mishra, G. Rezaei, H. Liao, A. Mardani, Extended Pythagorean fuzzy TOPSIS method based on similarity measure for sustainable recycling partner selection, Int. J. Fuzzy Syst., 2 (2017), 735–747. https://doi.org/10.1007/s40815-019-00689-9 doi: 10.1007/s40815-019-00689-9
|
| [23] |
C. Huang, M. Lin, Z. Xu, Pythagorean fuzzy MULTIMOORA method based on distance measure and score function: its application in multicriteria decision making process, Knowl. Inf. Syst., 62 (2020), 4373–4406. https://doi.org/10.1007/s10115-020-01491-y doi: 10.1007/s10115-020-01491-y
|
| [24] |
Z. Pawlak, Rough sets, Int. J. Comput. Inf. Sci., 11 (1982), 341–356. https://doi.org/10.1007/BF01001956 doi: 10.1007/BF01001956
|
| [25] |
D. Dubois, H. Prade, Rough fuzzy sets and fuzzy rough sets, Int. J. Gen. Syst., 17 (1990), 191–209. https://doi.org/10.1080/03081079008935107 doi: 10.1080/03081079008935107
|
| [26] |
J. Wang, X. Zhang, A novel multi-criteria decision-making method based on rough sets and fuzzy measures, Axioms, 11 (2022), 275. https://doi.org/10.3390/axioms11060275 doi: 10.3390/axioms11060275
|
| [27] |
L. Zhang, J. Zhan, Fuzzy soft β-covering based fuzzy rough sets and corresponding decision-making applications, Int. J. Mach. Learn. Cyber., 10 (2019), 1487–1502. https://doi.org/10.1007/s13042-018-0828-3 doi: 10.1007/s13042-018-0828-3
|
| [28] |
J. S. Mi, Y. Leung, W. Z. Wu, An uncertainty measure in partition-based fuzzy rough sets, Int. J. Gene. Syst., 34 (2005), 77–90. https://doi.org/10.1080/03081070512331318329 doi: 10.1080/03081070512331318329
|
| [29] |
M. A. Khan, S. Ashraf, S. Abdullah, F. Ghani, Applications of probabilistic hesitant fuzzy rough set in decision support system, Soft Comput., 24 (2020), 16759–16774. https://doi.org/10.1007/s00500-020-04971-z doi: 10.1007/s00500-020-04971-z
|
| [30] |
X. Zhang, B. Zhou, P. Li, A general frame for intuitionistic fuzzy rough sets, Inf. Sci., 216 (2012), 34–49. https://doi.org/10.1016/j.ins.2012.04.018 doi: 10.1016/j.ins.2012.04.018
|
| [31] |
L. Zhou, W. Z. Wu, On generalized intuitionistic fuzzy rough approximation operators, Inf. Sci., 178 (2008), 2448–2465. https://doi.org/10.1016/j.ins.2008.01.012 doi: 10.1016/j.ins.2008.01.012
|
| [32] |
P. Liu, A. Ali, N. Rehman, Multi-granulation fuzzy rough sets based on fuzzy preference relations and their applications, IEEE Access, 7 (2019), 147825–147848. https://doi.org/10.1109/ACCESS.2019.2942854 doi: 10.1109/ACCESS.2019.2942854
|
| [33] |
S. M. Yun, S. J. Lee, Intuitionistic fuzzy rough approximation operators, Int. J. Fuzzy Log. Intell. Syst., 15 (2015), 208–215. https://doi.org/10.5391/IJFIS.2015.15.3.208 doi: 10.5391/IJFIS.2015.15.3.208
|
| [34] |
H. Zhang, L. Shu, S. Liao, Intuitionistic fuzzy soft rough set and its application in decision making, Abstr. Appl. Anal., 2014 (2014), 287314. https://doi.org/10.1155/2014/287314 doi: 10.1155/2014/287314
|
| [35] |
Z. Zhang, Generalized intuitionistic fuzzy rough sets based on intuitionistic fuzzy coverings, Inf. Sci., 198 (2014), 186–206. https://doi.org/10.1016/j.ins.2012.02.054 doi: 10.1016/j.ins.2012.02.054
|
| [36] | H. Zhang, L. Xiong, W. Ma, Generalized intuitionistic fuzzy soft rough set and its application in decision making, J. Comput. Anal. Appl, 20 (2016), 750–766. |
| [37] |
R. Chinram, A. Hussain, T. Mahmood, M. I. Ali, EDAS method for multi-criteria group decision making based on intuitionistic fuzzy rough aggregation operators, IEEE Access, 9 (2021), 10199–10216. https://doi.org/10.1109/ACCESS.2021.3049605 doi: 10.1109/ACCESS.2021.3049605
|
| [38] |
S. P. Zhang, P. Sun, J. S. Mi, T. Feng, Belief function of Pythagorean fuzzy rough approximation space and its applications, Int. J. Approx. Reason., 119 (2020), 58–80. https://doi.org/10.1016/j.ijar.2020.01.001 doi: 10.1016/j.ijar.2020.01.001
|
| [39] |
H. Garg, A new generalized Pythagorean fuzzy information aggregation using Einstein operations and its application to decision making, Int. J. Intell. Syst., 31 (2016), 886–920. https://doi.org/10.1002/int.21809 doi: 10.1002/int.21809
|
| [40] |
K. Guo, Q. Song, On the entropy for Atanassov's intuitionistic fuzzy sets: An interpretation from the perspective of amount of knowledge, Appl. Soft Comput., 24 (2014), 328–340. https://doi.org/10.1016/j.asoc.2014.07.006 doi: 10.1016/j.asoc.2014.07.006
|
| [41] |
A. Biswas, B. Sarkar, Pythagorean fuzzy TOPSIS for multicriteria group decision‐making with unknown weight information through entropy measure, Int. J. Intell. Syst., 34 (2019), 1108–1128. https://doi.org/10.1002/int.22088 doi: 10.1002/int.22088
|
| [42] |
Z. Yue, An avoiding information loss approach to group decision making, Appl. Math. Model., 37 (2013), 112–126. https://doi.org/10.1016/j.apm.2012.02.008 doi: 10.1016/j.apm.2012.02.008
|
| [43] |
M. Riaz, H. M. A. Farid, Picture fuzzy aggregation approach with application to third-party logistic provider selection process, Rep. Mech. Eng., 3 (2022), 227–236. https://doi.org/10.31181/rme20023062022r doi: 10.31181/rme20023062022r
|
| [44] | S. Soh, A decision model for evaluating third-party logistics providers using fuzzy analytic hierarchy process, Afr. J. Bus. Manag., 4 (2010), 339–349. |
| [45] |
S. Ashraf, N. Rehman, A. Hussain, H. AlSalman, A. H. Gumaei, q-rung orthopair fuzzy rough einstein aggregation information-based EDAS method: applications in robotic agrifarming, Comput. Intell. Neurosci., 2021 (2021), 5520264. https://doi.org/10.1155/2021/5520264 doi: 10.1155/2021/5520264
|



Figures(4) / Tables(14)

Shougi S. Abosuliman, Abbas Qadir, Saleem Abdullah. Multi criteria group decision (MCGDM) for selecting third-party logistics provider (3PL) under Pythagorean fuzzy rough Einstein aggregators and entropy measures[J]. AIMS Mathematics, 2023, 8(8): 18040-18065. doi: 10.3934/math.2023917







 DownLoad:
DownLoad: