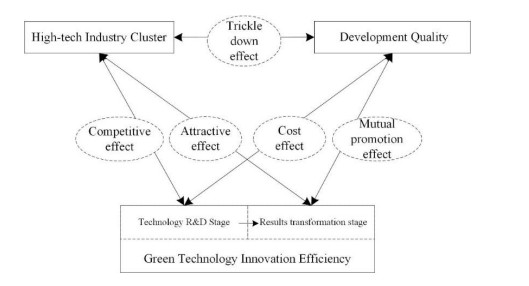
Technological progress, especially green innovation, is a key factor in achieving sustainable development and promoting economic growth. In this study, based on innovation value chain theory, we employ the location entropy, super-efficiency SBM-DEA model, and the improved entropy TOPSIS method to measure the technological industry agglomeration, two-stage green innovation efficiency, and development quality index in Yangtze River Delta city cluster, respectively. We then build a spatial panel simultaneous cubic equation model, focusing on the interaction effects among the three factors. The findings indicate: (1) There are significant spatial links between the technological industry agglomeration, green innovation efficiency, and development quality in city cluster. (2) The development quality and technological industry agglomeration are mutually beneficial. In the R&D stage, green innovation efficiency, development quality, and technological industry agglomeration compete with each other, while there is a mutual promotion in the transformation stage. (3) The spatial interaction among the three factors reveals the heterogeneity of two innovation stages. The positive geographical spillover effects of technological industry agglomeration, green innovation efficiency, and development quality are all related to each other. This paper can provide a reference for the direction and path of improving the development quality of city clusters worldwide.
Citation: Pengzhen Liu, Yanmin Zhao, Jianing Zhu, Cunyi Yang. Technological industry agglomeration, green innovation efficiency, and development quality of city cluster[J]. Green Finance, 2022, 4(4): 411-435. doi: 10.3934/GF.2022020
Technological progress, especially green innovation, is a key factor in achieving sustainable development and promoting economic growth. In this study, based on innovation value chain theory, we employ the location entropy, super-efficiency SBM-DEA model, and the improved entropy TOPSIS method to measure the technological industry agglomeration, two-stage green innovation efficiency, and development quality index in Yangtze River Delta city cluster, respectively. We then build a spatial panel simultaneous cubic equation model, focusing on the interaction effects among the three factors. The findings indicate: (1) There are significant spatial links between the technological industry agglomeration, green innovation efficiency, and development quality in city cluster. (2) The development quality and technological industry agglomeration are mutually beneficial. In the R&D stage, green innovation efficiency, development quality, and technological industry agglomeration compete with each other, while there is a mutual promotion in the transformation stage. (3) The spatial interaction among the three factors reveals the heterogeneity of two innovation stages. The positive geographical spillover effects of technological industry agglomeration, green innovation efficiency, and development quality are all related to each other. This paper can provide a reference for the direction and path of improving the development quality of city clusters worldwide.

| [1] |
Akinci M (2018) Inequality and economic growth: Trickle-down effect revisited. Dev Policy Rev 36: O1–O24. https://doi.org/10.1111/dpr.12214 doi: 10.1111/dpr.12214

|
| [2] |
Arbolino R, De Simone L, Carlucci F, et al. (2018) Towards a sustainable industrial ecology: Implementation of a novel approach in the performance evaluation of Italian regions. J Clean Prod 178: 220–236. https://doi.org/10.1016/j.jclepro.2017.12.183 doi: 10.1016/j.jclepro.2017.12.183
|
| [3] | Arrow KJ (1971) The economic implications of learning by doing. Readings in the Theory of Growth, 131–149. https://doi.org/10.1007/978-1-349-15430-2_11 |
| [4] |
Busch J, Foxon TJ, Taylor PG (2018) Designing industrial strategy for a low carbon transformation. Environ Innov Soc Transitions 29: 114–125. https://doi.org/10.1016/j.eist.2018.07.005 doi: 10.1016/j.eist.2018.07.005
|
| [5] |
Demirtas YE, Kececi NF (2020) The efficiency of private pension companies using dynamic data envelopment analysis. Quant Financ Econ 4: 204–219. https://doi.org/10.3934/qfe.2020009 doi: 10.3934/qfe.2020009
|
| [6] |
Du KR, Li JL (2019) Towards a green world: How do green technology innovations affect total-factor carbon productivity. Energy Policy 131: 240–250. https://doi.org/10.1016/j.enpol.2019.04.033 doi: 10.1016/j.enpol.2019.04.033
|
| [7] |
Greco M, Cricelli L, Grimaldi M, et al. (2022) Unveiling the relationships among intellectual property strategies, protection mechanisms and outbound open innovation. Creat Innov Manage 31: 376–389. https://doi.org/10.1111/caim.12498 doi: 10.1111/caim.12498
|
| [8] | Hansen MT, Birkinshaw J (2007) The innovation value chain. Harvard Bus Rev 85: 121. |
| [9] |
Hong Y, Liu W, Song H (2022) Spatial econometric analysis of effect of New economic momentum on China's high-quality development. Res Int Bus Financ 61: 101621. https://doi.org/10.1016/j.ribaf.2022.101621 doi: 10.1016/j.ribaf.2022.101621
|
| [10] |
Hou YX, Zhang KR, Zhu YC, et al. (2021) Spatial and temporal differentiation and influencing factors of environmental governance performance in the Yangtze River Delta, China. Sci Total Environ 801: 149699. https://doi.org/10.1016/j.scitotenv.2021.149699 doi: 10.1016/j.scitotenv.2021.149699
|
| [11] |
Huang CX, Zhao X, Deng YK, et al. (2022) Evaluating influential nodes for the Chinese energy stocks based on jump volatility spillover network. Int Rev Econ Financ 78: 81–94. https://doi.org/10.1016/j.iref.2021.11.001 doi: 10.1016/j.iref.2021.11.001
|
| [12] |
Kelejian HH, Prucha IR (2004) Estimation of simultaneous systems of spatially interrelated cross sectional equations. J Econometrics 118: 27–50. https://doi.org/10.1016/s0304-4076(03)00133-7 doi: 10.1016/s0304-4076(03)00133-7
|
| [13] |
Kemeny T, Osman T (2018) The wider impacts of high-technology employment: Evidence from US cities. Res Policy 47: 1729–1740. https://doi.org/10.1016/j.respol.2018.06.005 doi: 10.1016/j.respol.2018.06.005
|
| [14] |
Kolia DL, Papadopoulos S (2020) The levels of bank capital, risk and efficiency in the Eurozone and the U.S. in the aftermath of the financial crisis. Quant Financ Econ 4: 66–90. https://doi.org/10.3934/Qfe.2020004 doi: 10.3934/Qfe.2020004
|
| [15] |
Lin BQ, Zhou YC (2022) Does energy efficiency make sense in China? Based on the perspective of economic growth quality. Sci Total Environ 804: 149895. https://doi.org/10.1016/j.scitotenv.2021.149895 doi: 10.1016/j.scitotenv.2021.149895
|
| [16] |
Liu CY, Gao XY, Ma WL, et al. (2020) Research on regional differences and influencing factors of green technology innovation efficiency of China's high-tech industry. J Comput Appl Math 369: 112597. https://doi.org/10.1016/j.cam.2019.112597 doi: 10.1016/j.cam.2019.112597
|
| [17] |
Liu H, Lei H, Zhou Y (2022) How does green trade affect the environment? Evidence from China. J Econ Anal 1: 1–27. https://doi.org/10.12410/jea.2811-0943.2022.01.001 doi: 10.12410/jea.2811-0943.2022.01.001
|
| [18] |
Liu Y, Liu M, Wang GG, et al. (2021) Effect of Environmental Regulation on High-quality Economic Development in China-An Empirical Analysis Based on Dynamic Spatial Durbin Model. Environ Sci Pollut Res 28: 54661–54678. https://doi.org/10.1007/s11356-021-13780-2 doi: 10.1007/s11356-021-13780-2
|
| [19] |
Long RY, Gan X, Chen H, et al. (2020) Spatial econometric analysis of foreign direct investment and carbon productivity in China: Two-tier moderating roles of industrialization development. Resour Conserv Recy 155: 104677. https://doi.org/10.1016/j.resconrec.2019.104677 doi: 10.1016/j.resconrec.2019.104677
|
| [20] |
Lu R, Ruan M, Reve T (2016) Cluster and co-located cluster effects: An empirical study of six Chinese city regions. Res Policy 45: 1984–1995. https://doi.org/10.1016/j.respol.2016.07.003 doi: 10.1016/j.respol.2016.07.003
|
| [21] |
Lv CC, Shao CH, Lee CC (2021) Green technology innovation and financial development: Do environmental regulation and innovation output matter? Energy Econ 98: 105237. https://doi.org/10.1016/j.eneco.2021.105237 doi: 10.1016/j.eneco.2021.105237
|
| [22] |
Ma XW, Xu JW (2022) Impact of Environmental Regulation on High-Quality Economic Development. Front Env Sci 10: 896892. https://doi.org/10.3389/fenvs.2022.896892 doi: 10.3389/fenvs.2022.896892
|
| [23] |
Miao CL, Fang DB, Sun LY, et al. (2017) Natural resources utilization efficiency under the influence of green technological innovation. Resour Conserv Recy 126: 153–161. https://doi.org/10.1016/j.resconrec.2017.07.019 doi: 10.1016/j.resconrec.2017.07.019
|
| [24] |
Nieto J, Carpintero O, Lobejon LF, et al. (2020) An ecological macroeconomics model: The energy transition in the EU. Energy Policy 145: 111726. https://doi.org/10.1016/j.enpol.2020.111726 doi: 10.1016/j.enpol.2020.111726
|
| [25] |
Peng BH, Zheng CY, Wei G, et al. (2020) The cultivation mechanism of green technology innovation in manufacturing industry: From the perspective of ecological niche. J Clean Prod 252: 119711. https://doi.org/10.1016/j.jclepro.2019.119711 doi: 10.1016/j.jclepro.2019.119711
|
| [26] |
Poon JP, Kedron P, Bagchi-Sen S (2013) Do foreign subsidiaries innovate and perform better in a cluster? A spatial analysis of Japanese subsidiaries in the US. Appl Geogr 44: 33–42. https://doi.org/10.1016/j.apgeog.2013.07.007 doi: 10.1016/j.apgeog.2013.07.007
|
| [27] |
Ren S, Liu Z, Zhanbayev R, et al. (2022). Does the internet development put pressure on energy-saving potential for environmental sustainability? Evidence from China. J Econ Anal 1: 81–101. https://doi.org/10.12410/jea.2811-0943.2022.01.004 doi: 10.12410/jea.2811-0943.2022.01.004
|
| [28] |
Ren ZL (2020) Evaluation Method of Port Enterprise Product Quality Based on Entropy Weight TOPSIS. J Coastal Res 766–769. https://doi.org/10.2112/si103-158.1 doi: 10.2112/si103-158.1
|
| [29] |
Song Y, Yang L, Sindakis S, et al. (2022) Analyzing the Role of High-Tech Industrial Agglomeration in Green Transformation and Upgrading of Manufacturing Industry: the Case of China. J Knowl Econ, 1–31. https://doi.org/10.1007/s13132-022-00899-x doi: 10.1007/s13132-022-00899-x
|
| [30] |
Strauss J, Yigit T (2001) Present value model, heteroscedasticity and parameter stability tests. Econ Lett 73: 375–378. https://doi.org/10.1016/S0165-1765(01)00506-7 doi: 10.1016/S0165-1765(01)00506-7
|
| [31] |
Su Y, Li Z, Yang C (2021) Spatial Interaction Spillover Effects between Digital Financial Technology and Urban Ecological Efficiency in China: An Empirical Study Based on Spatial Simultaneous Equations. Int J Environ Res Public Health 18: 8535. https://doi.org/10.3390/ijerph18168535 doi: 10.3390/ijerph18168535
|
| [32] |
Sun CZ, Yang YD, Zhao LS (2015) Economic spillover effects in the Bohai Rim Region of China: Is the economic growth of coastal counties beneficial for the whole area? China Econ Rev 33: 123–136. https://doi.org/10.1016/j.chieco.2015.01.008 doi: 10.1016/j.chieco.2015.01.008
|
| [33] |
Wang L, Xue YB, Chang M, et al. (2020a) Macroeconomic determinants of high-tech migration in China: The case of Yangtze River Delta Urban Agglomeration. Cities 107: 102888. https://doi.org/10.1016/j.cities.2020.102888 doi: 10.1016/j.cities.2020.102888
|
| [34] |
Wang MY, Li YM, Li JQ, et al. (2021) Green process innovation, green product innovation and its economic performance improvement paths: A survey and structural model. J Environ Manage 297: 113282. https://doi.org/10.1016/j.jenvman.2021.113282 doi: 10.1016/j.jenvman.2021.113282
|
| [35] |
Wang S, Yang C, Li Z (2022) Green Total Factor Productivity Growth: Policy-Guided or Market-Driven? Int J Environ Res Public Health 19: 10471. https://doi.org/10.3390/ijerph191710471 doi: 10.3390/ijerph191710471
|
| [36] |
Wang SJ, Hua GH, Yang LZ (2020b) Coordinated development of economic growth and ecological efficiency in Jiangsu, China. Environ Sci Pollut Res 27: 36664–36676. https://doi.org/10.1007/s11356-020-09297-9 doi: 10.1007/s11356-020-09297-9
|
| [37] |
Wang Y, Pan JF, Pei RM, et al. (2020c) Assessing the technological innovation efficiency of China's high-tech industries with a two-stage network DEA approach. Socio-Econ Plan Sci 71: 100810. https://doi.org/10.1016/j.seps.2020.100810 doi: 10.1016/j.seps.2020.100810
|
| [38] |
Wu HT, Hao Y, Ren SY (2020) How do environmental regulation and environmental decentralization affect green total factor energy efficiency: Evidence from China. Energy Econ 91: 104880. https://doi.org/10.1016/j.eneco.2020.104880 doi: 10.1016/j.eneco.2020.104880
|
| [39] |
Wu HT, Hao Y, Ren SY, et al. (2021) Does internet development improve green total factor energy efficiency? Evidence from China. Energy Policy 153: 112247. https://doi.org/10.1016/j.enpol.2021.112247 doi: 10.1016/j.enpol.2021.112247
|
| [40] |
Wu MR (2022) The impact of eco-environmental regulation on green energy efficiency in China-Based on spatial economic analysis. Energy Environ. https://doi.org/10.1177/0958305x211072435 doi: 10.1177/0958305x211072435
|
| [41] |
Wu XX, Huang Y, Gao J (2022) Impact of industrial agglomeration on new-type urbanization: Evidence from Pearl River Delta urban agglomeration of China. Int Rev Econ Financ 77: 312–325. https://doi.org/10.1016/j.iref.2021.10.002 doi: 10.1016/j.iref.2021.10.002
|
| [42] |
Xu J, Li JS (2019) The impact of intellectual capital on SMEs' performance in China Empirical evidence from non-high-tech vs. high-tech SMEs. J Intellect Capital 20: 488–509. https://doi.org/10.1108/jic-04-2018-0074 doi: 10.1108/jic-04-2018-0074
|
| [43] |
Xu JH, Li Y (2021) Research on the Impact of Producer Services Industry Agglomeration on the High Quality Development of Urban Agglomerations in the Yangtze River Economic Belt. World Congress on Services, Springer, Cham, 12996: 35–52. https://doi.org/10.1007/978-3-030-96585-3_3 doi: 10.1007/978-3-030-96585-3_3
|
| [44] |
Yao Y, Hu D, Yang C, et al. (2021) The impact and mechanism of fintech on green total factor productivity. Green Financ 3: 198–221. https://doi.org/10.3934/gf.2021011 doi: 10.3934/gf.2021011
|
| [45] |
Yin XB, Guo LY (2021) Industrial efficiency analysis based on the spatial panel model. Eurasip J Wireless Commun Netw 2021: 1–17. https://doi.org/10.1186/s13638-021-01907-5 doi: 10.1186/s13638-021-01907-5
|
| [46] |
Zhao BY, Sun LC, Qin L (2022) Optimization of China's provincial carbon emission transfer structure under the dual constraints of economic development and emission reduction goals. Environ Sci Pollut Res, 1–17. https://doi.org/10.1007/s11356-022-19288-7 doi: 10.1007/s11356-022-19288-7
|
| [47] |
Zheng Y, Chen S, Wang N (2020) Does financial agglomeration enhance regional green economy development? Evidence from China. Green Financ 2: 173–196. https://doi.org/10.3934/GF.2020010 doi: 10.3934/GF.2020010
|
| [48] |
Zhou B, Zeng XY, Jiang L, et al. (2020) High-quality Economic Growth under the Influence of Technological Innovation Preference in China: A Numerical Simulation from the Government Financial Perspective. Struct Change Econ Dyn 54: 163–172. https://doi.org/10.1016/j.strueco.2020.04.010 doi: 10.1016/j.strueco.2020.04.010
|
| [49] |
Zhou J, Wang G, Lan S, et al. (2017) Study on the Innovation Incubation Ability Evaluation of High Technology Industry in China from the Perspective of Value-Chain An Empirical Analysis Based on 31 Provinces. Procedia Manuf 10: 1066–1076. https://doi.org/10.1016/j.promfg.2017.07.097 doi: 10.1016/j.promfg.2017.07.097
|
| [50] |
Zhu L, Luo J, Dong QL, et al. (2021) Green technology innovation efficiency of energy-intensive industries in China from the perspective of shared resources: Dynamic change and improvement path. Technol Forecasting Soc Change 170: 120890. https://doi.org/10.1016/j.techfore.2021.120890 doi: 10.1016/j.techfore.2021.120890
|
| [51] |
Zhu M, Song X, Chen W (2022) The Impact of Social Capital on Land Arrangement Behavior of Migrant Workers in China. J Econ Anal 1: 52–80. https://doi.org/10.12410/jea.2811-0943.2022.01.003 doi: 10.12410/jea.2811-0943.2022.01.003
|


Figures(3) / Tables(10)

Pengzhen Liu, Yanmin Zhao, Jianing Zhu, Cunyi Yang. Technological industry agglomeration, green innovation efficiency, and development quality of city cluster[J]. Green Finance, 2022, 4(4): 411-435. doi: 10.3934/GF.2022020







 DownLoad:
DownLoad: