Citation: Ngo Thai Hung. Dynamic spillover effects between oil prices and stock markets: New evidence from pre and during COVID-19 outbreak[J]. AIMS Energy, 2020, 8(5): 819-834. doi: 10.3934/energy.2020.5.819

| [1] |
Diebold X, Yilmaz K (2012) Better to give than to receive: Predictive directional measurement of volatility spillovers. Int J Forecasting 28: 57-66. doi: 10.1016/j.ijforecast.2011.02.006

|
| [2] | Goodell W (2020) COVID-19 and finance: Agendas for future research. Finance Res Lett, 101512. |
| [3] |
Yu L, Zha R, Stafylas D, et al. (2020) Dependences and volatility spillovers between the oil and stock markets: New evidence from the copula and VAR-BEKK-GARCH models. Int Rev Financ Anal 68: 101280. doi: 10.1016/j.irfa.2018.11.007
|
| [4] | Park J, Ratti A (2008) Oil price shocks and stock markets in the US and 13 European countries. Energy Econ 30: 2587-2608. |
| [5] |
Chen D, Cheng M, Demirer R (2017) Oil and stock market momentum. Energy Econ 68: 151-159. doi: 10.1016/j.eneco.2017.09.025
|
| [6] |
Lin B, Wesseh K, Appiah O (2014) Oil price fluctuation, volatility spillover and the Ghanaian equity market: Implication for portfolio management and hedging effectiveness. Energy Econ 42: 172-182. doi: 10.1016/j.eneco.2013.12.017
|
| [7] | Liu Z, Ding Z, Li R, et al. (2017) Research on differences of spillover effects between international crude oil price and stock markets in China and America. Nat Hazards 88: 575-590. |
| [8] |
Liu X, An H, Huang S, et al. (2017) The evolution of spillover effects between oil and stock markets across multi-scales using a wavelet-based GARCH-BEKK model. Phys A: Stat Mech its Appl 465: 374-383. doi: 10.1016/j.physa.2016.08.043
|
| [9] | Trabelsi N (2017) Tail dependence between oil and stocks of major oil-exporting countries using the CoVaR approach. Borsa Istanbul Rev 17: 228-237. |
| [10] |
Wang Y, Liu L (2016) Crude oil and world stock markets: volatility spillovers, dynamic correlations, and hedging. Empirical Econ 50: 1481-1509. doi: 10.1007/s00181-015-0983-2
|
| [11] | Hamilton J (1983) Oil and the macroeconomy since World War Ⅱ. J Political Econ 91. |
| [12] |
Wei Y, Qin S, Li X, et al. (2019) Oil price fluctuation, stock market and macroeconomic fundamentals: Evidence from China before and after the financial crisis. Finance Res Lett 30: 23-29. doi: 10.1016/j.frl.2019.03.028
|
| [13] |
Ni Y, Wu M, Day M, et al. (2020) Do sharp movements in oil prices matter for stock markets? Phys A: Stat Mech its Appl 539: 122865. doi: 10.1016/j.physa.2019.122865
|
| [14] |
Köse N, Ünal E (2020) The impact of oil price shocks on stock exchanges in Caspian Basin countries. Energy 190: 116383. doi: 10.1016/j.energy.2019.116383
|
| [15] |
Shahrestani P, Rafei M (2020) The impact of oil price shocks on Tehran Stock Exchange returns: Application of the Markov switching vector autoregressive models. Resour Policy 65: 101579. doi: 10.1016/j.resourpol.2020.101579
|
| [16] | Zhu B, Ye S, He K, et al. (2019) Measuring the risk of European carbon market: An empirical mode decomposition-based value at risk approach. Ann Oper Res 281: 373-395. |
| [17] |
Zhu B, Huang L, Yuan L, et al. (2020) Exploring the risk spillover effects between carbon market and electricity market: A bidimensional empirical mode decomposition based conditional value at risk approach. Int Rev Econ Finance 67: 163-175. doi: 10.1016/j.iref.2020.01.003
|
| [18] |
Xiao D, Wang J (2020) Dynamic complexity and causality of crude oil and major stock markets. Energy 193: 116791. doi: 10.1016/j.energy.2019.116791
|
| [19] |
Hamma W, Salhi B, Ghorbel A, et al. (2019) Conditional dependence structure between oil prices and international stock markets. Int J Energy Sector Manage 14: 439-46 doi: 10.1108/IJESM-04-2019-0010
|
| [20] |
Mokni K, Youssef M (2019) Measuring persistence of dependence between crude oil prices and GCC stock markets: A copula approach. The Q Rev Econ Finance 72: 14-33. doi: 10.1016/j.qref.2019.03.003
|
| [21] |
Bagirov M, Mateus C (2019) Oil prices, stock markets and firm performance: Evidence from Europe. Int Rev Econ Finance 61: 270-288. doi: 10.1016/j.iref.2019.02.007
|
| [22] | Hung N (2020) Volatility spillovers and time-frequency correlations between Chinese and African stock markets. Online first Hung 1-20. |
| [23] |
Baruník J, Kočenda E, Vácha, L (2016) Gold, oil, and stocks: Dynamic correlations. Int Rev Econ Finance 42: 186-201. doi: 10.1016/j.iref.2015.08.006
|
| [24] | Hung N (2020) Market integration among foreign exchange rate movements in central and eastern European countries. Soc Econ 42: 1-20. |
| [25] | Torrence C, Webster J (1999) Interdecadal changes in the ENSO-monsoon system. J Clim 12: 2679-2690. |
| [26] | Hung N (2018) Volatility behaviour of the foreign exchange rate and transmission among Central and Eastern European countries: evidence from the EGARCH model. Global Bus Rev, 0972150918811713. |
| [27] |
Hung N (2019) An analysis of CEE equity market integration and their volatility spillover effects. Eur J Manage Bus Econ 29: 23-40. doi: 10.1108/EJMBE-01-2019-0007
|
| [28] | Hung N (2020) Conditional dependence between oil prices and CEE stock markets: A copula-GARCH approach. East J Eur Stud 11. |
| [29] |
Hung N (2019) Interdependence of oil prices and exchange rates: Evidence from copula-based GARCH model. AIMS Energy 7: 465-482. doi: 10.3934/energy.2019.4.465
|
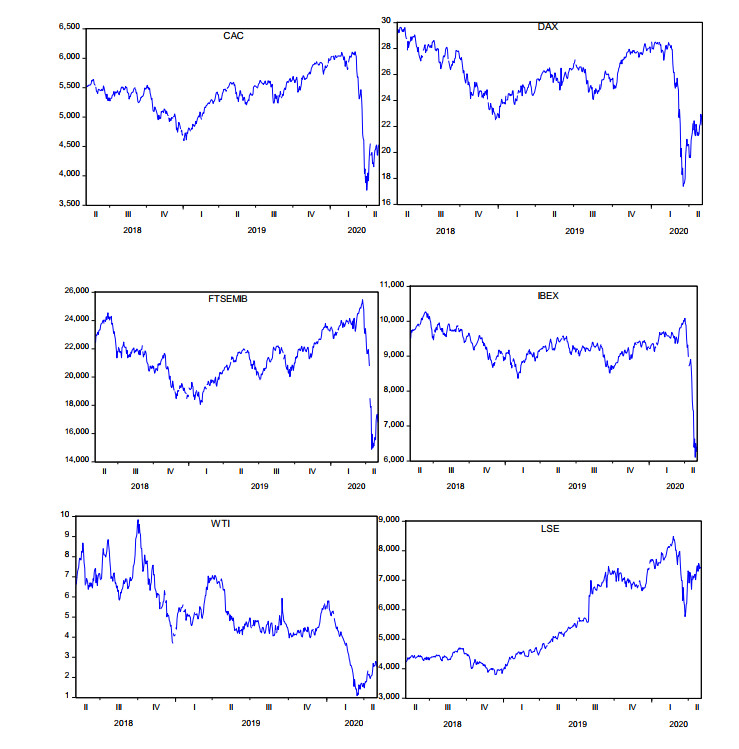
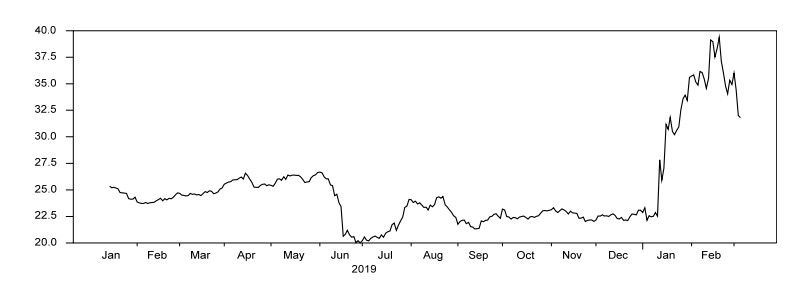
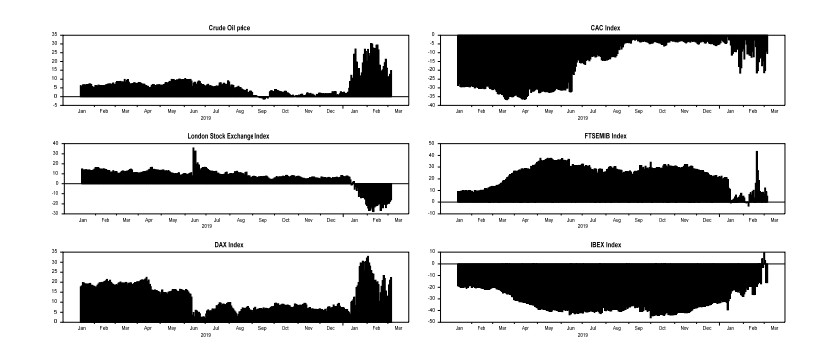
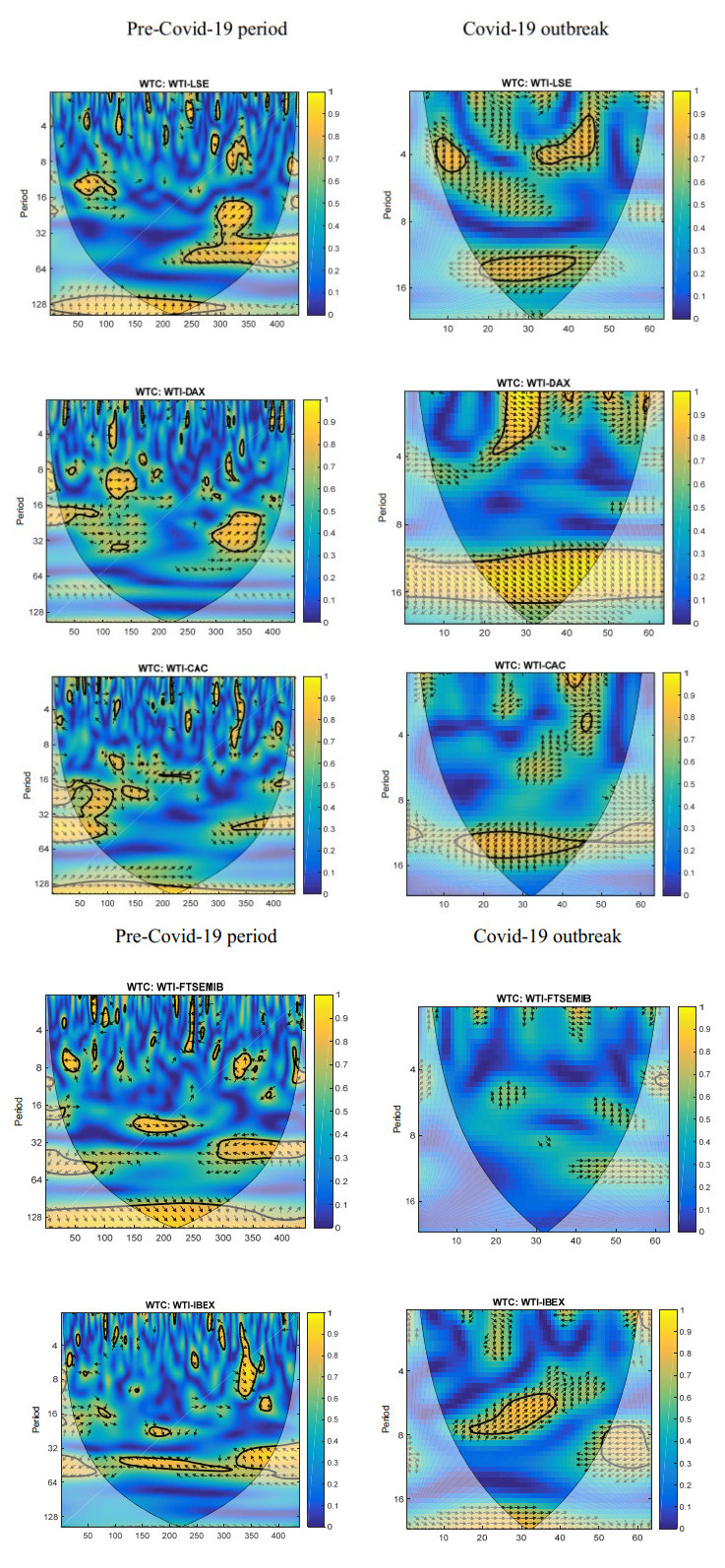
Figures(4) / Tables(2)

Ngo Thai Hung. Dynamic spillover effects between oil prices and stock markets: New evidence from pre and during COVID-19 outbreak[J]. AIMS Energy, 2020, 8(5): 819-834. doi: 10.3934/energy.2020.5.819







 DownLoad:
DownLoad: