Citation: Djelloul Benatiallah, Ali Benatiallah, Kada Bouchouicha, Bahous Nasri. Estimation of clear sky global solar radiation in Algeria[J]. AIMS Energy, 2019, 7(6): 710-727. doi: 10.3934/energy.2019.6.710

| [1] | Sawin J (2013) Global Status Report. Renewables. REN21 Secretariat, Paris, France. |
| [2] | Shukl K, Sudhakar K, Rangneker S (2015) Estimation and validation of solar radiation incident on horizontal and tilted surface at Bhopal, Madhya Pradesh, India. Am-Eurasian J Agric Environ Sci 15: 129-139. |
| [3] | Benatiallah D, Benatiallah A, Bouchouicha K, et al. (2016) Development and modeling of a geographic information system solar flux in Adrar, Algeria. Int J Sys Model Simul 1: 15-19. |
| [4] |
Kumar BS, Sudhakar K (2015) Performance evaluation of 10 MW grid connected solar photovoltaic power plant in India. Energy Rep 1: 184-192. doi: 10.1016/j.egyr.2015.10.001

|
| [5] |
Besarati SM, Padilla RV, Goswami DY, et al. (2013) The potential of harnessing solar radiation in Iran: generating solar maps and viability study of PV power plants. Renewable Energy 53: 193-199. doi: 10.1016/j.renene.2012.11.012
|
| [6] | Elhodeiby AS, Metwally HMB, Farahat MA (2011) Performance analysis of 3.6 kW Rooftop grid connected photovoltaic system Egypt. International Conference on Energy Systems and Technologies, Cairo, Egypt, CEST 2011. |
| [7] |
Kambezidis HD, Psiloglou BE, Karagiannis D, et al. (2016) Recent improvements of the Meteorological Radiation Model for solar irradiance estimates under all-sky conditions. Renewable Energy 93: 142-158. doi: 10.1016/j.renene.2016.02.060
|
| [8] | Mejdou L, Taqi R, Belouaggadian N (2011) Estimation of solar radiation in the Casablanca area. International Congress on Renewable Energies and Energy Efficiency, Fès Morocco. |
| [9] | Mesri M (2015) Numerical methods to calculate solar radiation, validation through a new Graphic User Interface design. Energy Convers Manage 90: 436-445. |
| [10] | Zaatri A, Azzizi N (2016) Evaluation of some mathematical models of solar radiation received by a ground collector. World J Eng 13: 376-380. |
| [11] | Lealea T, Tchinda R (2013) Estimation of diffuse solar radiation in the north and far north of Cameroon. Eur Sci J 9. |
| [12] | Mesri-Merad M (2012) Estimation of solar radiation on the ground by semi-empirical models. Rev Renewable Energies 15: 451-463. |
| [13] | El-mghouchi Y, Bouardi A, Choulli Z, et al. (2014) Estimate of the direct, diffuse and global solar radiations. Int J Sci Res 3: 1449-1457. |
| [14] | Yettou F, Malek A, Haddadi M, et al. (2009) Comparative study of two models of solar radiation calculation in Algeria. Renewable Energies Rev 12: 331-346. |
| [15] | Yaïche M, Bekkouche S (2010) Estimation of global solar radiation in Algeria for different types of sky. Rev Renewable Energies 13: 683-695. |
| [16] | Gueymard CA (2014) The sun's total and spectral irradiance for solar energy applications and solar radiation models. Sol Energy 76: 423-453. |
| [17] |
Otunla TA (2019) Estimates of clear-sky solar irradiances over Nigeria. Renewable Energy 131: 778-787. doi: 10.1016/j.renene.2018.07.053
|
| [18] |
Ruiz-Arias JA, Gueymard CA (2018) Worldwide inter-comparison of clear-sky solar radiation models: Consensus-based review of direct and global irradiance components simulated at the earth surface. Sol Energy 168: 10-29. doi: 10.1016/j.solener.2018.02.008
|
| [19] |
Scarpa F, Bianco V, Tagliafico LA (2018) A clear sky physical based solar radiation decomposition model. Therm Sci Eng Prog 6: 323-329. doi: 10.1016/j.tsep.2017.11.004
|
| [20] | Kambezidis HD, Psiloglou BE, Karagiannis D, et al. (2017) Meteorological Radiation Model (MRM v6.1): improvements in diffuse radiation estimates and new approach for implementation of cloud products. Renewable Sustainable Energy Rev 74: 616-637. |
| [21] | Bilbao J, Miguel A (2010) Estimation of UV-B irradiation from total global solar meteorological data in central Spain. J Geophys Res 115: D00I09. |
| [22] |
De Miguel A, Román R, Bilbao J, et al. (2011) Evolution of erythemal and total shortwave solar radiation in Valladolid, Spain: Effects of atmospheric factors. J Atmos Sol-Terr Phys 73: 578-586. doi: 10.1016/j.jastp.2010.11.021
|
| [23] |
Bilbao J, Román R, Miguel A (2014) Turbidity coefficients from normal direct solar irradiance in Central Spain. Atmos Res 143: 73-84. doi: 10.1016/j.atmosres.2014.02.007
|
| [24] | Yamasoe MA, do Rosário NME, Barros KM (2016) Downward solar global irradiance at the surface in São Paulo city-The climatological effects of aerosol and clouds. J Geophys Res 122. |
| [25] | Sanchez-Lorenzo A, Calbó J, Brunetti M, et al. (2009) Dimming/brightening over the Iberian Peninsula: trends in sunshine duration and cloud cover and their relations with atmospheric circulation. J Geophys Res 114: D00D09. |
| [26] | Hinkelman LM, Stackhouse PW, Wielicki BA, et al. (2009) Surface insolation trends from satellite and ground measurements: comparisons and challenges. J Geophys Res 114: D00D20. |
| [27] |
Hatzianastassiou N, Papadimas CD, Matsoukas C, et al. (2012) Recent regional surface solar radiation dimming and brightening patterns: inter-hemispherical asymmetry and a dimming in the Southern Hemisphere. Atmos Sci Lett 13: 43-48. doi: 10.1002/asl.361
|
| [28] | Berk A, Bernstein L, Robertson D (1989) MODTRAN: A moderate resolution model for LOWTRAN7, Rep. GL-TR-89-0122. Air Force Geophys. Lab., Bedford, MA. |
| [29] |
Bird RE, Riordan C (1986) Simple solar spectral model for direct and diffuse irradiance on horizontal and tilted planes at the earth's surface for cloudless atmospheres. J Clim Appl Meteorol 25: 87-97. doi: 10.1175/1520-0450(1986)025<0087:SSSMFD>2.0.CO;2
|
| [30] | Gueymard C (1995) A simple model of the atmospheric radiative transfer of sunshine: algorithms and performance assessment. Florida Solar Energy Center. |
| [31] | ASHRAE (1985) Handbook of fundamentals. Atlanta, Georgia: American Society of Heating, Refrigeration, and Air-Conditioning Engineers. |
| [32] | Campbell GS, Norman JM (1989) An Introduction to Environmental Biophysics. 2nd ed., New York Springer, ISBN 0-387-94937-2. |
| [33] | Atwater MA, Ball JT (1978) A numerical solar radiation model based on standard meteorological observations. Sol Energy 21: 163-70. |
| [34] | Davies JA (1988) Validation of models for estimating solar radiation on horizontal surface. Atmospheric Environment Service, Downsview (Ont.), IEA Task IX Final Report. |
| [35] | Ineichen P (2006) Comparison of eight clear sky broadband models against 16 independent data banks Sol Energy 80: 468-478. |
| [36] | Bouchouicha K, Razagui A, Bachari N, et al. (2016) Hourly global solar radiation estimation from MSG-SEVIRI images-case study: Algeria. World J Eng 13: 266-274. |
| [37] | Bouchouicha K, Razagui A, Bachari N, et al. (2015) Mapping and Geospatial Analysis of Solar Resource in Algeria. Int J Energy, Environ Econ 23: 735-751. |
| [38] | Bailek N, Bouchouicha K, Al-Mostafa Z, et al. (2018) A new empirical model for forecasting the diffuse solar radiation over Sahara in the Algerian Big South. Renewable Energy 117: 117-530. |
| [39] |
Journée M, Bertrand C (2011) Quality control of solar radiation data within the RMIB solar measurements network. Sol Energy 85: 72-86. doi: 10.1016/j.solener.2010.10.021
|
| [40] | Pandey CK, Katiyar AK (2013) Solar radiation: Models and measurement techniques. J Energy. |
| [41] | Bird RE, Hulstrom R (1981) A simplified clear sky model for directand diffuse insulation on horizontal surfaces, Seri/Tr. 642-761. |
| [42] | El-mghouchi Y, El-bouardi A, Sadouk A, et al. (2016) Comparison of three solar radiation models and their validation under all sky conditions-case study: Tetuan city in northern of Morocco. Renewable Sustainable Energy Rev 58: 1432-1444. |
| [43] | El-mghouchi Y, El-bouardi A, Choulli Z, et al. (2016) Models for obtaining the daily direct, diffuse and global solar radiations. Renewable Sustainable Energy Rev 56: 87-99. |
| [44] | Bird RE, Huldstrom R (1980) Direct insolation models. Trans ASME J Solar Energy Eng 103: 182-192. |
| [45] | Stone RJ (1993) Improved statistical procedure for the evaluation of solar radiation estimation models. Sol Energy 51: 289-291. |
| [46] | National Centers For Environmental Information. Available from: www.ncdc.noaa.gov. |
| [47] | Hussain M (1984) Estimation of global and diffuse irradiation from sunshine duration and atmospheric water vapour contents. Sol Energy 33: 217-220. |
| [48] | Van Heuklon TK (1979) Estimating atmospheric ozone for solar radiation models. Sol Energy 22: 63-68. |
| [49] | Mefti A (2007) Contribution to the solar deposit determination by solar soil data processing and meteosat images. Doctoral Thesis, University of USTHB Algiers. |

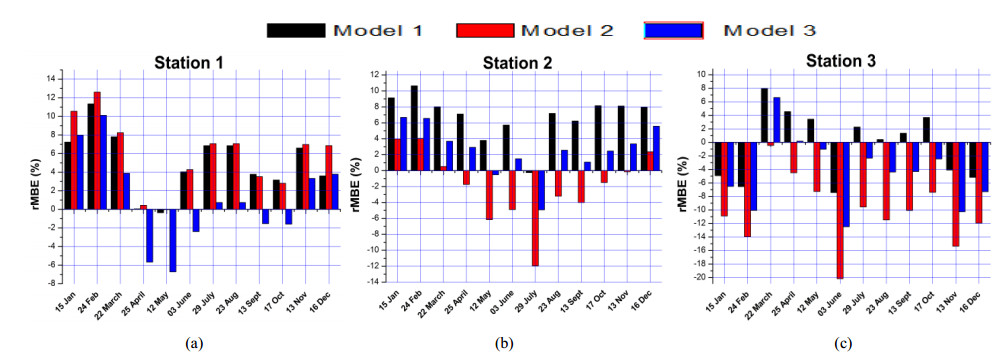
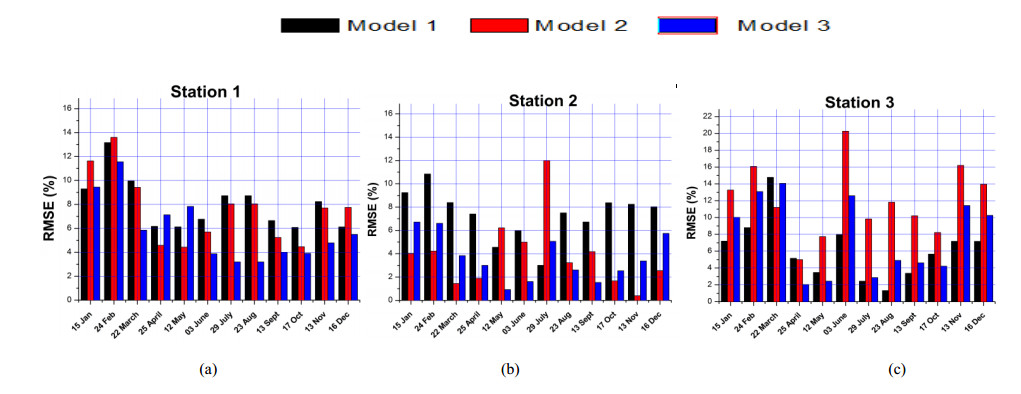
Figures(11) / Tables(6)

Djelloul Benatiallah, Ali Benatiallah, Kada Bouchouicha, Bahous Nasri. Estimation of clear sky global solar radiation in Algeria[J]. AIMS Energy, 2019, 7(6): 710-727. doi: 10.3934/energy.2019.6.710







 DownLoad:
DownLoad: