Citation: Carina Ladeira, Susana Viegas, Mário Pádua, Elisabete Carolino, Manuel C. Gomes, Miguel Brito. Relation between DNA damage measured by comet assay and OGG1 Ser326Cys polymorphism in antineoplastic drugs biomonitoring[J]. AIMS Genetics, 2015, 2(3): 204-218. doi: 10.3934/genet.2015.3.204

| [1] | CDC—The National Institute for Occupational Safety and Health (NIOSH) (2004). available from: http://www.cdc.gov/niosh/. |
| [2] |
Kopjar N, Garaj-Vrhovac V, Kašuba V, et al. (2009) Assessment of genotoxic risks in Croatian health care workers occupationally exposed to cytotoxic drugs: A multi-biomarker approach. Int J Hyg Environ Health 212: 414-431. doi: 10.1016/j.ijheh.2008.10.001

|
| [3] |
Mahboob M, Rahman F, Rekhadevi PV, et al. (2012) Monitoring of Oxidative Stress in Nurses Occupationally Exposed to Antineoplastic Drugs. Toxicol Int 19: 20-24. doi: 10.4103/0971-6580.94510
|
| [4] | Villarini M, Dominici L, Piccinini R, et al. (2011) Assessment of primary, oxidative and excision repaired DNA damage in hospital personnel handling antineoplastic drugs. Mutagenesis 26: 359-369. |
| [5] |
Villarini M, Dominici L, Fatigoni C, et al. (2012) Biological effect monitoring in peripheral blood lymphocytes from subjects occupationally exposed to antineoplastic drugs: assessment of micronuclei frequency. J Occup Health 54: 405-415. doi: 10.1539/joh.12-0038-OA
|
| [6] |
Fucic A, Jazbec A, Mijic A, et al. (1998) Cytogenetic consequences after occupational exposure to antineoplastic drugs. Mutat Res Toxicol Environ Mutagen 416: 59-66. doi: 10.1016/S1383-5718(98)00084-9
|
| [7] |
Burgaz S, Karahalil B, Bayrak P, et al. (1999) Urinary cyclophosphamide excretion and micronuclei frequencies in peripheral lymphocytes and in exfoliated buccal epithelial cells of nurses handling antineoplastics. Mutat Res 439: 97-104. doi: 10.1016/S1383-5718(98)00180-6
|
| [8] | Sessink RP, Bos RP (1999) Drugs hazardous to healthcare workers. Evaluation of methods for monitoring occupational exposure to cytostatic drugs. Drug Saf Int J Med Toxicol Drug Exp 20: 347-359. |
| [9] |
Bouraoui S, Brahem A, Tabka F, et al. (2011) Assessment of chromosomal aberrations, micronuclei and proliferation rate index in peripheral lymphocytes from Tunisian nurses handling cytotoxic drugs. Environ Toxicol Pharmacol 31: 250-257. doi: 10.1016/j.etap.2010.11.004
|
| [10] | Gulten T, Evke E, Ercan I, et al. (2011) Lack of genotoxicity in medical oncology nurses handling antineoplastic drugs: effect of work environment and protective equipment. Work Read Mass 39: 485-489. |
| [11] | Buschini A, Villarini M, Feretti D, et al. (2013) Multicentre study for the evaluation of mutagenic/carcinogenic risk in nurses exposed to antineoplastic drugs: assessment of DNA damage. Occup Environ Med 70: 789-794. |
| [12] |
Jackson MA, Stack HF, Waters MD (1996) Genetic activity profiles of anticancer drugs. Mutat Res 355: 171-208. doi: 10.1016/0027-5107(96)00028-0
|
| [13] | Connor TH (2006) Hazardous Anticancer Drugs in Health Care: Environmental Exposure Assessment. Ann N Y Acad Sci 1076: 615-623. |
| [14] | Kopjar N, Milas I, Garaj-Vrhovac V, et al. (2006) M. Gamulin, Alkaline comet assay study with breast cancer patients: evaluation of baseline and chemotherapy-induced DNA damage in non-target cells. Clin Exp Med 6: 177-190. |
| [15] | Kiffmeyer T, Hadtstein C (2007) Handling of chemotherapeutic drugs in the or: hazards and safety considerations. Cancer Treat Res 134: 275-290. |
| [16] |
Collins AR (2004) The comet assay for DNA damage and repair: principles, applications, and limitations. Mol Biotechnol 26: 249-261. doi: 10.1385/MB:26:3:249
|
| [17] |
Collins AR (2009) Investigating oxidative DNA damage and its repair using the comet assay. Mutat Res 681: 24-32. doi: 10.1016/j.mrrev.2007.10.002
|
| [18] |
Laffon B, Teixeira JP, Silva S, et al. (2005) Genotoxic effects in a population of nurses handling antineoplastic drugs, and relationship with genetic polymorphisms in DNA repair enzymes. Am J Ind Med 48: 128-136. doi: 10.1002/ajim.20189
|
| [19] | Dusinska M, Collins AR (2008) The comet assay in human biomonitoring: gene-environment interactions. Mutagenesis 23: 191-205. |
| [20] | Azqueta A, Shaposhnikov S, Collins A (2009) Detection of oxidised DNA using DNA repair enzymes, In: Anderson, D. and Dhawan A, Comet Assay Toxicol, Royal Society of Chemistry, 58-63. |
| [21] | Moller P, Knudsen LE, Loft S, et al. (2000) The comet assay as a rapid test in biomonitoring occupational exposure to DNA-damaging agents and effect of confounding factors. Cancer Epidemiol Biomark Prev Publ Am Assoc Cancer Res Cosponsored Am Soc Prev Oncol 9: 1005-1015. |
| [22] | Collins A.R, Dusinská M, Horváthová E, et al. (2001) Inter-individual differences in repair of DNA base oxidation, measured in vitro with the comet assay. Mutagenesis 16: 297-301. |
| [23] | Collins A, Oscoz A, Brunborg G, et al. (2008)The comet assay: topical issues. Mutagenesis 23: 143-151. |
| [24] |
Hoeijmakers JH (2001) Genome maintenance mechanisms for preventing cancer. Nature 411: 366-374. doi: 10.1038/35077232
|
| [25] |
Boiteux S, Radicella JP (1999) Base excision repair of 8-hydroxyguanine protects DNA from endogenous oxidative stress. Biochimie 81: 59-67. doi: 10.1016/S0300-9084(99)80039-X
|
| [26] | Ersson C (2011) International validation of the comet assay and a human intervention study. Stockholm: Karolinska Institutet. |
| [27] |
Pilger A, Rüdiger HW (2006) 8-Hydroxy-2′-deoxyguanosine as a marker of oxidative DNA damage related to occupational and environmental exposures. Int Arch Occup Environ Health 80: 1-15. doi: 10.1007/s00420-006-0106-7
|
| [28] |
Kohno T, Shinmura K, Tosaka M, et al. (1998) Genetic polymorphisms and alternative splicing of the hOGG1 gene, that is involved in the repair of 8-hydroxyguanine in damaged DNA. Oncogene 16: 3219-3225. doi: 10.1038/sj.onc.1201872
|
| [29] | Macpherson P, Barone F, Maga G, et al. (2005) 8-Oxoguanine incorporation into DNA repeats in vitro and mismatch recognition by MutSα. Nucleic Acids Res 33: 5094-5105. |
| [30] |
Hu YC, Ahrendt SA (2005) hOGG1 Ser326Cys polymorphism and G:C-to-T:A mutations: no evidence for a role in tobacco-related non small cell lung cancer. J Int Cancer 114: 387-393. doi: 10.1002/ijc.20730
|
| [31] |
Larson RR, Khazaeli MB, DillonHK (2003) A new monitoring method using solid sorbent media for evaluation of airborne cyclophosphamide and other antineoplastic agents. Appl Occup Environ Hyg 18: 120-131. doi: 10.1080/10473220301435
|
| [32] | Castiglia L, Miraglia N, Pieri M, et al. (2008) Evaluation of occupational exposure to antiblastic drugs in an Italian hospital oncological department. J Occup Health 50: 48-56. |
| [33] |
Hedmer M, Jönsson BAG, Nygren O (2004) Development and validation of methods for environmental monitoring of cyclophosphamide in workplaces. J Environ Monit 6: 979-984. doi: 10.1039/b409277e
|
| [34] | Hedmer M, Tinnerberg H, Axmon A, et al. (2008) Environmental and biological monitoring of antineoplastic drugs in four workplaces in a Swedish hospital. Int Arch Occup Environ Health 81: 899-911. |
| [35] | Kopp B, Crauste-Manciet S, Guibert A, et al. (2013) Environmental and Biological Monitoring of Platinum-Containing Drugs in Two Hospital Pharmacies Using Positive Air Pressure Isolators. Ann Occup Hyg 57: 374-383. |
| [36] | Schmaus G, Schierl R, Funck S (2002) Monitoring surface contamination by antineoplastic drugs using gas chromatography-mass spectrometry and voltammetry. Am J Health Syst Pharm 59: 956-961. |
| [37] | Singh N, Lai H (2009) Methods for freezing blood samples at -80 ℃ for DNA damage analysis in human leukocytes, In: Anderson D and Dhawan A, Comet Assay Toxicol, Royal Society of Chemistry, 120-128. |
| [38] |
Duthie SJ, Pirie L, Jenkinson AM, et al. (2002) Cryopreserved versus freshly isolated lymphocytes in human biomonitoring: endogenous and induced DNA damage, antioxidant status and repair capability. Mutagenesis 17: 211-214. doi: 10.1093/mutage/17.3.211
|
| [39] | Collins AR, Azqueta A (2012) Single-Cell Gel Electrophoresis Combined with Lesion-Specific Enzymes to Measure Oxidative Damage to DNA, In: Methods Cell Biol, Elsevier, 69-92. available from; http://linkinghub.elsevier.com/retrieve/pii/B9780124059146000044 |
| [40] | Collins AR (2002) The comet assay. Principles, applications, and limitations. Methods Mol Biol Clifton NJ 203: 163-177. |
| [41] | Hon C, Chua PP, Danyluk Q, et al. (2013) Examining factors that influence the effectiveness of cleaning antineoplastic drugs from drug preparation surfaces: a pilot study. J Oncol Pharm Pract 20: 210-216. |
| [42] |
Cavallo D, Ursini CL, Perniconi B, et al. (2005) Evaluation of genotoxic effects induced by exposure to antineoplastic drugs in lymphocytes and exfoliated buccal cells of oncology nurses and pharmacy employees. Mutat Res Toxicol Environ Mutagen 587: 45-51. doi: 10.1016/j.mrgentox.2005.07.008
|
| [43] |
Hedmer M, Wohlfart G (2012) Hygienic guidance values for wipe sampling of antineoplastic drugs in Swedish hospitals. J Environ Monit 14: 1968-1975. doi: 10.1039/c2em10704j
|
| [44] |
Viegas S, Pádua M, Veiga A, et al. (2014) Antineoplastic drugs contamination of workplaces surfaces in two Portuguese hospitals. Environ Monit Assess 186: 7807-18. doi: 10.1007/s10661-014-3969-1
|
| [45] | Collins AR (1999) Oxidative DNA damage, antioxidants, and cancer, BioEssays News Rev. Mol Cell Dev Biol 21: 238-246. |
| [46] | Cavallo D, Ursini CL, Rondinone B, et al. (2009) Evaluation of a suitable DNA damage biomarker for human biomonitoring of exposed workers. Environ Mol Mutagen: 781-790. |
| [47] |
Digue L, Orsière T, Méo M De, et al. (1999) Evaluation of the genotoxic activity of paclitaxel by the in vitro micronucleus test in combination with fluorescent in situ hybridization of a DNA centromeric probe and the alkaline single cell gel electrophoresis technique (comet assay) in human T-lymphocytes. Environ Mol Mutagen 34: 269-278. doi: 10.1002/(SICI)1098-2280(1999)34:4<269::AID-EM7>3.0.CO;2-D
|
| [48] |
Blasiak J, Kowalik J, Małecka-Panas EJ, et al. (2000) DNA damage and repair in human lymphocytes exposed to three anticancer platinum drugs. Teratog Carcinog Mutagen 20: 119-131. doi: 10.1002/(SICI)1520-6866(2000)20:3<119::AID-TCM3>3.0.CO;2-Z
|
| [49] |
Ursini CL, Cavallo D, Colombi A, et al. (2006) Evaluation of early DNA damage in healthcare workers handling antineoplastic drugs. Int Arch Occup Environ Health 80: 134-140. doi: 10.1007/s00420-006-0111-x
|
| [50] |
Sasaki M, Dakeishi M, Akeishi S, et al. (2008) Assessment of DNA Damage in Japanese Nurses Handling Antineoplastic Drugs by the Comet Assay. J Occup Health 50: 7-12. doi: 10.1539/joh.50.7
|
| [51] |
Ündeğer Ü, Başaran N, Kars A, et al. (1999) Assessment of DNA damage in nurses handling antineoplastic drugs by the alkaline COMET assay. Mutat Res Toxicol Environ Mutagen 439: 277-285. doi: 10.1016/S1383-5718(99)00002-9
|
| [52] |
Yoshida J, Kosaka H, Tomioka S, et al. (2006) Genotoxic Risks to Nurses from Contamination of the Work Environment with Antineoplastic Drugs in Japan. J Occup Health 48: 517-522. doi: 10.1539/joh.48.517
|
| [53] |
Branham MT, Nadin SB, Vargas-Roig LM, et al. (2004) DNA damage induced by paclitaxel and DNA repair capability of peripheral blood lymphocytes as evaluated by the alkaline comet assay. Mutat Res 560: 11-17. doi: 10.1016/j.mrgentox.2004.01.013
|
| [54] |
Mader RM, Kokalj A, Kratochvil E, et al. (2009) Longitudinal biomonitoring of nurses handling antineoplastic drugs. J Clin Nurs 18: 263-269. doi: 10.1111/j.1365-2702.2007.02189.x
|
| [55] |
Kopjar N, Garaj-Vrhovac V (2001) Application of the alkaline comet assay in human biomonitoring for genotoxicity: a study on Croatian medical personnel handling antineoplastic drugs. Mutagenesis 16: 71-78. doi: 10.1093/mutage/16.1.71
|
| [56] | Maluf SW, Erdtmann B (2000) Follow-up study of the genetic damage in lymphocytes of pharmacists and nurses handling antineoplastic drugs evaluated by cytokinesis-block micronuclei analysis and single cell gel electrophoresis assay. Mutat Res 471: 21-27. |
| [57] |
Kopjar N, Želježić D, Vrdoljak AL, et al. (2007) Irinotecan Toxicity to Human Blood Cells in vitro: Relationship between Various Biomarkers. Basic Clin Pharmacol Toxicol 100: 403-413. doi: 10.1111/j.1742-7843.2007.00068.x
|
| [58] | Rekhadevi PV, Sailaja N, Chandrasekhar M, et al. (2007) Genotoxicity assessment in oncology nurses handling anti-neoplastic drugs. Mutagenesis 22: 395-401. |
| [59] |
Cornetta T, Padua L, Testa A, et al. (2008) Molecular biomonitoring of a population of nurses handling antineoplastic drugs. Mutat Res 638: 75-82. doi: 10.1016/j.mrfmmm.2007.08.017
|
| [60] |
Izdes S, Sardas S, Kadioglu E, et al. (2009) Assessment of genotoxic damage in nurses occupationally exposed to anaesthetic gases or antineoplastic drugs by the comet assay. J Occup Health 51: 283-286. doi: 10.1539/joh.M8012
|
| [61] | Rombaldi F, Cassini C, Salvador M, et al. (2008) Occupational risk assessment of genotoxicity and oxidative stress in workers handling anti-neoplastic drugs during a working week. Mutagenesis 24: 143-148. |
| [62] |
Ladeira C, Viegas S, Pádua M, et al. (2014) Assessment of Genotoxic Effects in Nurses Handling Cytostatic Drugs. J Toxicol Environ Health A 77: 879-887. doi: 10.1080/15287394.2014.910158
|
| [63] |
Deng H, Zhang M, He J, et al. (2005) Investigating genetic damage in workers occupationally exposed to methotrexate using three genetic end-points. Mutagenesis 20: 351-357. doi: 10.1093/mutage/gei048
|
| [64] |
Xing DY, Tan E, Song N, et al. (2001) Ser326Cys polymorphism in hOGG1 gene and risk of esophageal cancer in a Chinese population. Int J Cancer 95: 140-143. doi: 10.1002/1097-0215(20010520)95:3<140::AID-IJC1024>3.0.CO;2-2
|
| [65] |
Elahi A, Zheng Z, Park P, et al. (2002) The human OGG1 DNA repair enzyme and its association with orolaryngeal cancer risk. Carcinogenesis 23: 1229-1234. doi: 10.1093/carcin/23.7.1229
|
| [66] |
Pawlowska E, Janik-Papis K, Rydzanicz M, et al. (2009) The Cys326 allele of the 8-oxoguanine DNA N-glycosylase 1 gene as a risk factor in smoking- and drinking-associated larynx cancer. Tohoku J Exp Med 219: 269-275. doi: 10.1620/tjem.219.269
|
| [67] |
Kim JI, Park YJ, Kim KH, et al. (2003) hOGG1 Ser326Cys polymorphism modifies the significance of the environmental risk factor for colon cancer. World J Gastroenterol 9: 956-960. doi: 10.3748/wjg.v9.i5.956
|
| [68] | Takezaki T, Gao C, Wu J, et al. (2002) hOGG1 Ser(326)Cys polymorphism and modification by environmental factors of stomach cancer risk in Chinese. Int J Cancer 99: 624-627. |
| [69] |
Chen SK, Hsieh WA, Tsai MH, et al. (2003) Age-associated decrease of oxidative repair enzymes, human 8-oxoguanine DNA glycosylases (hOgg1), in human aging. J Radiat Res (Tokyo) 44: 31-35. doi: 10.1269/jrr.44.31
|
| [70] | Aka P, Mateuca R, Buchet JP, et al. (2004) Are genetic polymorphisms in OGG1, XRCC1 and XRCC3 genes predictive for the DNA strand break repair phenotype and genotoxicity in workers exposed to low dose ionising radiations? Mutat Res 556: 169-181. |
| [71] | Mateuca RA, Roelants M, Iarmarcovai G, et al. (2008) hOGG1(326), XRCC1(399) and XRCC3(241) polymorphisms influence micronucleus frequencies in human lymphocytes in vivo. Mutagenesis 23: 35-41. |
| [72] | Tarng DC, Tsai TJ, Chen WT, et al. (2001) Effect of Human OGG1 1245C→G Gene Polymorphism on 8-Hydroxy-2'-Deoxyguanosine Levels of Leukocyte DNA among Patients Undergoing Chronic Hemodialysis. J Am Soc Nephrol 12: 2338-2347. |
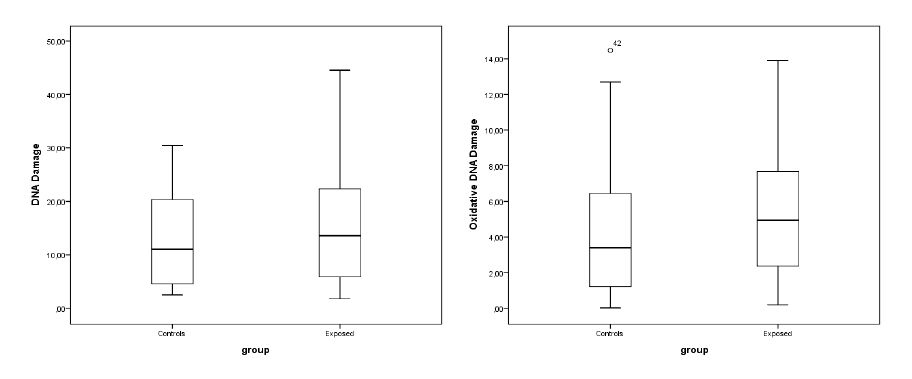
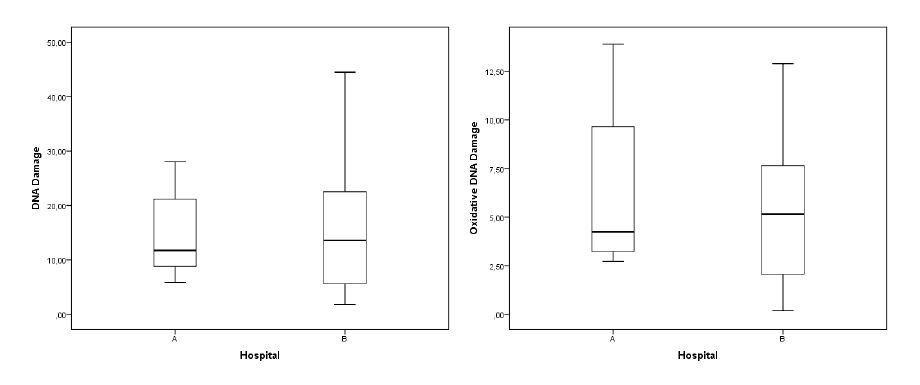
Figures(2) / Tables(4)

Carina Ladeira, Susana Viegas, Mário Pádua, Elisabete Carolino, Manuel C. Gomes, Miguel Brito. Relation between DNA damage measured by comet assay and OGG1 Ser326Cys polymorphism in antineoplastic drugs biomonitoring[J]. AIMS Genetics, 2015, 2(3): 204-218. doi: 10.3934/genet.2015.3.204







 DownLoad:
DownLoad: