Citation: Matteo Moncecchi, Davide Falabretti, Marco Merlo. Regional energy planning based on distribution grid hosting capacity[J]. AIMS Energy, 2019, 7(3): 264-284. doi: 10.3934/energy.2019.3.264

| [1] |
Santos IN, Ćuk V, Almeida PM, et al. (2015) Considerations on Hosting Capacity for harmonic distortions on transmission and distribution systems. Electr Power Syst Res 119: 199–206. doi: 10.1016/j.epsr.2014.09.020

|
| [2] |
Lopes JAP, Hatziargyriou N, Mutale J, et al. (2007) Integrating distributed generation into electric power systems: A review of drivers, challenges and opportunities. Electr Power Syst Res 77: 1189–1203. doi: 10.1016/j.epsr.2006.08.016
|
| [3] | Iyer H, Ray S, Ramakumar R (2006) Assessment of distributed generation based on voltage profile improvement and line loss reduction. In Proceedings of the IEEE Power Engineering Society Transmission and Distribution Conference 1171–1176. |
| [4] | AEEG (2008) Delibera ARG/elt 99/08-Testo integrato delle connessioni attive TICA, Gazzetta ufficiale della Repubblica Italiana (www.arera.it). |
| [5] |
Singh B, Sharma J (2017) A review on distributed generation planning. Renewable Sustainable Energy Rev 76: 529–544. doi: 10.1016/j.rser.2017.03.034
|
| [6] |
Keane A, Ochoa LF, Borges CLT, et al. (2013) State-of-the-Art techniques and challenges ahead for distributed generation planning and optimization. IEEE Trans Power Syst 28: 1493–1502. doi: 10.1109/TPWRS.2012.2214406
|
| [7] | Mahesh K, Nallagownden PAL, Elamvazuthi IAL (2015) Optimal placement and sizing of DG in distribution system using accelerated PSO for power loss minimization. In 2015 IEEE Conference on Energy Conversion (CENCON) 193–198. |
| [8] |
Keane A, Zhou Q, Bialek JW, et al. (2009) Planning and operating non-firm distributed generation. IET Renew Power Gener 3: 455–464. doi: 10.1049/iet-rpg.2008.0058
|
| [9] |
Zhu D, Broadwater RP, Tam KS, et al. (2006) Impact of DG placement on reliability and efficiency with time-varying loads. IEEE Trans Power Syst 21: 419–427. doi: 10.1109/TPWRS.2005.860943
|
| [10] |
Ochoa LF, Dent CJ, Harrison GP (2010) Distribution network capacity assessment: Variable DG and active networks. IEEE Trans Power Syst 25: 87–95. doi: 10.1109/TPWRS.2009.2031223
|
| [11] | Zeng F, Bie Z, Li X, et al. (2018) Annual renewable energy planning platform: Methodology and design. 13th IEEE Conference on Automation Science and Engineering (CASE) 1392–1397. |
| [12] |
Georgopoulou E, Lalas D, Papagiannakis L (1997) A Multicriteria Decision Aid approach for energy planning problems: The case of renewable energy option. Eur J Oper Res 103: 38–54. doi: 10.1016/S0377-2217(96)00263-9
|
| [13] | Meng T, Qian M, Zhao D (2018) Peak regulation strategy of regional power systems for large-scale renewable generation accommodation. 2018 IEEE International Conference on Energy Internet (ICEI) 99–104. |
| [14] |
Hong B, Chen J, Zhang W, et al. (2018) Integrated energy system planning at modular regional-user level based on a two-layer bus structure. CSEE J Power Energy Syst 4: 188–196. doi: 10.17775/CSEEJPES.2018.00110
|
| [15] |
Wang D, Liu L, Jia H, et al. (2018) Review of key problems related to integrated energy distribution systems. CSEE J Power Energy Syst 4: 130–145. doi: 10.17775/CSEEJPES.2018.00570
|
| [16] | Liu Z, Yang P, Peng J, et al. (2018) Capacity allocation for regional integrated energy system considering typical day economic operation. 2018 IEEE International Conference on Energy Internet (ICEI) 60–65. |
| [17] | Tannirandon A, Gerdsri N (2016) Energy planning for sustainable development-challenge and experience sharing from Thailand. 2016 IEEE International Conference on Management of Innovation and Technology (ICMIT) 115–120. |
| [18] |
Brand B, Missaoui R (2014) Multi-criteria analysis of electricity generation mix scenarios in Tunisia. Renewable Sustainable Energy Rev 39: 251–261. doi: 10.1016/j.rser.2014.07.069
|
| [19] |
Şengül Ü, Eren M, Shiraz SE, et al. (2015) Fuzzy TOPSIS method for ranking renewable energy supply systems in Turkey. Renewable Energy 75: 617–625. doi: 10.1016/j.renene.2014.10.045
|
| [20] |
Malkawi S, Al-Nimr M, Azizi D (2017) A multi-criteria optimization analysis for Jordan's energy mix. Energy 127: 680–696. doi: 10.1016/j.energy.2017.04.015
|
| [21] |
Volkart K, Weidmann N, Bauer C, et al. (2017) Multi-criteria decision analysis of energy system transformation pathways: A case study for Switzerland. Energy Policy 106: 155–168. doi: 10.1016/j.enpol.2017.03.026
|
| [22] |
Mourmouris JC, Potolias C (2013) A multi-criteria methodology for energy planning and developing renewable energy sources at a regional level: A case study Thassos, Greece. Energy Policy 52: 522–530. doi: 10.1016/j.enpol.2012.09.074
|
| [23] |
Baležentis T, Streimikiene D (2017) Multi-criteria ranking of energy generation scenarios with Monte Carlo simulation. Appl Energy 185: 862–871. doi: 10.1016/j.apenergy.2016.10.085
|
| [24] | Mirbagheri SM, Moncecchi M, Falabretti D, et al. (2018) Hosting Capacity evaluation in networks with parameter uncertainties. 18th International Conference on Harmonics and Quality of Power. |
| [25] | Falabretti D, Ilea V, Merlo M, et al. (2018) Hosting Capacity analysis: A review and a new evaluation method in case of parameters uncertainty and multi-generator. 2018 IEEE International Conference on Environment and Electrical Engineering and 2018 IEEE Industrial and Commercial Power Systems Europe, (EEEIC/I&CPS Europe). |
| [26] | Ministero dello Sviluppo Economico (2012) Decreto Ministero dello Sviluppo Economico 15 marzo 2012. Definizione e qualificazione degli obiettivi regionali in materia di fonti rinnovabili e definizione della modalità di gestione dei casi di mancato raggiungimento degli obiettivi da parte delle regioni. Gazzetta ufficiale della Repubblica Italiana (www.gazzettaufficiale.it). |
| [27] | European Parliament (2009) Directive 2009/28/EC of the european parliament and of the council of 23 April 2009. Off J Eur Union 140: 16–62. |
| [28] |
Zio E, Delfanti M, Giorgi L, et al. (2015) Monte Carlo simulation-based probabilistic assessment of DG penetration in medium voltage distribution networks. Int J Electr Power Energy Syst 64: 852–860. doi: 10.1016/j.ijepes.2014.08.004
|
| [29] |
Widén J, Wäckelgård E, Paatero J, et al. (2010) Impacts of distributed photovoltaics on network voltages: Stochastic simulations of three Swedish low-voltage distribution grids. Electr Power Syst Res 80: 1562–1571. doi: 10.1016/j.epsr.2010.07.007
|
| [30] |
Kolenc M, Papič I, Blažič B (2015) Assessment of maximum distributed generation penetration levels in low voltage networks using a probabilistic approach. Int J Electr Power Energy Syst 64: 505–515. doi: 10.1016/j.ijepes.2014.07.063
|
| [31] | Ballanti A, Pilo F, Navarro-Espinosa A, et al. (2013) Assessing the benefits of PV var absorption on the Hosting Capacity of LV feeders. 2013 4th IEEE/PES Innovative Smart Grid Technologies Europe, ISGT Europe 2013 1–5. |
| [32] |
Abdmouleh Z, Gastli A, Ben-Brahim L, et al. (2017) Review of optimization techniques applied for the integration of distributed generation from renewable energy sources. Renewable Energy 113: 266–280. doi: 10.1016/j.renene.2017.05.087
|
| [33] |
Pesaran MHA, Huy PD, Ramachandaramurthy VK (2017) A review of the optimal allocation of distributed generation: Objectives, constraints, methods, and algorithms. Renewable Sustainable Energy Rev 75: 293–312. doi: 10.1016/j.rser.2016.10.071
|
| [34] |
Conti S, Raiti S (2007) Probabilistic load flow using Monte Carlo techniques for distribution networks with photovoltaic generators. Sol Energy 81: 1473–1481. doi: 10.1016/j.solener.2007.02.007
|
| [35] |
Delfanti M, Falabretti D, Merlo M (2013) Dispersed generation impact on distribution network losses. Electr Power Syst Res 97: 10–18. doi: 10.1016/j.epsr.2012.11.018
|
| [36] | Bertini D, Falabretti D, Moneta D, et al. (2011) Hosting Capacity of italian distribution networks. CIRED 21st Int Conf Electr Distrib. |
| [37] | Delfanti M, Merlo M, Monfredini G, et al. (2010) Hosting dispersed generation on Italian MV networks: Towards smart grids. 14th International Conference on Harmonics and Quality of Power. |
| [38] | Delfanti M, Falabretti D, Mandelli S, et al. (2016) Energy planning approach for an efficient distribution grid. In CIRED Workshop 2016. |
| [39] | CEI (2014) Regola tecnica di riferimento per la connessione di Utenti attivi e passivi alle reti AT ed MT delle imprese distributrici di energia elettrica. Norma 0–16. Comitato Elettrotecnico Italiano (www.cei.it). |
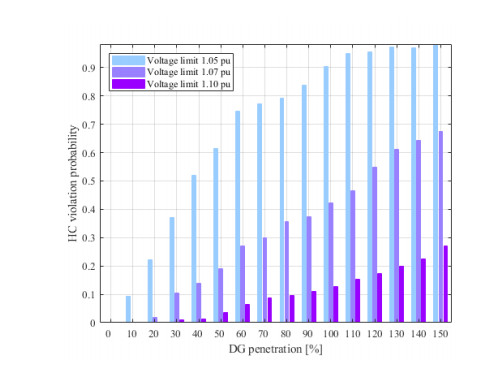
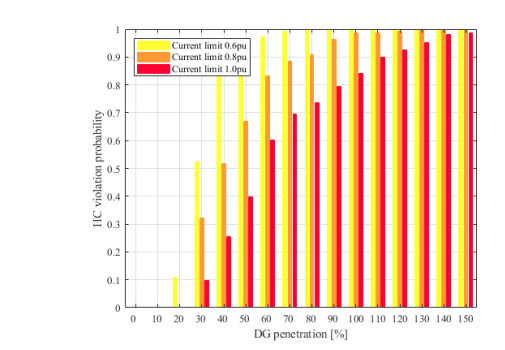
Figures(10) / Tables(5)

Matteo Moncecchi, Davide Falabretti, Marco Merlo. Regional energy planning based on distribution grid hosting capacity[J]. AIMS Energy, 2019, 7(3): 264-284. doi: 10.3934/energy.2019.3.264







 DownLoad:
DownLoad: