Citation: Paola Brun. The profiles of dysbiotic microbial communities[J]. AIMS Microbiology, 2019, 5(1): 87-101. doi: 10.3934/microbiol.2019.1.87

| [1] | Carding S, Verbeke K, Vipond DT, et al. (2015) Dysbiosis of the gut microbiota in disease. Microb Ecol Heal Dis 26: 1–9. |
| [2] |
Hold GL, Smith M, Grange C, et al. (2014) Role of the gut microbiota in inflammatory bowel disease pathogenesis: What have we learnt in the past 10 years? World J Gastroenterol 20: 1192–1210. doi: 10.3748/wjg.v20.i5.1192

|
| [3] |
Cox AJ, West NP, Cripps AW (2015) Obesity, inflammation, and the gut microbiota. Lancet Diabetes Endocrinol 3: 207–215. doi: 10.1016/S2213-8587(14)70134-2
|
| [4] |
Sartor RB (2008) Microbial influences in inflammatory bowel diseases. Gastroenterology 134: 577–594. doi: 10.1053/j.gastro.2007.11.059
|
| [5] |
Quigley EMM (2017) Microbiota-brain-gut axis and neurodegenerative diseases. Curr Neurol Neurosci Rep 17: 94. doi: 10.1007/s11910-017-0802-6
|
| [6] |
Marchesi JR, Dutilh BE, Hall N, et al. (2011) Towards the human colorectal cancer microbiome. PLoS One 6: e20447. doi: 10.1371/journal.pone.0020447
|
| [7] |
Gentile CL, Weir TL (2018) The gut microbiota at the intersection of diet and human health. Science 362: 776–780. doi: 10.1126/science.aau5812
|
| [8] | Claesson MJ, Clooney AG, O'Toole PW (2017) A clinician's guide to microbiome analysis. Nat Rev Gastroenterol Hepatol 14: 585–595. |
| [9] |
Bäckhed F, Ley RE, Sonnenburg JL, et al. (2005) Host-bacterial mutualism in the human intestine. Science 307: 1915–1920. doi: 10.1126/science.1104816
|
| [10] |
Zhang M, Liu B, Zhang Y, et al. (2007) Structural shifts of mucosa-associated lactobacilli and Clostridium leptum subgroup in patients with ulcerative colitis. J Clin Microbiol 45: 496–500. doi: 10.1128/JCM.01720-06
|
| [11] |
Donskey CJ, Hujer AM, Das SM, et al. (2003) Use of denaturing gradient gel electrophoresis for analysis of the stool microbiota of hospitalized patients. J Microbiol Methods 54: 249–256. doi: 10.1016/S0167-7012(03)00059-9
|
| [12] |
Voltan S, Castagliuolo I, Elli M, et al. (2007) Aggregating phenotype in Lactobacillus crispatus determines intestinal colonization and TLR2 and TLR4 modulation in murine colonic mucosa. Clin Vaccine Immunol 14: 1138–1148. doi: 10.1128/CVI.00079-07
|
| [13] |
Turnbaugh PJ, Hamady M, Yatsunenko T, et al. (2009) A core gut microbiome in obese and lean twins. Nature 457: 480-484. doi: 10.1038/nature07540
|
| [14] |
Ngom-bru C, Barretto C. (2012) Gut microbiota: Methodological aspects to describe taxonomy and functionality. Brief Bioinform 13: 747–750. doi: 10.1093/bib/bbs019
|
| [15] |
Wang Q, Garrity GM, Tiedje JM, et al. (2007) Naïve Bayesian classifier for rapid assignment of rRNA sequences into the new bacterial taxonomy. Appl Environ Microbiol. 73: 5261–5267. doi: 10.1128/AEM.00062-07
|
| [16] |
Hiergeist A, Reischl U. (2016) Multicenter quality assessment of 16S ribosomal DNA-sequencing for microbiome analyses reveals high inter-center variability. Int J Med Microbiol 306: 334–342. doi: 10.1016/j.ijmm.2016.03.005
|
| [17] |
Yang YW, Chen MK, Yang BY, et al. (2015) Use of 16S rRNA gene-targeted group-specific primers for real-time PCR analysis of predominant bacteria in mouse feces. Appl Environ Microbiol 81: 6749–6756. doi: 10.1128/AEM.01906-15
|
| [18] | Jovel J, Patterson J, Wang W, et al. (2016) Characterization of the gut microbiome using 16S or shotgun metagenomics. Front Microbiol 7: 1–17. |
| [19] |
Kanehisa M (2004) The KEGG resource for deciphering the genome. Nucleic Acids Res 32: D277–D280. doi: 10.1093/nar/gkh063
|
| [20] |
Engel P, Stepanauskas R, Moran NA (2014) Hidden diversity in honey bee gut symbionts detected by single-cell genomics. PLoS Genet 10: e1004596. doi: 10.1371/journal.pgen.1004596
|
| [21] |
Wang J, Qin J, Li Y, et al. (2012) A metagenome-wide association study of gut microbiota in type 2 diabetes. Nature 490: 55–60. doi: 10.1038/nature11450
|
| [22] |
Kostic AD, Xavier RJ, Gevers D (2014) The microbiome in inflammatory bowel disease: Current status and the future ahead. Gastroenterology 146: 1489–1499. doi: 10.1053/j.gastro.2014.02.009
|
| [23] |
Greenblum S, Turnbaugh PJ, Borenstein E (2012) Metagenomic systems biology of the human gut microbiome reveals topological shifts associated with obesity and inflammatory bowel disease. Proc Natl Acad Sci 109: 594–599. doi: 10.1073/pnas.1116053109
|
| [24] |
Karlsson FH, Tremaroli V, Nookaew I, et al. (2013) Gut metagenome in European women with normal, impaired and diabetic glucose control. Nature 498: 99–103. doi: 10.1038/nature12198
|
| [25] | Vogtmann E, Hua X, Zeller G, et al. (2016) Colorectal cancer and the human gut microbiome: Reproducibility with whole-genome shotgun sequencing. PLoS One 11: 1–13. |
| [26] |
Zeller G, Tap J, Voigt AY, et al. (2014) Potential of fecal microbiota for early-stage detection of colorectal cancer. Mol Syst Biol 10: 766. doi: 10.15252/msb.20145645
|
| [27] |
Moustafa A, Li W, Anderson EL, et al. (2018) Genetic risk, dysbiosis, and treatment stratification using host genome and gut microbiome in inflammatory bowel disease. Clin Transl Gastroenterol 9: e132–e138. doi: 10.1038/ctg.2017.58
|
| [28] |
Franzosa EA, Morgan XC, Segata N, et al. (2014) Relating the metatranscriptome and metagenome of the human gut. Proc Natl Acad Sci 111: E2329–E2338. doi: 10.1073/pnas.1319284111
|
| [29] |
Abu-Ali GS, Mehta RS, Lloyd-Price J, et al. (2018) Metatranscriptome of human faecal microbial communities in a cohort of adult men. Nat Microbiol 3: 356–366. doi: 10.1038/s41564-017-0084-4
|
| [30] |
Camp JG, Frank CL, Lickwar CR, et al. (2014) Microbiota modulate transcription in the intestinal epithelium without remodeling the accessible chromatin landscape. Genome Res 24: 1504–1516. doi: 10.1101/gr.165845.113
|
| [31] |
Pan WH, Sommer F, Falk-Paulsen M, et al. (2018) Exposure to the gut microbiota drives distinct methylome and transcriptome changes in intestinal epithelial cells during postnatal development. Genome Med 10: 1–15. doi: 10.1186/s13073-017-0512-3
|
| [32] |
Sung J, Kim S, Cabatbat JJ, et al. (2017) Global metabolic interaction network of the human gut microbiota for context-specific community-scale analysis. Nature Communications 8: 15393. doi: 10.1038/ncomms15393
|
| [33] | Väremo L, Nookaew I, Nielsen J (2013) Novel insights into obesity and diabetes through genome-scale metabolic modeling Front Physiol 4: 1–7. |
| [34] | Lewis NE, Hixson KK, Conrad TM, et al. (2010) Omic data from evolved E. coli are consistent with computed optimal growth from genome-scale models Mol Syst Biol 6: 390. |
| [35] |
Fang X, Monk JM, Mih N, et al. (2018) Escherichia coli B2 strains prevalent in inflammatory bowel disease patients have distinct metabolic capabilities that enable colonization of intestinal mucosa. BMC Syst Biol 12: 1–10. doi: 10.1186/s12918-017-0484-3
|
| [36] |
Ferrer M, Ruiz A, Lanza F, et al. (2013) Microbiota from the distal guts of lean and obese adolescents exhibit partial functional redundancy besides clear differences in community structure. Environ Microbiol 15: 211–226. doi: 10.1111/j.1462-2920.2012.02845.x
|
| [37] |
Kolmeder CA, Ritari J, Verdam FJ, et al. (2015) Colonic metaproteomic signatures of active bacteria and the host in obesity. Proteomics 15: 3544–3552. doi: 10.1002/pmic.201500049
|
| [38] |
De Filippis F, Pellegrini N, Vannini L, et al. (2016) High-level adherence to a Mediterranean diet beneficially impacts the gut microbiota and associated metabolome. Gut 65: 1812–1821. doi: 10.1136/gutjnl-2015-309957
|
| [39] |
Wu GD, Compher C, Chen EZ, et al. (2016) Comparative metabolomics in vegans and omnivores reveal constraints on diet-dependent gut microbiota metabolite production. Gut 65: 63–72. doi: 10.1136/gutjnl-2014-308209
|
| [40] |
Pasinetti GM, Singh R, Westfall S, et al. (2018) The Role of the gut microbiota in the metabolism of polyphenols as characterized by gnotobiotic mice. J Alzheimer's Dis 63: 409–421. doi: 10.3233/JAD-171151
|
| [41] |
Duffy LC, Raiten DJ, Hubbard VS, et al. (2015) Progress and challenges in developing metabolic footprints from diet in human gut microbial cometabolism. J Nutr 145: 1123S–1130S. doi: 10.3945/jn.114.194936
|
| [42] |
Schroeder BO, Bäckhed F (2016) Signals from the gut microbiota to distant organs in physiology and disease. Nat Med 22: 1079–1089. doi: 10.1038/nm.4185
|
| [43] |
Lamas B, Richard ML, Leducq V, et al. (2016) CARD9 impacts colitis by altering gut microbiota metabolism of tryptophan into aryl hydrocarbon receptor ligands. Nat Med 22: 598–605. doi: 10.1038/nm.4102
|
| [44] |
Thorburn AN, Mckenzie CI, Shen S, et al. (2015) Evidence that asthma is a developmental origin disease influenced by maternal diet and bacterial metabolites. Nat Commun 6: 7320. doi: 10.1038/ncomms8320
|
| [45] | Macfabe DF. (2015) Enteric short-chain fatty acids: microbial messengers of metabolism, mitochondria, and mind: implications in autism spectrum disorders. Microbial Ecology in Health & Disease 26: 28177 . |
| [46] |
Dinan TG, Cryan JF. (2017) Gut-brain axis in 2016: Brain-gut-microbiota axis-mood, metabolism and behaviour. Nat Rev Gastroenterol Hepatol 14: 69–70. doi: 10.1038/nrgastro.2016.200
|
| [47] |
Shah P, Fritz J V., Glaab E, et al. (2016) A microfluidics-based in vitro model of the gastrointestinal human-microbe interface. Nat Commun 7: 11535. doi: 10.1038/ncomms11535
|
| [48] | Lasken RS, Mclean JS (2014) Recent advances in genomic DNA sequencing of microbial species from single cells. Nat Publ Gr 15: 577–584. |
| [49] |
Zhang Q, Wang T, Zhou Q, et al. (2017) Development of a facile droplet- based single-cell isolation platform for cultivation and genomic analysis in microorganisms. Sci Rep 7: 1–11. doi: 10.1038/s41598-016-0028-x
|
| [50] |
Wang Y, Ji Y, Wharfe ES, et al. (2013) Raman activated cell ejection for isolation of single cells. Anal Chem 85: 10697–10701. doi: 10.1021/ac403107p
|
| [51] | Teng L, Wang X, Wang X, et al. (2016) Label-free , rapid and quantitative phenotyping of stress response in E . coli via ramanome. Sci Rep 6: 34359. |
| [52] |
Huang KC (2015) Applications of imaging for bacterial systems biology. Curr Opin Microbiol 27: 114–120. doi: 10.1016/j.mib.2015.08.003
|
| [53] |
Tropini C, Earle KA, Huang KC, et al. (2017) The gut microbiome: Connecting spatial organization to function. Cell Host Microbe 21: 433–442. doi: 10.1016/j.chom.2017.03.010
|
| [54] |
Fung TC, Artis D, Sonnenberg GF (2014) Anatomical localization of commensal bacteria in immune cell homeostasis and disease. Immunol Rev 260: 35–49. doi: 10.1111/imr.12186
|
| [55] |
Arena ET, Campbell-Valois FX, Tinevez JY, et al. (2015) Bioimage analysis of Shigella infection reveals targeting of colonic crypts. Proc Natl Acad Sci 112: E3282–E3290. doi: 10.1073/pnas.1509091112
|
| [56] |
Müller AJ, Kaiser P, Dittmar KEJ, et al. (2012) Salmonella gut invasion involves TTSS-2-dependent epithelial traversal, basolateral exit, and uptake by epithelium-sampling lamina propria phagocytes. Cell Host Microbe 11: 19–32. doi: 10.1016/j.chom.2011.11.013
|
| [57] | Swidsinski A, Weber J, Loening-Baucke V, et al. (2015) Spatial organization and composition of the mucosal flora in patients with inflammatory bowel disease. J Clin Microbiol 43: 3380–3389. |
| [58] |
Dejea CM, Wick EC, Hechenbleikner EM, et al. (2014) Microbiota organization is a distinct feature of proximal colorectal cancers. Proc Natl Acad Sci 111: 18321–18326. doi: 10.1073/pnas.1406199111
|
| [59] |
Lu JW, Ho Y-, Ciou SC, et al. (2017) Innovative disease model: Zebrafish as an in vivo platform for intestinal disorder and tumors. Biomedicines 5: 58. doi: 10.3390/biomedicines5040058
|
| [60] |
Eckburg (2008) Diversity of the human intestinal microbial flora. Brain Behav Immun 22: 629. doi: 10.1016/j.bbi.2008.05.010
|
| [61] |
Lagier JC, Khelaifia S, Alou MT, et al. (2016) Culture of previously uncultured members of the human gut microbiota by culturomics. Nat Microbiol 1: 16203. doi: 10.1038/nmicrobiol.2016.203
|
| [62] |
Gross A, Schoendube J, Zimmermann S, et al. (2015) Technologies for single-cell isolation. Int J Mol Sci 16: 16897–16919. doi: 10.3390/ijms160816897
|
| [63] |
Lagier JC, Hugon P, Khelaifia S, et al. (2015) The rebirth of culture in microbiology through the example of culturomics to study human gut microbiota. Clin Microbiol Rev 28: 237–264. doi: 10.1128/CMR.00014-14
|
| [64] | Rettedal EA, Gumpert H, Sommer MOA (2014) Cultivation-based multiplex phenotyping of human gut microbiota allows targeted recovery of previously uncultured bacteria. Nat Commun 5: 1–9. |
| [65] |
Lagier JC, Armougom F, Million M, et al. (2012) Microbial culturomics: Paradigm shift in the human gut microbiome study. Clin Microbiol Infect 18: 1185–1193. doi: 10.1111/1469-0691.12023
|
| [66] |
Nichols D, Cahoon N, Trakhtenberg EM, et al. (2010) Use of ichip for high-throughput in situ cultivation of 'uncultivable microbial species. Appl Environ Microbiol 76: 2445–2450. doi: 10.1128/AEM.01754-09
|
| [67] |
Sonnenburg ED, Smits SA, Tikhonov M, et al. (2016) Diet-induced extinctions in the gut microbiota compound over generations. Nature 529: 212–215. doi: 10.1038/nature16504
|
| [68] |
Arrieta MC, Walter J, Finlay BB (2016) Human Microbiota-Associated Mice: A Model with Challenges. Cell Host Microbe 19: 575–578. doi: 10.1016/j.chom.2016.04.014
|
| [69] |
Turnbaugh P, Lozupone CA, Knight RD, et al. (2005) Obesity alters gut microbial ecology. Proc Natl Acad Sci USA 102: 11070–11075. doi: 10.1073/pnas.0504978102
|
| [70] | Turnbaugh PJ, Ridaura VK , Faith JJ , et al. (2009) The effect of diet on the human gut microbiome: A metagenomic analysis in humanized gnotobiotic mice. Sci Transl Med 14: 6ra14. |
| [71] |
Rawls JF, Mahowald MA, Ley RE, et al. (2006) Reciprocal gut microbiota transplants from zebrafish and mice to germ-free recipients reveal host habitat selection. Cell 127: 423–433. doi: 10.1016/j.cell.2006.08.043
|
| [72] |
Chung H, Pamp SJ, Hill JA, et al. (2012) Gut immune maturation depends on colonization with a host-specific microbiota. Cell 149: 1578–1593. doi: 10.1016/j.cell.2012.04.037
|
| [73] | Kauffman AL, Gyurdieva AV, Mabus JR, et al. (2013) Alternative functional in vitro models of human intestinal epithelia. Front Pharmacol 4: 1–18. |
| [74] | Moon C, Vandussen KL, Miyoshi H, et al. (2013) Development of a primary mouse intestinal epithelial cell monolayer culture system to evaluate factors that modulate IgA transcytosis. Mucosal Immunol 7: 818–828. |
| [75] | Chen Y, Lin Y, Davis KM, et al. (2015) Robust bioengineered 3D functional human intestinal epithelium. Nat Publ Gr. 2015: 1–11. |
| [76] | Ma L, Kim J, Hatzenpichler R, et al. (2014) Gene-targeted microfluidic cultivation validated by isolation of a gut bacterium listed in Human Microbiome Project's Most Wanted taxa 111: 9768–9773. |
| [77] | Reygner J, Condette CJ, Bruneau A, et al. (2016) Changes in composition and function of human intestinal microbiota exposed to chlorpyrifos in oil as assessed by the SHIME® model. Int J Environ Res Public Health 13: 1–18. |
| [78] |
Petrof EO, Khoruts A (2014) From stool transplants to next-generation microbiota therapeutics. Gastroenterology 146: 1573–1582. doi: 10.1053/j.gastro.2014.01.004
|
| [79] |
Auchtung JM, Robinson CD, Britton RA (2015) Cultivation of stable, reproducible microbial communities from different fecal donors using minibioreactor arrays (MBRAs). Microbiome 3: 1–15. doi: 10.1186/s40168-014-0066-1
|
| [80] |
Williamson IA, Arnold JW, Samsa LA, et al. (2018) A high-throughput organoid microinjection platform to study gastrointestinal microbiota and luminal physiology. Cellr Mol Gastroenterol Hepatol 6: 301–319. doi: 10.1016/j.jcmgh.2018.05.004
|
| [81] |
Leslie JL, Huang S, Opp JS, et al. (2015) Persistence and toxin production by Clostridium difficile within human intestinal organoids result in disruption of epithelial paracellular barrier function. Infect Immun 83: 138–145. doi: 10.1128/IAI.02561-14
|
| [82] |
Gracz AD, Williamson IA, Roche KC, et al. (2015) A high-throughput platform for stem cell niche co-cultures and downstream gene expression analysis. Nat Cell Biol 17: 340–349. doi: 10.1038/ncb3104
|
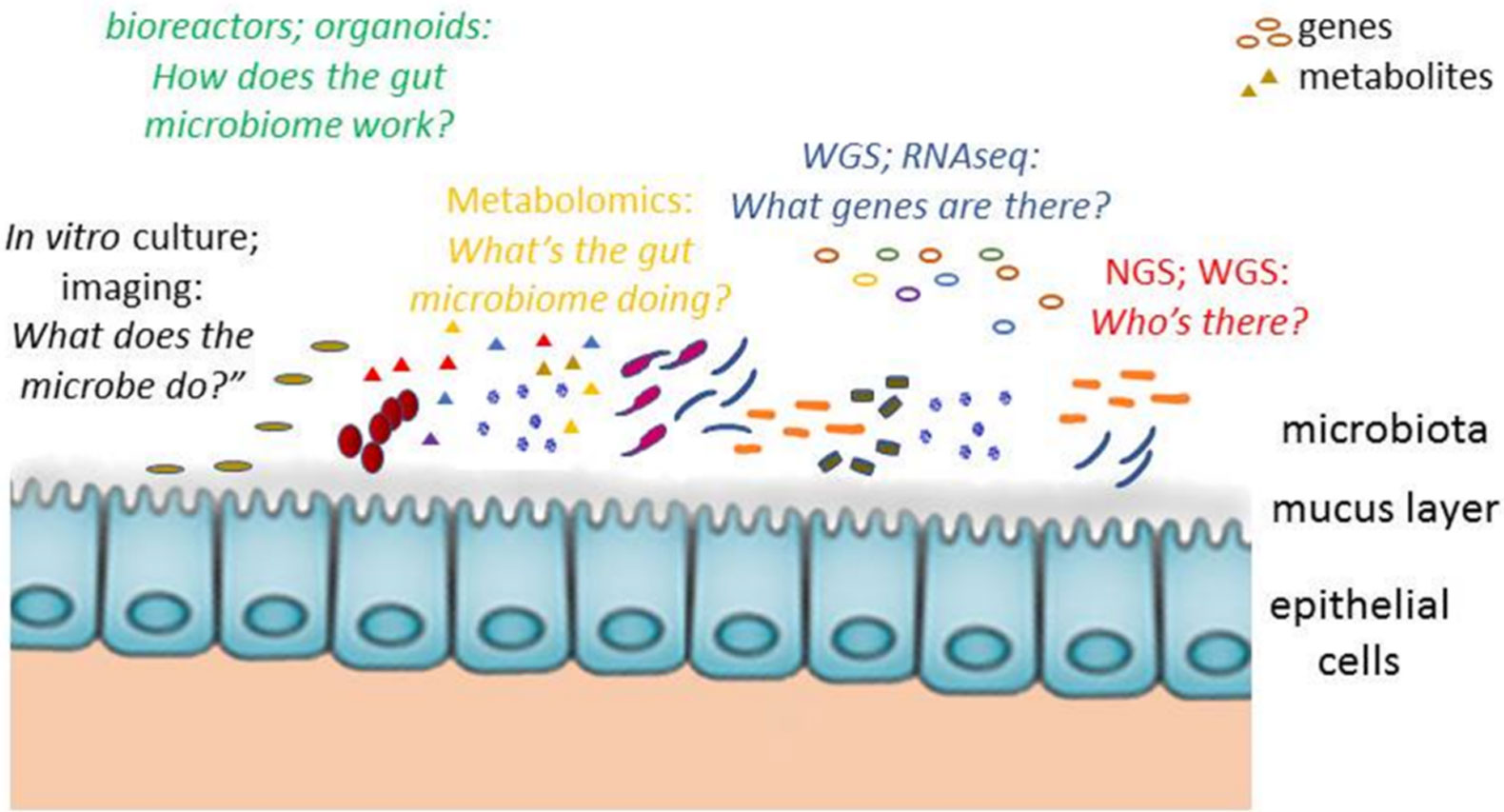
Figures(1) / Tables(1)

Paola Brun. The profiles of dysbiotic microbial communities[J]. AIMS Microbiology, 2019, 5(1): 87-101. doi: 10.3934/microbiol.2019.1.87







 DownLoad:
DownLoad: