Citation: Siddhartha Mishra. A machine learning framework for data driven acceleration of computations of differential equations[J]. Mathematics in Engineering, 2019, 1(1): 118-146. doi: 10.3934/Mine.2018.1.118

| [1] |
Barron AR (1993) Universal approximation bounds for superpositions of a sigmoidal function. IEEE T Inform Theory 39: 930–945. doi: 10.1109/18.256500

|
| [2] | Beck C, Weinan E and Jentzen A (2017) Machine learning approximation algorithms for high dimensional fully nonlinear partial differential equations and second-order backward stochastic differential equations. Technical Report 2017-49, Seminar for Applied Mathematics, ETH Zürich. |
| [3] | Bijl H, Lucor D, Mishra S, et al. (2014) Uncertainty quantification in computational fluid dynamics. Lecture notes in computational science and engineering 92, Springer. |
| [4] | Borzi A and Schulz V (2012) Computational optimization of systems governed by partial differential equations, SIAM. |
| [5] | Brenner SC and Scott LR (2008) The mathematical theory of finite element methods. Texts in applied mathematics 15, Springer. |
| [6] | Dafermos CM (2005) Hyperbolic Conservation Laws in Continuum Physics (2nd Ed.), Springer Verlag. |
| [7] |
Weinan E and Yu B (2018) The deep Ritz method: a deep learning-based numerical algorithm for solving variational problems. Commun Math Stat 6: 1–12. doi: 10.1007/s40304-018-0127-z
|
| [8] |
Fjordholm US, Mishra S and Tadmor E (2012) Arbitrarily high-order order accurate essentially non-oscillatory entropy stable schemes for systems of conservation laws. SIAM J Numer Anal 50: 544–573. doi: 10.1137/110836961
|
| [9] | Ghanem R, Higdon D and Owhadi H (2016) Handbook of uncertainty quantification, Springer. |
| [10] | Godlewski E and Raviart PA (1991) Hyperbolic Systems of Conservation Laws. Mathematiques et Applications, Ellipses Publ., Paris. |
| [11] | Goodfellow I, Bengio Y and Courville A (2016) Deep learning. MIT Press. Available from: http://www.deeplearningbook.org. |
| [12] | Hairer E and Wanner G (1991) Solving ordinary differential equations. Springer Series in computational mathematics, 14, Springer. |
| [13] |
Hornik K, Stinchcombe M, and White H (1989) Multilayer feedforward networks are universal approximators. Neural networks 2: 359–366. doi: 10.1016/0893-6080(89)90020-8
|
| [14] | Kingma DP and Ba JL (2015) Adam: a Method for Stochastic Optimization. International Conference on Learning Representations, 1–13. |
| [15] |
LeCun Y, Bengio Y and Hinton G (2015) Deep learning. Nature 521: 436–444. doi: 10.1038/nature14539
|
| [16] | LeVeque RJ (2007) Finite difference methods for ordinary and partial differential equations, steady state and time dependent problems, SIAM. |
| [17] |
Mishra S, Schwab C and Šukys J (2012) Multi-level Monte Carlo finite volume methods for nonlinear systems of conservation laws in multi-dimensions. J Comput Phys 231: 3365–3388. doi: 10.1016/j.jcp.2012.01.011
|
| [18] | Miyanawala TP and Jaiman RK (2017) An efficient deep learning technique for the Navier-Stokes equations: application to unsteady wake flow dynamics. Preprint, arXiv :1710.09099v2. |
| [19] | Poon H and Domingos P (2011) Sum-product Networks: A new deep architecture. International conference on computer vision (ICCV), 689–690. |
| [20] |
Raissi M and Karniadakis GE (2018) Hidden physics models: machine learning of nonlinear partial differential equations. J Comput Phys 357: 125–141. doi: 10.1016/j.jcp.2017.11.039
|
| [21] | Ray D and Hesthaven JS (2018) An artificial neural network as a troubled cell indicator. J Comput Phys to appear. |
| [22] | Ruder S (2017) An overview of gradient descent optimization algorithms. Preprint, arXiv.1609.04747v2. |
| [23] | Schwab C and Zech J (2017) Deep learning in high dimension. Technical Report 2017-57, Seminar for Applied Mathematics, ETH Zürich. |
| [24] |
Stuart AM (2010) Inverse problems: a Bayesian perspective. Acta Numerica 19: 451–559. doi: 10.1017/S0962492910000061
|
| [25] | Tadmor E (2003) Entropy stability theory for difference approximations of nonlinear conservation laws and related time-dependent problems. Acta Numerica, 451–512. |
| [26] | Tompson J, Schlachter K, Sprechmann P, et al. (2017) Accelarating Eulerian fluid simulation with convolutional networks. Preprint, arXiv:1607.03597v6. |
| [27] | Trefethen LN (2000) Spectral methods in MATLAB, SIAM. |
| [28] | Troltzsch F (2010) Optimal control of partial differential equations. AMS. |
| [29] | Quateroni A, Manzoni A and Negri F (2015) Reduced basis methods for partial differential equations: an introduction, Springer Verlag. |
| [30] |
Yarotsky D (2017) Error bounds for approximations with deep ReLU networks. Neural Networks 94: 103–114 doi: 10.1016/j.neunet.2017.07.002
|
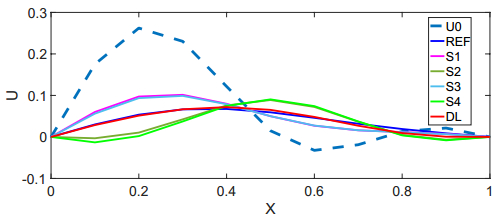
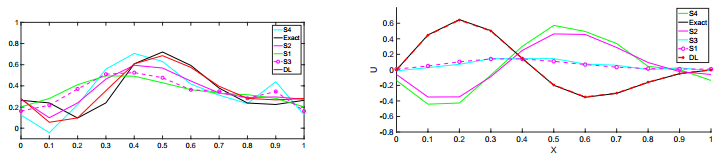
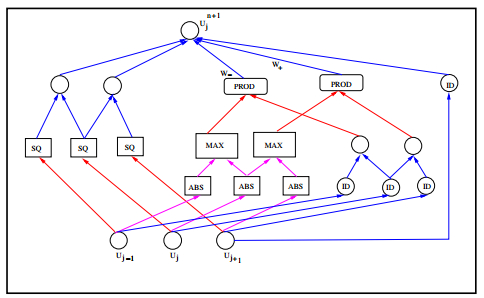
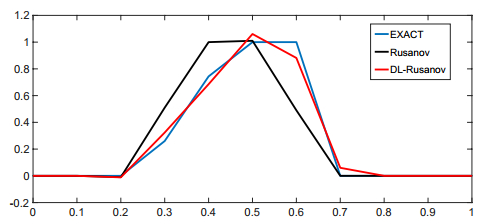

Figures(9) / Tables(8)

Siddhartha Mishra. A machine learning framework for data driven acceleration of computations of differential equations[J]. Mathematics in Engineering, 2019, 1(1): 118-146. doi: 10.3934/Mine.2018.1.118







 DownLoad:
DownLoad: