




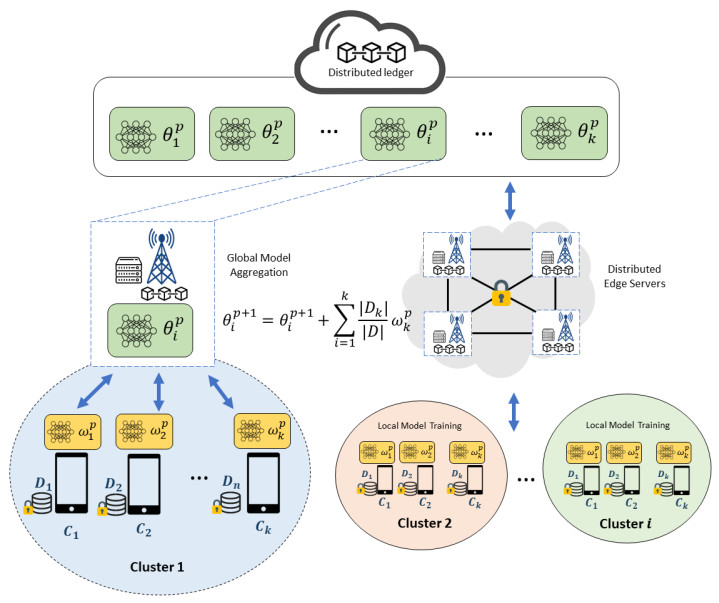
Figure 1.
Distributed edge cluster for personalized federated learning.
Citation: Dieter Armbruster, Christian Ringhofer, Andrea Thatcher. A kinetic model for an agent based market simulation[J]. Networks and Heterogeneous Media, 2015, 10(3): 527-542. doi: 10.3934/nhm.2015.10.527
| [1] | Kun Zhai, Qiang Ren, Junli Wang, Chungang Yan . Byzantine-robust federated learning via credibility assessment on non-IID data. Mathematical Biosciences and Engineering, 2022, 19(2): 1659-1676. doi: 10.3934/mbe.2022078 |
| [2] | M Kumaresan, M Senthil Kumar, Nehal Muthukumar . Analysis of mobility based COVID-19 epidemic model using Federated Multitask Learning. Mathematical Biosciences and Engineering, 2022, 19(10): 9983-10005. doi: 10.3934/mbe.2022466 |
| [3] | Yongjun Ren, Yan Leng, Yaping Cheng, Jin Wang . Secure data storage based on blockchain and coding in edge computing. Mathematical Biosciences and Engineering, 2019, 16(4): 1874-1892. doi: 10.3934/mbe.2019091 |
| [4] | Songfeng Liu, Jinyan Wang, Wenliang Zhang . Federated personalized random forest for human activity recognition. Mathematical Biosciences and Engineering, 2022, 19(1): 953-971. doi: 10.3934/mbe.2022044 |
| [5] | Dawei Li, Enzhun Zhang, Ming Lei, Chunxiao Song . Zero trust in edge computing environment: a blockchain based practical scheme. Mathematical Biosciences and Engineering, 2022, 19(4): 4196-4216. doi: 10.3934/mbe.2022194 |
| [6] | Sonza Singh, Anne Marie France, Yao-Hsuan Chen, Paul G. Farnham, Alexandra M. Oster, Chaitra Gopalappa . Progression and transmission of HIV (PATH 4.0)-A new agent-based evolving network simulation for modeling HIV transmission clusters. Mathematical Biosciences and Engineering, 2021, 18(3): 2150-2181. doi: 10.3934/mbe.2021109 |
| [7] | Yong Zhu, Zhipeng Jiang, Xiaohui Mo, Bo Zhang, Abdullah Al-Dhelaan, Fahad Al-Dhelaan . A study on the design methodology of TAC3 for edge computing. Mathematical Biosciences and Engineering, 2020, 17(5): 4406-4421. doi: 10.3934/mbe.2020243 |
| [8] | Hui Du, Depeng Lu, Zhihe Wang, Cuntao Ma, Xinxin Shi, Xiaoli Wang . Fast clustering algorithm based on MST of representative points. Mathematical Biosciences and Engineering, 2023, 20(9): 15830-15858. doi: 10.3934/mbe.2023705 |
| [9] | Xiangshuai Duan, Naiping Song, Fu Mo . An edge intelligence-enhanced quantitative assessment model for implicit working gain under mobile internet of things. Mathematical Biosciences and Engineering, 2023, 20(4): 7548-7564. doi: 10.3934/mbe.2023326 |
| [10] | A. N. Licciardi Jr., L. H. A. Monteiro . A complex network model for a society with socioeconomic classes. Mathematical Biosciences and Engineering, 2022, 19(7): 6731-6742. doi: 10.3934/mbe.2022317 |
The emergence of the Internet of Things (IoT) and the widespread utilization of mobile devices with advanced computing capabilities have instigated the need for large-scale data acquisition. These data can be harnessed to train advanced artificial intelligence (AI) models that can provide various smart services, benefiting society in diverse aspects. Nevertheless, traditional data acquisition models that rely on centralized machine learning models entail security and privacy challenges and reduce participation in data contribution. Moreover, with the recent establishment of data privacy preservation regulations, such as the General Data Protection Regulation [1] and the Health Insurance Portability and Accountability act [2], the need for privacy-preserving AI has been continuously growing. Hence, federated learning (FL), which allows clients to train their data collaboratively without exposing their private data to each other, has become more prevalent as a promising approach for tackling privacy-preserving AI issues. The introduction of FL was first used by Google for Gboard's next-word prediction [3]. Subsequently, empowered by the success of Gboard, the utilization of FL was promoted in a myriad of applications, such as healthcare [4], industrial IoT [5], vehicular networks [6], finance [7] and so forth.
Despite the benefits of general FL, the federated averaging (FedAvg) [8] approach, has suffered from poor convergence from the highly heterogeneous and non-independent nature of data distributions across clients [9]. A global model is trained using data from multiple clients; however, the data from each client are not necessarily identically distributed. This approach can lead to poor model performance for certain clients, whereby the negative impact can lead to the reluctance or refusal of clients to participate in the FL training process. Thus, the concept of personalized federated learning (PFL), as a variation of FL, was developed to alleviate the impact of non-identically and independently distributed (non-IID) data and statistical heterogeneity issues for the efficient creation of tailored models. PFL addresses these problems by personalizing the model for each client, considering the specific characteristics of their data. Moreover, it allows for better performance and increases clients' FL participation.
One approach to PFL is clustering-based PFL [10], which enables personalization using a multi-model approach with group-level client interactions. By mapping client associations, this approach facilitates the learning of personalized models by each client in conjunction with affiliated clients within similar clusters. However, the existing cluster-based PFL method still depends on the centralized strategy where the server orchestrates all processes and requires high communication, incurring computational costs. To address these shortcomings, this study introduces a blockchain-enabled distributed edge cluster for PFL (BPFL) that exploits the benefits of two cutting-edge technologies, blockchain and edge computing, which have the potential to revolutionize the way data are stored, processed, and shared. Specifically, in clustering-based PFL, the integration of blockchain and edge computing enables the creation of clusters based on real-time data, eliminating the need for a central authority to manage and process the data, thereby providing a robust and decentralized solution for data management and processing. In this study, blockchain is used to enrich client privacy and security by recording all transactions in immutable distributed ledger networks to enhance efficient client selection and clustering. Blockchain can be utilized to establish a decentralized network of devices, where each device maintains a copy of the same data, making the process more resilient to data loss or tampering. Likewise, to offer appropriate storage and computation of PFL, we employ an edge computing system, where computational processing is locally performed in the edge infrastructure of PFL to be nearer to clients as data providers. Thus, this approach allows for faster and more efficient data processing and provides proper computation capability by improving real-time services while reducing the latency and bandwidth requirements of PFL.
This paper is organized as follows. Section 2 provides background knowledge related to edge-AI, FL challenges, and blockchain. Section 3 explains the current works related to PFL. In Section 4, we present the proposed model which is based on a distributed edge cluster for PFL. In Section 5, numerical results of BPFL are discussed, and several related concerns are explored. Finally, Section 6 concludes the paper.
In 2014, the European Telecommunications Standards Institute introduced the concept of edge computing to optimize the user experience through low latency, high bandwidth, and real-time communication capabilities [11]. Edge computing leverages local infrastructure to enhance response speed and minimize transmission latency during the transaction process by strategically placing the servers in the edge network [12], thus emphasizing proximity to end users [13]. Whereas, edge-AI, also known as edge intelligence, offers the utilization of AI technologies at the perimeter of a network as opposed to a centralized cloud infrastructure. Specifically, data collection, processing, transmission, and utilization occur at the network edge. The approach enables model training across network nodes, allowing the preservation of privacy and confidentiality [14,15]. Moreover, this approach can enhance the responsiveness and efficiency of the system by decreasing the volume of data that needs to be transmitted over the network [16,17,18]. Edge-AI has been increasingly gaining popularity in recent years in both industry and academia. Leading companies such as Google, Microsoft, Intel, and IBM have initiated pilot projects to showcase the benefits of edge computing in the last mile of AI [19].
The traditional client-server architecture in machine learning involves training on a server, with clients providing the data. However, this approach raises privacy concerns. Clients serve only as providers of data, whereas the server also undertakes the task of data training and aggregation. Various concerns are associated with this classical machine learning strategy, in particular, regarding user privacy. To address this issue, Google introduced FedAvg, a novel communication-efficient optimization algorithm for FL. FedAvg, as outlined in [8], is an efficient method for the distribution-based training of models, allowing distributed mobile devices to collaborate in model training without centralizing the training data and keeping local data stored on mobile devices, thereby improving privacy by blocking access to local data. It also reduces the number of communication rounds, making it more efficient than conventional distributed methods.
In the FedAvg algorithm, the server, acting as a model provider, initially sends the global model to the clients. Each client, as a participant user, downloads the global model from the central server, generates a model update by training the current global model on local data, and subsequently uploads the trained model to the aggregator server. The central server, then acting as an aggregator, gathers and aggregates all model updates from the clients to produce a new global model for the next iteration. Thus, FedAvg significantly enhances client privacy by blocking attacks from straightforward access to the local training data, as cited in [20]. FedAvg is much more communication-efficient than conventional distributed stochastic gradient descent because of fewer communication rounds. Furthermore, FedAvg frequently leads to improved performance, as demonstrated in various learning-related issues such as predictive models in health, low latency vehicle-to-vehicle communication, vocabulary estimation, and next-word prediction, as cited in [3,21,22,23].
FL offers numerous benefits for various practical applications. However, the highly heterogeneous data distribution among clients also poses several challenges, leading to a lack of personalization and poor convergence. Specifically, the data distribution among clients is highly non-IID, which makes it challenging to train a single model with effective performance for all clients. The non-IID data also significantly affect the accuracy of FedAvg. Since the distribution of each local dataset differs significantly from the global distribution, the local objectives of each client are incompatible with the global optimum, which leads to a drift in local updates, causing each model to be updated towards its own local optimum, which may be far from the global optimum [24]. Especially if there are many significant local updates (i.e., an enormous number of local epochs), the averaged model might also be far from the global optimum [25,26]. Consequently, the convergence of the global model provides a substantially less accurate solution than that associated with the IID setting.
In 2008, Bitcoin, a digital currency system based on blockchain technology, was proposed by Nakamoto for financial transactions. Blockchain is a technology that enables participating nodes to share and validate transactions on a network, which are then imprinted with timestamps and stored in an unchangeable database using a specific consensus mechanism. Blockchain has three primary features: decentralized storage, a distributed ledger, and the ability to support distributed services through the use of smart contracts [27]. Because of these benefits, many researchers from various fields are currently exploring the development of blockchain technology. The advantages of blockchain include anonymity and privacy for users, the immutability of stored data, a decentralized approach that eliminates single points of failure, transparency of transactions, as well as trustful and distributed transactions that do not require a central authority [5]. The feature of immutability ensures that data cannot be deleted or modified from the network, whereas the decentralized approach allows for open participation, provides immunity from particular attacks, and eliminates single points of failure, resulting in consistent, reliable, and widely accessible data, timestamped for recorded transactions. In addition, every user has access to transparent transactions, thereby enabling every node to share and validate transactions in a distributed manner [28].
PFL learning emerged as a response to the problems caused by the non-IID data distribution and statistical heterogeneity of the current FL. The use of FedAvg-based methods for non-IID data result in a decrease in accuracy due to client drift. To overcome these issues, two strategies have been proposed in [29], i.e., the global model personalization strategy, which involves training a single global model, and personalized model learning strategies, which involve training PFL models individually. Most personalization methods for the global FL model typically involve two distinct processes [30]: creating a global model through collaboration or using private client information to personalize the global model [31]. Essentially, PFL uses FedAvg as the standard approach for general FL training settings, with the added step of personalizing the global model using local client data after training. The personalized model strategy for learning aims to achieve PFL by applying different learning algorithms and modifying the FL aggregation process through similarity and architecture-based approaches. Furthermore, PFL seeks to train personalized models for a group of clients by utilizing the non-IID nature of all clients' private data while maintaining their privacy. Thus, to improve the practicality of PFL, the work in [32] suggested that the following three goals be simultaneously addressed: achieving rapid model convergence in a reduced number of training rounds, improving personalized models that benefit a large number of clients, and creating more accurate global models that aid clients with limited private data for personalization.
Recently, research on PFL has been gaining popularity as it aims to address one of the main challenges of current FL. One of the earliest works on PFL was the manager, owner, consultant, helper, approver (MOCHA) framework which was proposed in 2017, as a multi-task learning approach [9]. MOCHA simultaneously learns client task settings and a similarity matrix, to address the issue of federated multi-task learning. The distributed multi-task issues addressed by MOCHA include fault tolerance, stragglers, and communication limitations. In addition, the authors of [10] proposed a context-based client clustering approach to facilitate multiple global models and handle changes in client populations over time. In this approach, FL models are trained for each homogeneous group of clients, whereby clients are divided into clusters based on the cosine similarity of the gradient updates from the clients. There are multiple methods for implementing the PFL framework, such as data augmentation [33], meta-learning [32], transfer learning [34], and fine-tuning [25]. It is worth noting that this study focuses on context-based client clustering with a multi-task approach.
In this section, we introduce the BPFL approach, which combines the benefits of edge computing and blockchain technology to enable PFL through distributed edge clusters. Unlike traditional methods that rely on a single global model, our approach utilizes a multi-model approach with group-level client associations to achieve personalization. Blockchain technology is employed to securely store these models in a distributed manner with smart contracts to improve efficient client selection and clustering through the evaluation of client relationships. The proposed model utilizes a consortium blockchain to ensure that the participating edge clusters are preselected based on their trustworthiness, thereby enhancing the security and reliability of the overall system. Consortium blockchain guarantees the authenticity of the transactions and mitigates the risk of eavesdropping, tampering, and compromising of the BPFL network edge servers by malicious clients. To verify the validity of the transaction, we employed the proof of training quality concept, where the accuracy of the local model is the primary verification parameter [35]. Moreover, edge computing servers were utilized to reduce communication and computation costs by providing local storage, communication, and computation capabilities, allowing the computational processing to be conducted closer to clients as data providers. As illustrated in Figure 1, the proposed model comprises the steps of system initialization, collaborative edge cluster establishment, personalized local training models, and personalized global model aggregation. The specific procedures are explained in further detail as follows.
The initial model parameters of the global model ($ \theta^{in} $) are stored in a distributed ledger blockchain (which can be integrated with off-chain storage, e.g., the InterPlanetary File System (IPFS)) as the initial learning model process. It is maintained by edge servers that are placed throughout clusters. Then, the number of $ K $ clients ($ C_k $) need to register to the BPFL system by sending asset statement (refers to [36]) validation with their pseudo-public key address $ Pub_C^{ps} $ through Eq (4.1).
|
$ Tx_Ck(Asset)=PubpsCk→{(PubCk_Asset=PubHash(Ck_Asset),βj_Ck=(Hash(j).PubHash(Ck_Asset))Hash(Ck_Asset)),"Asset_sum"},where,PubpsCk∈{Pub1Sec_C,Pub2Sec_C,...,PubkSec_C} $
|
(4.1) |
Equation (4.1) describes the process of recording a client's asset information in the system, which includes the client's public key related to the asset pseudonym $ Pub_{{C_k}\_Asset} $, as evidence that the client owns the asset $ \beta_{j}\_{C_k} $, and general asset information $ "Asset\_sum" $ (e.g., its format, topic, and data size). The public key and ownership proof are essential for verifying that the client owns the asset and keeping the asset information anonymous. These elements are created using a secure hash function $ Hash({C_k}\_{Asset}) $ to map the client's assets into unique public and private keys $ {Pub_k}^{Sec\_C} $ to maintain the client's anonymity. In short, only validated clients can download $ \theta^{in} $ and access the BPFL system.
In this step, BPFL can distinguish incongruent clients after converging to a stationary point [10] as well as generate a multi-model method ($ \theta_k $) that is maintained by distributed edge servers. Hence, according to the client's asset statement, the collaborative edge clusters ($ ECl_i $) are established based on the client's data distribution ($ D_k $) similarity, where their datasets are non-IID. In this sense, BPFL splits the clients into two clusters ($ ECl_1, ECl_2 $) in a manner that optimizes the minimization of the maximum similarity between clients belonging to different clusters (see Eq (4.2)). Additionally, the group-level client similarity ($ \delta $) can be counted using specific partition techniques, such as Euclidean distance, cosine similarity, and Gaussian mixture. Our model relies on the cosine similarity technique (see Eq (4.3)).
|
$ ECl1,ECl2←argminECL1∪ECL2(maxδECl1,ECl2) $
|
(4.2) |
|
$ δC1,C2:=δ(wp1,wp2):=(wp1,wp2)‖wp1‖‖wp2‖ $
|
(4.3) |
In the $ p- $th iteration, $ C_k $ in each $ ECl_i $ downloads global parameter $ \theta_i^p $ from the blockchain and performs local training using their datasets $ D_k $ to obtain a personalized model ($ w_k^p $) owned by client $ C_k $ by using the following formula [37]:
|
$ wpk=argminw∈RdFi(w)+μ2αp‖w−θpk‖ $
|
(4.4) |
where $ F_i $ is a loss function associated with the $ i- $th data point on $ C_k $; $ w\in \mathbb{R}^d $ encodes the parameters of local model $ w $, $ \mu $ represents the regularization parameter, and $ \alpha_p $ is the step size of gradient descent in iteration $ p $.
| Algorithm 1 A summary of the BPFL algorithm. $ D^i $ is the local datasets; $ K $ number of clients $ C_k $; number of iteration, $ p $; $ E $ is the number of local epochs; and $ \eta $ is learning rate. |
| 1: procedure EdgeServerUpdate: |
| 2: $ ECL_i $ initialize $ \theta^{in} $ *the initial models are stored in the blockchain |
| 3: for each round $ p $ = 1, 2, ..., P do |
| 4: $ C_K \leftarrow max (Tx\_{C_k}_{(Asset)}) $ |
| 5: $ ECl_1, ECl_2 \leftarrow \arg \min_{ECL_1 \cup ECL_2} (\max \delta_{ECl_1, ECl_2}) $ *similarity-based clients clustering |
| 6: for each client $ i \in C_K $ in parallel do |
| 7: $ w_k^p \leftarrow $ UserUpdate($ i, w^p $) *$ \forall $ updates the personalized model |
| 8: $ \theta_i^{(p+1)} \leftarrow \theta_i^p + \sum_{i=1}^k \frac{|D_k|}{|D|} w_k^p $ *aggregating the gathered models |
| 9: end for |
| 10: end for |
| 11: end procedure |
| 12: procedure ClientUpdate: ($ i, w^p $) |
| 13: //Executes on client $ i $ |
| 14: $ w_k^p \leftarrow w^p $ |
| 15: for each local epoch $ j $ from 1 to $ E $ do |
| 16: for each batch $ b=\{x, y\} $ of $ D^i $ do |
| 17: $ w_k^p \leftarrow \arg \min_{w \in \mathbb{R} ^d}F_i\left (w \right) + \frac{\mu}{2\alpha_p} \| w-\theta_k^p \| $; *$ \forall $ local training of personalized model |
| 18: end for |
| 19: end for |
| 20: return $ w_k^p $ for aggregation |
| 21: end procedure |
| 22: procedure Incentive_Mechanism($ Incv\_C_k $) *incentivized using Ethereum platform |
| 23: $ ECL_i $ collects the list of participating clients $ C_{1}, C_{2}, ..., C_{k} $ |
| 24: for $ C_1, C_2, ..., C_k; ECL_i $ do |
| 25: $ ECL_i \leftarrow $ ConfirmTransaction $ H(w_1^p, w_2^p, ..., w_k^P) $ *$ ECL_i $ has the list of clients |
| 26: $ Incv\_C_k $ are given to $ C_{1}, C_{2}, ..., C_{k} $ *the rewards are distributed to the clients |
| 27: end for |
| 28: end procedure |
 DownLoad:
CSV
DownLoad:
CSV
After the clients collaboratively upload their $ w_k^p $ to the distributed edge cluster, the cluster global model aggregation is executed as follows:
|
$ θ(p+1)i=θpi+k∑i=1|Dk||D|wpk $
|
(4.5) |
where $ \theta_i^{(p+1)} $ is a new personalized global model obtained for the next iteration $ (p+1) $. In this step, all participants in the BPFL system can download $ \theta_i^{(p+1)} $ through the distributed ledger blockchain. Consequently, iterations continue until the model achieves precise accuracy or reaches the maximum number of iterations. Finally, clients are incentivized through the implementation of a smart contract blockchain, whereby they are rewarded for fulfilling the transaction requirements of the BPFL platform. The incentive, represented by $ Incv\_C_k $, is calculated based on the following formula [38]:
|
$ Incv_Ck=∑icontribCk⋅θ(p+1)i $
|
(4.6) |
where $ contrib_{C_k} $ is the contribution of client $ C_k $ to $ \theta_i^{(p+1)} $. Later, $ Incv\_C_k $ is automatically distributed to participating clients once $ \theta_i^{(p+1)} $ has been generated, thus providing a decentralized and responsive system. A summary of the BPFL framework can be found in Algorithm 1.
This section describes the implementation of the proposed model which forms a distributed edge clustering framework to realize PFL by leveraging the merits of blockchain and EC. The modified National Institute of Standards and Technology (MNIST) [39] datasets were used with 10.000 images for the test set and 60.000 images for the training set. Our preliminary research compared the performance of IID and non-IID data distributions among clients through two different models of MNIST, i.e., a basic two-layer multilayer perceptron (MLP; also known as MNIST 2NN) and a convolutional neural network (CNN) comprising two 5 $ \times $ 5 convolution layers. Figure 2 shows the loss from 50 epochs of training with a learning rate of 0.01 for both MLP and CNN models. The loss in the non-IID setting is higher than that of IID because of the unbalanced and highly heterogeneous nature of client data. The impact of non-IID data is further reflected in poor convergence and a decline in performance accuracy, as depicted in Figure 3. The accuracy is observed to be at its lowest at epoch 5, reaching 61.48%, as opposed to an accuracy of 95.03% in the IID setting.


To create a BPFL framework that leverages blockchain technology, we adopted a consortium setting [40] that harnesses the power of blockchain to perform decentralized PFL transactions, assess participant contributions to the global model with transparency, and establish a decentralized incentive system. The distribution of edge cluster contributions towards generating the global PFL model based on the Ethereum platform is depicted in Figure 4. We designed three distinct collaborative $ ECL_i $ edge clusters, $ ECL_1 $, $ ECL_2 $, and $ ECL_3 $, which work collaboratively to train FL models using their personalized models and local datasets. Upon creating a new personalized global model, the incentive is distributed to the edge clusters based on the recorded contribution of each cluster in the blockchain's distributed ledger. Figure 5 shows that, on average, BPFL achieves better performance accuracy than existing works. In summary, BPFL seeks to motivate clients possessing heterogeneous data to actively participate in preserving PFL and improve system performance.


The study of PFL is the latest trend addressing the issue of statistical heterogeneity of non-IID data distributions, which is one of the primary challenges of the existing FL approach. Even though the PFL approach is advantageous compared to the general FL framework of FedAvg, there are some significant challenges, especially regarding the data privacy risk of clients during the model training process. Therefore, to enhance security and privacy in PFL, we introduced BPFL, which exploits the concept of distributed edge clusters to leverage the merits of edge computing and blockchain technology. Table 1 provides a theoretical summary of the advantages of BPFL compared to current PFL clustering techniques.
| Key parameters | Smith et al. [9] | Sattler et al. [10] | This work |
| Computation and communication cost | High | High | Low |
| Works on non-convex setting | No | Yes | Yes |
| Multiple global model setting | Not investigated | Not investigated | Yes |
| Distributed edge cluster | Not applied | Not applied | Yes |
| Privacy guarantees | Not investigated | Yes | Yes |
| Asset statement | Not applied | Not applied | Yes |
| Incentive mechanism | Not applied | Not applied | Applied |
DownLoad:
CSV
Nevertheless, to strengthen and achieve a robust PFL technique, further work is required to investigate the potential attacks and defenses originating from the more complex protocols and structures of PFL. To protect the client's sensitive data from various threats, several privacy techniques might be leveraged, such as differential privacy, homomorphic encryption, secure multiparty computation, and a trusted execution environment. In addition, the development of a reliable incentive mechanism can be studied to maintain fairness and motivate client contributions. The scalability of blockchain is another aspect that requires attention. The main issue with a fully distributed ledger network is that every node must agree on the complete state of the ledger, which leads to challenges such as limited scalability and longer transaction delays as the network expands. However, representative datasets are essential for developing the PFL field. Datasets with more modalities (sensor signals, video, and audio) and involving a more comprehensive assortment of machine learning tasks from practical applications are required to further PFL research. Additionally, performance benchmarking is another critical aspect for the long-term expansion of the PFL research domain.
This study introduced a blockchain-enabled distributed edge cluster approach for PFL, exploiting the benefits of blockchain and edge computing. Blockchain protects client privacy and security by recording all transactions in immutable distributed ledger networks, thereby enhancing efficient client selection and clustering. Similarly, an edge computing system offers appropriate storage and computation, whereby computational processing is locally performed in the edge infrastructure to be nearer to clients. Thus, this system provides proper computation capability and improves real-time services and low-latency communication of PFL. As challenges for future study directions in the PFL field, privacy-preserving, trustworthy PFL, as well as representative datasets and benchmarks are suggested.
This research was supported by the MSIT (Ministry of Science and ICT), Republic of Korea, under the ITRC (Information Technology Research Center) support program (IITP-2022-2020-0-01797) supervised by the IITP (Institute for Information & Communications Technology Planning & Evaluation) and partially supported by the Basic Science Research Program through the National Research Foundation of Korea (NRF) funded by the Ministry of Education (No. 2021R1I1A3046590).
The authors declare there is no conflict of interest.
| [1] |
T. Adriaansen, D. Armbruster, K. G. Kempf and H. Li, An agent model for the high-end gamers market, Advances in Complex Systems, 16 (2013), 1350028, 33pp. doi: 10.1142/S0219525913500288

|
| [2] |
D. Armbruster, P. Degond and C. Ringhofer, A model for the dynamics of large queuing networks and supply chains, SIAM J. Appl. Math, 66 (2006), 896-920. doi: 10.1137/040604625
|
| [3] |
F. M. Bass, A new product growth model for consumer durables, Mathematical Models in Marketing, Lecture Notes in Economics and Mathematical Systems, 132 (1976), 351-253. doi: 10.1007/978-3-642-51565-1_107
|
| [4] |
L. Boltzmann, The second law of thermodynamics, Theoretical Physics and Philosophical Problems, Vienna Circle Collection, 5 (1974), 13-32. doi: 10.1007/978-94-010-2091-6_2
|
| [5] |
C. Cercignani, R. Illner and M. Pulvirenti, The Mathematical Theory Of Dilute Gases, Springer-Verlag, 1994. doi: 10.1007/978-1-4419-8524-8
|
| [6] |
P. Degond, J.-G. Liu and C. Ringhofer, Large-scale dynamics of mean-field games driven by local Nash equilibria, J. Nonlinear Sci., 24 (2014), 93-115. doi: 10.1007/s00332-013-9185-2
|
| [7] |
P. Degond, J.-G. Liu and C. Ringhofer, Evolution of the distribution of wealth in an economic environment driven by local Nash equilibria, J. Stat. Phys., 154 (2014), 751-780. doi: 10.1007/s10955-013-0888-4
|
| [8] | D. Helbing, A mathematical model for attitude formation by pair interactions, Behavioral sciences, 37 (1992), 190-214. |
| [9] |
R. J. LeVeque, Finite Volume Methods For Hyperbolic Problems, Cambridge University Press, 2002. doi: 10.1017/CBO9780511791253
|
| [10] |
H. Li, D. Armbruster and K. G. Kempf, A population-growth model for multiple generations of technology products, Manufacturing & Service Operations Management, 15 (2013), 343-360. doi: 10.1287/msom.2013.0430
|
| [11] | L. Pareschi and G. Toscani, Interacting Multiagent Systems: Kinetic Equations And Monte Carlo Methods, Oxford University Press, 2014. |
| [12] |
G. Toscani, C. Brugna and S. Demichelis, Kinetic models for the trading of goods, J. Stat. Phys., 151 (2013), 549-566. doi: 10.1007/s10955-012-0653-0
|
| [13] |
A. Tversky and D. Kahneman, Loss aversion in riskless choice: A reference-dependent model, The Quarterly Journal of Economics, 106 (1991), 1039-1061. doi: 10.2307/2937956
|
| 1. | Fahad Sabah, Yuwen Chen, Zhen Yang, Muhammad Azam, Nadeem Ahmad, Raheem Sarwar, Model optimization techniques in personalized federated learning: A survey, 2024, 243, 09574174, 122874, 10.1016/j.eswa.2023.122874 | |
| 2. | Muhammad Firdaus, Kyung-Hyune Rhee, 2023, Towards Trustworthy Collaborative Healthcare Data Sharing, 979-8-3503-3748-8, 4059, 10.1109/BIBM58861.2023.10385319 | |
| 3. | Meriem Arbaoui, Mohamed-el-Amine Brahmia, Abdellatif Rahmoun, Mourad Zghal, Federated Learning Survey: A Multi-Level Taxonomy of Aggregation Techniques, Experimental Insights, and Future Frontiers, 2024, 2157-6904, 10.1145/3678182 | |
| 4. | Fahad Sabah, Yuwen Chen, Zhen Yang, Abdul Raheem, Muhammad Azam, Nadeem Ahmad, Raheem Sarwar, FairDPFL-SCS: Fair Dynamic Personalized Federated Learning with strategic client selection for improved accuracy and fairness, 2025, 115, 15662535, 102756, 10.1016/j.inffus.2024.102756 | |
| 5. | Jong Hyuk Park, Editorial: Artificial Intelligence-based Security Applications and Services for Smart Cities, 2024, 21, 1551-0018, 7012, 10.3934/mbe.2024307 | |
| 6. | Saprunov Vadim, Muhammad Firdaus, Kyung-Hyune Rhee, Privacy-Preserving Decentralized Biometric Identity Verification in Car-Sharing System, 2024, 11, 2383-7632, 17, 10.33851/JMIS.2024.11.1.17 | |
| 7. | Qian Zhuohao, Muhammad Firdaus, Siwan Noh, Kyung-Hyune Rhee, A Blockchain-Based Auditable Semi-Asynchronous Federated Learning for Heterogeneous Clients, 2023, 11, 2169-3536, 133394, 10.1109/ACCESS.2023.3335603 | |
| 8. | Fahad Sabah, Yuwen Chen, Zhen Yang, Abdul Raheem, Muhammad Azam, Nadeem Ahmad, Raheem Sarwar, Communication optimization techniques in Personalized Federated Learning: Applications, challenges and future directions, 2025, 117, 15662535, 102834, 10.1016/j.inffus.2024.102834 |
Dieter Armbruster, Christian Ringhofer, Andrea Thatcher. A kinetic model for an agent based market simulation[J]. Networks and Heterogeneous Media, 2015, 10(3): 527-542. doi: 10.3934/nhm.2015.10.527

| Algorithm 1 A summary of the BPFL algorithm. $ D^i $ is the local datasets; $ K $ number of clients $ C_k $; number of iteration, $ p $; $ E $ is the number of local epochs; and $ \eta $ is learning rate. |
| 1: procedure EdgeServerUpdate: |
| 2: $ ECL_i $ initialize $ \theta^{in} $ *the initial models are stored in the blockchain |
| 3: for each round $ p $ = 1, 2, ..., P do |
| 4: $ C_K \leftarrow max (Tx\_{C_k}_{(Asset)}) $ |
| 5: $ ECl_1, ECl_2 \leftarrow \arg \min_{ECL_1 \cup ECL_2} (\max \delta_{ECl_1, ECl_2}) $ *similarity-based clients clustering |
| 6: for each client $ i \in C_K $ in parallel do |
| 7: $ w_k^p \leftarrow $ UserUpdate($ i, w^p $) *$ \forall $ updates the personalized model |
| 8: $ \theta_i^{(p+1)} \leftarrow \theta_i^p + \sum_{i=1}^k \frac{|D_k|}{|D|} w_k^p $ *aggregating the gathered models |
| 9: end for |
| 10: end for |
| 11: end procedure |
| 12: procedure ClientUpdate: ($ i, w^p $) |
| 13: //Executes on client $ i $ |
| 14: $ w_k^p \leftarrow w^p $ |
| 15: for each local epoch $ j $ from 1 to $ E $ do |
| 16: for each batch $ b=\{x, y\} $ of $ D^i $ do |
| 17: $ w_k^p \leftarrow \arg \min_{w \in \mathbb{R} ^d}F_i\left (w \right) + \frac{\mu}{2\alpha_p} \| w-\theta_k^p \| $; *$ \forall $ local training of personalized model |
| 18: end for |
| 19: end for |
| 20: return $ w_k^p $ for aggregation |
| 21: end procedure |
| 22: procedure Incentive_Mechanism($ Incv\_C_k $) *incentivized using Ethereum platform |
| 23: $ ECL_i $ collects the list of participating clients $ C_{1}, C_{2}, ..., C_{k} $ |
| 24: for $ C_1, C_2, ..., C_k; ECL_i $ do |
| 25: $ ECL_i \leftarrow $ ConfirmTransaction $ H(w_1^p, w_2^p, ..., w_k^P) $ *$ ECL_i $ has the list of clients |
| 26: $ Incv\_C_k $ are given to $ C_{1}, C_{2}, ..., C_{k} $ *the rewards are distributed to the clients |
| 27: end for |
| 28: end procedure |
DownLoad:
CSV
| Key parameters | Smith et al. [9] | Sattler et al. [10] | This work |
| Computation and communication cost | High | High | Low |
| Works on non-convex setting | No | Yes | Yes |
| Multiple global model setting | Not investigated | Not investigated | Yes |
| Distributed edge cluster | Not applied | Not applied | Yes |
| Privacy guarantees | Not investigated | Yes | Yes |
| Asset statement | Not applied | Not applied | Yes |
| Incentive mechanism | Not applied | Not applied | Applied |
DownLoad:
CSV
| Algorithm 1 A summary of the BPFL algorithm. $ D^i $ is the local datasets; $ K $ number of clients $ C_k $; number of iteration, $ p $; $ E $ is the number of local epochs; and $ \eta $ is learning rate. |
| 1: procedure EdgeServerUpdate: |
| 2: $ ECL_i $ initialize $ \theta^{in} $ *the initial models are stored in the blockchain |
| 3: for each round $ p $ = 1, 2, ..., P do |
| 4: $ C_K \leftarrow max (Tx\_{C_k}_{(Asset)}) $ |
| 5: $ ECl_1, ECl_2 \leftarrow \arg \min_{ECL_1 \cup ECL_2} (\max \delta_{ECl_1, ECl_2}) $ *similarity-based clients clustering |
| 6: for each client $ i \in C_K $ in parallel do |
| 7: $ w_k^p \leftarrow $ UserUpdate($ i, w^p $) *$ \forall $ updates the personalized model |
| 8: $ \theta_i^{(p+1)} \leftarrow \theta_i^p + \sum_{i=1}^k \frac{|D_k|}{|D|} w_k^p $ *aggregating the gathered models |
| 9: end for |
| 10: end for |
| 11: end procedure |
| 12: procedure ClientUpdate: ($ i, w^p $) |
| 13: //Executes on client $ i $ |
| 14: $ w_k^p \leftarrow w^p $ |
| 15: for each local epoch $ j $ from 1 to $ E $ do |
| 16: for each batch $ b=\{x, y\} $ of $ D^i $ do |
| 17: $ w_k^p \leftarrow \arg \min_{w \in \mathbb{R} ^d}F_i\left (w \right) + \frac{\mu}{2\alpha_p} \| w-\theta_k^p \| $; *$ \forall $ local training of personalized model |
| 18: end for |
| 19: end for |
| 20: return $ w_k^p $ for aggregation |
| 21: end procedure |
| 22: procedure Incentive_Mechanism($ Incv\_C_k $) *incentivized using Ethereum platform |
| 23: $ ECL_i $ collects the list of participating clients $ C_{1}, C_{2}, ..., C_{k} $ |
| 24: for $ C_1, C_2, ..., C_k; ECL_i $ do |
| 25: $ ECL_i \leftarrow $ ConfirmTransaction $ H(w_1^p, w_2^p, ..., w_k^P) $ *$ ECL_i $ has the list of clients |
| 26: $ Incv\_C_k $ are given to $ C_{1}, C_{2}, ..., C_{k} $ *the rewards are distributed to the clients |
| 27: end for |
| 28: end procedure |
| Key parameters | Smith et al. [9] | Sattler et al. [10] | This work |
| Computation and communication cost | High | High | Low |
| Works on non-convex setting | No | Yes | Yes |
| Multiple global model setting | Not investigated | Not investigated | Yes |
| Distributed edge cluster | Not applied | Not applied | Yes |
| Privacy guarantees | Not investigated | Yes | Yes |
| Asset statement | Not applied | Not applied | Yes |
| Incentive mechanism | Not applied | Not applied | Applied |
