Citation: Fohona S. Coulibaly, Danielle N. Thomas, Bi-Botti C. Youan. Anti-HIV lectins and current delivery strategies[J]. AIMS Molecular Science, 2018, 5(1): 96-116. doi: 10.3934/molsci.2018.1.96

| [1] | Hodder SL, Justman J, Haley DF, et al. (2010) Challenges of a hidden epidemic: HIV prevention among women in the United States. J Acquir Immune Defic Syndr 55 Suppl 2: S69–S73. |
| [2] | Shattock RJ, Rosenberg Z (2012) Microbicides: Topical prevention against HIV. Cold Spring Harb Perspect Med 2: a007385. |
| [3] | UNAIDS. Available from: http://www.unaids.org/en/resources/documents/2016/Global-AIDS-update-2016. |
| [4] |
Swanson MD, Winter HC, Goldstein IJ, et al. (2010) A lectin isolated from bananas is a potent inhibitor of HIV replication. J Biol Chem 285: 8646–8655. doi: 10.1074/jbc.M109.034926

|
| [5] | Murphy EM, Greene ME, Mihailovic A, et al. (2006) Was the "ABC" approach (abstinence, being faithful, using condoms) responsible for Uganda's decline in HIV? PLoS Med 3: 1–5. |
| [6] | Cohen SA. Available from: https://www.guttmacher.org/gpr/2004/11/promoting-b-abc-its-value-and-limitations-fostering-reproductive-health. |
| [7] | Sovran S (2013) Understanding culture and HIV/AIDS in sub-Saharan Africa. Sahara J 10: 32–41. |
| [8] |
Reniers G, Watkins S (2010) Polygyny and the spread of HIV in sub-Saharan Africa: A case of benign concurrency. Aids 24: 299–307. doi: 10.1097/QAD.0b013e328333af03
|
| [9] |
Helweglarsen M, Collins BE (1994) The UCLA Multidimensional Condom Attitudes Scale: Documenting the complex determinants of condom use in college students. Health Psychol 13: 224–237. doi: 10.1037/0278-6133.13.3.224
|
| [10] | UNAIDS. Available from: http://www.unaids.org/globalreport/Global_report.htm. |
| [11] |
Qian K, Morris-Natschke SL, Lee KH (2009) HIV entry inhibitors and their potential in HIV therapy. Med Res Rev 29: 369–393. doi: 10.1002/med.20138
|
| [12] | Fohona S, Coulibaly BBC (2017) Current status of lectin-based cancer diagnosis and therapy. AIMS Mol Sci 4: 1–27. |
| [13] | Hansen TK, Gall MA, Tarnow L, et al. (2007) Mannose-binding lectin and mortality in type 2 diabetes. Arch Intern Med 166: 2007–2013. |
| [14] | Guan LZ, Tong Q, Xu J (2015) Elevated serum levels of mannose-binding lectin and diabetic nephropathy in type 2 diabetes. PLoS One 10: 1–10. |
| [15] | Losin IE, Shakhnovich RM, Zykov KA, et al. (2014) Cardiovascular diseases and mannose-binding lectin. Kardiologiia 54: 64–70. |
| [16] |
Kelsall A, Fitzgerald AJ, Howard CV, et al. (2002) Dietary lectins can stimulate pancreatic growth in the rat. Int J Exp Pathol 83: 203–208. doi: 10.1046/j.1365-2613.2002.00230.x
|
| [17] | Hoyem PH, Bruun JM, Pedersen SB, et al. (2012) The effect of weight loss on serum mannose-binding lectin levels. Clin Dev Immunol 2012: 1–5. |
| [18] |
Akkouh O, Ng TB, Singh SS, et al. (2015) Lectins with anti-HIV activity: A review. Molecules 20: 648–668. doi: 10.3390/molecules20010648
|
| [19] |
Checkley MA, Luttge BG, Freed EO (2011) HIV-1 envelope glycoprotein biosynthesis, trafficking, and incorporation. J Mol Biol 410: 582–608. doi: 10.1016/j.jmb.2011.04.042
|
| [20] |
Balzarini J, Van LK, Hatse S, et al. (2004) Profile of resistance of human immunodeficiency virus to mannose-specific plant lectins. J Virol 78: 10617–10627. doi: 10.1128/JVI.78.19.10617-10627.2004
|
| [21] |
Huskens D, Van LK, Vermeire K, et al. (2007) Resistance of HIV-1 to the broadly HIV-1-neutralizing, anti-carbohydrate antibody 2G12. Virology 360: 294–304. doi: 10.1016/j.virol.2006.10.027
|
| [22] |
Blumenthal R, Durell S, Viard M (2012) HIV entry and envelope glycoprotein-mediated fusion. J Biol Chem 287: 40841–40849. doi: 10.1074/jbc.R112.406272
|
| [23] | Wilen CB, Tilton JC, Doms RW (2012) HIV: Cell binding and entry. Cold Spring Harb Perspect Med 2: 1–13 |
| [24] |
Ratner L, Haseltine W, Patarca R, et al. (1985) Complete nucleotide sequence of the AIDS virus, HTLV-III. Nature 313: 277–284. doi: 10.1038/313277a0
|
| [25] |
Allan JS, Coligan JE, Barin F, et al. (1985) Major glycoprotein antigens that induce antibodies in AIDS patients are encoded by HTLV-III. Science 228: 1091–1094. doi: 10.1126/science.2986290
|
| [26] |
Montagnier L, Clavel F, Krust B, et al. (1985) Identification and antigenicity of the major envelope glycoprotein of lymphadenopathy-associated virus. Virology 144: 283–289. doi: 10.1016/0042-6822(85)90326-5
|
| [27] |
Wainhobson S, Sonigo P, Danos O, Cole S, et al. (1985) Nucleotide sequence of the AIDS virus, LAV. Cell 40: 9–17. doi: 10.1016/0092-8674(85)90303-4
|
| [28] |
Mizuochi T, Spellman MW, Larkin M, et al. (1988) Carbohydrate structures of the human-immunodeficiency-virus (HIV) recombinant envelope glycoprotein gp120 produced in Chinese-hamster ovary cells. Biochem J 254: 599–603. doi: 10.1042/bj2540599
|
| [29] | Mizuochi T, Spellman MW, Larkin M, et al. (1988) Structural characterization by chromatographic profiling of the oligosaccharides of human immunodeficiency virus (HIV) recombinant envelope glycoprotein gp120 produced in Chinese hamster ovary cells. Biomed Chromatogr 2: 260–270. |
| [30] | Mizuochi T, Matthews TJ, Kato M, et al. (1990) Diversity of oligosaccharide structures on the envelope glycoprotein gp120 of human immunodeficiency virus 1 from the lymphoblastoid cell line H9. Presence of complex-type oligosaccharides with bisecting N-acetylglucosamine residues. J Biol Chem 265: 8519–8524. |
| [31] | Geyer H, Holschbach C, Hunsmann G, et al. (1988) Carbohydrates of human immunodeficiency virus. Structures of oligosaccharides linked to the envelope glycoprotein 120. J Biol Chem 263: 11760–11767. |
| [32] |
Go EP, Hewawasam G, Liao HX, et al. (2011) Characterization of glycosylation profiles of HIV-1 transmitted/founder envelopes by mass spectrometry. J Virol 85: 8270–8284. doi: 10.1128/JVI.05053-11
|
| [33] | Bonomelli C, Doores KJ, Dunlop DC, et al. (2011) The glycan shield of HIV is predominantly oligomannose independently of production system or viral clade. PLoS One 6: 1–7. |
| [34] |
Go EP, Herschhorn A, Gu C, et al. (2015) Comparative Analysis of the Glycosylation Profiles of Membrane-Anchored HIV-1 Envelope Glycoprotein Trimers and Soluble gp140. J Virol 89: 8245–8257. doi: 10.1128/JVI.00628-15
|
| [35] |
Raska M, Takahashi K, Czernekova L, et al. (2010) Glycosylation patterns of HIV-1 gp120 depend on the type of expressing cells and affect antibody recognition. J Biol Chem 285: 20860–20869. doi: 10.1074/jbc.M109.085472
|
| [36] |
Zhu X, Borchers C, Bienstock RJ, et al. (2000) Mass spectrometric characterization of the glycosylation pattern of HIV-gp120 expressed in CHO cells. Biochemistry 39: 11194–11204. doi: 10.1021/bi000432m
|
| [37] |
Doores KJ, Bonomelli C, Harvey DJ, et al. (2010) Envelope glycans of immunodeficiency virions are almost entirely oligomannose antigens. Proc Natl Acad Sci U S A 107: 13800–13805. doi: 10.1073/pnas.1006498107
|
| [38] | Behrens AJ, Harvey DJ, Milne E, et al. (2017) Molecular Architecture of the Cleavage-Dependent Mannose Patch on a Soluble HIV-1 Envelope Glycoprotein Trimer. J Virol 91: 1–16. |
| [39] | Sok D, Doores KJ, Briney B, et al. (2014) Promiscuous glycan site recognition by antibodies to the high-mannose patch of gp120 broadens neutralization of HIV. Sci Transl Med 6: 1–15. |
| [40] | Pritchard LK, Spencer DI, Royle L, et al. (2015) Glycan clustering stabilizes the mannose patch of HIV-1 and preserves vulnerability to broadly neutralizing antibodies. Nat Commun 6: 1–11. |
| [41] |
Coss KP, Vasiljevic S, Pritchard LK, et al. (2016) HIV-1 Glycan Density Drives the Persistence of the Mannose Patch within an Infected Individual. J Virol 90: 11132–11144. doi: 10.1128/JVI.01542-16
|
| [42] |
Raska M, Novak J (2010) Involvement of envelope-glycoprotein glycans in HIV-1 biology and infection. Arch Immunol Ther Exp 58: 191–208. doi: 10.1007/s00005-010-0072-3
|
| [43] |
Wang SK, Liang PH, Astronomo RD, et al. (2008) Targeting the carbohydrates on HIV-1: Interaction of oligomannose dendrons with human monoclonal antibody 2G12 and DC-SIGN. Proc Natl Acad Sci U S A 105: 3690–3695. doi: 10.1073/pnas.0712326105
|
| [44] |
Balzarini J (2005) Targeting the glycans of gp120: A novel approach aimed at the Achilles heel of HIV. Lancet Infect Dis 5: 726–731. doi: 10.1016/S1473-3099(05)70271-1
|
| [45] |
Koch M, Pancera M, Kwong PD, et al. (2003) Structure-based, targeted deglycosylation of HIV-1 gp120 and effects on neutralization sensitivity and antibody recognition. Virology 313: 387–400. doi: 10.1016/S0042-6822(03)00294-0
|
| [46] | Rathore U, Saha P, Kesavardhana S, et al. (2017) Glycosylation of the core of the HIV-1 envelope subunit protein gp120 is not required for native trimer formation or viral infectivity. J Biol Chem 24: 10197–10219. |
| [47] |
Sanders RW, Anken EV, Nabatov AA, et al. (2008) The carbohydrate at asparagine 386 on HIV-1 gp120 is not essential for protein folding and function but is involved in immune evasion. Retrovirology 5: 1–15. doi: 10.1186/1742-4690-5-1
|
| [48] |
Montefiori DC, Jr RW, Mitchell WM (1988) Role of protein N-glycosylation in pathogenesis of human immunodeficiency virus type 1. Proc Natl Acad Sci U S A 85: 9248–9252. doi: 10.1073/pnas.85.23.9248
|
| [49] |
Francois KO, Balzarini J (2011) The highly conserved glycan at asparagine 260 of HIV-1 gp120 is indispensable for viral entry. J Biol Chem 286: 42900–42910. doi: 10.1074/jbc.M111.274456
|
| [50] | Mathys L, Francois KO, Quandte M, et al. (2014) Deletion of the highly conserved N-glycan at Asn260 of HIV-1 gp120 affects folding and lysosomal degradation of gp120, and results in loss of viral infectivity. PLoS One 9: 1–11. |
| [51] |
Huang X, Jin W, Hu K, et al. (2012) Highly conserved HIV-1 gp120 glycans proximal to CD4-binding region affect viral infectivity and neutralizing antibody induction. Virology 423: 97–106. doi: 10.1016/j.virol.2011.11.023
|
| [52] |
Binley JM, Ban YE, Crooks ET, et al. (2010) Role of complex carbohydrates in human immunodeficiency virus type 1 infection and resistance to antibody neutralization. J Virol 84: 5637–5655. doi: 10.1128/JVI.00105-10
|
| [53] | Li Y, Luo L, Rasool N, et al. (1993) Glycosylation is necessary for the correct folding of human immunodeficiency virus gp120 in CD4 binding. J Virol 67: 584–588. |
| [54] |
Li H, Jr CP, Tuen M, Visciano ML, et al. (2008) Identification of an N-linked glycosylation in the C4 region of HIV-1 envelope gp120 that is critical for recognition of neighboring CD4 T cell epitopes. J Immunol 180: 4011–4021. doi: 10.4049/jimmunol.180.6.4011
|
| [55] |
Behrens AJ, Vasiljevic S, Pritchard LK, et al. (2016) Composition and Antigenic Effects of Individual Glycan Sites of a Trimeric HIV-1 Envelope Glycoprotein. Cell Rep 14: 2695–2706. doi: 10.1016/j.celrep.2016.02.058
|
| [56] |
Pritchard LK, Vasiljevic S, Ozorowski G, et al. (2015) Structural Constraints Determine the Glycosylation of HIV-1 Envelope Trimers. Cell Rep 11: 1604–1613. doi: 10.1016/j.celrep.2015.05.017
|
| [57] |
Steckbeck JD, Craigo JK, Barnes CO, et al. (2011) Highly conserved structural properties of the C-terminal tail of HIV-1 gp41 protein despite substantial sequence variation among diverse clades: Implications for functions in viral replication. J Biol Chem 286: 27156–27166. doi: 10.1074/jbc.M111.258855
|
| [58] |
Dimonte S, Mercurio F, Svicher V, et al. (2011) Selected amino acid mutations in HIV-1 B subtype gp41 are associated with specific gp120v(3) signatures in the regulation of co-receptor usage. Retrovirology 8: 1–11. doi: 10.1186/1742-4690-8-1
|
| [59] |
Perrin C, Fenouillet E, Jones IM (1998) Role of gp41 glycosylation sites in the biological activity of human immunodeficiency virus type 1 envelope glycoprotein. Virology 242: 338–345. doi: 10.1006/viro.1997.9016
|
| [60] |
Johnson WE, Sauvron JM, Desrosiers RC (2001) Conserved, N-linked carbohydrates of human immunodeficiency virus type 1 gp41 are largely dispensable for viral replication. J Virol 75: 11426–11436. doi: 10.1128/JVI.75.23.11426-11436.2001
|
| [61] | Fenouillet E (1993) La N-glycosylation du VIH: Du modèle expérimental à l'application thérapeutique. J Libbery Eurotext Montrouge 9: 901–906. |
| [62] |
Fenouillet E, Jones IM (1995) The glycosylation of human immunodeficiency virus type 1 transmembrane glycoprotein (gp41) is important for the efficient intracellular transport of the envelope precursor gp160. J Gen Virol 76: 1509–1514. doi: 10.1099/0022-1317-76-6-1509
|
| [63] | Lee WR, Yu XF, Syu WJ, et al. (1992) Mutational analysis of conserved N-linked glycosylation sites of human immunodeficiency virus type 1 gp41. J Virol 66: 1799–1803. |
| [64] | Ma BJ, Alam SM, Go EP, et al. (2011) Envelope deglycosylation enhances antigenicity of HIV-1 gp41 epitopes for both broad neutralizing antibodies and their unmutated ancestor antibodies. PLoS Pathog 7: 1–16. |
| [65] |
Wang LX, Song H, Liu S, et al. (2005) Chemoenzymatic synthesis of HIV-1 gp41 glycopeptides: Effects of glycosylation on the anti-HIV activity and alpha-helix bundle-forming ability of peptide C34. Chembiochem 6: 1068–1074. doi: 10.1002/cbic.200400440
|
| [66] |
Balzarini J, Van LK, Hatse S, et al. (2005) Carbohydrate-binding agents cause deletions of highly conserved glycosylation sites in HIV GP120: A new therapeutic concept to hit the achilles heel of HIV. J Biol Chem 280: 41005–41014. doi: 10.1074/jbc.M508801200
|
| [67] |
Van AE, Sanders RW, Liscaljet IM, et al. (2008) Only five of 10 strictly conserved disulfide bonds are essential for folding and eight for function of the HIV-1 envelope glycoprotein. Mol Biol Cell 19: 4298–4309. doi: 10.1091/mbc.E07-12-1282
|
| [68] |
Mathys L, Balzarini J (2014) The role of N-glycans of HIV-1 gp41 in virus infectivity and susceptibility to the suppressive effects of carbohydrate-binding agents. Retrovirology 11: 1–18. doi: 10.1186/1742-4690-11-1
|
| [69] | Fenouillet E, Jones I, Powell B, et al. (1993) Functional role of the glycan cluster of the human immunodeficiency virus type 1 transmembrane glycoprotein (gp41) ectodomain. J Virol 67: 150–160. |
| [70] |
Yuste E, Bixby J, Lifson J, et al. (2008) Glycosylation of gp41 of simian immunodeficiency virus shields epitopes that can be targets for neutralizing antibodies. J Virol 82: 12472–12486. doi: 10.1128/JVI.01382-08
|
| [71] |
Tanaka H, Chiba H, Inokoshi J, et al. (2009) Mechanism by which the lectin actinohivin blocks HIV infection of target cells. Proc Natl Acad Sci U S A 106: 15633–15638. doi: 10.1073/pnas.0907572106
|
| [72] |
Hoorelbeke B, Huskens D, Ferir G, et al. (2010) Actinohivin, a broadly neutralizing prokaryotic lectin, inhibits HIV-1 infection by specifically targeting high-mannose-type glycans on the gp120 envelope. Antimicrob Agents Chemother 54: 3287–32301. doi: 10.1128/AAC.00254-10
|
| [73] |
Zhang F, Hoque MM, Jiang J, et al. (2014) The characteristic structure of anti-HIV actinohivin in complex with three HMTG D1 chains of HIV-gp120. Chembiochem 15: 2766–2773. doi: 10.1002/cbic.201402352
|
| [74] |
Bewley CA, Gustafson KR, Boyd MR, et al. (1998) Solution structure of cyanovirin-N, a potent HIV-inactivating protein. Nat Struct Biol 5: 571–578. doi: 10.1038/828
|
| [75] |
Barrientos LG, Louis JM, Ratner DM, et al. (2003) Solution structure of a circular-permuted variant of the potent HIV-inactivating protein cyanovirin-N: Structural basis for protein stability and oligosaccharide interaction. J Mol Biol 325: 211–223. doi: 10.1016/S0022-2836(02)01205-6
|
| [76] | Esser MT, Mori T, Mondor I, et al. (1999) Cyanovirin-N binds to gp120 to interfere with CD4-dependent human immunodeficiency virus type 1 virion binding, fusion, and infectivity but does not affect the CD4 binding site on gp120 or soluble CD4-induced conformational changes in gp120. J Virol 73: 4360–4371. |
| [77] |
Alexandre KB, Gray ES, Mufhandu H, et al. (2012) The lectins griffithsin, cyanovirin-N and scytovirin inhibit HIV-1 binding to the DC-SIGN receptor and transfer to CD4(+) cells. Virology 423: 175–186. doi: 10.1016/j.virol.2011.12.001
|
| [78] |
Buffa V, Stieh D, Mamhood N, et al. (2009) Cyanovirin-N potently inhibits human immunodeficiency virus type 1 infection in cellular and cervical explant models. J Gen Virol 90: 234–243. doi: 10.1099/vir.0.004358-0
|
| [79] | Boyd MR, Gustafson KR, Mcmahon JB, et al. (1997) Discovery of cyanovirin-N, a novel human immunodeficiency virus-inactivating protein that binds viral surface envelope glycoprotein gp120: Potential applications to microbicide development. Antimicrob Agents Chemother 41: 1521–1530. |
| [80] |
Hu Q, Mahmood N, Shattock RJ (2007) High-mannose-specific deglycosylation of HIV-1 gp120 induced by resistance to cyanovirin-N and the impact on antibody neutralization. Virology 368: 145–154. doi: 10.1016/j.virol.2007.06.029
|
| [81] |
Keeffe JR, Gnanapragasam PN, Gillespie SK, et al. (2011) Designed oligomers of cyanovirin-N show enhanced HIV neutralization. Proc Natl Acad Sci U S A 108: 14079–14084. doi: 10.1073/pnas.1108777108
|
| [82] |
Dey B, Lerner DL, Lusso P, et al. (2000) Multiple antiviral activities of cyanovirin-N: Blocking of human immunodeficiency virus type 1 gp120 interaction with CD4 and coreceptor and inhibition of diverse enveloped viruses. J Virol 74: 4562–4569. doi: 10.1128/JVI.74.10.4562-4569.2000
|
| [83] |
Férir G, Huskens D, Noppen S, et al. (2014) Broad anti-HIV activity of the Oscillatoria agardhii agglutinin homologue lectin family. J Antimicrob Chemother 69: 2746–2758. doi: 10.1093/jac/dku220
|
| [84] |
Koharudin LM, Gronenborn AM (2011) Structural basis of the anti-HIV activity of the cyanobacterial Oscillatoria Agardhii agglutinin. Structure 19: 1170–1181. doi: 10.1016/j.str.2011.05.010
|
| [85] |
Koharudin LM, Furey W, Gronenborn AM (2011) Novel fold and carbohydrate specificity of the potent anti-HIV cyanobacterial lectin from Oscillatoria agardhii. J Biol Chem 286: 1588–1597. doi: 10.1074/jbc.M110.173278
|
| [86] |
Carneiro MG, Koharudin LM, Ban D, et al. (2015) Sampling of Glycan-Bound Conformers by the Anti-HIV Lectin Oscillatoria agardhii agglutinin in the Absence of Sugar. Angew Chem 54: 6462–6465. doi: 10.1002/anie.201500213
|
| [87] |
Bokesch HR, O'Keefe BR, Mckee TC, et al. (2003) A potent novel anti-HIV protein from the cultured cyanobacterium Scytonema varium. Biochemistry 42: 2578–2584. doi: 10.1021/bi0205698
|
| [88] |
Adams EW, Ratner DM, Bokesch HR, et al. (2004) Oligosaccharide and glycoprotein microarrays as tools in HIV glycobiology; glycan-dependent gp120/protein interactions. Chem Biol 11: 875–881. doi: 10.1016/j.chembiol.2004.04.010
|
| [89] |
Mcfeeters RL, Xiong C, O'Keefe BR, et al. (2007) The novel fold of scytovirin reveals a new twist for antiviral entry inhibitors. J Mol Biol 369: 451–461. doi: 10.1016/j.jmb.2007.03.030
|
| [90] |
Alexandre KB, Gray ES, Lambson BE, et al. (2010) Mannose-rich glycosylation patterns on HIV-1 subtype C gp120 and sensitivity to the lectins, Griffithsin, Cyanovirin-N and Scytovirin. Virology 402: 187–196. doi: 10.1016/j.virol.2010.03.021
|
| [91] |
Williams DC, Lee JY, Cai M, et al. (2005) Crystal structures of the HIV-1 inhibitory cyanobacterial protein MVL free and bound to Man3GlcNAc2: Structural basis for specificity and high-affinity binding to the core pentasaccharide from n-linked oligomannoside. J Biol Chem 280: 29269–29276. doi: 10.1074/jbc.M504642200
|
| [92] | Ziółkowska NE, Wlodawer A (2006) Structural studies of algal lectins with anti-HIV activity. Acta Biochim Pol 53: 617–626. |
| [93] |
Shahzadulhussan S, Gustchina E, Ghirlando R, et al. (2011) Solution structure of the monovalent lectin microvirin in complex with Man(alpha)(1–2)Man provides a basis for anti-HIV activity with low toxicity. J Biol Chem 286: 20788–20796. doi: 10.1074/jbc.M111.232678
|
| [94] |
Huskens D, Ferir G, Vermeire K, et al. (2010) Microvirin, a novel alpha(1,2)-mannose-specific lectin isolated from Microcystis aeruginosa, has anti-HIV-1 activity comparable with that of cyanovirin-N but a much higher safety profile. J Biol Chem 285: 24845–24854. doi: 10.1074/jbc.M110.128546
|
| [95] |
López S, Armandugon M, Bastida J, et al. (2003) Anti-human immunodeficiency virus type 1 (HIV-1) activity of lectins from Narcissus species. Planta Med 69: 109–112. doi: 10.1055/s-2003-37715
|
| [96] | Müller WEG, Forrest JMS, Chang SH, et al. (1991) Narcissus and Gerardia lectins: Tools for the development of a vaccine against AIDS and a new ELISA to quantify HIV-gp 120. Lectins Cancer 1991: 27–40. |
| [97] |
Charan RD, Munro MH, O'Keefe BR, et al. (2000) Isolation and characterization of Myrianthus holstii lectin, a potent HIV-1 inhibitory protein from the plant Myrianthus holstii(1). J Nat Prod 63: 1170–1174. doi: 10.1021/np000039h
|
| [98] |
Coulibaly FS, Youan BB (2014) Concanavalin A-polysaccharides binding affinity analysis using a quartz crystal microbalance. Biosens Bioelectron 59: 404–411. doi: 10.1016/j.bios.2014.03.040
|
| [99] | Bhattacharyya L, Brewer CF (1989) Interactions of concanavalin A with asparagine-linked glycopeptides. Structure/activity relationships of the binding and precipitation of oligomannose and bisected hybrid-type glycopeptides with concanavalin A. Eur J Biochem 178: 721–726. |
| [100] |
Witvrouw M, Fikkert V, Hantson A, et al. (2005) Resistance of human immunodeficiency virus type 1 to the high-mannose binding agents cyanovirin N and concanavalin A. J Virol 79: 7777–7784. doi: 10.1128/JVI.79.12.7777-7784.2005
|
| [101] |
Hansen JE, Nielsen CM, Nielsen C, et al. (1989) Correlation between carbohydrate structures on the envelope glycoprotein gp120 of HIV-1 and HIV-2 and syncytium inhibition with lectins. Aids 3: 635–641. doi: 10.1097/00002030-198910000-00003
|
| [102] | Matsui T, Kobayashi S, Yoshida O, et al. (1990) Effects of succinylated concanavalin A on infectivity and syncytial formation of human immunodeficiency virus. Med Microbiol Immunol 179: 225–235. |
| [103] |
Pashov A, Macleod S, Saha R, et al. (2005) Concanavalin A binding to HIV envelope protein is less sensitive to mutations in glycosylation sites than monoclonal antibody 2G12. Glycobiology 15: 994–1001. doi: 10.1093/glycob/cwi083
|
| [104] |
Swanson MD, Boudreaux DM, Salmon L, et al. (2015) Engineering a therapeutic lectin by uncoupling mitogenicity from antiviral activity. Cell 163: 746–758. doi: 10.1016/j.cell.2015.09.056
|
| [105] |
Alexandre KB, Gray ES, Pantophlet R, et al. (2011) Binding of the mannose-specific lectin, griffithsin, to HIV-1 gp120 exposes the CD4-binding site. J Virol 85: 9039–9050. doi: 10.1128/JVI.02675-10
|
| [106] |
Mori T, O'Keefe BR, Bringans S, et al. (2005) Isolation and characterization of griffithsin, a novel HIV-inactivating protein, from the red alga Griffithsia sp. J Biol Chem 280: 9345–9353. doi: 10.1074/jbc.M411122200
|
| [107] |
Emau P, Tian B, O'Keefe BR, et al. (2007) Griffithsin, a potent HIV entry inhibitor, is an excellent candidate for anti-HIV microbicide. J Med Primatol 36: 244–253. doi: 10.1111/j.1600-0684.2007.00242.x
|
| [108] |
Moulaei T, Alexandre KB, Shenoy SR, et al. (2015) Griffithsin tandemers: Flexible and potent lectin inhibitors of the human immunodeficiency virus. Retrovirology 12: 1–14. doi: 10.1186/s12977-014-0129-1
|
| [109] | Zhou X, Liu J, Yang B, et al. (2013) Marine natural products with anti-HIV activities in the last decade. Curr Med Chem 20: 953–973. |
| [110] |
Wang JH, Kong J, Li W, et al. (2006) A beta-galactose-specific lectin isolated from the marine worm Chaetopterus variopedatus possesses anti-HIV-1 activity. Comp Biochem Physiol C Toxicol Pharmacol 142: 111–117. doi: 10.1016/j.cbpc.2005.10.019
|
| [111] |
Bulgheresi S, Schabussova I, Chen T, et al. (2006) A new C-type lectin similar to the human immunoreceptor DC-SIGN mediates symbiont acquisition by a marine nematode. Appl Environ Microbiol 72: 2950–2956. doi: 10.1128/AEM.72.4.2950-2956.2006
|
| [112] |
Nabatov AA, Jong MAWPD, Witte LD, et al. (2008) C-type lectin Mermaid inhibits dendritic cell mediated HIV-1 transmission to CD4+ T cells. Virology 378: 323–328. doi: 10.1016/j.virol.2008.05.025
|
| [113] |
Molchanova V, Chikalovets I, Chernikov O, et al. (2007) A new lectin from the sea worm Serpula vermicularis: Isolation, characterization and anti-HIV activity. Comp Biochem Physiol C Toxicol Pharmacol 145: 184–193. doi: 10.1016/j.cbpc.2006.11.012
|
| [114] |
Vo TS, Kim SK (2010) Potential anti-HIV agents from marine resources: An overview. Mar Drugs 8: 2871–2892. doi: 10.3390/md8122871
|
| [115] |
Mahalingam A, Geonnotti AR, Balzarini J, et al. (2011) Activity and safety of synthetic lectins based on benzoboroxole-functionalized polymers for inhibition of HIV entry. Mol Pharmaceutics 8: 2465–2475. doi: 10.1021/mp2002957
|
| [116] |
Berube M, Dowlut M, Hall DG (2008) Benzoboroxoles as efficient glycopyranoside-binding agents in physiological conditions: Structure and selectivity of complex formation. J Org Chem 73: 6471–6479. doi: 10.1021/jo800788s
|
| [117] | Trippier PC, Mcguigan C, Balzarini J (2010) Phenylboronic-acid-based carbohydrate binders as antiviral therapeutics: Monophenylboronic acids. Antivir Chem Chemother 20: 249–257. |
| [118] | Trippier PC, Balzarini J, Mcguigan C (2011) Phenylboronic-acid-based carbohydrate binders as antiviral therapeutics: Bisphenylboronic acids. Antivir Chem Chemother 21: 129–142. |
| [119] | Khan JM, Qadeer A, Ahmad E, et al. (2013) Monomeric banana lectin at acidic pH overrules conformational stability of its native dimeric form. PLoS One 8: 1–12. |
| [120] |
Suzuki K, Ohbayashi N, Jiang J, et al. (2012) Crystallographic study of the interaction of the anti-HIV lectin actinohivin with the alpha(1-2)mannobiose moiety of gp120 HMTG. Acta Crystallogr Sect F Struct Biol Cryst Commun 68: 1060–1063. doi: 10.1107/S1744309112031077
|
| [121] | Tevibénissan C, Bélec L, Lévy M, et al. (1997) In vivo semen-associated pH neutralization of cervicovaginal secretions. Clin Diagn Lab Immunol 4: 367–374. |
| [122] |
Ballerstadt R, Evans C, Mcnichols R, et al. (2006) Concanavalin A for in vivo glucose sensing: A biotoxicity review. Biosens Bioelectron 22: 275–284. doi: 10.1016/j.bios.2006.01.008
|
| [123] |
Krauss S, Buttgereit F, Brand MD (1999) Effects of the mitogen concanavalin A on pathways of thymocyte energy metabolism. Biochim Biophys Acta 1412: 129–138. doi: 10.1016/S0005-2728(99)00058-4
|
| [124] |
Balzarini J, Laethem KV, Peumans WJ, et al. (2006) Mutational pathways, resistance profile, and side effects of cyanovirin relative to human immunodeficiency virus type 1 strains with N-glycan deletions in their gp120 envelopes. J Virol 80: 8411–8421. doi: 10.1128/JVI.00369-06
|
| [125] |
Gavrovicjankulovic M, Poulsen K, Brckalo T, et al. (2008) A novel recombinantly produced banana lectin isoform is a valuable tool for glycoproteomics and a potent modulator of the proliferation response in CD3+, CD4+, and CD8+ populations of human PBMCs. Int J Biochem Cell Biol 40: 929–941. doi: 10.1016/j.biocel.2007.10.033
|
| [126] |
Mahalingam A, Geonnotti AR, Balzarini J, et al. (2011) Activity and safety of synthetic lectins based on benzoboroxole-functionalized polymers for inhibition of HIV entry. Mol Pharm 8: 2465–2475. doi: 10.1021/mp2002957
|
| [127] |
Lam SK, Ng TB (2011) Lectins: Production and practical applications. Appl Microbiol Biotechnol 89: 45–55. doi: 10.1007/s00253-010-2892-9
|
| [128] |
Scanlan CN, Offer J, Zitzmann N, et al. (2007) Exploiting the defensive sugars of HIV-1 for drug and vaccine design. Nature 446: 1038–1045. doi: 10.1038/nature05818
|
| [129] | Gupta A, Gupta RK, Gupta GS (2009) Targeting cells for drug and gene delivery: Emerging applications of mannans and mannan binding lectins. J Sci Ind Res 68: 465–483. |
| [130] |
Ghazarian H, Idoni B, Oppenheimer SB (2011) A glycobiology review: Carbohydrates, lectins and implications in cancer therapeutics. Acta Histochem 113: 236–247. doi: 10.1016/j.acthis.2010.02.004
|
| [131] |
Toda S, Ishii N, Okada E, et al. (1997) HIV-1-specific cell-mediated immune responses induced by DNA vaccination were enhanced by mannan-coated liposomes and inhibited by anti-interferon-gamma antibody. Immunology 92: 111–117. doi: 10.1046/j.1365-2567.1997.00307.x
|
| [132] |
Zelensky AN, Gready JE (2005) The C-type lectin-like domain superfamily. FEBS J 272: 6179–6217. doi: 10.1111/j.1742-4658.2005.05031.x
|
| [133] |
Cui Z, Hsu CH, Mumper RJ (2003) Physical characterization and macrophage cell uptake of mannan-coated nanoparticles. Drug Dev Ind Pharm 29: 689–700. doi: 10.1081/DDC-120021318
|
| [134] |
Espuelas S, Thumann C, Heurtault B, et al. (2008) Influence of ligand valency on the targeting of immature human dendritic cells by mannosylated liposomes. Bioconjugate Chem 19: 2385–2393. doi: 10.1021/bc8002524
|
| [135] |
Zhang Q, Su L, Collins J, et al. (2014) Dendritic cell lectin-targeting sentinel-like unimolecular glycoconjugates to release an anti-HIV drug. J Am Chem Soc 136: 4325–4332. doi: 10.1021/ja4131565
|
| [136] |
Hong PWP, Flummerfelt KB, Parseval AD, et al. (2002) Human immunodeficiency virus envelope (gp120) binding to DC-SIGN and primary dendritic cells is carbohydrate dependent but does not involve 2G12 or cyanovirin binding sites: Implications for structural analyses of gp120-DC-SIGN binding. J Virol 76: 12855–12865. doi: 10.1128/JVI.76.24.12855-12865.2002
|
| [137] |
Cruz LJ, Tacken PJ, Fokkink R, et al. (2010) Targeted PLGA nano- but not microparticles specifically deliver antigen to human dendritic cells via DC-SIGN in vitro. J Controlled Release 144: 118–126. doi: 10.1016/j.jconrel.2010.02.013
|
| [138] |
Ingale J, Stano A, Guenaga J, et al. (2016) High-Density Array of Well-Ordered HIV-1 Spikes on Synthetic Liposomal Nanoparticles Efficiently Activate B Cells. Cell Rep 15: 1986–1999. doi: 10.1016/j.celrep.2016.04.078
|
| [139] | He L, Val ND, Morris CD, et al. (2016) Presenting native-like trimeric HIV-1 antigens with self-assembling nanoparticles. Nat Commun 7: 1–15. |
| [140] |
Akashi M, Niikawa T, Serizawa T, et al. (1998) Capture of HIV-1 gp120 and virions by lectin-immobilized polystyrene nanospheres. Bioconjugate Chem 9: 50–53. doi: 10.1021/bc970045y
|
| [141] |
Hayakawa T, Kawamura M, Okamoto M, et al. (1998) Concanavalin A-immobilized polystyrene nanospheres capture HIV-1 virions and gp120: Potential approach towards prevention of viral transmission. J Med Virol 56: 327–331. doi: 10.1002/(SICI)1096-9071(199812)56:4<327::AID-JMV7>3.0.CO;2-A
|
| [142] | Coulibaly FS, Ezoulin MJM, Purohit SS, et al. (2017) Layer-by-layer engineered microbicide drug delivery system targeting HIV-1 gp120: Physicochemical and biological properties. Mol Pharm 14: 3512–3527. |
| [143] |
Takahashi K, Moyo P, Chigweshe L, et al. (2013) Efficacy of recombinant chimeric lectins, consisting of mannose binding lectin and L-ficolin, against influenza A viral infection in mouse model study. Virus Res 178: 495–501. doi: 10.1016/j.virusres.2013.10.001
|
| [144] |
Sato Y, Morimoto K, Kubo T, et al. (2015) Entry Inhibition of Influenza Viruses with High Mannose Binding Lectin ESA-2 from the Red Alga Eucheuma serra through the Recognition of Viral Hemagglutinin. Mar Drugs 13: 3454–3465. doi: 10.3390/md13063454
|
| [145] |
Kachko A, Loesgen S, Shahzad-Ul-Hussan S, et al. (2013) Inhibition of hepatitis C virus by the cyanobacterial protein Microcystis viridis lectin: Mechanistic differences between the high-mannose specific lectins MVL, CV-N, and GNA. Mol Pharmaceutics 10: 4590–4602. doi: 10.1021/mp400399b
|
| [146] |
Gadjeva M, Paludan SR, Thiel S, et al. (2004) Mannan-binding lectin modulates the response to HSV-2 infection. Clin Exp Immunol 138: 304–311. doi: 10.1111/j.1365-2249.2004.02616.x
|
| [147] |
Eisen S, Dzwonek A, Klein NJ (2008) Mannose-binding lectin in HIV infection. Future Virol 3: 225–233. doi: 10.2217/17460794.3.3.225
|
| [148] |
Ji X, Olinger GG, Aris S, et al. (2005) Mannose-binding lectin binds to Ebola and Marburg envelope glycoproteins, resulting in blocking of virus interaction with DC-SIGN and complement-mediated virus neutralization. J Gen Virol 86: 2535–2542. doi: 10.1099/vir.0.81199-0
|
| [149] |
Keyaerts E, Vijgen L, Pannecouque C, et al. (2007) Plant lectins are potent inhibitors of coronaviruses by interfering with two targets in the viral replication cycle. Antiviral Res 75: 179–187. doi: 10.1016/j.antiviral.2007.03.003
|
| [150] |
Hamel R, Dejarnac O, Wichit S, et al. (2015) Biology of Zika Virus Infection in Human Skin Cells. J Virol 89: 8880–8896. doi: 10.1128/JVI.00354-15
|
| [151] |
Clement F, Venkatesh YP (2010) Dietary garlic (Allium sativum) lectins, ASA I and ASA II, are highly stable and immunogenic. Int Immunopharmacol 10: 1161–1169. doi: 10.1016/j.intimp.2010.06.022
|
| [152] | Lusvarghi S, Bewley CA (2016) Griffithsin: An Antiviral Lectin with Outstanding Therapeutic Potential. Viruses 8: 1–18. |
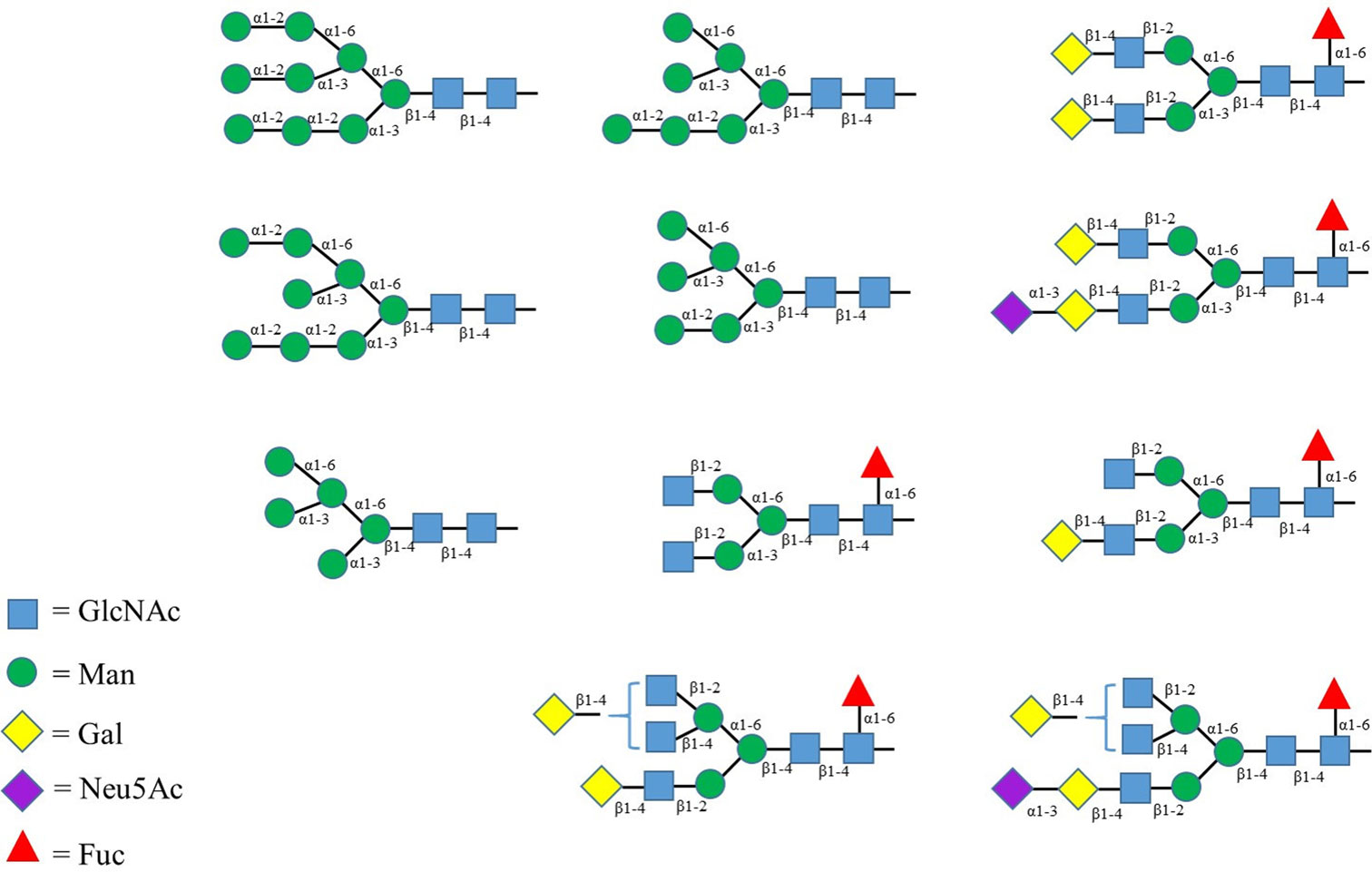
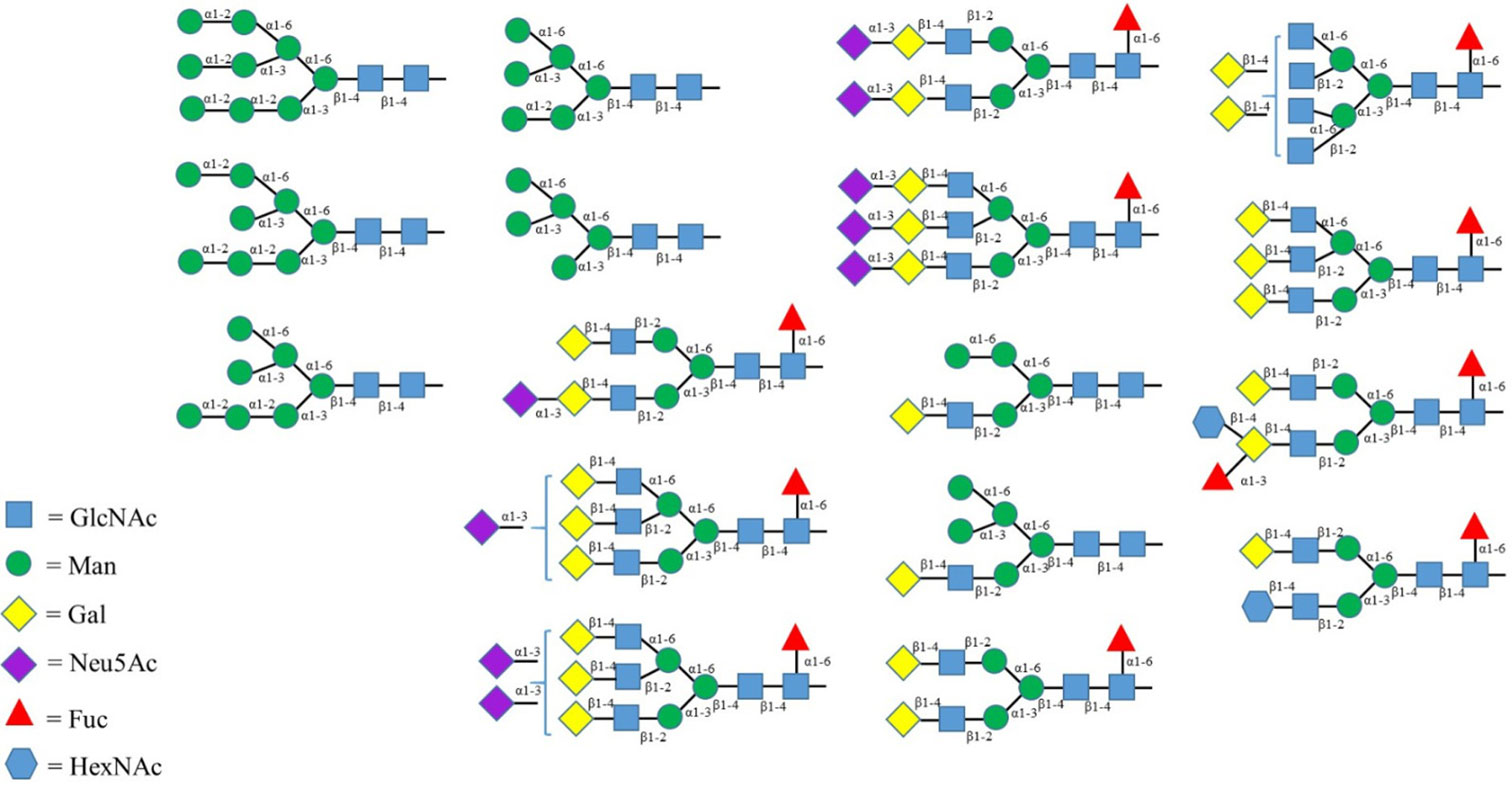
Figures(2) / Tables(2)

Fohona S. Coulibaly, Danielle N. Thomas, Bi-Botti C. Youan. Anti-HIV lectins and current delivery strategies[J]. AIMS Molecular Science, 2018, 5(1): 96-116. doi: 10.3934/molsci.2018.1.96







 DownLoad:
DownLoad: