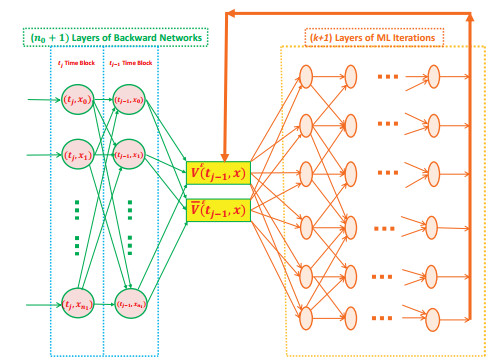
We have studied a strongly nonlinear backward stochastic partial differential equation (B-SPDE) through an approximation method and with machine learning (ML)-based Monte Carlo simulation. This equation is well-known and was previously derived from studies in finance. However, how to analyze and solve this equation has remained a problem for quite a long time. The main difficulty is due to the singularity of the B-SPDE since it is a strongly nonlinear one. Therefore, by introducing new truncation operators and integrating the machine learning technique into the platform of a convolutional neural network (CNN), we have developed an effective approximation method with a Monte Carlo simulation algorithm to tackle the well-known open problem. In doing so, the existence and uniqueness of a 2-tuple adapted strong solution to an approximation B-SPDE were proved. Meanwhile, the convergence of a newly designed simulation algorithm was established. Simulation examples and an application in finance were also provided.
Citation: Wanyang Dai. Simulating a strongly nonlinear backward stochastic partial differential equation via efficient approximation and machine learning[J]. AIMS Mathematics, 2024, 9(7): 18688-18711. doi: 10.3934/math.2024909
We have studied a strongly nonlinear backward stochastic partial differential equation (B-SPDE) through an approximation method and with machine learning (ML)-based Monte Carlo simulation. This equation is well-known and was previously derived from studies in finance. However, how to analyze and solve this equation has remained a problem for quite a long time. The main difficulty is due to the singularity of the B-SPDE since it is a strongly nonlinear one. Therefore, by introducing new truncation operators and integrating the machine learning technique into the platform of a convolutional neural network (CNN), we have developed an effective approximation method with a Monte Carlo simulation algorithm to tackle the well-known open problem. In doing so, the existence and uniqueness of a 2-tuple adapted strong solution to an approximation B-SPDE were proved. Meanwhile, the convergence of a newly designed simulation algorithm was established. Simulation examples and an application in finance were also provided.

| [1] |
J. Braun, M. Griebel, On a constructive proof of Kolmogorov's superposition thoerem, Constr. Approx., 35 (2009), 653–675. https://doi.org/10.1007/s00365-009-9054-2 doi: 10.1007/s00365-009-9054-2

|
| [2] |
A. Cĕrný, J. Kallsen. On the structure of general mean-variance hedging strategies, Ann. Appl. Probab., 35 (2007), 1479–1531. https://doi.org/10.1214/009117906000000872 doi: 10.1214/009117906000000872
|
| [3] |
G. Cybenko, Approximation by superpositions of a sigmoidal function, Math. Control Signal System, 1 (1989), 303–314. https://doi.org/10.1007/BF02551274 doi: 10.1007/BF02551274
|
| [4] | W. Dai, Brownian approximations for queueing networks with finite buffers: modeling, heavy traffic analysis and numerical implementations, Ph.D thesis, Georgia Institute of Technology, 1996. |
| [5] |
J. G. Dai, W. Dai, A heavy traffic limit theorem for a class of open queueing networks with finite buffers, Queueing Syst., 32 (1999), 5–40. https://doi.org/10.1023/A:1019178802391 doi: 10.1023/A:1019178802391
|
| [6] |
W. Dai, Mean-variance portfolio selection based on a generalized BNS stochastic volatility model, Int. J. Comput. Math., 88 (2011), 3521–3534. https://doi.org/10.1080/00207160.2011.606904 doi: 10.1080/00207160.2011.606904
|
| [7] |
W. Dai, Optimal rate scheduling via utility-maximization for $J$-user MIMO Markov fading wireless channels with cooperation, Oper. Res., 61 (2013), 1450–1462. https://doi.org/10.1287/opre.2013.1224 doi: 10.1287/opre.2013.1224
|
| [8] |
W. Dai, Mean-variance hedging based on an incomplete market with external risk factors of non-Gaussian OU processes, Math. Probl. Eng., 2015 (2015), 625289. https://doi.org/10.1155/2015/625289 doi: 10.1155/2015/625289
|
| [9] |
W. Dai, Convolutional neural network based simulation and analysis for backward stochastic partial differential equations, Comput. Math. Appl., 119 (2022), 21–58. https://doi.org/10.1016/j.camwa.2022.05.019 doi: 10.1016/j.camwa.2022.05.019
|
| [10] |
W. Dai, Optimal policy computing for blockchain based smart contracts via federated learning, Oper. Res. Int. J., 22 (2022), 5817–5844. https://doi.org/10.1007/s12351-022-00723-z doi: 10.1007/s12351-022-00723-z
|
| [11] |
L. Gonon, L. Grigoryeva, J. P. Ortega, Approximation bounds for random neural networks and reservoir systems, Ann. Appl. Probab., 33 (2023), 28–69. https://doi.org/10.1214/22-AAP1806 doi: 10.1214/22-AAP1806
|
| [12] | R. Gozalo-Brizuela, E. C. Garrido-Merchan, ChatGPT is not all you need. A state of the art review of large generative AI models, preprint paper, 2023. https://doi.org/10.48550/arXiv.2301.04655 |
| [13] | S. Haykin, Neural networks: A Comprehensive Foundation, New Jersey: Prentice Hall PTR, 1994. |
| [14] |
K. Hornik, M. Stinchcombe, H. White, Multilayer feedforward networks are universal approximators, Neur. Networks, 2 (1989), 359–366. https://doi.org/10.1016/0893-6080(89)90020-8 doi: 10.1016/0893-6080(89)90020-8
|
| [15] | N. Ikeda, S. Watanabe, Stochastic Differential Equations and Diffusion Processes, 2 Eds., Kodansha: North-Holland, 1989. |
| [16] | O. Kallenberg, Foundation of Modern Probability, Berlin: Springer, 1997. |
| [17] | A. N. Kolmogorov, On the representation of continuous functions of several variables as superpositions of continuous functions of a smaller number of variables, Dokl. Akad. Nauk, 108 (1956). |
| [18] |
D. Kramkov, M. Sirbu, On the two times differentiability of the value function in the problem of optimal investment in incomplete markets, Ann. Appl. Probab., 16 (2006), 1352–1384. https://doi.org/10.1214/105051606000000259 doi: 10.1214/105051606000000259
|
| [19] | A. Kratsios, V. Debarnot, I. Dokmannić, Small transformers compute universal metric embeddings, J. Mach. Learning Res., 24 (2023), 1–48. |
| [20] |
Y. LeCun, B. Boser, J. S. Denker, D. Henderson, R. E. Howard, W. Hubbard, et al., Backpropagation applied to handwritten zip code recognition, Neur. Comput., 1 (1989), 541–551. https://doi.org/10.1162/neco.1989.1.4.541 doi: 10.1162/neco.1989.1.4.541
|
| [21] | Z. Liu, Y. Wang, S. Vaidya, F. Ruehle, J. Halverson, M. Solja$\breve{c}$ić, et al., KAN: Kolmogorov-Arnold networks, preprint paper, 2024. https://arXiv.org/pdf/2404.19756 |
| [22] | M. Musiela, T. Zariphopoulou. Stochastic partial differential equations and portfolio choice, In: Contemporary Quantitative Finance, Berlin: Springer, 2009. https://doi.org/10.1007/978-3-642-03479-4_11 |
| [23] | B. $\emptyset$ksendal, Stochastic Differential Equations, 6 Eds, New York: Springer, 2005. |
| [24] | B. $\emptyset$ksendal, A. Sulem, T. Zhang, A stochastic HJB equation for optimal control of forward-backward SDEs, In: The Fascination of Probability, Statistics and their Applications, Berlin: Springer, 2016. |
| [25] | S. Peluchetti, Diffusion bridge mixture transports, Schr$\ddot{o}$dinger bridge problems and generative modeling, J. Mach. Learning Res., 24 (2023), 1–51. |
| [26] |
J. Sirignano, K. Spiliopoulos, Dgm: a deep learning algorithm for solving partial differential equations, J. Comput. Phys., 375 (2018), 1339–1364. https://doi.org/10.1016/j.jcp.2018.08.029 doi: 10.1016/j.jcp.2018.08.029
|
| [27] | A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, et al., Attention is all you need, Adv. Neur. Informa. Proc. Syst., 30 (2017), 5998–6008. |
| [28] |
R. Yamashitza, M. Nishio, R. K. G. Do, Togashi, Convolutional neural networks: an overview and application in radiology, Insights into Imaging, 9 (2018), 611–629. https://doi.org/10.1007/s13244-018-0639-9 doi: 10.1007/s13244-018-0639-9
|







Figures(8)

Wanyang Dai. Simulating a strongly nonlinear backward stochastic partial differential equation via efficient approximation and machine learning[J]. AIMS Mathematics, 2024, 9(7): 18688-18711. doi: 10.3934/math.2024909







 DownLoad:
DownLoad: