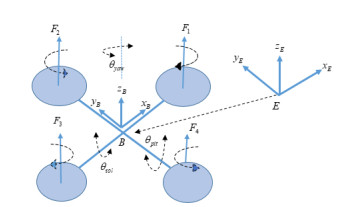
In this work, an adaptive backstepping position tracking control using neural network (NN) approximation mechanism is proposed with respect to the translational system of quadrotor unmanned aerial vehicle (QUAV). Concerning the translational system of QUAV, on the one hand, it does not satisfy the matching condition and is an under-actuation dynamic system; on the other hand, it is with strong nonlinearity containing some uncertainty. To achieve the control objective, an intermediary control is introduced to handle the under-actuation problem, then the backstepping technique is combined with NN approximation strategy, which is employed to compensate the uncertainty of the system. Compared with traditional adaptive methods, the proposed adaptive NN position control of QUAV can alleviate the computation burden effectively, because it only trains a scalar adaptive parameter instead of the adaptive parameter vector or matrix. Finally, according to Lyapunov stability proof and computer simulation, it is proved that the control tasks can be accomplished.
Citation: Xia Song, Lihua Shen, Fuyang Chen. Adaptive backstepping position tracking control of quadrotor unmanned aerial vehicle system[J]. AIMS Mathematics, 2023, 8(7): 16191-16207. doi: 10.3934/math.2023828
In this work, an adaptive backstepping position tracking control using neural network (NN) approximation mechanism is proposed with respect to the translational system of quadrotor unmanned aerial vehicle (QUAV). Concerning the translational system of QUAV, on the one hand, it does not satisfy the matching condition and is an under-actuation dynamic system; on the other hand, it is with strong nonlinearity containing some uncertainty. To achieve the control objective, an intermediary control is introduced to handle the under-actuation problem, then the backstepping technique is combined with NN approximation strategy, which is employed to compensate the uncertainty of the system. Compared with traditional adaptive methods, the proposed adaptive NN position control of QUAV can alleviate the computation burden effectively, because it only trains a scalar adaptive parameter instead of the adaptive parameter vector or matrix. Finally, according to Lyapunov stability proof and computer simulation, it is proved that the control tasks can be accomplished.

| [1] |
P. Rodriguez-Gonzalvez, D. Gonzalez-Aguilera, G. Lopez-Jimenez, I. Picon-Cabrera, Imagebased modeling of built environment from an unmanned aerial system, Automat. Const., 48 (2014), 44–52. http://dx.doi.org/10.1016/j.autcon.2014.08.010 doi: 10.1016/j.autcon.2014.08.010

|
| [2] |
J. Senthilnath, A. Dokania, M. Kandukuri, K. N. Ramesh, G. Anand, S. N. Omkar, Detection of tomatoes using spectral-spatial methods in remotely sensed rgb images captured by uav, Biosyst. Eng., 146 (2016), 16–32. http://dx.doi.org/10.1016/j.biosystemseng.2015.12.003 doi: 10.1016/j.biosystemseng.2015.12.003
|
| [3] | A. Ryan, J. K. Hedrick, A mode-switching path planner for uav-assisted search and rescue, In: Proceedings 44th IEEE Confrences Decision and Control, 2005, 1471–1476. http://dx.doi.org/10.1109/CDC.2005.1582366 |
| [4] |
K. Alexis, G. Nikolakopoulos, A. Tzes, L. Dritsas, Coordination of Helicopter UAVs for Aerial Forest-Fire Surveillance, Appl. Intell. Control Eng. Systems, 39 (2009), 169–193. http://dx.doi.org/10.1007/978-90-481-3018-4_7 doi: 10.1007/978-90-481-3018-4_7
|
| [5] |
X. Liang, Y. Fang, N. Sun, H. Lin, Dynamics analysis and time-optimal motion planning for unmanned quadrotor transportation systems, Mechatronics, 50 (2018), 16–29. http://dx.doi.org/10.1016/j.mechatronics.2018.01.009 doi: 10.1016/j.mechatronics.2018.01.009
|
| [6] |
H. Liu, X. Wang, Y. Zhong, Dynamics analysis and time-optimal motion planning for unmanned quadrotor transportation systems, IEEE T. Ind. Inform., 11 (2017), 406–415. http://dx.doi.org/10.1109/TII.2015.2397878 doi: 10.1109/TII.2015.2397878
|
| [7] | S. Gupte, P. I. T. Mohandas, J. M. Conrad, A survey of quadrotor unmanned aerial vehicles, In: 2012 Proceedings of IEEE Southeastcon, 2012, 1–6. http://dx.doi.org/10.1109/SECon.2012.6196930 |
| [8] |
G. Wen, W. Hao, W. Feng, K. Gao, Optimized backstepping tracking control using reinforcement learning for quadrotor unmanned aerial vehicle system, IEEE T. Syst. Man Cy. Syst., 52 (2022), 5004–5015. http://dx.doi.org/10.1109/TSMC.2021.3112688 doi: 10.1109/TSMC.2021.3112688
|
| [9] | A. L. Salih, M. Moghavvemi, H. A. F. Mohamed, K. S. Gaeid, Modelling and pid controller design for a quadrotor unmanned air vehicle, In: 2010 IEEE International Conference on Automation, Quality and Testing, Robotics (AQTR), 1 (2010), 1–5. http://dx.doi.org/10.1109/AQTR.2010.5520914 |
| [10] | R. Xu, U. Ozguner, Sliding mode control of a quadrotor helicopter, In: Proceedings of the 45th IEEE Conference on Decision and Control, (2006), 4957–4962. https://doi.org/10.1109/CDC.2006.377588 |
| [11] |
P. Castillo, R. Lozano, A. Dzul, Stabilization of a mini rotorcraft with four rotors, IEEE Control Syst., 25 (2005), 45–55. https://doi.org/10.1109/IROS.2004.1389815 doi: 10.1109/IROS.2004.1389815
|
| [12] | M. Santos, V. Lopez, F. Morata, Intelligent fuzzy controller of a quadrotor, In: 2010 IEEE International Conference on Intelligent Systems and Knowledge Engineering, 2010,141–146. https://doi.org/10.1109/ISKE.2010.5680812 |
| [13] |
G. Wen, S. S. Ge, F. Tu, Optimized backstepping for tracking control of strict-feedback systems, IEEE T. Neur. Net. Lear. Syst., 29 (2018), 3850–3862. http://dx.doi.org/10.1109/TNNLS.2018.2803726 doi: 10.1109/TNNLS.2018.2803726
|
| [14] |
A. Karimi, A. Feliachi, Decentralized adaptive backstepping control of electric power systems, Electr. Pow. Syst. Res., 78 (2008), 484–493. http://dx.doi.org/10.1016/j.epsr.2007.04.003 doi: 10.1016/j.epsr.2007.04.003
|
| [15] |
Q. Xie, Z. Han, H. Kang, Adaptive backstepping control for hybrid excitation synchronous machine with uncertain parameters, Expert Syst. Appl., 37 (2010), 7280–7284. http://dx.doi.org/10.1016/j.eswa.2010.03.038 doi: 10.1016/j.eswa.2010.03.038
|
| [16] |
G. Wen, C. L. P. Chen, S. S. Ge, Simplified optimized backstepping control for a class of nonlinear strict-feedback systems with unknown dynamic functions, IEEE T. Cybernetics, 51 (2021), 4567–4580. http://dx.doi.org/10.1109/TCYB.2020.3002108 doi: 10.1109/TCYB.2020.3002108
|
| [17] |
R. Sakthivel, A. Parivallal, N. Huy Tuan, S. Manickavalli, Nonfragile control design for consensus of semi-markov jumping multiagent systems with disturbances, Int. J. Adapt. Control Signal Proc., 35 (2021), 1039–1061. http://dx.doi.org/10.1002/acs.3245 doi: 10.1002/acs.3245
|
| [18] |
A. Parivallal, R. Sakthivel, C. Wang, Guaranteed cost leaderless consensus for uncertain markov jumping multi-agent systems, J. Exp. Theor. Artif. Int., 35 (2023), 257–273. http://dx.doi.org/10.1080/0952813X.2021.1960631 doi: 10.1080/0952813X.2021.1960631
|
| [19] |
M. A. Mohd Basri, A. R. Husain, K. A. Danapalasingam, Enhanced backstepping controller design with application to autonomous quadrotor unmanned aerial vehicle, J. Intell. Robot. Syst., 79 (2015), 295–321. http://dx.doi.org/10.1007/s10846-014-0072-3 doi: 10.1007/s10846-014-0072-3
|
| [20] | T. Madani, A. Benallegue, Backstepping control for a quadrotor helicopter, In: IEEE/RSJ International Conference on Intelligent Robots & Systemn, 2006, 9419317. http://dx.doi.org/10.1109/IROS.2006.282433 |
| [21] | T. Madani, A. Benallegue, Backstepping sliding mode control applied to a miniature quadrotor flying robot, In: IECON 2006-32nd Annual Conference on IEEE Industrial Electronics, 2006, 9430817. http://dx.doi.org/10.1109/IECON.2006.347236 |
| [22] | T. Madani, A. Benallegue, Control of a quadrotor mini-helicopter via full state backstepping technique, In: Proceedings of the 45th IEEE Conference on Decision and Control, 2006, 9409085. http://dx.doi.org/10.1109/CDC.2006.377548 |
| [23] |
G. Wen, C. L. P. Chen, S. S. Ge, H. Yang, X. Liu, Optimized adaptive nonlinear tracking control using actor-critic reinforcement learning strategy, IEEE T. Ind. Inform., 15 (2019), 4969–4977. http://dx.doi.org/10.1109/TII.2019.2894282 doi: 10.1109/TII.2019.2894282
|
| [24] |
A. Poznyak, W. Yu, E. Sanchez, J. Perez, Nonlinear adaptive trajectory tracking using dynamic neural networks, IEEE T. Neur. Net., 10 (1999), 1402–1411. http://dx.doi.org/10.1109/72.809085 doi: 10.1109/72.809085
|
| [25] | A. S. Poznyak, W. Yu, E. N. Sanchez, J. P. Perez, Stability analysis of dynamic neural control, Expert Syst. Appl., 14 (1998), 227–236. http://dx.doi.org/10.1016/S0957-4174(97)00072-9 |
| [26] | G. Wen, S. S. Ge, C. L. P. Chen, F. Tu, S. Wang, Adaptive tracking control of surface vessel using optimized backstepping technique, IEEE T. Cybernetics. 49 (2019), 3420–3431. http://dx.doi.org/10.1109/TCYB.2018.2844177 |
| [27] | A. Poznyak, W. Yu, Robust asymptotic neuro-observer with time delay term, J. Robust Nonlin. Control, 10 (2000), 535–559. |
| [28] |
G. Wen, C. L. P. Chen, J. Feng, N. Zhou, Optimized multi-agent formation control based on an identifier-actor-critic reinforcement learning algorithm, IEEE T. Fuzzy Syst., 26 (2018), 2719–2731. http://dx.doi.org/10.1109/TFUZZ.2017.2787561 doi: 10.1109/TFUZZ.2017.2787561
|
| [29] |
Y. J. Liu, W. Wang, S. C. Tong, Y. S. Liu, Robust adaptive tracking control for nonlinear systems based on bounds of fuzzy approximation parameters, IEEE T. Syst. Man Cy. A, 40 (2010), 170–184. http://dx.doi.org/10.1109/TSMCA.2009.2030164 doi: 10.1109/TSMCA.2009.2030164
|
| [30] |
X. Shao, S. Tong, Adaptive fuzzy prescribed performance control for mimo stochastic nonlinear systems, IEEE Access, 6 (2018), 76754–76767. http://dx.doi.org/10.1109/ACCESS.2018.2882634 doi: 10.1109/ACCESS.2018.2882634
|
| [31] |
S. Islam, P. X. Liu, A. El Saddik, Nonlinear adaptive control for quadrotor flying vehicle, Nonlinear Dynam., 78 (2014), 117–133. http://dx.doi.org/10.1007/s11071-014-1425-y doi: 10.1007/s11071-014-1425-y
|
| [32] |
F. Kendoul, Z. Yu, K. Nonami, Guidance and nonlinear control system for autonomous flight of minirotorcraft unmanned aerial vehicles, J. Field Robot., 27 (2010), 311–334. http://dx.doi.org/10.1002/rob.20327 doi: 10.1002/rob.20327
|
| [33] |
B. Zhao, B. Xian, Y. Zhang, X. Zhang, Nonlinear robust adaptive tracking control of a quadrotor uav via immersion and invariance methodology, IEEE T. Ind. Electron., 62 (2015), 2891–2902. http://dx.doi.org/10.1109/TIE.2014.2364982 doi: 10.1109/TIE.2014.2364982
|
| [34] |
G. Wen, S. S. Ge, F. Tu, Optimized backstepping for tracking control of strict-feedback systems, IEEE T. Neural Net. Learning Syst., 29 (2018), 3850–3862. http://dx.doi.org/10.1109/TNNLS.2018.2803726 doi: 10.1109/TNNLS.2018.2803726
|
| [35] |
G. X. Wen, C. L. P. Chen, Y. J. Liu, Z. Liu, Neural-network-based adaptive leader-following consensus control for second-order non-linear multi-agent systems, IET Control Theory Appl., 9 (2015), 1927–1934. https://doi.org/10.1109/TCYB.2016.2608499 doi: 10.1109/TCYB.2016.2608499
|
| [36] |
S. S. Ge, C. C. Hang, T. Zhang, Adaptive neural network control of nonlinear systems by state and output feedback, IEEE T. Syst. Man Cy. B, 29 (1999), 818–828. http://dx.doi.org/10.1109/3477.809035 doi: 10.1109/3477.809035
|
| [37] |
W. Yang, G. Cui, Q. Ma, J. Ma, C. Tao, Finite-time adaptive event-triggered command filtered backstepping control for a quav, Appl. Math. Comput., 423 (2022), 126898. http://dx.doi.org/10.1016/j.amc.2021.126898 doi: 10.1016/j.amc.2021.126898
|
| [38] |
N. Koksal, H. An, B. Fidan, Backstepping-based adaptive control of a quadrotor uav with guaranteed tracking performance, ISA T., 105 (2020), 98–110. http://dx.doi.org/10.1016/j.isatra.2020.06.006 doi: 10.1016/j.isatra.2020.06.006
|
| [39] |
K. Eliker, W. Zhang, Finite-time adaptive integral backstepping fast terminal sliding mode control application on quadrotor uav, Int. J. Control Autom. Syst., 18 (2020), 415–430. http://dx.doi.org/10.1007/s12555-019-0116-3 doi: 10.1007/s12555-019-0116-3
|
| [40] | F. Chen, L. Wen, K. Zhang, T. Gang, B. Jiang, A novel nonlinear resilient control for a quadrotor uav via backstepping control and nonlinear disturbance observer, Nonlinear Dynam., 85 (2016), 1281–1295. https://link.springer.com/article/10.1007/s11071-016-2760-y |






Figures(7)

Xia Song, Lihua Shen, Fuyang Chen. Adaptive backstepping position tracking control of quadrotor unmanned aerial vehicle system[J]. AIMS Mathematics, 2023, 8(7): 16191-16207. doi: 10.3934/math.2023828







 DownLoad:
DownLoad: