Citation: Windarto, Muhammad Altaf Khan, Fatmawati. Parameter estimation and fractional derivatives of dengue transmission model[J]. AIMS Mathematics, 2020, 5(3): 2758-2779. doi: 10.3934/math.2020178

| [1] | World Health Organization, Fact sheet on the Dengue and severe dengue, WHO, 2017. Available from: http://www.who.int/mediacentre/factsheets/fs117/en/. |
| [2] | World Health Organization, Global strategy for dengue prevention and control 2012-2020, WHO, 2012. Available from: http://www.who.int/denguecontrol/9789241504034/en/. |
| [3] | Health Office (Dinas Kesehatan) of the East Java, Dinas Kesehatan Provinsi Jawa Timur, Surabaya, Indonesia, 2009. |
| [4] | Ministry of Health Republic of Indonesia, Kementerian Kesehatan Republik Indonesia Jakarta, 2014. |
| [5] |
D. Aldila, T. Gotz, E. Soewono, An optimal control problem arising from a dengue disease transmission model, Math. Biosci., 242 (2013), 9-16. doi: 10.1016/j.mbs.2012.11.014

|
| [6] | H. Tasman, A. K. Supriatna, N. Nuraini, et al. A dengue vaccination model for immigrants in a two-age-class population, Int. J. Math., 2012 (2012), 1-15. |
| [7] |
J. P. Chavez, T. Gotz, S. Siegmund, et al. An SIR-Dengue transmission model with seasonal effects and impulsive control, Math. Biosci., 289 (2017), 29-39. doi: 10.1016/j.mbs.2017.04.005
|
| [8] |
A. Pandey, A. Mubayi, J. Medlock, Comparing vector-host and SIR models for dengue transmission, Math. Biosci., 246 (2013), 252-259. doi: 10.1016/j.mbs.2013.10.007
|
| [9] |
T. Gotz, N. Altmeier, W. Bock, et al. Modeling dengue data from Semarang, Indonesia, Ecol. Complex., 30 (2017), 57-62. doi: 10.1016/j.ecocom.2016.12.010
|
| [10] |
F. B. Agusto, M. A. Khan, Optimal control strategies for dengue transmission in pakistan, Math. Biosci., 305 (2018), 102-121. doi: 10.1016/j.mbs.2018.09.007
|
| [11] |
N. Tutkun, Parameter estimation in mathematical models using the real coded genetic algorithms, Expert Syst. Appl., 36 (2009), 3342-3345. doi: 10.1016/j.eswa.2008.01.060
|
| [12] | R. L. Haupt, S. E. Haupt, Practical Genetic Algorithms, Second Edition, John Wiley & Sons, 2004. |
| [13] |
W. B. Roush, S. L. Branton, A Comparison of fitting growth models with a genetic algorithm and nonlinear regression, Poultry Sci., 84 (2005), 494-502. doi: 10.1093/ps/84.3.494
|
| [14] | W. S. W. Indratno, N. Nuraini, E. Soewono, A comparison of binary and continuous genetic algorithm in parameter estimation of a logistic growth model, American Institute of Physics Conference Series, 1587 (2014), 139-142. |
| [15] | Windarto, An Implementation of continuous genetic algorithm in parameter estimation of predator-prey model, AIP Conference Proceedings, 2016. |
| [16] | D. Akman, O. Akman, E. Schaefer, Parameter Estimation in Ordinary Differential Equations Modeling via Particle Swarm Optimization, J. Appl. Math., 2018 (2018), 1-9. |
| [17] | Windarto, Eridani, U. D. Purwati, A comparison of continuous genetic algorithm and particle swarm optimization in parameter estimation of Gompertz growth model, AIP Conference Proceedings, 2084 (2019), 020017. |
| [18] | R. Eberhart, J. Kennedy, A new optimizer using particle swarm theory, Proceedings of the Sixth International Symposium on Micro Machine and Human Science, 1995. |
| [19] |
K. Diethelm, A fractional calculus based model for the simulation of an outbreak of dengue fever, Nonlinear Dyn., 71 (2013), 613-619. doi: 10.1007/s11071-012-0475-2
|
| [20] |
T. Sardar, S. Rana, J. Chattopadhyay, A mathematical model of dengue transmission with memory, Commun. Nonlinear Sci., 22 (2015), 511-525. doi: 10.1016/j.cnsns.2014.08.009
|
| [21] | M. A. Khan, S. Ullah, M. Farooq, A new fractional model for tuberculosis with relapse via Atangana-Baleanu derivative, Chaos, Solitons & Fractals, 116 (2018), 227-238. |
| [22] | S. Ullah, M. A. Khan, M. Farooq, Modeling and analysis of the fractional HBV model with Atangana-Baleanu derivative, The European Physical Journal Plus, 133 (2018), 313. |
| [23] | E. O. Alzahrani, M. A. Khan, Modeling the dynamics of Hepatitis E with optimal control, Chaos, Solitons & Fractals, 116 (2018), 287-301. |
| [24] | Fatmawati, E. M. Shaiful, M. I. Utoyo, A fractional order model for HIV dynamics in a two-sex population, Int. J. Math., 2018 (2018), 1-11. |
| [25] | Fatmawati, M. A. Khan, M. Azizah, et al. A fractional model for the dynamics of competition between commercial and rural banks in Indonesia, Chaos, Solitons & Fractals, 122 (2019), 32-46. |
| [26] |
A. Atangana, D. Baleanu, New fractional derivatives with nonlocal and non-singular kernel: theory and application to heat transfer model, Therm. Sci., 20 (2016), 763-769. doi: 10.2298/TSCI160111018A
|
| [27] | S. Qureshi, A. Atangana, Mathematical analysis of dengue fever outbreak by novel fractional operators with field data, Physica A, 526 (2019), 121127. |
| [28] | O. Diekmann, J. A. P. Heesterbeek, J. A. J. Metz, On the definition and the computation of the basic reproduction ratio R0 in models for infectious diseases in heterogenous populations, J. Math. Biol., 28 (1990), 362-382. |
| [29] | O. Diekmann, J. A. P. Heesterbeek, Mathematical Epidemiology of Infectious Diseases, Model Building, Analysis and Interpretation, John Wiley & Son, 2000. |
| [30] |
P. van den Driessche, J. Watmough, Reproduction numbers and sub-threshold endemic equilibria for compartmental models of disease transmition, Math. Biosci., 180 (2002), 29-48. doi: 10.1016/S0025-5564(02)00108-6
|
| [31] | Wikipedia contributors: East Java, Wikipedia. Available from: https://en.wikipedia.org/wiki/East-Java. |
| [32] | M. Toufik, A. Atangana, New numerical approximation of fractional derivative with non-local and non-singular kernel: application to chaotic models, Eur. Phys. J. Plus, 132 (2017), 444. |
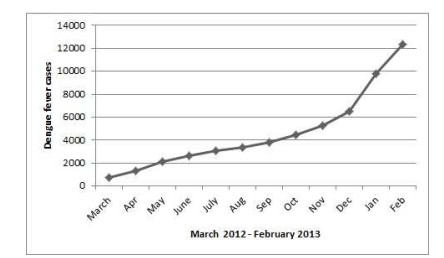
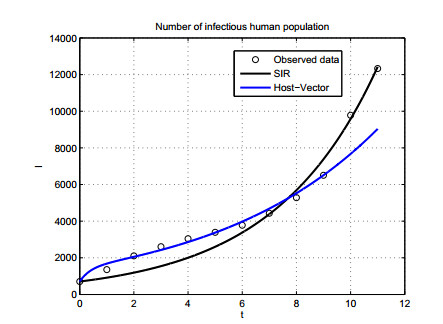
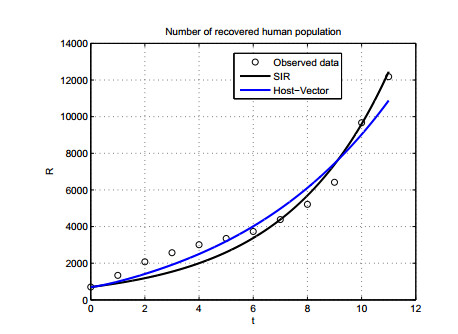
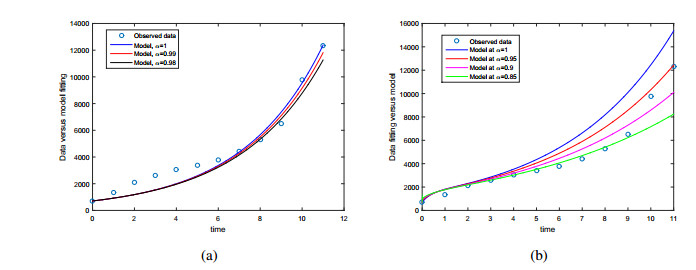
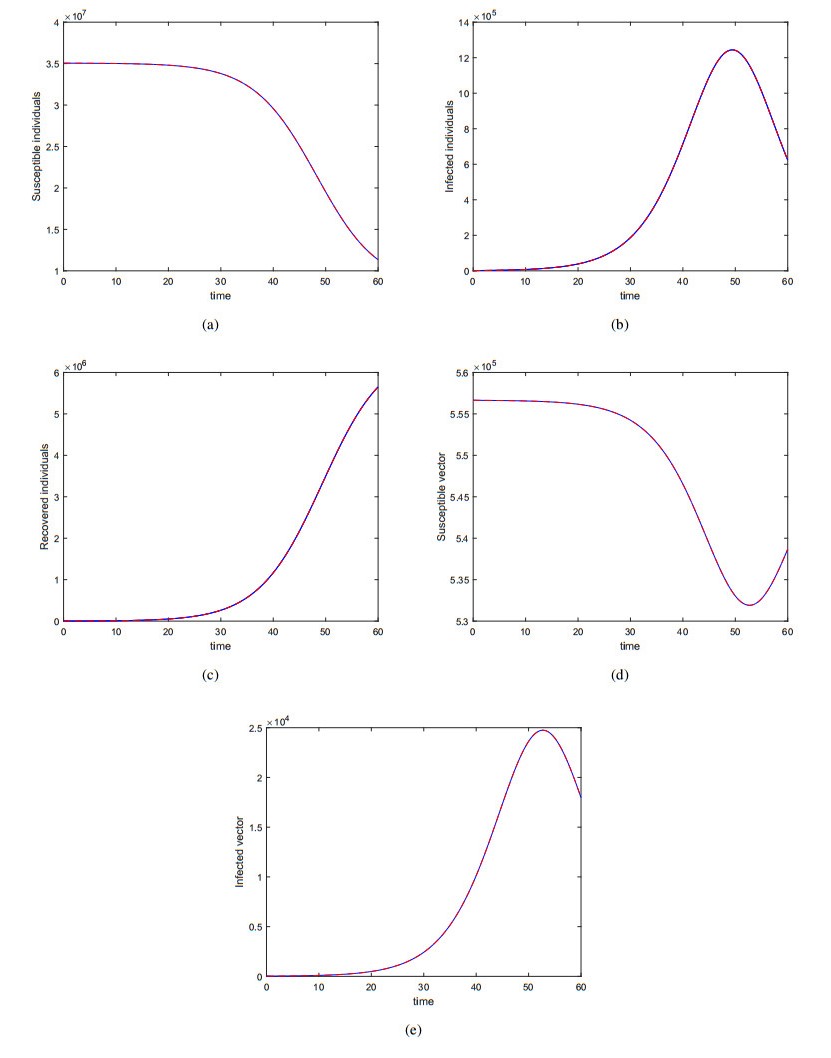
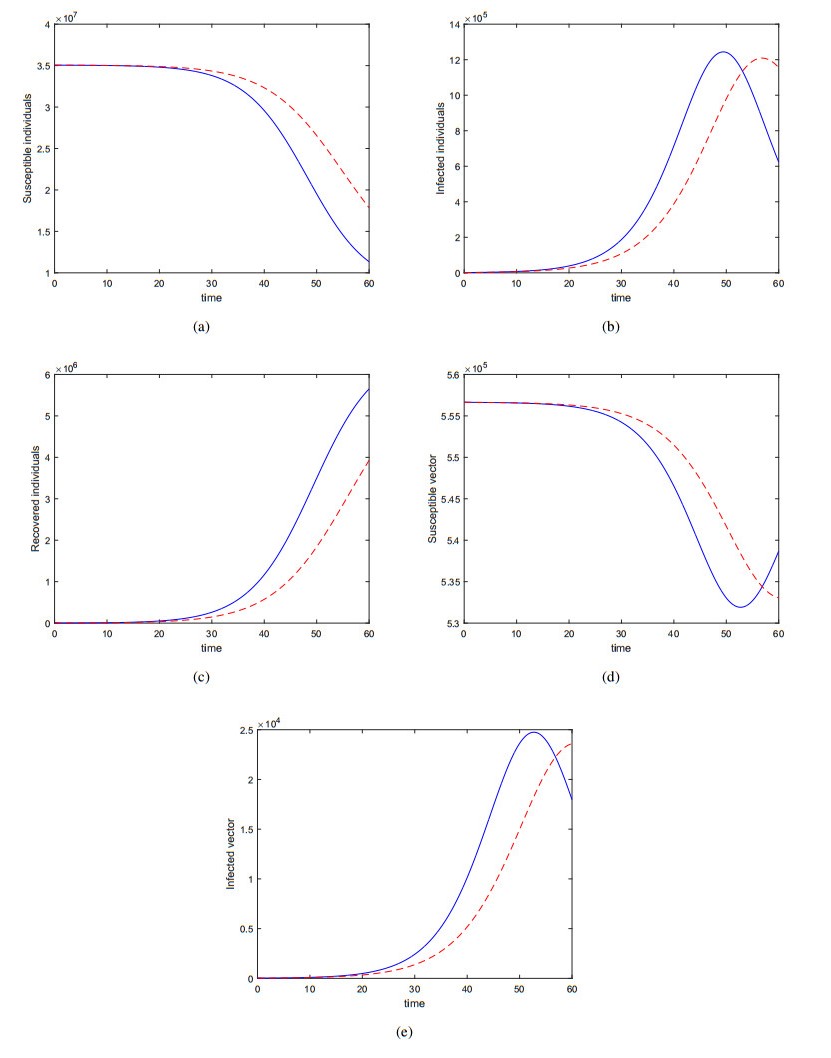
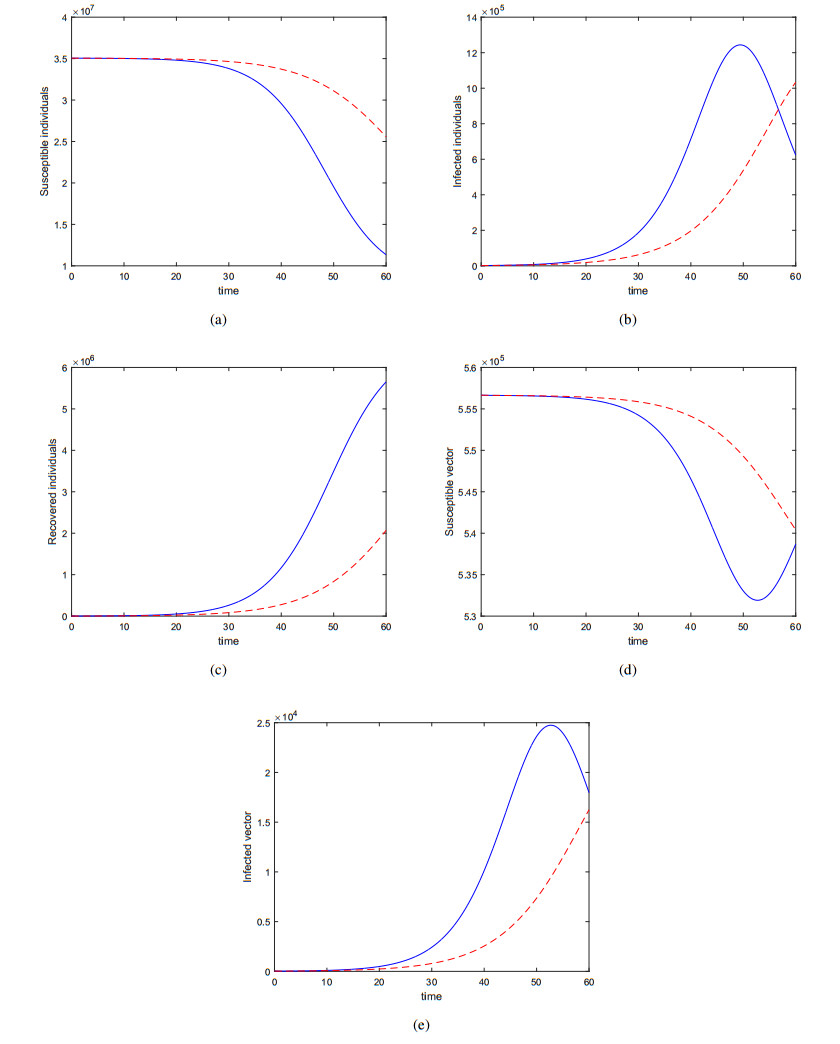
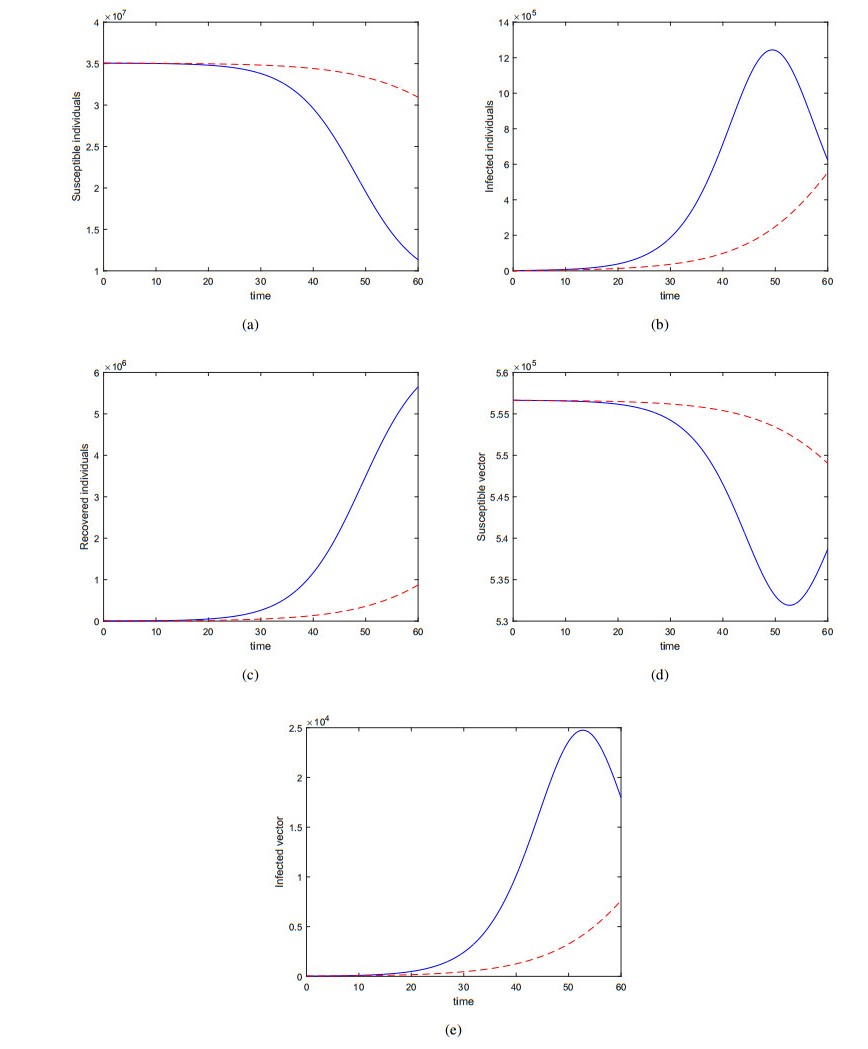
Figures(12) / Tables(3)

Windarto, Muhammad Altaf Khan, Fatmawati. Parameter estimation and fractional derivatives of dengue transmission model[J]. AIMS Mathematics, 2020, 5(3): 2758-2779. doi: 10.3934/math.2020178







 DownLoad:
DownLoad: