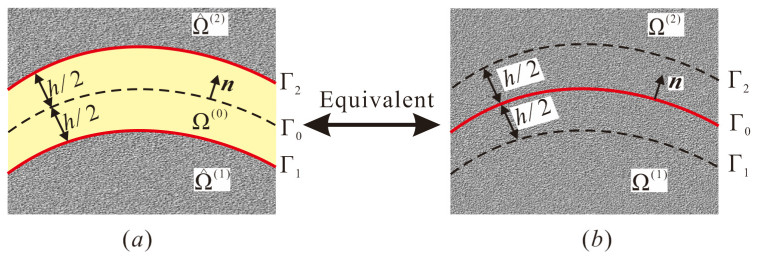
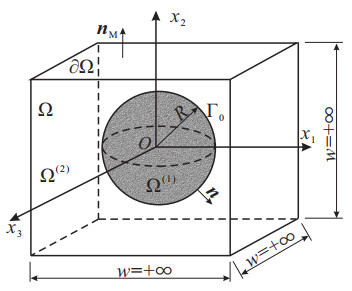
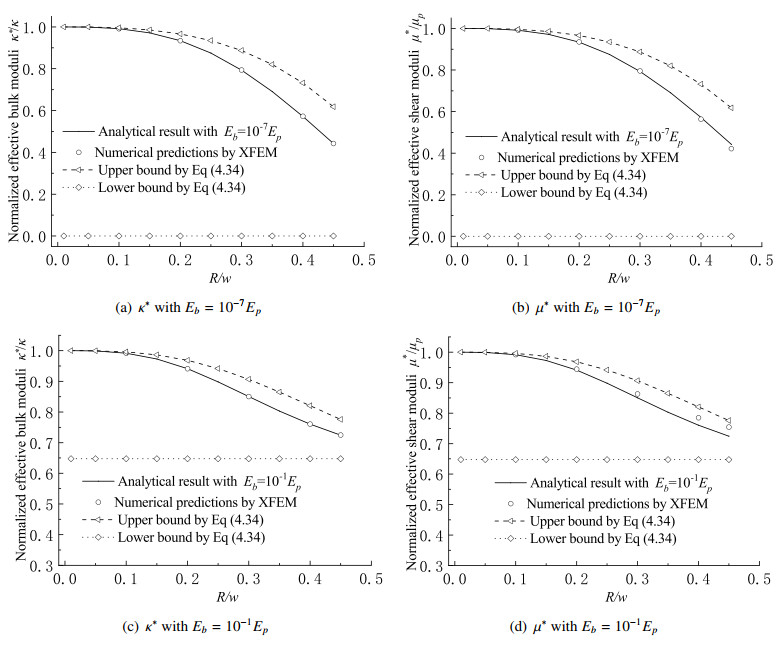
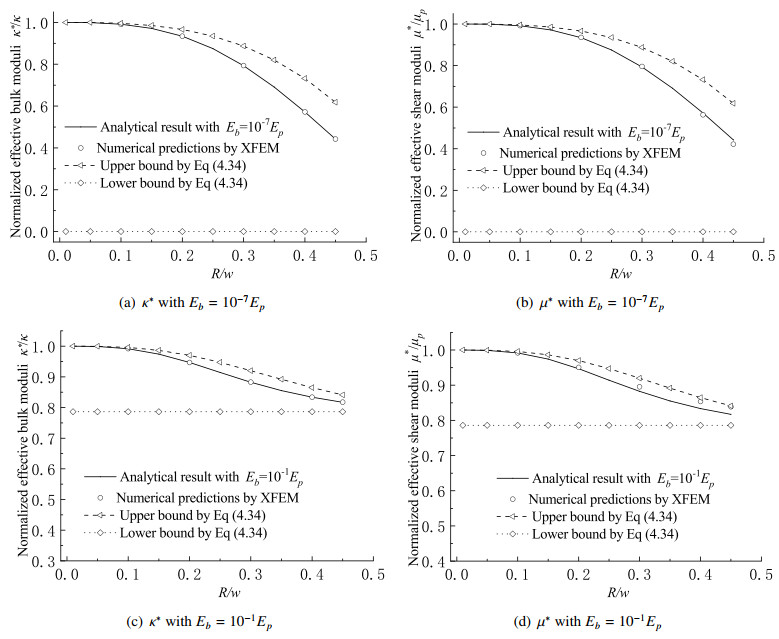
Binder interphases inside the highly filled polymer bonded explosives (PBXs) are irregularly distributed and extremely thin, but play an essential role in affecting the overall moduli and explosive performance of such heterogeneous media. In the present paper, a spring-type interface model, which was physically equivalent to these practical layers within a fixed error bound, was briefly derived, at first taking account of the fact that the stiffness of the binder material was much lower than that of the explosive crystals. Hereafter, a simplified PBX model consisting of a spherical explosive particle bonded to an infinite explosive matrix by the spring-type interface is designed, and its effective isotropic moduli were analytically determined via the generalized self-consistent scheme. The upper and lower bounds of these moduli were also derived based on the elasticity extremum principles of minimum potential and minimum complementary energies. These explicit expressions can be applied to predict the preliminary elastic properties of highly filled PBXs as benchmarks to validate numerical evaluations and so forth. Eventually, some discussions were made on the size-dependent effect of PBXs with the aid of the simplified model.
Citation: Jian-Tao Liu, Mei-Tong Fu. Theoretical modeling of thin binder interphases in highly filled PBX composites together with the closed form expression of the effective isotropic moduli of a simplified PBX model[J]. Electronic Research Archive, 2025, 33(2): 1045-1069. doi: 10.3934/era.2025047
Binder interphases inside the highly filled polymer bonded explosives (PBXs) are irregularly distributed and extremely thin, but play an essential role in affecting the overall moduli and explosive performance of such heterogeneous media. In the present paper, a spring-type interface model, which was physically equivalent to these practical layers within a fixed error bound, was briefly derived, at first taking account of the fact that the stiffness of the binder material was much lower than that of the explosive crystals. Hereafter, a simplified PBX model consisting of a spherical explosive particle bonded to an infinite explosive matrix by the spring-type interface is designed, and its effective isotropic moduli were analytically determined via the generalized self-consistent scheme. The upper and lower bounds of these moduli were also derived based on the elasticity extremum principles of minimum potential and minimum complementary energies. These explicit expressions can be applied to predict the preliminary elastic properties of highly filled PBXs as benchmarks to validate numerical evaluations and so forth. Eventually, some discussions were made on the size-dependent effect of PBXs with the aid of the simplified model.

| [1] |
Y. Q. Wu, F. L. Huang, A thermal-mechanical constitutive model for b-HMX single crystal and cohesive interface under dynamic high pressure loading, Sci. China Phys. Mech. Astron., 53 (2010), 218–226. https://doi.org/10.1007/s11433-009-0264-1 doi: 10.1007/s11433-009-0264-1

|
| [2] |
J. J. Xiao, W. R. Wang, J. Chen, G. F. Ji, W. Zhu, H. M. Xiao, Study on structure, sensitivity and mechanical properties of HMX and HMX-based PBXs with molecular dynamics simulation, Comput. Theor. Chem., 999 (2012), 21–27. https://doi.org/10.1016/j.comptc.2012.08.006 doi: 10.1016/j.comptc.2012.08.006
|
| [3] |
A. Elbeih, S. Zeman, M. Jungova, P. Vávra, Z. Akstein, Effect of different polymeric matrices on some properties of plastic bonded explosives, Propellants Explos. Pyrotech., 37 (2012), 676–684. https://doi.org/10.1002/prep.201200018 doi: 10.1002/prep.201200018
|
| [4] | K. D. Dai, Y. L. Liu, P. W. Chen, Y. Tian, Finite element simulation on effective elastic modulus of PBX explosives, Trans. Beijing Inst. Technol., 2012 (2012), 1154–1158. |
| [5] |
H. Tan, C. Liu, Y. Huang, P. H. Geubelle, The cohesive law for the particle/matrix interfaces in high explosives, J. Mech. Phys. Solids, 53 (2005), 1892–1917. https://doi.org/10.1016/j.jmps.2005.01.009 doi: 10.1016/j.jmps.2005.01.009
|
| [6] |
B. Banerjee, D. O. Adams, On predicting the effective elastic properties of polymer bonded explosives using the recursive cell method, Int. J. Solids Struct., 41 (2004), 481–509. https://doi.org/10.1016/j.ijsolstr.2003.09.016 doi: 10.1016/j.ijsolstr.2003.09.016
|
| [7] |
H. Tan, Y. Huang, C. Liu, P. H. Geubelle, The Mori-Tanaka method for composite materials with nonlinear interface debonding, Int. J. Plast., 21 (2005), 1890–1918. https://doi.org/10.1016/j.ijplas.2004.10.001 doi: 10.1016/j.ijplas.2004.10.001
|
| [8] |
P. J. Rae, H. T. Goldrein, S. J. P. Palmer, J. E. Field, A. L. Lewis, Quasi-static studies of the deformation and failure of $\beta$-HMX based polymer bonded explosives, Proc. R. Soc. London, Ser. A, 458 (2002), 743–762. https://doi.org/10.1098/rspa.2001.0894 doi: 10.1098/rspa.2001.0894
|
| [9] |
C. Hübner, E. Geibler, P. Elsner, P. Eyerer, The importance of micromechanical phenomena in energetic materials, Propellants Explos. Pyrotech., 24 (1999), 119–125. https://doi.org/10.1002/(SICI)1521-4087(199906)24:03<119::AID-PREP119>3.0.CO;2-G doi: 10.1002/(SICI)1521-4087(199906)24:03<119::AID-PREP119>3.0.CO;2-G
|
| [10] |
P. W. Chen, H. M. Xie, F. L. Huang, T. Huang, Y. S. Ding, Deformation and failure of polymer bonded explosives under diametric compression test, Polym. Test., 25 (2006), 333–341. https://doi.org/10.1016/j.polymertesting.2005.12.006 doi: 10.1016/j.polymertesting.2005.12.006
|
| [11] |
X. Q. Liu, P. J. Wei, Influences of interfacial damage on the effective wave velocity in composites with reinforced particles, Sci. China Ser. G: Phys. Mech. Astron., 51 (2008), 1126–1133. https://doi.org/10.1007/s11433-008-0094-6 doi: 10.1007/s11433-008-0094-6
|
| [12] |
R. L. Peeters, R. M. Hackett, Constitutive modeling of plastic-bonded explosives, Exp. Mech., 21 (1981), 111–116. https://doi.org/10.1007/BF02326367 doi: 10.1007/BF02326367
|
| [13] |
K. S. Yeom, S. Jeong, H. Hun, J. Park, New pseudo-elastic model for polymer-bonded explosive simulants considering the Mullins effect, J. Compos. Mater., 47 (2013), 3401–3411. https://doi.org/10.1177/0021998312466118 doi: 10.1177/0021998312466118
|
| [14] | J. Gao, Z. X. Huang, Parameter indentification for viscoelastic damage constitutive model of PBX (in Chinese), Eng. Mech., 30 (2013), 299–304. |
| [15] |
F. Saghir, S. Gohery, F. Mozafari, N. Moslemi, C. Burvill, A. Smith, et al., Mechanical characterization of particulated FRP composite pipes: A comprehensive experimental study, Polym. Test., 93 (2021), 1007001. https://doi.org/10.1016/j.polymertesting.2020.107001 doi: 10.1016/j.polymertesting.2020.107001
|
| [16] |
S. Gohery, S. Sharifi, C. Burvill, S. Mouloodi, M. Izadifar, P. Thissen, Localized failure analysis of internally pressurized laminated ellipsoidal woven GFRP composite domes: Analytical, numerical, and experimental studies, Arch. Civ. Mech. Eng., 19 (2019), 1235–1250. https://doi.org/10.1016/j.acme.2019.06.009 doi: 10.1016/j.acme.2019.06.009
|
| [17] |
Q. Z. Xia, Y. Q. Wu, F. L. Huang, Effect of interface behaviour on damage and instability of PBX under combined tension-shear loading, Def. Technol., 23 (2023), 137–151. https://doi.org/10.1016/j.dt.2022.01.010 doi: 10.1016/j.dt.2022.01.010
|
| [18] |
P. W. Chen, F. L. Huang, K. D. Dai, Y. S. Ding, Detection and characterization of long-pulse low-velocity impact damage in plastic bonded explosives, Int. J. Impact. Eng., 31 (2005), 497–508. https://doi.org/10.1016/j.ijimpeng.2004.01.008 doi: 10.1016/j.ijimpeng.2004.01.008
|
| [19] |
Z. W. Liu, H. M. Xie, K. X. Li, P. W. Chen, F. L. Huang, Fracture behavior of PBX simulation subject to combined thermal and mechanical loads, Polym. Test., 28 (2009), 627–635. https://doi.org/10.1016/j.polymertesting.2009.05.011 doi: 10.1016/j.polymertesting.2009.05.011
|
| [20] |
A. E. D. M. Heijden, Y. L. M. Creyghton, E. Marino, R. H. B. Bouma, G. J. H. G. Scholtes, W. Duvalois, et al., Energetic materials: Crystallization, characterization and insensitive plastic bonded explosives, Propellants Explos. Pyrotech., 33 (2008), 25–32. https://doi.org/10.1002/prep.200800204 doi: 10.1002/prep.200800204
|
| [21] |
Z. B. Zhou, P. W. Chen, F. L. Huang, S. Q. Liu, Experimental study on the micromechanical behavior of a PBX simulant using SEM and digital image correlation method, Opt. Lasers Eng., 49 (2011), 366–370. https://doi.org/10.1016/j.optlaseng.2010.11.001 doi: 10.1016/j.optlaseng.2010.11.001
|
| [22] |
W. Zhu, J. J. Xiao, W. H. Zhu, H. M. Xiao, Molecular dynamics simulations of RDX and RDX-based plastic-bonded explosives, J. Hazard. Mater., 164 (2009), 1082–1088. https://doi.org/10.1016/j.jhazmat.2008.09.021 doi: 10.1016/j.jhazmat.2008.09.021
|
| [23] |
L. Qiu, H. M. Xiao, Molecular dynamics study of binding energies, mechanical properties and detonation performance of bicyclo-HMX-based PBXs, J. Hazard. Mater., 164 (2009), 329–336. https://doi.org/10.1016/j.jhazmat.2008.08.030 doi: 10.1016/j.jhazmat.2008.08.030
|
| [24] |
M. M. Li, F. S. Li, R. Q. Shen, X. D. Guo, Molecular dynamics study of the structures and properties of RDX/GAP propellant, J. Hazard. Mater., 186 (2011), 2031–2036. https://doi.org/10.1016/j.jhazmat.2010.12.101 doi: 10.1016/j.jhazmat.2010.12.101
|
| [25] | B. Banerjee, D. O. Adams, Micormechanics-based prediction of thermoelastic properties of high energy materials, preprint, arXiv: 1201.2437. |
| [26] |
B. Banerjee, C. M. Cady, D. O. Adams, Micromechanics simulations of glass-estane mock polymer bonded explosives, Modell. Simul. Mater. Sci. Eng., 11 (2003), 457–475. https://doi.org/10.1088/0965-0393/11/4/304 doi: 10.1088/0965-0393/11/4/304
|
| [27] | B. Banerjee, Effective elastic moduli of polymer bonded explosives from finite element simulations, preprint, arXiv: cond-mat/0510367. |
| [28] |
H. Tan, Y. Huang, C. Liu, G. Ravichandran, G. H. Paulino, Constitutive behaviors of composites with interface debonding: the extended Mori-Tanaka method for uniaxial tension, Int. J. Fract., 146 (2007), 139–148. https://doi.org/10.1007/s10704-007-9155-5 doi: 10.1007/s10704-007-9155-5
|
| [29] |
A. Barua, M. Zhou, A Lagrangian framework for analyzing microstructural level response of polymer-bonded explosives, Modell. Simul. Mater. Sci. Eng., 19 (2011), 055001. https://doi.org/10.1088/0965-0393/19/5/055001 doi: 10.1088/0965-0393/19/5/055001
|
| [30] |
A. Barua, M. Zhou, Computational analysis of temperature rises in microstructures of HMX-Estane PBXs, Comput. Mech., 52 (2013), 151–159. https://doi.org/10.1007/s00466-012-0803-x doi: 10.1007/s00466-012-0803-x
|
| [31] |
Z. Hashin, Extremum principles for elastic heterogenous media with imperfect interfaces and their application to bounding of effective moduli, J. Mech. Phys. Solids, 40 (1992), 767–781. https://doi.org/10.1016/0022-5096(92)90003-K doi: 10.1016/0022-5096(92)90003-K
|
| [32] |
S. T. Gu, Q. C. He, Interfacial discontinuity relations for coupled multified phenomena and their application to the modeling of thin interphases as imperfect interface, J. Mech. Phys. Solids, 59 (2011), 1413–1426. https://doi.org/10.1016/j.jmps.2011.04.004 doi: 10.1016/j.jmps.2011.04.004
|
| [33] |
J. T. Liu, S. T. Gu, Q. C. He, A computational approach for evaluating the effective elastic moduli of non-spherical particle reinforced composites with interfacial displacement and traction jumps, Int. J. Multiscale Comput. Eng., 13 (2015), 123–143. https://doi.org/10.1615/INTJMULTCOMPENG.2014011640 doi: 10.1615/INTJMULTCOMPENG.2014011640
|
| [34] |
S. Gohery, M. Ahmed, Q. Q. Liang, T. Molla, M. Kajtaz, K. M. Tse, et al., Higher-order trigonometric series-based analytical solution to free transverse vibration of suspended laminated composite slabs, Eng. Struct., 296 (2023), 116902. https://doi.org/10.1016/j.engstruct.2023.116902 doi: 10.1016/j.engstruct.2023.116902
|
| [35] |
S. T. Gu, J. T. Liu, Q. C. He, Size-dependent effective elastic moduli of particulate composites with interfacial displacement and traction discontinuities, Int. J. Solids Struct., 51 (2014), 2283–2296. https://doi.org/10.1016/j.ijsolstr.2014.02.033 doi: 10.1016/j.ijsolstr.2014.02.033
|
| [36] |
Q. Z. Zhu, S. T. Gu, J. Yvonnet, J. F. Shao, Q. C. He, Three-dimensional numerical modelling by XFEM of spring-layer imperfect curved interfaces with applications to linearly elastic composite materials, Int. J. Numer. Mech. Eng., 88 (2011), 307–328. https://doi.org/10.1002/nme.3175 doi: 10.1002/nme.3175
|
| [37] |
H. L. Duan, X. Yi, Z. P. Huang, J. Wang, A unified scheme for prediction of effective moduli of multiphase composites with interface effects. Part Ⅰ: Theoretical framework, Mech. Mater., 39 (2007), 81–93. https://doi.org/10.1016/j.mechmat.2006.02.009 doi: 10.1016/j.mechmat.2006.02.009
|
| [38] |
H. L. Duan, J. Wang, Z. P. Huang, B. L. Karihaloo, Size-dependent effective elastic constants of solids containing nano-inhomogeneities with interface stress, J. Mech. Phys. Solids, 53 (2005), 1574–1596. https://doi.org/10.1016/j.jmps.2005.02.009 doi: 10.1016/j.jmps.2005.02.009
|
| [39] |
H. L. Duan, X. Yi, Z. P. Huang, J. Wang, A unified scheme for prediction of effective moduli of multiphase composites with interface effects. Part Ⅱ: Applicationa and scaling laws, Mech. Mater., 39 (2007), 94–103. https://doi.org/10.1016/j.mechmat.2006.02.010 doi: 10.1016/j.mechmat.2006.02.010
|
| [40] |
S. Nemat-Nasser, M. Lori, Micromechanics: Overall properties of heterogeneous materials, J. Appl. Mech., 63 (1996), 561. https://doi.org/10.1115/1.2788912 doi: 10.1115/1.2788912
|
| [41] |
R. M. Christensen, K. H. Lo, Solutions for effective shear properties in three phase sphere and cyliner models, J. Mech. Phys. Solids, 27 (1979), 315–330. https://doi.org/10.1016/0022-5096(79)90032-2 doi: 10.1016/0022-5096(79)90032-2
|
| [42] | J. H. Liu, S. J. Liu, M. Huang, H. Z. Li, F. D. Nie, Progress on crystal damage in pressed polymer bonded explosives (in Chinese), Energetic Mater., 21 (2013), 372–378. |


Figures(9) / Tables(1)
Jian-Tao Liu, Mei-Tong Fu. Theoretical modeling of thin binder interphases in highly filled PBX composites together with the closed form expression of the effective isotropic moduli of a simplified PBX model[J]. Electronic Research Archive, 2025, 33(2): 1045-1069. doi: 10.3934/era.2025047







 DownLoad:
DownLoad: