Citation: Vanessa Duarte Pinto, Catarina Martins, José Rodrigues, Manuela Pires Rosa. Improving access to greenspaces in the Mediterranean city of Faro[J]. AIMS Environmental Science, 2020, 7(3): 226-246. doi: 10.3934/environsci.2020014

| [1] | UN General Assembly. Transforming our world: From 2030 Agenda for Sustainable Development, 2015. Available from: https://www.refworld.org/docid/57b6e3e44.html. |
| [2] | World Health Organization (2016) Urban green spaces and health, a review of evidence. Copenhagen: WHO regional office for Europe. |
| [3] | European Communities (2000) Towards a local sustainability profile: European common indicators. In: Towards an urban atlas, Technical Report, Directorate-General for Environment, Luxembourg, European Commission. |
| [4] | Cavaco C, Vilares E, Rosa F, et al. (2015) The Portuguese Strategy for Sustainable Cities towards smarter urban development. GEOSPATIAL World Forum: Workshop Measuring Progress Achieving Smarter Cities. Available from: http://www.unece.org/fileadmin/DAM/hlm/prgm/urbandevt/Measuring_Progress__Achieving_Smarter_Cities_/Presentations/Cristina_Cavaco.pdf. |
| [5] | Fisher B, Costanza R, Turner K, et al. (2007) Defining and classifying ecosystem services for decision making. CSERGE, University of East Anglia, Norwich 07-04. |
| [6] | Millennium Ecosystem Assessment (2005) Ecosystems and Human Well-being: Synthesis. In: Island Press, Washington DC. |
| [7] |
Escobedo FJ, Varela S, Zhao M, et al. (2010) Analysing the efficacy of subtropical urban forests in offsetting carbon emissions from cities. Environ Sci Policy 13: 362-372. doi: 10.1016/j.envsci.2010.03.009

|
| [8] |
Gill S, Handley J, Ennos A, et al. (2007) Adapting cities for climate change: the role of the green infrastructure. Built Environ 33: 115-133. doi: 10.2148/benv.33.1.115
|
| [9] | Simpson JR, McPherson EG (1996) Potential of tree shade for reducing residential energy use in California. J Arboricult 22: 10-18. |
| [10] |
Comber A, Brunsdon C, Green E (2008) Using a GIS-based network analysis to determine urban greenspace accessibility for different ethnic and religious groups. Landsc Urban Plan 86: 103-114. doi: 10.1016/j.landurbplan.2008.01.002
|
| [11] | Handley J, Pauleit S, Slinn P, et al. (2003) Providing accessible natural greenspace in towns and cities: a practical guide to assessing the resource and implementing local standards for provision. Centre for Urban and Regional Ecology 1-36. |
| [12] | Maidstone Borough Council: Green and blue infrastructure strategy, 2016. Available from: http://www.maidstone.gov.uk/__data/assets/pdf_file/0004/164659/Green-and-Blue-Infrastructure-trategy-June-2016.pdf. |
| [13] |
Bowler DE, Buyung-Ali LM, Knight TM, et al. (2010) A systematic review of evidence for the added benefits to health of exposure to natural environments. BMC Public Health 10: 456. doi: 10.1186/1471-2458-10-456
|
| [14] | Thompson K, Coon JB, Stein K, et al. (2011) Does participating in physical activity in outdoor natural environments have a greater effect on physical and mental wellbeing than physical activity indoors? A systematic review. Environ Sc. Technol 45: 1761-1772. |
| [15] | de Vries S, Verheij R, Groenewegen P, et al. (2003) Natural environments-healthy environments? An exploratory analysis of the relationship between greenspace and health. Environ Plan A 35: 1717-173. |
| [16] |
Fuller R, Irvine K, Devine-Wright P, et al. (2007) Psychological benefits of greenspace increase with biodiversity. Biol Lett 3: 390-394. doi: 10.1098/rsbl.2007.0149
|
| [17] |
Owen N, Healy GN, Matthews CE, et al. (2010) Too much sitting: the population-health science of sedentary behavior. Exerc Sport Sci Rev 38: 105-113. doi: 10.1097/JES.0b013e3181e373a2
|
| [18] |
Li Q, Morimoto K, Kobayashi M (2008) Visiting a forest, but not a city, increases human natural killer activity and expression of anti-cancer proteins. Int J Immunopath Ph 21: 117-127. doi: 10.1177/039463200802100113
|
| [19] | Kuo M (2015) How might contact with nature promote human health? Promising mechanisms and a possible central pathway. Front Psych 25: 1093. |
| [20] |
Madureira H., Nunes F., Oliveira JV, et al. (2015) Urban residents' beliefs concerning green space benefits in four cities in France and Portugal. Urban Forest Urban Green 14: 56-64. doi: 10.1016/j.ufug.2014.11.008
|
| [21] | Sunyer J, Ballester F, Le Tetre A, et al. (2003) The association of daily sulfur dioxide air pollution levels with hospital admissions for cardiovascular diseases in Europe (The Aphea-II study). Eur Heart J 24 (8): 752-760. |
| [22] | Bernstein JA, Alexis N, Barnes C, et al. (2004) Health effects of air pollution. J Allergy Clin Inmun 114 (5): 1116-1123. |
| [23] |
Kim J, Kaplan R (2004) Physical and psychological factors in sense of community: new urbanist kentlands and nearby orchard village. Environ Behav 36: 313-340. doi: 10.1177/0013916503260236
|
| [24] |
Seeland K, Dubendorfer S, Hansmann R (2009) Making friends in Zurich's urban forests and parks: The role of public green space for social inclusion of youths from different cultures. Forest Policy Econ 11: 10-17. doi: 10.1016/j.forpol.2008.07.005
|
| [25] |
Mitchell R, Popham F (2008) Effect of exposure to natural environment on health inequalities: an observational population study. Lancet 372: 1655-1660. doi: 10.1016/S0140-6736(08)61689-X
|
| [26] |
Brown SC, Perrino T, Lombard J, et al. (2018) Health disparities in the relationship of neighborhood greenness to mental health outcomes in 249,405 U.S. Medicare beneficiaries. Int J Environ Res Public Health 15: 430. doi: 10.3390/ijerph15030430
|
| [27] |
James P, Banay RF, Hart JE, et al. (2015) A Review of the Health Benefits of Greenness. Curr Epidemiol Rep 2:131-142. doi: 10.1007/s40471-015-0043-7
|
| [28] |
van den Berg M, Wendel-Vos W, van Poppel M, et al. (2015) Health benefits of green spaces in the living environment: A systematic review of epidemiological studies. Urban Forest Urban Green 14: 806-816. doi: 10.1016/j.ufug.2015.07.008
|
| [29] |
Twohig-Bennett C, Jones A (2018) The health benefits of the great outdoors: A systematic review and meta-analysis of greenspace exposure and health outcomes. Environ Res 166: 628-637. doi: 10.1016/j.envres.2018.06.030
|
| [30] | Forsyth A, Musacchio L, Fitzgerald F (2005) Designing small parks: a manual for addressing social and ecological concerns, In: John Wiley & Sons, New Jersey. |
| [31] |
Berardi U, GhaffarianHoseini A, GhaffarianHoseini A (2014) State-of-the-art analysis of the environmental benefits of green roofs. Appl Energy 115: 411-428. doi: 10.1016/j.apenergy.2013.10.047
|
| [32] |
Emilsson T (2008) Vegetation development on extensive vegetated green roofs: influence of substrate composition, establishment method and species mix. Ecol Eng 33: 265-77. doi: 10.1016/j.ecoleng.2008.05.005
|
| [33] | Liu K, Baskaran B (2003) Thermal performance of green roofs through field evaluation. Proceedings of the First North American Green Roof Infrastructure Conference, Chicago, USA, May 29-30, 1-10. |
| [34] |
GhaffarianHoseini A, Dahlan N, Berardi U, et al. (2013) Sustainable energy performances of green buildings: a review of current theories, implementations and challenges. Renew Sustainable Energy Rev 25: 1-17. doi: 10.1016/j.rser.2013.01.010
|
| [35] |
Weng Q, Lu D, Schubring J (2004) Estimation of land surface temperature-vegetation abundance relationship for urban heat island studies. Remote Sens Environ 89: 467-83. doi: 10.1016/j.rse.2003.11.005
|
| [36] |
Bates A, Sadler J, Mackay R (2013) Vegetation development over four years on two green roofs in the UK. Urban Forest Urban Green 12: 98-108. doi: 10.1016/j.ufug.2012.12.003
|
| [37] | Baumann N (2006) Ground-nesting birds on green roofs in Switzerland: Preliminary observations. Urban Habitats 4 (1): 37-50. |
| [38] | Colla SR, Willis E, Packer L (2009) Can green roofs provide habitat for urban bees (Hymenoptera: Apidae)? CATE 2:1-12. |
| [39] |
MacIvor S, Lundholm J (2011) Insect species composition and diversity on intensive green roofs and adjacent level-ground habitats. Urban Ecosyst 14: 225-241. doi: 10.1007/s11252-010-0149-0
|
| [40] |
Kim KG (2004) The application of the biosphere reserve concept to urban areas: the case for green rooftops for habitat network in Seoul. Ann NY Acad Sci 1023: 187-214. doi: 10.1196/annals.1319.010
|
| [41] |
Ignatieva M, Stewart G, Meurk C (2011) Planning and design of ecological networks in urban areas. Landscape Ecol Eng 7: 17-25. doi: 10.1007/s11355-010-0143-y
|
| [42] |
Baldock K, Goddard M, Hicks D, et al. (2019) A systems approach reveals urban pollinator hotspots and conservation opportunities. Nat Ecol Evol 3: 363-373. doi: 10.1038/s41559-018-0769-y
|
| [43] |
Whittinghill L, Rowe D, Cregg B (2013) Evaluation of vegetable production on extensive green roofs. Agroecol Sust Food 37: 465-484. doi: 10.1080/21683565.2012.756847
|
| [44] | Dubbeling M, Renting H, Hoekstra F, et al. (2015) City Region Food Systems. Urban Agr Mag 29: 1-72. |
| [45] |
Mears M, Brindley P (2019) Measuring Urban Greenspace Distribution Equity: The Importance of Appropriate Methodological Approaches. Int J Geo-Inf 8: 286. doi: 10.3390/ijgi8060286
|
| [46] | VTPI, Accessibility evaluating peoples to reach desired goods, services and activities: From TDM Encyclopedia, Victoria Transport Policy Institute, 2017. Available from: http://www.vtpi.org/tdm/tdm84.htm. |
| [47] | Litman T (2017) Accessibility for transportation planning: Measuring people's ability to reach desired goods and activitie. TDM Encyclopedia, Victoria Transport Policy Institute. |
| [48] | Barton H, Davis G, Guise R (1995) Sustainable Settlements-a guide for planners, designers and developers, In: Bristol University of the West of England and The Local Government Management Board. |
| [49] |
Rioux L, Werner C, Mokounkolo R, et al. (2016) Walking in two French neighbourhoods: A study of how park numbers and locations relate to everyday walking. J Environ Psychol 48: 169-184. doi: 10.1016/j.jenvp.2016.10.003
|
| [50] |
Dai D (2011) Racial/ethnic and socioeconomic disparities in urban green space accessibility: Where to intervene? Landsc Urban Plan 102: 234-244. doi: 10.1016/j.landurbplan.2011.05.002
|
| [51] | Astell-Burt T, Feng X, Mavoa S, et al. (2014) Do low-income neighbourhoods have the least green space? A cross-sectional study of Australia's most populous cities. BMC Public Health 14: 292. |
| [52] |
Heckert M (2013) Access and equity in greenspace provision: A comparison of methods to assess the impacts of greening vacant land. Trans GIS 17: 808-827. doi: 10.1111/tgis.12000
|
| [53] |
Shen Y, Sun F, Che Y (2017) Public green spaces and human wellbeing: Mapping the spatial inequity and mismatching status of public green space in the Central City of Shanghai. Urban Forest Urban Green 27: 59-68. doi: 10.1016/j.ufug.2017.06.018
|
| [54] | Calthorpe P (1994) Shokokusya: The Next American Metropolis-Ecology, Community and the American Dream, In: Architectural Press, Princeton. |
| [55] | European Environment Agency (2002). Towards an urban atlas: Assessment of spatial data on 25 European cities and urban areas. In: Environmental issue report No 30/2002, Copenhagen. |
| [56] |
van Herzele A, Wiedemann T (2003) A monitoring tool for the provision of accessible and attractive urban green spaces. Landsc Urban Plan 63: 109-126. doi: 10.1016/S0169-2046(02)00192-5
|
| [57] | Natural England: From 'Nature Nearby' Accessible Natural Greenspace Guidance, 2010. Available from: http://www.ukmaburbanforum.co.uk/docunents/other/nature_nearby.pdf. |
| [58] | Barbosa O, Tratalos J, Armsworth P, et al. (2007) Who benefits from access to green space? A case study from Sheffield, UK. Landsc Urban Plan 83: 187-195. |
| [59] |
Higgs G, Fry R, Langford M (2012) Investigating the implications of using alternative GIS-based techniques to measure accessibility to green space. Environ Plann B: Planning and Design 39: 326-343. doi: 10.1068/b37130
|
| [60] |
Comber A, Brunsdon C, Green E (2008) Using a GIS-based network analysis to determine urban greenspace accessibility for different ethnic and religious groups. Landsc Urban 86: 103-114. doi: 10.1016/j.landurbplan.2008.01.002
|
| [61] |
Li L, Du Q, Ren F, et al. (2019) Assessing Spatial Accessibility to Hierarchical Urban Parks by Multi-Types of Travel Distance in Shenzhen, China. Int. J Environ Res Public Health 16: 1038. doi: 10.3390/ijerph16061038
|
| [62] |
Herman K, Sbarcea M, Panagopoulos T (2018) Creating Green Space Sustainability through Low-Budget and Upcycling Strategies. Sustainability 10: 1857. doi: 10.3390/su10061857
|
| [63] | Instituto Nacional de Estatística (INE): From Base Geográfica de Referenciação da Informação, 2011. Available from: http://mapas.ine.pt/download/index2011.phtml. |
| [64] | Figure 1 from: Map data copyrighted OpenStreetMap contributors. Available from: https://www.openstreetmap.org. |
| [65] | Alves R, Bento R, Ramos L, et al. (2015) Integração dos usos do solo e transportes em cidades de média dimensão (InLUT). In: Relatório final, Universidade de Trás-os-Montes e Alto douro, Faculdade de Arquitectura da Universidade técnica de Lisboa e Universidade do Algarve. |
| [66] | Rosa MP, Martins C, Rodrigues J (2017) The development of indicators of sustainable mobility associated with an urbanism of proximity. The Case of the City of Faro. In: INCREaSE, Proceedings of the International Congress on Engineering and Sustainability, Faro, Portugal, Springer 47-66. |
| [67] |
Berte E, Panagopoulos T (2014) Enhancing city resilience to climate change by means of ecosystem services improvement: A SWOT analysis for the city of Faro, Portugal. Int J Urban Sust Dev 6: 241-253. doi: 10.1080/19463138.2014.953536
|
| [68] | Santos A, Terremoto R, Brito J, et al. (2008) Plano Verde de Faro-Princípios, Objectivos e Conteúdo. Câmara Municipal de Faro e Gabinete de Apoio Técnico de Faro. |
| [69] | Guimarães ET, Bragança L, Almeida MG, et al. (2015) Analysis of Portuguese Residential Building and Proposed Solutions, Connecting People and Ideas. In: Proceedings of EURO ELECS, Guimarães, Portugal. |
| [70] | Noocity: Urban Ecology. Available from: https://www.noocity.com/pt-pt/#. |
| [71] | Huang R, Hawley D (2009) A data model and internet GIS framework for safe routes to school. URISA J 21: 21-30. |
| [72] | Salvo G, Sabatini S (2014) Advanced or and AI methods in transportation a Gis approach to evaluate bus stop accessibility. Available from: http://www.iasi.cnr.it/ewgt/16conference/ID108.pdf. |
| [73] | Scheurer J, Curtis C (2007) Accessibility measures: Overview and practical applications. Urbanet Department of Urban and Regional Planning, Curtin University. |
| [74] | Geurs K, Ritsema van Eck J (2001) Accessibility measures: review and applications, evaluation of accessibility impacts of land-use transport scenarios and related social and economic impacts. Rese Man Environ 408505 006. |
| [75] | Achuthan K, Titheridge H, Mackett RL (2007) Measuring pedestrian accessibility. In: Winstanley, Proceedings of the Geographical Information Science Research, National University of Ireland, Maynooth, UK, vol. 11-13, 264-269. |
| [76] |
Bhatti M, Church A (2004) Home the culture of nature and meanings of gardens in late modernity. Housing Studies 19: 37-51. doi: 10.1080/0267303042000152168
|
| [77] |
Coolen H, Meesters J (2012) Private and public green spaces: meaningful but different settings. J Hous Built Environ 27:49-67. doi: 10.1007/s10901-011-9246-5
|
| [78] | Boumeester HJFM, Dol K., Meesters J (2009) Stedelijk wonen: een brug tussen wens en werkelijkheid. Een onderzoek naar woonwensen en woonproducten bij binnenstedelijk bouwen (Urban living: bridging preferences and reality. Housing preference and housing products for urban development). Voorburg: NVB. |
| [79] | Bernardini C, Irvine KN (2007) The 'nature' of urban sustainability: private or public green spaces. In: A. Kungolas, C. A. Brebbia, & E. Beriatos, (Eds.), Sustainable development and planning III, volume 2, WIT Press: 661-674. |
| [80] |
Russo A, Cirella G (2018) Modern Compact Cities: How Much Greenery Do We Need? Int J Environ Res Public Health 15: 2180. doi: 10.3390/ijerph15102180
|
| [81] |
Oliver LN, Schuurman N, Hall AW (2007) Comparing circular and network buffers to examine the influence of land use on walking for leisure and errands. Int J Health Geograph 6: 41. doi: 10.1186/1476-072X-6-41
|
| [82] | Lyytimäki J, Petersen LK, Normander B, et al. (2008) Nature as a nuisance? Ecosystem services and disservices to urban lifestyle. J Environ Sci 5 (3): 161-172. |





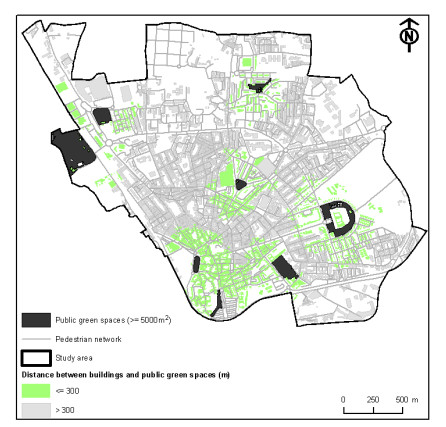
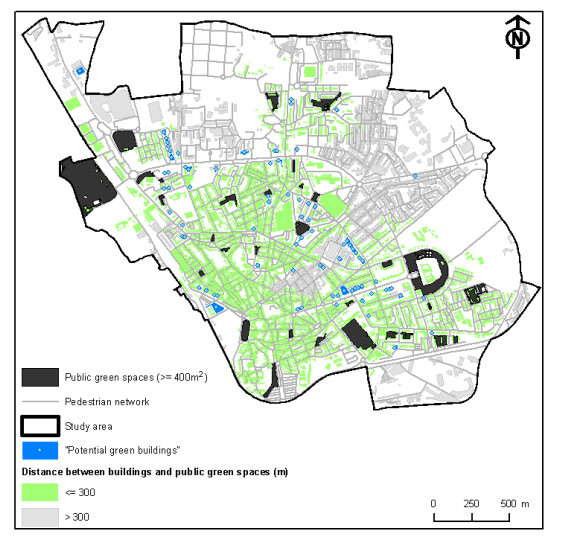
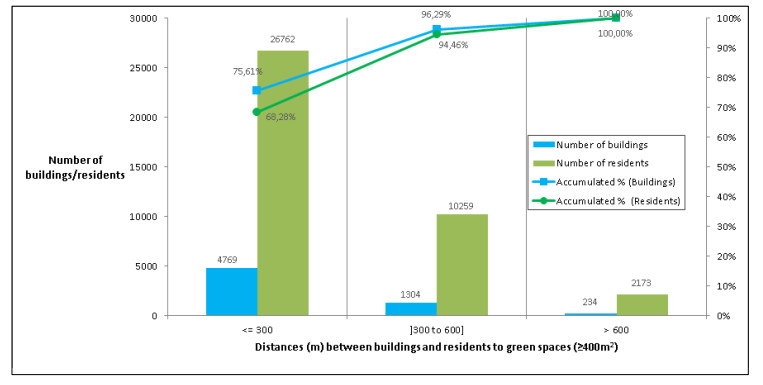
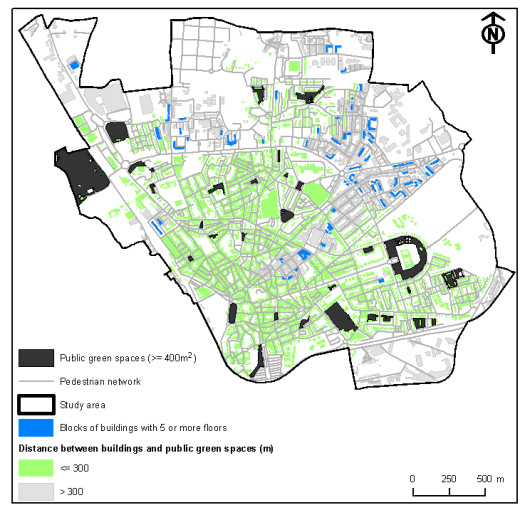
Figures(10) / Tables(2)

Vanessa Duarte Pinto, Catarina Martins, José Rodrigues, Manuela Pires Rosa. Improving access to greenspaces in the Mediterranean city of Faro[J]. AIMS Environmental Science, 2020, 7(3): 226-246. doi: 10.3934/environsci.2020014







 DownLoad:
DownLoad: