Citation: Joseph A. Kazery, Dayakar P. Nittala, H. Anwar Ahmad. Meteorological effects on trace element solubility in Mississippi coastal wetlands[J]. AIMS Environmental Science, 2019, 6(1): 1-13. doi: 10.3934/environsci.2019.1.1

| [1] | Shervette V (2006) Assessment of Estuarine Habitats for Resident and Estuarine-dependent Species: Tools for Conservation and Management. PhD diss., Texas A & M University, 1–187. |
| [2] | Paalman MAA (1997) Processes affecting the distribution and speciation of heavy metals in the Rhine/Meuse Estuary. Published by Utrecht University, 148: 1–149. |
| [3] |
Mok JS, Kwon JY, Son KT, et al. (2014) Contents and Risk Assessment of Heavy Metals in Marine Invertebrates from Korean Coastal Fish Markets. J Food Protect 77: 1022–1030. doi: 10.4315/0362-028X.JFP-13-485

|
| [4] |
Tabelin CB, Igarashi T, Villacorte-Tabelin M, et al. (2018) Arsenic, selenium, boron, lead, cadmium, copper, and zinc in naturally contaminated rocks: A review of their sources, modes of enrichment, mechanisms of release, and mitigation strategies. Sci Total Environ 645: 1522–1553. doi: 10.1016/j.scitotenv.2018.07.103
|
| [5] |
Whalley C, Rowlatt S, Bennett M, et al. (1999) Total Arsenic in Sediments from the Western North Sea and the Humber Estuary. Mar Pollut Bull 38: 394–400. doi: 10.1016/S0025-326X(98)00158-1
|
| [6] |
Xie X, Wang Y, Ellis A, et al. (2011) The sources of geogenic arsenic in aquifers at Datong basin, northern China: Constraints from isotopic and geochemical data. J Geochem Explor 110: 155–166. doi: 10.1016/j.gexplo.2011.05.006
|
| [7] |
Sun Z, Mou X, Tong C, et al. (2015) Spatial variations and bioaccumulation of heavy metals in intertidal zone of the Yellow River estuary, China. Catena 126: 43–52. doi: 10.1016/j.catena.2014.10.037
|
| [8] | Peterson M, Waggy G, Woodrey M, et al. (2007) Grand Bay national estuarine research reserve: An ecological characterization. Moss Point, Mississippi. Silver Spring, MD 20910, 1–268. |
| [9] |
McComb JQ, Han FX, Rogers C, et al. (2015) Trace elements and heavy metals in the Grand Bay National Estuarine Reserve in the northern Gulf of Mexico. Mar Pollut Bull 99: 61–69. doi: 10.1016/j.marpolbul.2015.07.062
|
| [10] |
Reiman JH, Xu YJ, He S, et al. (2018) Metals geochemistry and mass export from the Mississippi-Atchafalaya River system to the Northern Gulf of Mexico. Chemosphere 205: 559–569. doi: 10.1016/j.chemosphere.2018.04.094
|
| [11] |
Hu XF, Jiang Y, Shu Y, et al. (2014) Effects of mining wastewater discharges on heavy metal pollution and soil enzyme activity of the paddy fields. J Geochem Explor 147: 139–150. doi: 10.1016/j.gexplo.2014.08.001
|
| [12] |
Du Laing G, Vandecasteele B, De Grauwe P, et al. (2007) Factors affecting metal concentrations in the upper sediment layer of intertidal reedbeds along the river Scheldt. J Environ Monitor 9: 449–455. doi: 10.1039/b618772b
|
| [13] |
Du Laing G, Meers E, Dewispelaere M, et al. (2009) Heavy metal mobility in intertidal sediments of the Scheldt estuary: Field monitoring. Sci Total Environ 407: 2919–2930. doi: 10.1016/j.scitotenv.2008.12.024
|
| [14] |
Hatje V, Payne TE, Hill DM, et al. (2003) Kinetics of trace element uptake and release by particles in estuarine waters: Effects of pH, salinity, and particle loading. Environ Int 29: 619–629. doi: 10.1016/S0160-4120(03)00049-7
|
| [15] | Turner A (2000) Trace Metal Contamination in Sediments from U.K. Estuaries: An Empirical Evaluation of the Role of Hydrous Iron and Manganese Oxides. Estuar Coast Shelf Sci 50: 355–371. |
| [16] |
Ouddane B, Skiker M, Fischer JC, et al. (1999) Distribution of iron and manganese in the Seine river estuary: Approach with experimental laboratory mixing. J Environ Monitor 1: 489–496. doi: 10.1039/a903721g
|
| [17] |
Wong VNL, Johnston SG, Burton ED, et al. (2010) Seawater causes rapid trace metal mobilisation in coastal lowland acid sulfate soils: Implications of sea level rise for water quality. Geoderma 160: 252–263. doi: 10.1016/j.geoderma.2010.10.002
|
| [18] |
Charters FJ, Cochrane TA, O'Sullivan AD (2016) Untreated runoff quality from roof and road surfaces in a low intensity rainfall climate. Sci Total Environ 550: 265–272. doi: 10.1016/j.scitotenv.2016.01.093
|
| [19] |
Nordstrom DK (2009) Acid rock drainage and climate change. J Geochem Explor 100: 97–104. doi: 10.1016/j.gexplo.2008.08.002
|
| [20] |
Shehane SD, Harwood VJ, Whitlock JE, et al. (2005) The influence of rainfall on the incidence of microbial faecal indicators and the dominant sources of faecal pollution in a Florida river. J Appl Microbiol 98: 1127–1136. doi: 10.1111/j.1365-2672.2005.02554.x
|
| [21] | Alloway BJ, (2013) Sources of Heavy Metals and Metalloids in Soils, In: Alloway BJ, editor. Dordrecht: Springer Netherlands, 11–50. |
| [22] |
Mearns LO, Giorgi F, McDaniel L, et al. (1995) Analysis of daily variability of precipitation in a nested regional climate model: Comparison with observations and doubled CO2 results. Global Planet Change 10: 55–78. doi: 10.1016/0921-8181(94)00020-E
|
| [23] |
Hatje V, Birch GF, Hill DM (2001) Spatial and Temporal Variability of Particulate Trace Metals in Port Jackson Estuary, Australia. Estuarine Coastal Shelf Sci 53: 63–77. doi: 10.1006/ecss.2001.0792
|
| [24] |
Katz RW (1983) Statistical Procedures for Making Inferences about Precipitation Changes Simulated by an Atmospheric General Circulation Model. J Atmos Sci 40: 2193–2201. doi: 10.1175/1520-0469(1983)040<2193:SPFMIA>2.0.CO;2
|
| [25] |
Ragosta M, Caggiano R, D'Emilio M, et al. (2002) Source origin and parameters influencing levels of heavy metals in TSP, in an industrial background area of Southern Italy. Atmos Environ 36: 3071–3087. doi: 10.1016/S1352-2310(02)00264-9
|
| [26] |
Chuan MC, Shu GY, Liu JC (1996) Solubility of heavy metals in a contaminated soil: Effects of redox potential and pH. Water Air Soil Pollut 90: 543–556. doi: 10.1007/BF00282668
|
| [27] |
Huerta-Diaz MA, Tessier A, Carignan R (1998) Geochemistry of trace metals associated with reduced sulfur in freshwater sediments. Appl Geochem 13: 213–233. doi: 10.1016/S0883-2927(97)00060-7
|
| [28] | Byrnes MR, Davis JRA, Kennicutt IIMC, et al. (2017) Habitats and Biota of the Gulf of Mexico: Before the Deepwater Horizon Oil Spill. Volume 1: Water Quality, Sediments, Sediment Co ntaminants, Oil and Gas Seeps, Coastal Habitats, Offshore Plankton and Benthos, and Shellfish. 948. |
| [29] | Ideriah TJK, Ikpe FN, Nwanjoku FN (2013) Distribution and Speciation of Heavy Metals in Crude Oil Contaminated Soils from Niger Delta, Nigeria. World Environ 3: 18–28. |
| [30] |
Stephens SR, Alloway BJ, Parker A, et al. (2001) Changes in the leachability of metals from dredged canal sediments during drying and oxidation. Environ Pollut 114: 407–413. doi: 10.1016/S0269-7491(00)00231-1
|
| [31] |
Church TM, Bernat M, Sharma P (1986) Distribution of natural uranium, thorium, lead, and polonium radionuclides in tidal phases of a Delaware salt marsh. Estuaries 9: 2–8. doi: 10.2307/1352187
|
| [32] |
Li QS, Liu YN, Du YF, et al. (2011) The behavior of heavy metals in tidal flat sediments during fresh water leaching. Chemosphere 82: 834–838. doi: 10.1016/j.chemosphere.2010.11.026
|
| [33] |
Peterson ML, Carpenter R (1986) Arsenic distributions in porewaters and sediments of Puget Sound, Lake Washington, the Washington coast and Saanich Inlet, B.C. Geochim Cosmochim Ac 50: 353–369. doi: 10.1016/0016-7037(86)90189-4
|
| [34] | Chu B, Chen X, Li Q, et al. (2014) Effects of salinity on the transformation of heavy metals in tropical estuary wetland soil. Chem Ecol 31: 186–198. |
| [35] |
Charlatchka R, Cambier P (2000) Influence of reducing conditions on solubility of trace metals in contaminated soils. Water Air Soil Pollut 118: 143–168. doi: 10.1023/A:1005195920876
|
| [36] |
Du Laing G, De Vos R, Vandecasteele B, et al. (2008) Effect of salinity on heavy metal mobility and availability in intertidal sediments of the Scheldt estuary. Estuar Coast Shelf Sci 77: 589–602. doi: 10.1016/j.ecss.2007.10.017
|
| [37] |
Acosta JA, Jansen B, Kalbitz K, et al. (2011) Salinity increases mobility of heavy metals in soils. Chemosphere 85: 1318–1324. doi: 10.1016/j.chemosphere.2011.07.046
|
| [38] | Millward GE, Liu YP (2003) Modelling metal desorption kinetics in estuaries. Sci Total Environ 314–316: 613–623. |
| [39] |
Mearns LO, Giorgi F, McDaniel L, et al. (1995) Analysis of daily variability of precipitation in a nested regional climate model: Comparison with observations and doubled CO2 results. Global Planet Change 10: 55–78. doi: 10.1016/0921-8181(94)00020-E
|
| [40] |
Kraepiel AML, Chiffoleau JF, Martin JM, et al. (1997) Geochemistry of trace metals in the Gironde estuary. Geochim Cosmochim Ac 61: 1421–1436. doi: 10.1016/S0016-7037(97)00016-1
|
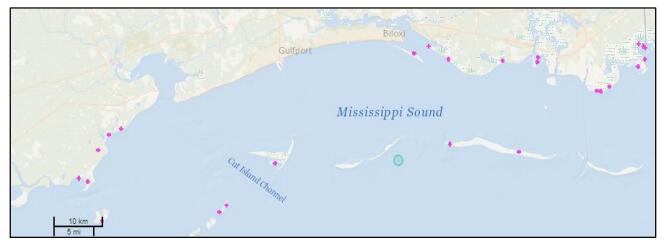
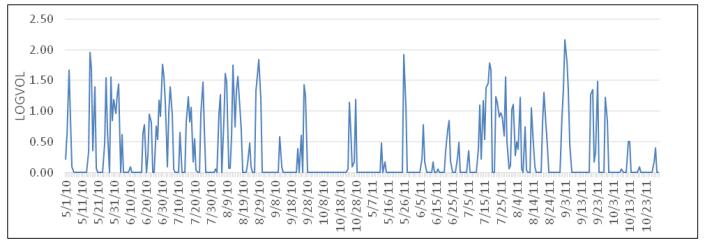
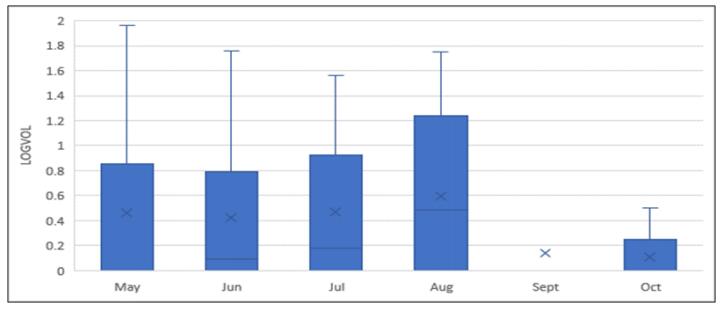
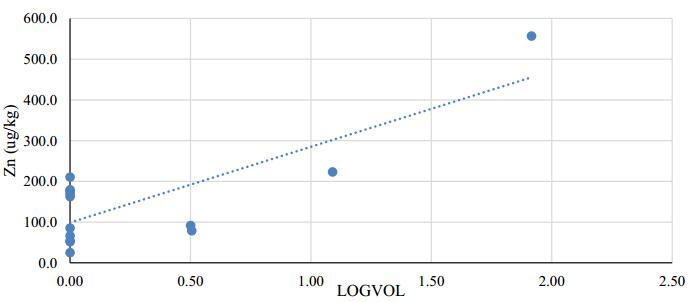
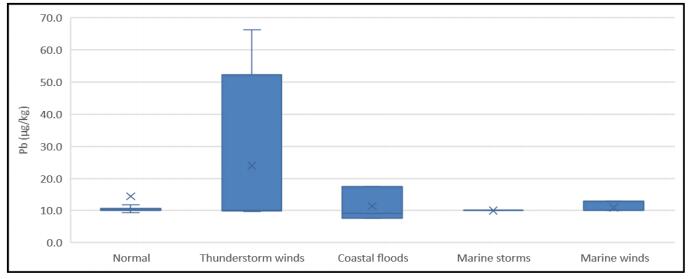
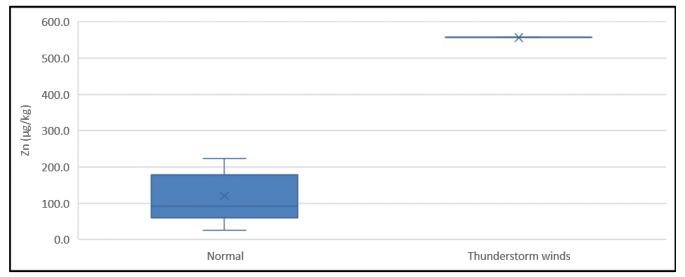
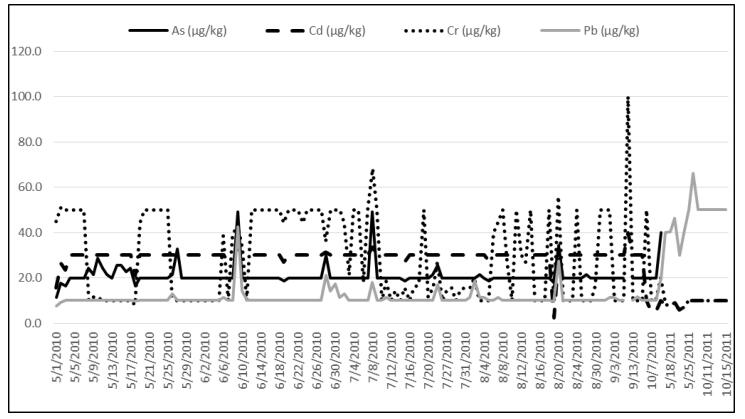
Figures(11)

Joseph A. Kazery, Dayakar P. Nittala, H. Anwar Ahmad. Meteorological effects on trace element solubility in Mississippi coastal wetlands[J]. AIMS Environmental Science, 2019, 6(1): 1-13. doi: 10.3934/environsci.2019.1.1







 DownLoad:
DownLoad: