The continuous increase of energy consumption resulted in the unavoidable increase in demand for renewable energy (RE) investment projects in recent years. Although the necessity of developing alternative energy sources is clear, the government cannot afford the huge investment in RE investment projects without private sector participation. Therefore, analyzing the decision-making procedure from the investor's point of view is essential to improve this process. Numerous studies in the literature developed various multi-criteria decision-making approaches using expert's judgments to provide informed decisions on RE investment projects. While prior efforts are valuable, accounting heterogeneity impact with regard to experts' background and knowledge on results has not been examined. Therefore, this study aims to develop a modified decision-making approach in RE projects using an analytical hierarchy process to: (1) provide a comprehensive review of investors criteria in RE projects; (2) evaluate how the level of expertise of experts in RE subject has an impact on the achieved common solution; and (3) determine the best RE alternative in different scenarios. Then, Iran, as a case study is selected to illustrate the model practicability. The results indicate that those who have higher expertise in the subject are more concerned about the "consumption market", and "government supportive policies". Whereas economic factors remain the most challenging criteria in less expert participation views. Both groups chose 'wind energy' as the best alternative energy source for investment based on current Iran's energy market. It is anticipated that the developed methodology and its results can be used by (1) government and public agencies to understand the investors' concerns; (2) investors to make a more-informed risk-based decision in RE projects or other complex decision-making projects.
Citation: Abdolmajid Erfani, Mehdi Tavakolan, Ali Hassandokht Mashhadi, Pouria Mohammadi. Heterogeneous or homogeneous? A modified decision-making approach in renewable energy investment projects[J]. AIMS Energy, 2021, 9(3): 558-580. doi: 10.3934/energy.2021027
The continuous increase of energy consumption resulted in the unavoidable increase in demand for renewable energy (RE) investment projects in recent years. Although the necessity of developing alternative energy sources is clear, the government cannot afford the huge investment in RE investment projects without private sector participation. Therefore, analyzing the decision-making procedure from the investor's point of view is essential to improve this process. Numerous studies in the literature developed various multi-criteria decision-making approaches using expert's judgments to provide informed decisions on RE investment projects. While prior efforts are valuable, accounting heterogeneity impact with regard to experts' background and knowledge on results has not been examined. Therefore, this study aims to develop a modified decision-making approach in RE projects using an analytical hierarchy process to: (1) provide a comprehensive review of investors criteria in RE projects; (2) evaluate how the level of expertise of experts in RE subject has an impact on the achieved common solution; and (3) determine the best RE alternative in different scenarios. Then, Iran, as a case study is selected to illustrate the model practicability. The results indicate that those who have higher expertise in the subject are more concerned about the "consumption market", and "government supportive policies". Whereas economic factors remain the most challenging criteria in less expert participation views. Both groups chose 'wind energy' as the best alternative energy source for investment based on current Iran's energy market. It is anticipated that the developed methodology and its results can be used by (1) government and public agencies to understand the investors' concerns; (2) investors to make a more-informed risk-based decision in RE projects or other complex decision-making projects.

| [1] |
Heravi G, Salehi MM, Rostami M (2020) Identifying cost-optimal options for a typical residential nearly zero energy building's design in developing countries. Clean Technol Environ Policy 22: 2107-2128. doi: 10.1007/s10098-020-01962-4

|
| [2] |
Hansen K, Breyer C, Lund H (2019) Status and perspectives on 100% renewable energy systems. Energy 175: 471-480. doi: 10.1016/j.energy.2019.03.092
|
| [3] |
Houri Jafari H, Vakili A, Eshraghi H, et al. (2016) Energy planning and policy making; The case study of Iran. Energy Sources, Part B: Econ, Plann, Policy 11: 682-689. doi: 10.1080/15567249.2012.741186
|
| [4] |
Gabbar HA, Eldessouky A, Runge J (2016) Evaluation of renewable energy deployment scenarios for building energy management. AIMS Energy 4: 742-761. doi: 10.3934/energy.2016.5.742
|
| [5] |
Saeed T, Tularam GA (2017) Relations between fossil fuel returns and climate change variables using canonical correlation analysis. Energy Sources, Part B: Econ, Plann, Policy 12: 675-684. doi: 10.1080/15567249.2016.1265615
|
| [6] |
Kim SB, Cho JH (2014) A study on forecasting green infrastructure construction market. KSCE J Civ Eng 18: 430-443. doi: 10.1007/s12205-014-0189-8
|
| [7] |
Hailu AD, Kumsa DK (2021) Ethiopia renewable energy potentials and current state. AIMS Energy 9: 1-14. doi: 10.3934/energy.2021001
|
| [8] |
Kahia M, Jebli MB, Belloumi M (2019) Analysis of the impact of renewable energy consumption and economic growth on carbon dioxide emissions in 12 MENA countries. Clean Technol Environ Policy 21: 871-885. doi: 10.1007/s10098-019-01676-2
|
| [9] | Alizadeh R, Maknoon R, Majidpour M (2014) Clean Development Mechanism, a bridge to mitigate the Greenhouse Gasses: is it broken in Iran. 13th International Conference on Clean Energy (ICCE): 399-404. |
| [10] | Asutosh AT, Woo J, Kouhirostami M, et al. (2020) Renewable energy industry trends and its contributions to the development of energy resilience in an era of accelerating climate change. Int J Energy Power Eng 14: 233-240. |
| [11] |
Brockway PE, Owen A, Brand-Correa LI, et al. (2019) Estimation of global final-stage energy-return-on-investment for fossil fuels with comparison to renewable energy sources. Nat Energy 4: 612-621. doi: 10.1038/s41560-019-0425-z
|
| [12] |
Suárez-Eiroa B, Fernández E, Méndez-Martínez G, et al. (2019) Operational principles of circular economy for sustainable development: Linking theory and practice. J Cleaner Prod 214: 952-961. doi: 10.1016/j.jclepro.2018.12.271
|
| [13] |
Kirchherr J, Piscicelli L, Bour R, et al. (2018) Barriers to the circular economy: evidence from the European Union (EU). Ecol Econ 150: 264-272. doi: 10.1016/j.ecolecon.2018.04.028
|
| [14] |
Okafor C, Madu C, Ajaero C, et al. (2021) Moving beyond fossil fuel in an oil-exporting and emerging economy: Paradigm shift. AIMS Energy 9: 379-413. doi: 10.3934/energy.2021020
|
| [15] | International Energy Agency. Data and statistics, 2018. Available from: https://www.iea.org/data-and-statistics/. |
| [16] |
Falcone PM, Morone P, Sica E (2018) Greening of the financial system and fuelling a sustainability transition: A discursive approach to assess landscape pressures on the Italian financial system. Technol Forecast Soc Change 127: 23-37. doi: 10.1016/j.techfore.2017.05.020
|
| [17] |
Gielen D, Boshell F, Saygin D, et al. (2019) The role of renewable energy in the global energy transformation. Energy Strategy Rev 24: 38-50. doi: 10.1016/j.esr.2019.01.006
|
| [18] |
Fadly D (2019) Low-carbon transition: Private sector investment in renewable energy projects in developing countries. World Dev 122: 552-569. doi: 10.1016/j.worlddev.2019.06.015
|
| [19] |
Moriarty P, Honnery D (2018) Energy policy and economics under climate change. AIMS Energy 6: 272-290. doi: 10.3934/energy.2018.2.272
|
| [20] |
Yang X, He L, Xia Y, et al. (2019) Effect of government subsidies on renewable energy investments: The threshold effect. Energy Policy 132: 156-166. doi: 10.1016/j.enpol.2019.05.039
|
| [21] |
Ndiritu SW, Engola MK (2020) The effectiveness of feed-in-tariff policy in promoting power generation from renewable energy in Kenya. Renewable Energy 161: 593-605. doi: 10.1016/j.renene.2020.07.082
|
| [22] | Erfani A, Tavakolan M (2020) Risk evaluation model of wind energy investment projects using modified fuzzy group decision-making and monte carlo simulation. Arthaniti: J Econ Theory Pract, 0976747920963222. |
| [23] |
Echeverri-Martínez R, Alfonso-Morales W, Caicedo-Bravo EF (2020) A methodological Decision-Making support for the planning, design and operation of smart grid projects. AIMS Energy 8: 627-651. doi: 10.3934/energy.2020.4.627
|
| [24] |
Lee HC, Chang CT (2018). Comparative analysis of MCDM methods for ranking renewable energy sources in Taiwan. Renewable Sustainable Energy Rev 92: 883-896. doi: 10.1016/j.rser.2018.05.007
|
| [25] | Monzer N, Fayek AR, Lourenzutti R, et al. (2019) Aggregation-based framework for construction risk assessment with heterogeneous groups of experts. J Constr Eng Manage, 145. |
| [26] |
Perez IJ, Cabrerizo FJ, Alonso S, et al. (2013) A new consensus model for group decision making problems with non-homogeneous experts. IEEE Trans Syst, Man, Cybern: Syst 44: 494-498. doi: 10.1109/TSMC.2013.2259155
|
| [27] | Zheng Y (2018) Identifying Dominators and Followers in Group Decision Making based on The Personality Traits. IUI Workshops. Available from: http://ceur-ws.org/Vol-2068/humanize3.pdf. |
| [28] |
Morente-Molinera JA, Wu X, Morfeq A, et al. (2020). A novel multi-criteria group decision-making method for heterogeneous and dynamic contexts using multi-granular fuzzy linguistic modelling and consensus measures. Inf Fusion 53: 240-250. doi: 10.1016/j.inffus.2019.06.028
|
| [29] |
Alizadeh R, Soltanisehat L, Lund PD, et al. (2020). Improving renewable energy policy planning and decision-making through a hybrid MCDM method. Energy Policy 137: 111-174. doi: 10.1016/j.enpol.2019.111174
|
| [30] |
Gündoğdu FK, Kahraman C (2020) A novel spherical fuzzy analytic hierarchy process and its renewable energy application. Soft Comput 24: 4607-4621. doi: 10.1007/s00500-019-04222-w
|
| [31] |
Zarnegar M (2018) Renewable energy utilization in Iran. Energy Sources, Part A: Recovery, Util, Environ Eff 40: 765-771. doi: 10.1080/15567036.2018.1457741
|
| [32] |
Thang VV, Ha T (2019) Optimal siting and sizing of renewable sources in distribution system planning based on life cycle cost and considering uncertainties. AIMS Energy 7: 211-226. doi: 10.3934/energy.2019.2.211
|
| [33] | Alizadeh R, Beiragh RG, Soltanisehat L, et al. (2020) Performance evaluation of complex electricity generation systems: A dynamic network-based data envelopment analysis approach. Energy Econ, 91. |
| [34] | Alizadeh R, Lund PD, Soltanisehat L (2020) Outlook on biofuels in future studies: A systematic literature review. Renewable Sustainable Energy Rev, 134. |
| [35] |
Alizadeh R, Allen JK, Mistree F (2020) Managing computational complexity using surrogate models: a critical review. Res Eng Des 31: 275-298. doi: 10.1007/s00163-020-00336-7
|
| [36] | Bou-Rabee M, Sulaiman SA, Saleh MS, et al. (2017) Using artificial neural networks to estimate solar radiation in Kuwait. Renewable Sustainable Energy Rev 72: 434-438. |
| [37] |
Teimourian A, Bahrami A, Teimourian H, et al. (2020) Assessment of wind energy potential in the southeastern province of Iran. Energy Sources, Part A: Recovery, Util, Environ Eff 42: 329-343. doi: 10.1080/15567036.2019.1587079
|
| [38] | Çakmakçı BA, Hüner E (2020) Evaluation of wind energy potential: a case study. Energy Sources, Part A: Recovery, Util, Environ Eff, 1-19. |
| [39] |
Azizkhani M, Vakili A, Noorollahi Y, et al. (2017) Potential survey of photovoltaic power plants using Analytical Hierarchy Process (AHP) method in Iran. Renewable Sustainable Energy Rev 75: 1198-1206. doi: 10.1016/j.rser.2016.11.103
|
| [40] |
Díaz-Cuevas P, Domínguez-Bravo J, Prieto-Campos A (2019) Integrating MCDM and GIS for renewable energy spatial models: assessing the individual and combined potential for wind, solar and biomass energy in Southern Spain. Clean Technol Environ Policy 21: 1855-1869. doi: 10.1007/s10098-019-01754-5
|
| [41] |
Yun TS, Lee JS, Lee SC, et al. (2011) Geotechnical issues related to renewable energy. KSCE J Civ Eng 15: 635-642. doi: 10.1007/s12205-011-0004-8
|
| [42] |
Liu X, Xu Y, Herrera F (2019). Consensus model for large-scale group decision making based on fuzzy preference relation with self-confidence: Detecting and managing overconfidence behaviors. Inf Fusion 52: 245-256. doi: 10.1016/j.inffus.2019.03.001
|
| [43] |
Heravi G, Fathi M, Faeghi S (2017) Multi-criteria group decision-making method for optimal selection of sustainable industrial building options focused on petrochemical projects. J Cleaner Prod 142: 2999-3013. doi: 10.1016/j.jclepro.2016.10.168
|
| [44] |
Dranka GG, Cunha J, de Lima JD, et al. (2020) Economic evaluation methodologies for renewable energy projects. AIMS Energy 8: 339-364. doi: 10.3934/energy.2020.2.339
|
| [45] |
Boran FE, Boran K, Dizdar E (2012) A fuzzy multi criteria decision making to evaluate energy policy based on an information axiom: a case study in Turkey. Energy Sources, Part B: Econ, Plann, Policy 7: 230-240. doi: 10.1080/15567240902839294
|
| [46] |
Celiktas MS, Kocar G (2010) From potential forecast to foresight of Turkey's renewable energy with Delphi approach. Energy 35: 1973-1980. doi: 10.1016/j.energy.2010.01.012
|
| [47] | Kul C, Zhang L, Solangi YA (2020) Assessing the Renewable Energy Investment Risk Factors for Sustainable Development in Turkey. J Cleaner Prod, 124164. |
| [48] | Hsu CC, Sandford BA (2007) The Delphi technique: making sense of consensus. Pract Assess, Res, Eval 12: 10. |
| [49] |
Kabak M, Dağdeviren M, Burmaoğlu S (2016) A hybrid SWOT-FANP model for energy policy making in Turkey. Energy Sources, Part B: Econ, Plann, Policy 11: 487-495. doi: 10.1080/15567249.2012.673692
|
| [50] |
Aslani A, Naaranoja M, Zakeri B (2012) The prime criteria for private sector participation in renewable energy investment in the Middle East (case study: Iran). Renewable Sustainable Energy Rev 16: 1977-1987. doi: 10.1016/j.rser.2011.12.015
|
| [51] | Aslani A, Feng B (2014) Investment prioritization in renewable energy resources with consideration to the investment criteria in Iran. Distrib Gener Altern Energy J 29: 7-26. |
| [52] | Erfani A, Tavakolan M (2019) Challenges in renewable energy investment projects in Iran: A review of the main Criteria and Risks. 3rd International Conference on Applied Researches in Structural Engineering and Construction Management, 1-10. |
| [53] |
Boran FE (2018) A new approach for evaluation of renewable energy resources: A case of Turkey. Energy Sources, Part B: Econ, Plann, Policy 13: 196-204. doi: 10.1080/15567249.2017.1423414
|
| [54] |
Ozorhon B, Batmaz A, Caglayan S (2018) Generating a framework to facilitate decision making in renewable energy investments. Renewable Sustainable Energy Rev 95: 217-226. doi: 10.1016/j.rser.2018.07.035
|
| [55] |
Cavallaro F, Ciraolo L (2005) A multicriteria approach to evaluate wind energy plants on an Italian island. Energy Policy 33: 235-244. doi: 10.1016/S0301-4215(03)00228-3
|
| [56] |
Wang JJ, Jing YY, Zhang CF, et al. (2009) Review on multi-criteria decision analysis aid in sustainable energy decision-making. Renewable Sustainable Energy Rev 13: 2263-2278. doi: 10.1016/j.rser.2009.06.021
|
| [57] |
Kaya T, Kahraman C (2010) Multicriteria renewable energy planning using an integrated fuzzy VIKOR & AHP methodology: The case of Istanbul. Energy 35: 2517-2527. doi: 10.1016/j.energy.2010.02.051
|
| [58] |
Şengül Ü, Eren M, Shiraz SE, et al. (2015) Fuzzy TOPSIS method for ranking renewable energy supply systems in Turkey. Renewable Energy 75: 617-625. doi: 10.1016/j.renene.2014.10.045
|
| [59] |
Strantzali E, Aravossis K (2016) Decision making in renewable energy investments: A review. Renewable Sustainable Energy Rev 55: 885-898. doi: 10.1016/j.rser.2015.11.021
|
| [60] |
Al Garni H, Kassem A, Awasthi A, et al. (2016) A multicriteria decision making approach for evaluating renewable power generation sources in Saudi Arabia. Sustainable Energy Technol Assess 16: 137-150. doi: 10.1016/j.seta.2016.05.006
|
| [61] |
Balin A, Baraçli H (2017) A fuzzy multi-criteria decision-making methodology based upon the interval type-2 fuzzy sets for evaluating renewable energy alternatives in Turkey. Technol Econ Dev Econ 23: 742-763. doi: 10.3846/20294913.2015.1056276
|
| [62] |
Çolak M, Kaya İ (2017) Prioritization of renewable energy alternatives by using an integrated fuzzy MCDM model: A real case application for Turkey. Renewable Sustainable Energy Rev 80: 840-853. doi: 10.1016/j.rser.2017.05.194
|
| [63] |
Wu Y, Li L, Song Z, et al. (2019) Risk assessment on offshore photovoltaic power generation projects in China based on a fuzzy analysis framework. J Cleaner Prod 215: 46-62. doi: 10.1016/j.jclepro.2019.01.024
|
| [64] |
Solangi YA, Tan Q, Mirjat NH, et al. (2019) An integrated Delphi-AHP and fuzzy TOPSIS approach toward ranking and selection of renewable energy resources in Pakistan. Processes 7: 118. doi: 10.3390/pr7020118
|
| [65] | Karakaş E (2019) Evaluation of renewable energy alternatives for turkey via modified fuzzy ahp. Available from: http://zbw.eu/econis-archiv/bitstream/11159/3155/1/1667513583.pdf. |
| [66] |
Peng HG, Shen KW, He SS, et al. (2019) Investment risk evaluation for new energy resources: An integrated decision support model based on regret theory and ELECTRE III. Energy Convers Manage 183: 332-348. doi: 10.1016/j.enconman.2019.01.015
|
| [67] | Saaty TL (2008) Decision making with the analytic hierarchy process. Int J Serv Sci 1: 83-98. |
| [68] |
Kamaruzzaman SN, Lou ECW, Wong PF, et al. (2018) Developing weighting system for refurbishment building assessment scheme in Malaysia through analytic hierarchy process (AHP) approach. Energy Policy 112: 280-290. doi: 10.1016/j.enpol.2017.10.023
|
| [69] | Saaty TL (1977) A scaling method for priorities in hierarchical structures. J Math Psychol 15: 234-281. |
| [70] | Saaty TL (1990) Multicriteria decision making: the analytic hierarchy process: planning, priority setting resource allocation. |
| [71] |
Katal F, Fazelpour F (2018) Multi-criteria evaluation and priority analysis of different types of existing power plants in Iran: An optimized energy planning system. Renewable Energy 120: 163-177. doi: 10.1016/j.renene.2017.12.061
|
| [72] |
Erdogan SA, Šaparauskas J, Turskis Z (2019) A multi-criteria decision-making model to choose the best option for sustainable construction management. Sustainability 11: 2239. doi: 10.3390/su11082239
|
| [73] | Feili H, Ahmadian P, Rabiei E, et al. (2018) Ranking of suitable renewable energy location using AHP method and scoring systems with sustainable development perspective. 6th International Conference on Economics, Management, Engineering Science and Art, 1-8. |
| [74] | OPEC, Share of world crude oil reserves (2018) Available from: https://www.opec.org/opec_web/en/data_graphs/330.htm. |
| [75] |
Mollahosseini A, Hosseini SA, Jabbari M, et al. (2017) Renewable energy management and market in Iran: A holistic review on current state and future demands. Renewable Sustainable Energy Rev 80: 774-788. doi: 10.1016/j.rser.2017.05.236
|
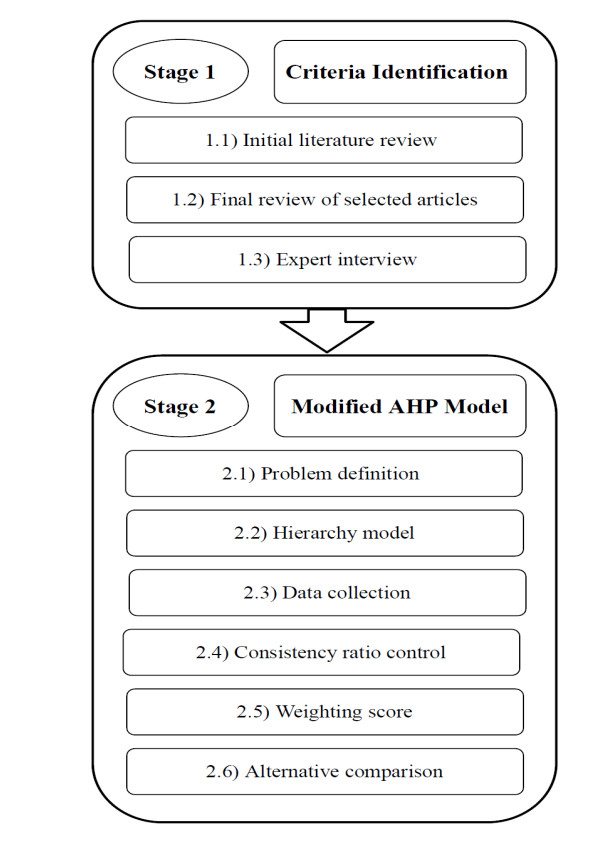
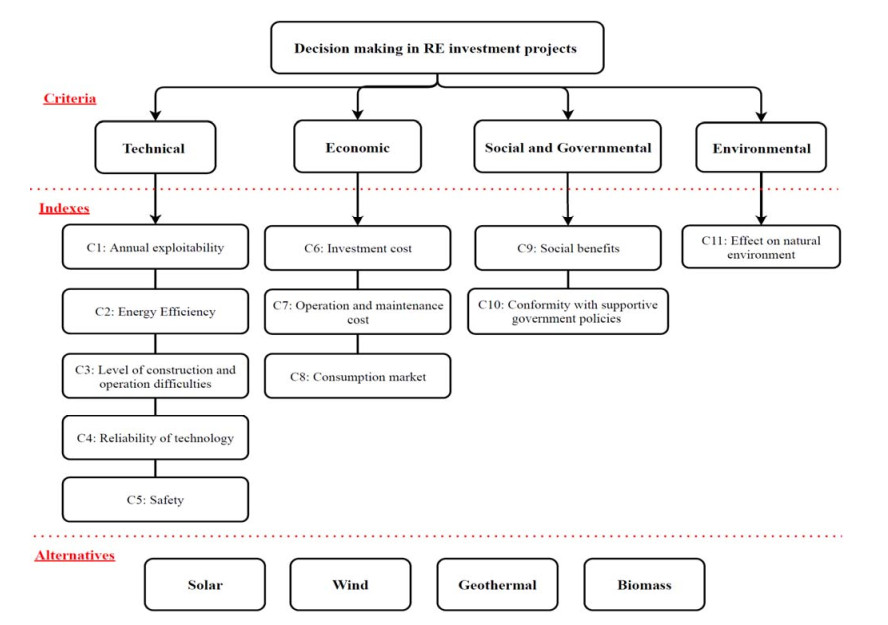
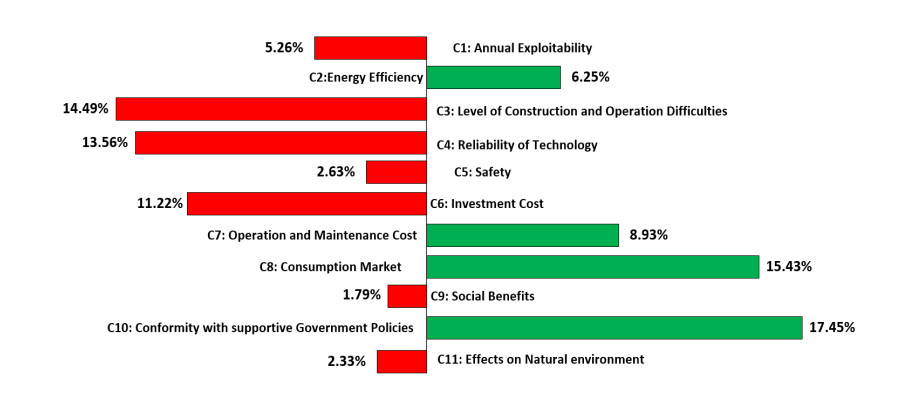
Figures(3) / Tables(5)

Abdolmajid Erfani, Mehdi Tavakolan, Ali Hassandokht Mashhadi, Pouria Mohammadi. Heterogeneous or homogeneous? A modified decision-making approach in renewable energy investment projects[J]. AIMS Energy, 2021, 9(3): 558-580. doi: 10.3934/energy.2021027







 DownLoad:
DownLoad: