Citation: Yannick Fanchette, Harry Ramenah, Camel Tanougast, Michel Benne. Applying Johansen VECM cointegration approach to propose a forecast model of photovoltaic power output plant in Reunion Island[J]. AIMS Energy, 2020, 8(2): 179-213. doi: 10.3934/energy.2020.2.179

| [1] |
Selosse S, Garabedian S, Ricci O, et al. (2018) The renewable energy revolution of reunion island. Renewable Sustainable Energy Rev 89: 99-105. doi: 10.1016/j.rser.2018.03.013

|
| [2] | Omubo-Pepple VB, Israel-Cookey C, Alaminokuma GI (2009) Effects of temperature, solar flux and relative humidity on the efficient conversion of solar energy to electricity. Eur J Sci Res 35: 173-180. |
| [3] | Laronde R, Charki A, Bigaud D (2010) Reliability of photovoltaic modules based on climatic measurement data. International Metrology Conference CAFMET, 1-6. |
| [4] |
Wan C, Zhao J, Song Y, et al. (2015) Photovoltaic and solar power forecasting for smart grid energy management. CSEE J Power Energy Syst 1: 38-46. doi: 10.17775/CSEEJPES.2015.00046
|
| [5] |
Antonanzas J, Osorio N, Escobar R, et al. (2016) Review of photovoltaic power forecasting. Sol Energy 136: 78-111. doi: 10.1016/j.solener.2016.06.069
|
| [6] |
Sobri S, Koohi-Kamali S, Abd Rahim N (2018) Solar photovoltaic generation forecasting methods: A review. Energy Convers Manage 156: 459-497. doi: 10.1016/j.enconman.2017.11.019
|
| [7] |
Al-Sabounchi AM (1998) Effect of ambient temperature on the demanded energy of solar sells at different inclinations. Renewable Energy 14: 149-155. doi: 10.1016/S0960-1481(98)00061-5
|
| [8] | Chandra S, Agrawal S, Chauhan DS (2018) Effect of ambient temperature and wind speed on performance ratio of polycrystalline solar photovoltaic module: An experimental analysis. Int Energy J 18: 171-180. |
| [9] | Amajama J, Ogbulezie JC, Akonjom NA, et al. (2016) Impact of wind on the output of photovoltaic panel and solar illuminance/intensity. Int J Eng Res Gen Sci, 4. |
| [10] | Kaldellis JK, Kapsali M, Kavadias KA (2014) Temperature and wind speed impact on the efficiency of PV installations. Experience obtained from outdoor measurements in Greece. Renewable Energy 66: 612-624. |
| [11] |
Ketjoy N, Konyu M (2014) Study of dust effect on photovoltaic module for photovoltaic power plant. Energy Procedia 52: 431-437. doi: 10.1016/j.egypro.2014.07.095
|
| [12] |
Barbieri F, Rajakaruna S, Ghosh A (2017) Very short-term photovoltaic power forecasting with cloud modeling: A review. Renewable Sustainable Energy Rev 75: 242-263. doi: 10.1016/j.rser.2016.10.068
|
| [13] |
Li Y, Sub Y, Shu L (2014) An ARMAX model for forecasting the power output of a grid connected photovoltaic system. Renewable Energy 66: 78-89. doi: 10.1016/j.renene.2013.11.067
|
| [14] |
Raza MQ, Nadarajah M, Ekanayake C (2016) On recent advances in PV output power forecast. Sol Energy 136: 125-144. doi: 10.1016/j.solener.2016.06.073
|
| [15] |
Zamo M, Mestre O, Arbogast P, et al. (2014) A benchmark of statistical regression methods for short-term forecasting of photovoltaic electricity production, part I: Deterministic forecast of hourly production. Sol Energy 105: 792-803. doi: 10.1016/j.solener.2013.12.006
|
| [16] | Zamo M, Mestre O, Arbogast P, et al. (2014) A benchmark of statistical regression methods for short-term forecasting of photovoltaic electricity production. Part II: Probabilistic forecast of daily production. Sol Energy 105: 804-816. |
| [17] |
AlSkaif T, Dev S, Visser L, et al. (2020) A systematic analysis of meteorological variables for PV output power estimation. Renewable Energy 153: 12-22. doi: 10.1016/j.renene.2020.01.150
|
| [18] | Gujarati DN (2004) Basic of econometric. The McGraw-Hill Econometrics, Fourth Edition, Fourth Companies. |
| [19] | Enders W (1995) Applied economic time series. Wiley Series in Probability and Statistics. |
| [20] |
Bacher P, Madsen H, Nielsen H (2009) Online short-term solar power forecasting. Sol Energy 83: 1772-1783. doi: 10.1016/j.solener.2009.05.016
|
| [21] |
Li Y, Shu Y (2014) An ARMAX model for forecasting the power output of a grid connected photovoltaic system. Renewable Energy 66: 78-89. doi: 10.1016/j.renene.2013.11.067
|
| [22] |
Chu Y, Urguhart B, Gohari S, et al. (2015) Short-term reforecasting of power output from a 48MWe solar PV plant. Sol Energy 112: 68-77. doi: 10.1016/j.solener.2014.11.017
|
| [23] |
Bessa R, Trindade A, Silva C, et al. (2015) Probabilistic solar power forecasting in smart grids using distributed information. Int J Electr Power Energy Syst 72: 16-23. doi: 10.1016/j.ijepes.2015.02.006
|
| [24] |
Pedro H, Coimbra C (2012) Assessment of forecasting techniques for solar power production with no exogenous inputs. Sol Energy 86: 2017-2028. doi: 10.1016/j.solener.2012.04.004
|
| [25] |
Bouzerdoum M, Mellit A, Massi Pavan A (2013) A hybrid model (SARIMA-SVM) for short-term power forecasting of a small-scale grid-connected photovoltaic plant. Sol Energy 98: 226-235. doi: 10.1016/j.solener.2013.10.002
|
| [26] |
Jing H, Korolkiewicz M, Agrawal M, et al. (2013) Forecasting solar radiation on an hourly time scale using Coupled Auto-Regressive and Dynamical System (CARDS) model. Sol Energy 87: 136-149. doi: 10.1016/j.solener.2012.10.012
|
| [27] |
Zamo M, Mestre O, Arbogast P, et al. (2014) A benchmark of statistical regression methods for short-term forecasting of photovoltaic electricity production, part I: Deterministic forecast of hourly production. Sol Energy 105: 792-803. doi: 10.1016/j.solener.2013.12.006
|
| [28] | Kostylev V, Pavlovski A (2011) Solar power forecasting performance towards industry standards. 1st International Workshop on the Integration of Solar Power into Power Systems, Denmark. |
| [29] |
Das UK, Soon Tey K, Seyedmahmoudian M, et al. (2018) Forecasting of photovoltaic power generation and model optimization: A review. Renewable Sustainable Energy Rev 81: 912-928. doi: 10.1016/j.rser.2017.08.017
|
| [30] |
Diagne M, David M, Lauret P, et al. (2013) Review of solar irradiance forecasting methods and a proposition for small-scale insular grids. Renewable Sustainable Energy Rev 27: 65-76. doi: 10.1016/j.rser.2013.06.042
|
| [31] |
Ramenah H, Casin P, Ba M, et al. (2018) Accurate determination of parameters relationship for photovoltaic power output by augmented dickey fuller and engle granger method. AIMS Energy 6: 19-48. doi: 10.3934/energy.2018.1.19
|
| [32] | Marcinkiewicz E (2014) Some aspects of application of VECM analysis for modeling causal relationships between spot and futures prices. Optimum Stud Ekon 71: 114-125. |
| [33] |
Andrei D, Andrei L (2015) Vector error correction model in explaining the association of some macroeconomic variables in Romania. Procedia Econ finance 22: 568-576. doi: 10.1016/S2212-5671(15)00261-0
|
| [34] |
Katircioglu ST (2009) Revisiting the tourism-led-growth hypothesis for Turkey using the bounds test and Johansen approach for cointegration. Tourism Manage 30: 17-20. doi: 10.1016/j.tourman.2008.04.004
|
| [35] |
Skoplaki E, Palyvos JA (2009) Operating temperature of photovoltaic modules: A survey of pertinent correlations. Renewable Energy 34: 23-29. doi: 10.1016/j.renene.2008.04.009
|
| [36] |
Dubey S, Sarvaiya JN, Seshadri B (2013) Temperature dependent photovoltaic (PV) efficiency and its effect on PV production in the world-A Review. Energy Procedia 33: 311-321. doi: 10.1016/j.egypro.2013.05.072
|
| [37] |
Luo Y, Zhang L, Liu Z, et al. (2017) Performance analysis of a self-adaptive building integrated photovoltaic thermoelectric wall system in hot summer and cold winter zone of China. Energy 140: 584-600. doi: 10.1016/j.energy.2017.09.015
|
| [38] | Amajama J, Oku DE (2016) Wind versus UHF Radio signal. Int J Sci Eng Technol Res 5: 583-585. |
| [39] |
Qasem H, Betts TR, Müllejans H, et al. (2014) Application dust-induced shading on photovoltaic modules. Photovolt Res 22: 218-226. doi: 10.1002/pip.2230
|
| [40] | Jalil A, Rao NH (2019) Chapter 8-Time series analysis (Stationarity, Cointegration, and Causality). Özcan B, Öztürk I, Éds. Environmental Kuznets Curve (EKC), Academic Press, 85-99. |
| [41] | Granger CWJ, Weiss AA (1983) Time series analysis of error-correction. Karlin S, Amemiya T, Goodman LA, Éds. Studies in Econometrics, Time Series, and Multivariate Statistics, Academic Press, 255-278. |
| [42] | Mills TC (2019) Chapter 14-Error correction, spurious regressions, and cointegration. Mills TC, Ed. Applied Time Series Analysis, Academic Press, 233-253. |
| [43] | Davinson R, MacKinnon JG (2009) Econometric Theory and Methods, Oxford University Press. |
| [44] |
Hassani H, Yeganegi MR (2019) Sum of squared ACF and the Ljung-Box statistics. Phys A: Stat Mech Appl 520: 81-86. doi: 10.1016/j.physa.2018.12.028
|
| [45] |
Ljung GM, Box GEP (1978) On a measure of lack of fit in time series models. Biometrika 65: 297-303. doi: 10.1093/biomet/65.2.297
|
| [46] | Hoffman JIE (2015) Chapter 6-Normal distribution. Hoffman JIE, Ed. Biostatistics for Medical and Biomedical Practitioners, Academic Press, 101-119. |
| [47] |
Johansen S (1988) Statistical analysis of cointegration vectors. J Econ Dyn Control 12: 231-254. doi: 10.1016/0165-1889(88)90041-3
|
| [48] |
Johansen S (1991) Estimation and hypothesis testing of cointegration vectors in gaussian vector autoregressive models. Econometrica 59: 1551-1580. doi: 10.2307/2938278
|
| [49] | Johansen S (1995) Likelihood-Based Inference in Cointegrated Vector Autoregressive Models. New York: Oxford University Press. |
| [50] |
Fu T, Tang X, Cai Z, et al. (2020) Correlation research of phase angle variation and coating performance by means of Pearson's correlation coefficient. Prog Org Coat 139: 105459. doi: 10.1016/j.porgcoat.2019.105459
|
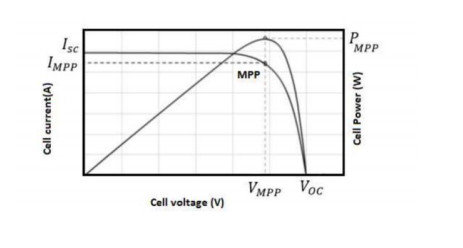
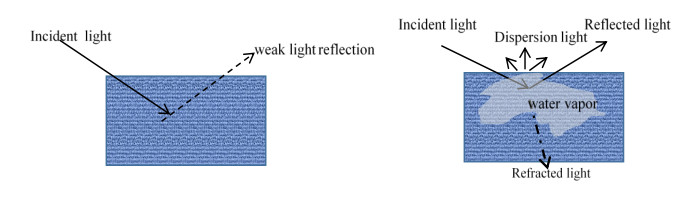
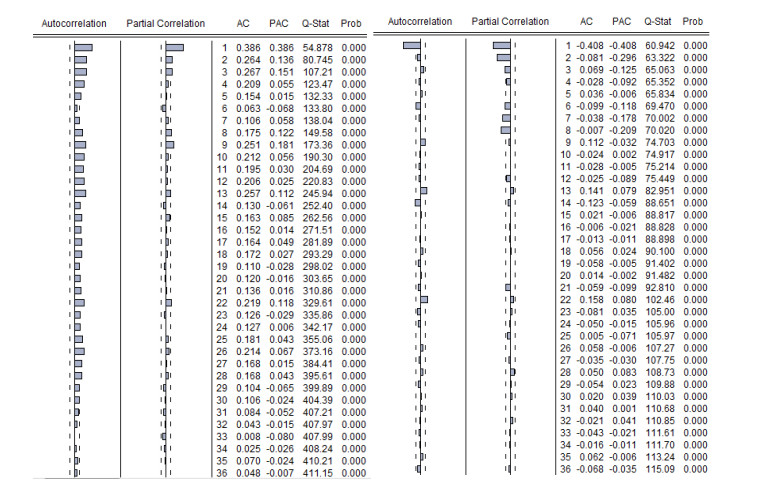
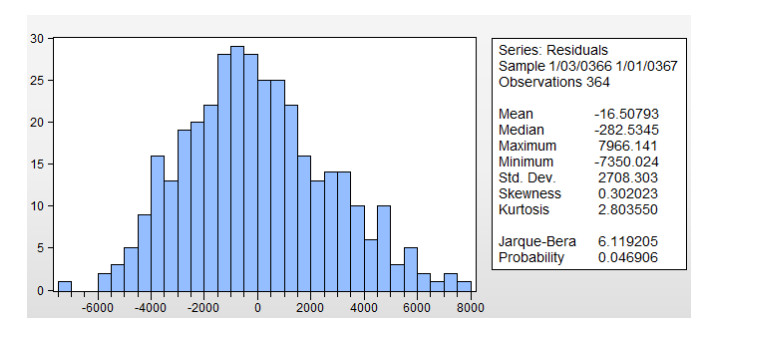
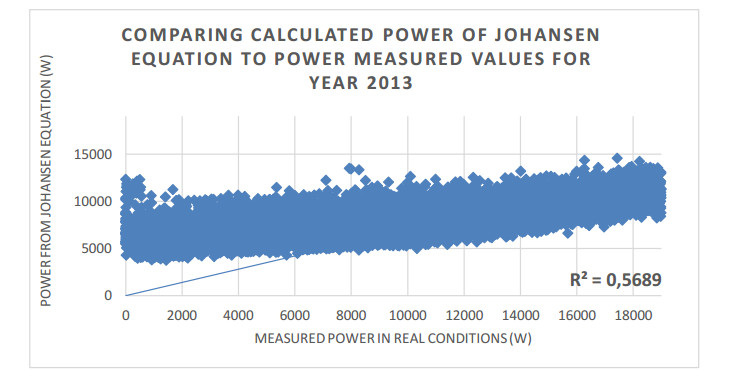
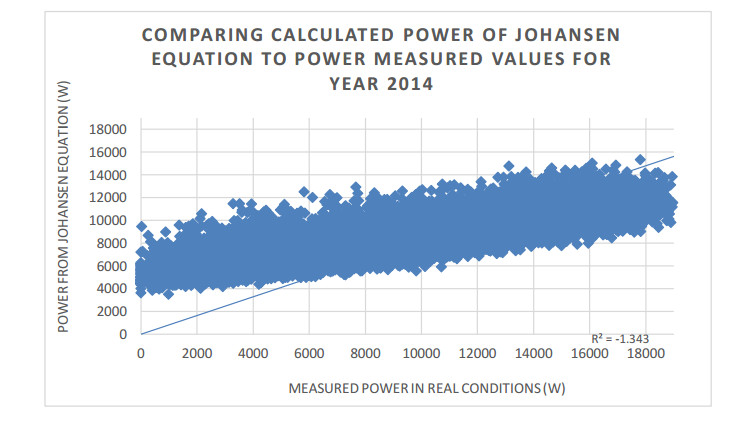
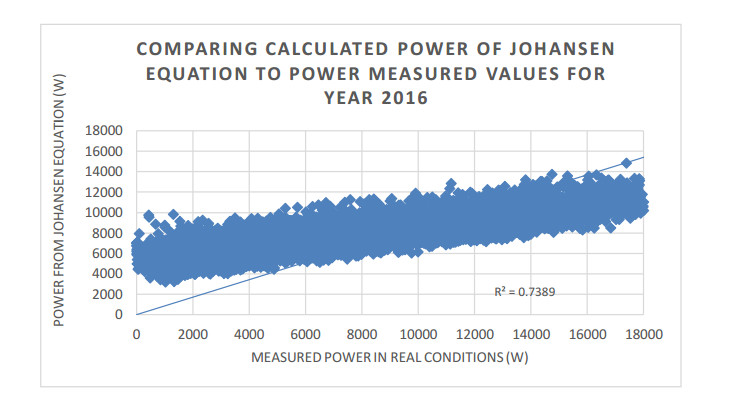
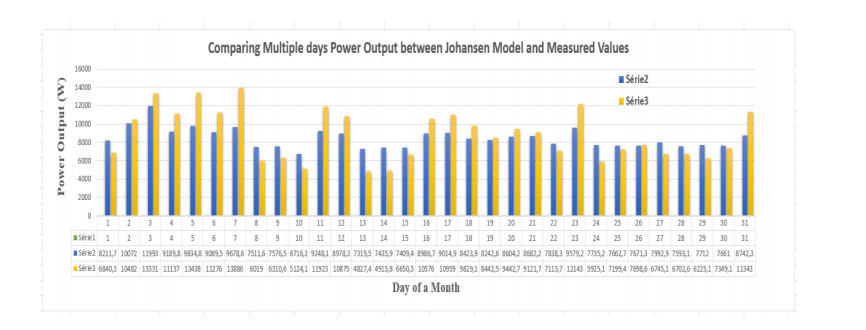
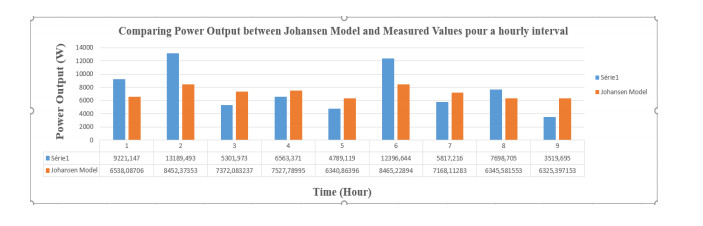
Figures(13) / Tables(19)

Yannick Fanchette, Harry Ramenah, Camel Tanougast, Michel Benne. Applying Johansen VECM cointegration approach to propose a forecast model of photovoltaic power output plant in Reunion Island[J]. AIMS Energy, 2020, 8(2): 179-213. doi: 10.3934/energy.2020.2.179







 DownLoad:
DownLoad: