A volatile trading pattern on a given day in a financial market presents an opportunity for traders to maximize the difference between their buying and selling prices. In order to formulate trading strategies it may be advantageous to study typical trading patterns. This paper first describes how clustering can be used to profile typical volatile trading patterns. Fuzzy $c$-means provides a better description of individual trading patterns, since they can display certain aspects of different trading profiles. While daily volatility profile is a useful indicator for trading a stock, the volatility history is also an important part of the decision making process. This paper further proposes a fuzzy temporal meta-clustering algorithm that not only captures the daily volatility but also puts it in a historical perspective by including the volatility of previous two weeks in the meta-profile.
Citation: Pawan Lingras, Farhana Haider, Matt Triff. Fuzzy temporal meta-clustering of financial trading volatility patterns[J]. Big Data and Information Analytics, 2017, 2(3): 219-238. doi: 10.3934/bdia.2017018
A volatile trading pattern on a given day in a financial market presents an opportunity for traders to maximize the difference between their buying and selling prices. In order to formulate trading strategies it may be advantageous to study typical trading patterns. This paper first describes how clustering can be used to profile typical volatile trading patterns. Fuzzy $c$-means provides a better description of individual trading patterns, since they can display certain aspects of different trading profiles. While daily volatility profile is a useful indicator for trading a stock, the volatility history is also an important part of the decision making process. This paper further proposes a fuzzy temporal meta-clustering algorithm that not only captures the daily volatility but also puts it in a historical perspective by including the volatility of previous two weeks in the meta-profile.

| [1] |
J. C. Bezdek, Pattern Recognition with Fuzzy Objective Function Algorithms, Kluwer Academic Publishers, Norwell, MA, USA, 1981. MR631231 |
| [2] |
F. Black and M. Scholes, The pricing of options and corporate liabilities, The journal of political economy, 81 (1973), 637–654. doi: 10.1086/260062

|
| [3] |
R. Caruana, M. Elhaway, N. Nguyen and C. Smith, Meta clustering, in Data Mining, 2006. ICDM'06. Sixth International Conference on, IEEE, 2006,107–118. 10.1109/ICDM.2006.103 |
| [4] | G. Castellano, A. M. Fanelli and C. Mencar, Generation of interpretable fuzzy granules by a double-clustering technique, Archives of Control Science, 12 (2002), 397–410. |
| [5] |
J. C. Dunn, A fuzzy relative of the ISODATA process and its use in detecting compact well-separated clusters, Cybernetics, 3 (1973), 32–57. doi: 10.1080/01969727308546046
|
| [6] | R. El-Yaniv and O. Souroujon, Iterative double clustering for unsupervised and semisupervised learning, Machine Learning: ECML 2001, Springer, (2001), 121–132. |
| [7] | D. Gnatyshak, D. I. Ignatov, A. Semenov and J. Poelmans, Gaining insight in social networks with biclustering and triclustering, Perspectives in Business Informatics Research, Springer, (2012), 162–171. |
| [8] | D. V. Gnatyshak, D. I. Ignatov and S. O. Kuznetsov, From triadic fca to triclustering: Experimental comparison of some triclustering algorithms, CLA 2013, p249. |
| [9] |
M. Halkidi, Y. Batistakis and M. Vazirgianni, Clustering validity checking methods: Part Ⅱ, ACM SIGMOD Record, 31 (2002), 19–27. doi: 10.1145/601858.601862
|
| [10] | J. A. Hartigan and M. A.Wong, Algorithm AS136: A K-Means Clustering Algorithm, Applied Statistics, 28 (1979), 100–108. |
| [11] |
D. I. Ignatov, S. O. Kuznetsov and J. Poelmans, Concept-based biclustering for internet advertisement, in Data Mining Workshops (ICDMW), 2012 IEEE 12th International Conference on, IEEE, 2012,123–130. 10.1109/ICDMW.2012.100 |
| [12] |
D. I. Ignatov, S. O. Kuznetsov, J. Poelmans and L. E. Zhukov, Can triconcepts become triclusters?, International Journal of General Systems, 42 (2013), 572–593. doi: 10.1080/03081079.2013.798899
|
| [13] |
P. Lingras and K. Rathinavel, Recursive Meta-clustering in a Granular Network, in Plenary talk at the Fourth International Conference of Soft Computing and Pattern Recognition, Brunei, 2012. 10.1109/ISDA.2012.6416634 |
| [14] |
P. Lingras and M. Tri, Fuzzy and crisp recursive profiling of online reviewers and businesses, IEEE Transactions on Fuzzy Systems, 23 (2015), 1242–1258. doi: 10.1109/TFUZZ.2014.2349532
|
| [15] |
P. Lingras, A. Elagamy, A. Ammar and Z. Elouedi, Iterative meta-clustering through granular hierarchy of supermarket customers and products, Information Sciences, 257 (2014), 14–31. doi: 10.1016/j.ins.2013.09.018
|
| [16] | P. Lingras and F. Haider, Recursive temporal meta-clustering, Applied Soft Computing, submitted. |
| [17] |
P. Lingras and K. Rathinavel, Recursive meta-clustering in a granular network, in Intelligent Systems Design and Applications (ISDA), 2012 12th International Conference on, IEEE, 2012,770–775. 10.1109/ISDA.2012.6416634 |
| [18] |
J. MacQueen, Some methods for classification and analysis of multivariate observations, in Proceedings of Fifth Berkeley Symposium on Mathematical Statistics and Probability, 1 (1967), 281–297. MR0214227 |
| [19] |
B. Mirkin, Mathematical Classification and Clustering, Kluwer Academic Publishers, Boston, MA, USA, 1996. MR1480413 |
| [20] |
W. Pedrycz and J. Waletzky, Fuzzy clustering with partial supervision, IEEE Transactions on Systems, Man, and Cybernetics, Part B, 27 (1997), 787–795. doi: 10.1109/3477.623232
|
| [21] | D. Ramirez-Cano, S. Colton and R. Baumgarten, Player classification using a meta-clustering approach, in Proceedings of the 3rd Annual International Conference Computer Games, Multimedia and Allied Technology, 2010,297–304. |
| [22] |
K. Rathinavel and P. Lingras, A granular recursive fuzzy meta-clustering algorithm for social networks, in IFSA World Congress and NAFIPS Annual Meeting (IFSA/NAFIPS), 2013 Joint, IEEE, 2013,567–572. 10.1109/IFSA-NAFIPS.2013.6608463 |
| [23] |
N. Slonim and N. Tishby, Document clustering using word clusters via the information bottleneck method, in 23rd Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, 2000,208–215. 10.1145/345508.345578 |
| [24] | M. Triff and P. Lingras, Recursive profiles of businesses and reviewers on yelp. com, Rough Sets, Fuzzy Sets, Data Mining, and Granular Computing, Springer, (2013), 325–336. |
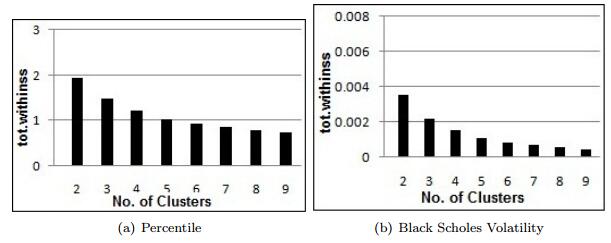
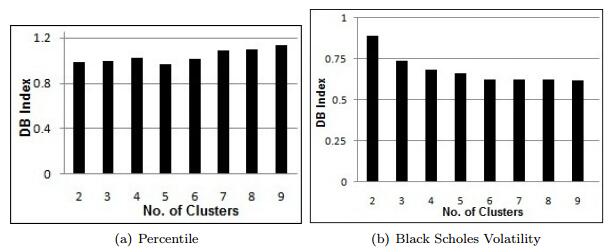
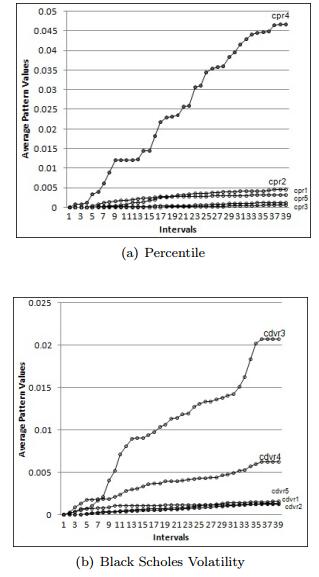
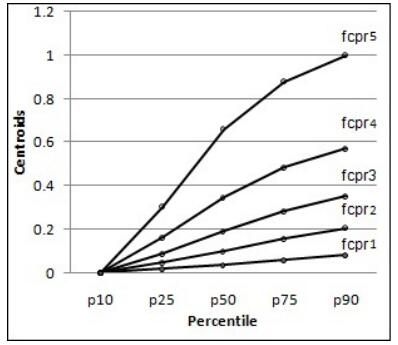

Figures(14) / Tables(10)

Pawan Lingras, Farhana Haider, Matt Triff. Fuzzy temporal meta-clustering of financial trading volatility patterns[J]. Big Data and Information Analytics, 2017, 2(3): 219-238. doi: 10.3934/bdia.2017018









 DownLoad:
DownLoad: