Citation: Md Akther Uddin, Mohammad Enamul Hoque, Md Hakim Ali. International economic policy uncertainty and stock market returns of Bangladesh: evidence from linear and nonlinear model[J]. Quantitative Finance and Economics, 2020, 4(2): 236-251. doi: 10.3934/QFE.2020011

| [1] | Alqahtani A, Miguel M (2020) US Economic Policy Uncertainty and GCC Stock Market. Asia-Paci Financ Markets, 1-11. |
| [2] |
Anagnostidis P, Emmanouilides CJ (2015) Nonlinearity in high-frequency stock returns: Evidence from the Athens Stock Exchange. Phys A 421: 473-487. doi: 10.1016/j.physa.2014.11.056

|
| [3] |
Andreou E, Ghysels E (2002) Detecting multiple breaks in financial market volatility dynamics. J Appl Econometrics 17: 579-600. doi: 10.1002/jae.684
|
| [4] |
Andrews DW, Ploberger W (1994) Optimal tests when a nuisance parameter is present only under the alternative. Econometrica J Econometric Society, 1383-1414. doi: 10.2307/2951753
|
| [5] |
Andrews DW (1993) Tests for parameter instability and structural change with unknown change point. Econometrica J Econometric Society, 821-856. doi: 10.2307/2951764
|
| [6] | Apergis N, Bonato M, Gupta R, et al. (2018) Does geopolitical risks predict stock returns and volatility of leading defense companies? Evidence from a nonparametric approach. Def Peace Econ 29: 684-696. |
| [7] |
Arouri M, Estay C, Rault C, et al. (2016) Economic policy uncertainty and stock markets: Long-run evidence from the US. Financ Res Lett 18: 136-141. doi: 10.1016/j.frl.2016.04.011
|
| [8] | Arouri M, Roubaud D (2016) On the determinants of stock market dynamics in emerging countries: the role of economic policy uncertainty in China and India. Econ Bull 36: 760-770. |
| [9] | Bahmani-Oskooee M, Saha S (2019) On the Effects of Policy Uncertainty on Stock Prices. J Econ Financ. [In press]. |
| [10] |
Bahmani-Oskooee M, Sujata S (2019) On the effects of policy uncertainty on stock prices: an asymmetric analysis. Quant Financ Econ 3: 412-424. doi: 10.3934/QFE.2019.2.412
|
| [11] |
Bai J, Perron P (1998) Estimating and testing linear models with multiple structural changes. Econometrica, 47-78. doi: 10.2307/2998540
|
| [12] |
Bai J, Perron P (2003) Computation and analysis of multiple structural change models. J Appl Econometrics 18: 1-22. doi: 10.1002/jae.659
|
| [13] |
Baker SR, Bloom N, Canes-Wrone B, et al. (2014) Why has US policy uncertainty risen since 1960? Am Econ Rev 104: 56-60. doi: 10.1257/aer.104.5.56
|
| [14] |
Baker SR, Bloom N, Davis SJ (2016) Measuring economic policy uncertainty. Q J Econ 131: 1593-1636. doi: 10.1093/qje/qjw024
|
| [15] |
Balcilar M, Bekiros S, Gupta R (2017) The role of news-based uncertainty indices in predicting oil markets: a hybrid nonparametric quantile causality method. Empirica Econ 53: 879-889. doi: 10.1007/s00181-016-1150-0
|
| [16] | Balcilar M, Gupta R, Kyei C, et al. (2016) Does economic policy uncertainty predict exchange rate returns and volatility? Evidence from a nonparametric causality-in-quantiles test. Open Econ Rev 27: 229-250. |
| [17] |
Banerjee PK, Ahmed MN, Hossain MM (2017) Bank, stock market and economic growth: Bangladesh perspective. J Dev Areas 51: 17-29. doi: 10.1353/jda.2017.0028
|
| [18] |
Barberis N, Shleifer A, Vishny R (1998) A model of investor sentiment. J Financ Econ 49: 307-343. doi: 10.1016/S0304-405X(98)00027-0
|
| [19] |
Basher SA, Hassan MK, Islam AM (2007) Time-varying volatility and equity returns in Bangladesh stock market. Appl Financ Econ 17: 1393-1407. doi: 10.1080/09603100600771034
|
| [20] |
Basher SA, Haug AA, Sadorsky P (2018) The impact of oil-market shocks on stock returns in major oil-exporting countries. J Int Money Financ 86: 264-280. doi: 10.1016/j.jimonfin.2018.05.003
|
| [21] |
Bekaert G, Ehrmann M, Fratzscher M, et al. (2014) The global crisis and equity market contagion. J Financ 69: 2597-2649. doi: 10.1111/jofi.12203
|
| [22] |
Bekaert G, Harvey CR, Lundblad CT (2003) Equity market liberalization in emerging markets. J Financ Res 26: 275-299. doi: 10.1111/1475-6803.00059
|
| [23] |
Blanchard O, Dell'Ariccia G, Mauro P (2010) Rethinking macroeconomic policy. J Money Credit Bank 42: 199-215. doi: 10.1111/j.1538-4616.2010.00334.x
|
| [24] |
Choi S, Furceri D (2019) Uncertainty and cross-border banking flows. J In Money Financ 93: 260-274. doi: 10.1016/j.jimonfin.2019.01.012
|
| [25] |
Chung KH, Chuwonganant C (2018) Market volatility and stock returns: The role of liquidity providers. J Financ Markets 37: 17-34. doi: 10.1016/j.finmar.2017.07.002
|
| [26] |
Guo P, Zhu H, You W (2018) Asymmetric dependence between economic policy uncertainty and stock market returns in G7 and BRIC: A quantile regression approach. Financ Res Lett 25: 251-258. doi: 10.1016/j.frl.2017.11.001
|
| [27] |
Hamilton JD (1989) A new approach to the economic analysis of nonstationary time series and the business cycle. Econometrica: J Econometric Society, 357-384. doi: 10.2307/1912559
|
| [28] | Hamilton JD (2010) Regime switching models, In Macroeconometrics and time series analysis, Palgrave Macmillan UK, 202-209. |
| [29] |
Hassan MK, Chowdhury SSH (2008) Efficiency of Bangladesh stock market: evidence from monthly index and individual firm data. Appl Financ Econ 18: 749-758. doi: 10.1080/09603100701320178
|
| [30] | Hoque ME, Zaidi AS (2020) Impacts of Global Economic Policy Uncertainty 0n Emerging Stock Markets: Evidence From Linear and Non-Linear Models. Prague Econ Pap, 1-12. |
| [31] |
Hoque ME, Zaidi MAS (2019) The impacts of global economic policy uncertainty on stock market returns in regime switching environment: Evidence from sectoral perspectives. Int J Financ Econ 24: 991-1016. doi: 10.1002/ijfe.1702
|
| [32] | Islam KM, Ahmed SF (2015) Stock market crash and stock return volatility: empirical evidence from Dhaka stock exchange. Bangladesh Dev Stud 38: 25-34. |
| [33] | Islam MS (2012) China-Bangladesh relations: contemporary convergence. Daily Star 25. |
| [34] | Islam MS, Islam MR (2011) Demutualization: Pros and Cons for Dhaka Stock Exchange (DSE). Eur J Bus Manage 3: 24-33. |
| [35] |
Janina E, Markus W, Rudi Z (2018) Forecasting turbulence in the Asian and European stock market using regime-switching models. Quant Financ Econ 2: 388-406. doi: 10.3934/QFE.2018.2.388
|
| [36] |
JulioB, Yook Y (2016) Policy uncertainty, irreversibility, and cross-border flows of capital. J Int Econ 103: 13-26. doi: 10.1016/j.jinteco.2016.08.004
|
| [37] | Li R, Sufang L, Di Yuan, et al. (2020) Does economic policy uncertainty in the US influence stock markets in China and India? Time-frequency evidence. Appl Econ, 1-17. |
| [38] |
Li X, Mehmet B, Rangan G, et al. (2016) The causal relationship between economic policy uncertainty and stock returns in China and India: evidence from a bootstrap rolling window approach. Emerging Markets Financ Trade 52: 674-689. doi: 10.1080/1540496X.2014.998564
|
| [39] | Mahmud N (2019) Chinese consortium in DSE: Performance not as per expectation after a year. Dhaka Tribune. Retrieved on 5th October, 2019 . Available from: https://www.dhakatribune.com/business/stock/2019/05/13/chinese-consortium-in-dse-performance-not-as-per-expectation-after-a-year |
| [40] | Manni UH, Afzal MNI (2012) Effect of trade liberalization on economic growth of developing countries: A case of Bangladesh economy. J Bus Econ 1: 37-44. |
| [41] | Mollah S (2011) Do emerging market firms follow different dividend policies? Empirical investigation on the pre-and post-reform dividend policy and behaviour of Dhaka Stock Exchange listed firms. Stud Econ Financ 28: 118-135. |
| [42] | Murshid KAS, Zohir SC, Ahmed M, et al. (2009) The global financial crisis implications for Bangladesh. BIDS-PRP Working Paper Series, 1. |
| [43] |
Pastor L, Veronesi P (2012) Uncertainty about government policy and stock prices. J Financ 67: 1219-1264. doi: 10.1111/j.1540-6261.2012.01746.x
|
| [44] |
Phan DHB, Sharma SS, Tran VT (2018) Can economic policy uncertainty predict stock returns? Global evidence. J Int Financ Markets Inst Money 55, 134-150. doi: 10.1016/j.intfin.2018.04.004
|
| [45] |
Portes R, Rey H (2005) The determinants of cross-border equity flows. J Int Econ 65: 269-296. doi: 10.1016/j.jinteco.2004.05.002
|
| [46] |
Rahman T, Hossain S, Habibullah M (2017) Stock market crash in Bangladesh: The moneymaking psychology of domestic investors. Am J Theor Appl Bus 3: 43-53. doi: 10.11648/j.ajtab.20170303.12
|
| [47] | Rey H (2015) Dilemma not trilemma: the global financial cycle and monetary policy independence. National Bureau of Economic Research (No. w21162). |
| [48] |
Tsai I (2017) The source of global stock market risk: A viewpoint of economic policy uncertainty. Econ Model 60: 122-131. doi: 10.1016/j.econmod.2016.09.002
|
| [49] | Ullah N, Uddin MA (2018) Does Indian Economic Growth Affect Bangladesh? An Application of ARDL. J South Asian Stud 6: 69-84. |
| [50] |
Zhang D, Lei L, Ji Q, et al. (2019) Economic policy uncertainty in the US and China and their impact on the global markets. Econ Model 79: 47-56. doi: 10.1016/j.econmod.2018.09.028
|
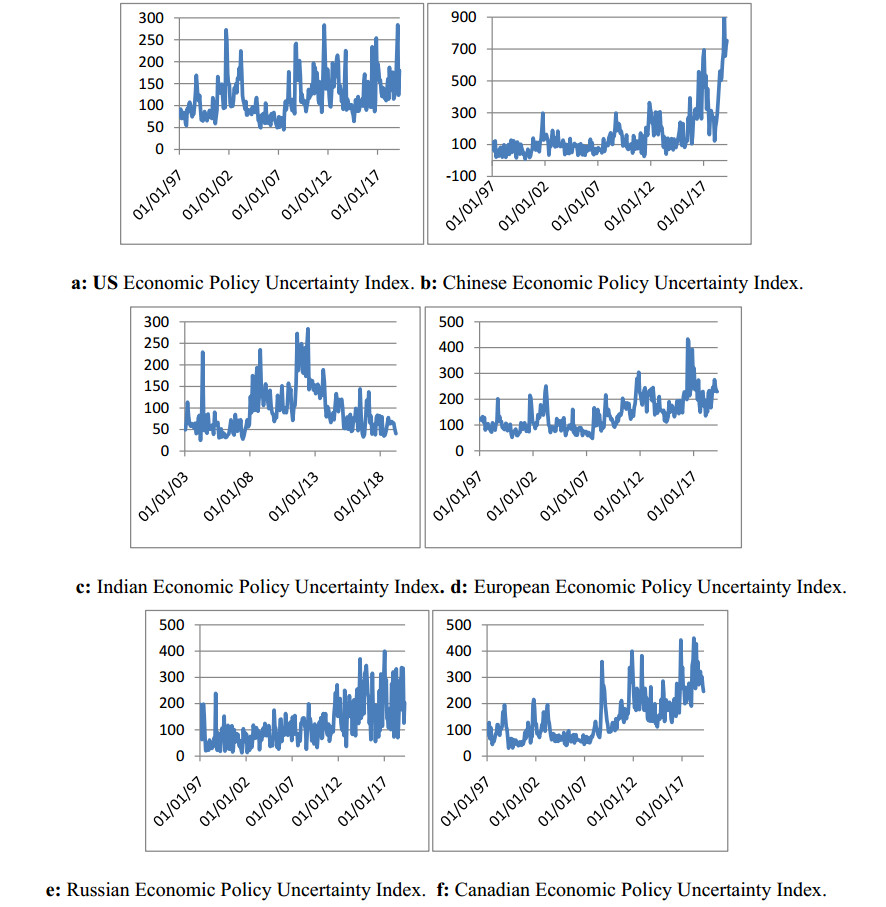
Figures(1) / Tables(7)

Md Akther Uddin, Mohammad Enamul Hoque, Md Hakim Ali. International economic policy uncertainty and stock market returns of Bangladesh: evidence from linear and nonlinear model[J]. Quantitative Finance and Economics, 2020, 4(2): 236-251. doi: 10.3934/QFE.2020011







 DownLoad:
DownLoad: