Citation: Jörg Fehr, Jan Heiland, Christian Himpe, Jens Saak. Best practices for replicability, reproducibility and reusability of computer-based experiments exemplified by model reduction software[J]. AIMS Mathematics, 2016, 1(3): 261-281. doi: 10.3934/Math.2016.3.261

| [1] | D. H. Bailey, J. M. Borwein, and V. Stodden. Set the default to “open”. Notices of the AMS, 60(6): 679–680, 2013. URL http://dx:doi:org/10:1090/noti1014. |
| [2] | D. H. Bailey, J. M. Borwein, and V. Stodden. Facilitating reproducibility in scientific computing:Principles and practice. In H. Atmanspacher and S. Maasen, editors, Reproducibility: Principles,Problems, Practices, and Prospects, pages 205–232. Wiley, 2016. ISBN 9781118864975. URL http://dx:doi:org/10:1002/9781118865064:ch9. |
| [3] | W. Bangerth and T. Heister. Quo vadis, scientific software? SIAM News, 47(1), 2014. URL http://citeseerx:ist:psu:edu/viewdoc/summary?doi=10:1:1:636:5594. Accessed: |
| [4] | 2016-09-22. |
| [5] | 4. L. A. Barba. Why should i believe your supercomputing research? http://medium:com/@lorenaabarba/why-should-i-believe-your-supercomputing-researcha7cbf4cbc6b4#:anqkh3s, 2016. URL http://archive:is/2Zgx4. |
| [6] | 5. N. Barnes. Publish your computer code: it is good enough. Nature, 4:753, 2010. URL http://dx:doi:org/10:1038/467753a. |
| [7] | 6. P. Bourque and R. E. Fairley, editors. Guide to the Software Engineering Body of Knowledge(SWEBOK), Version 3.0. IEEE Computer Society, 2014. URL http://swebok:org. |
| [8] | 7. B. Brembs. Earning credibility in post-factual science? bjoern:brembs:net/2016/02/earning-credibility-in-post-factual-science, 2016. URL http://archive:is/zniPL. |
| [9] | 8. C. T. Brown. Replication, reproduction, and remixing in research software. ivory:idyll:org/blog/research-software-reuse:html, 2013. URL http://archive:is/2myPk. |
| [10] | 9. J. B. Buckheit and D. L. Donoho. Wavelab and reproducible research. In A. Antoniadis and G. Oppenheim,editors, Wavelets and Statistics, volume of Lecture Notes in Statistics, pages 55–81. Springer, New York, 1995. URL http://dx:doi:org/10:1007/978-1-4612-2544-7_5. |
| [11] | 10. S. Chaturantabut and D. C. Sorensen. Nonlinear model reduction via discrete empirical interpolation.SIAM Journal of Scientific Computing, 32(5):2737–2764, 2010. URL http://dx:doi:org/10:7/090766498. |
| [12] | 11. C. Collberg, T. Proebsten, and A. M. Warren. Repeatability and benefaction in computer systems research. Technical report, University of Arizona, 2014. URL http://reproducibility:cs:arizona:edu/v2/RepeatabilityTR:pdf. Accessed:2016-09-22. |
| [13] | 12. Scientific Data. Editorial and publishing policies. www:nature:com/sdata/for-authors/editorial-and-publishing-policies#code-avail, 2016. URL http://archive:is/c0BBk. |
| [14] | 13. S. M. Easterbrook. Open code for open science? Nature Geoscience, 7:779–781, 20 URL http://dx:doi:org/10:1038/ngeo2283. |
| [15] | 14. J.W. Eaton, D. Bateman, S. Hauberg, and R.Wehbring. GNU Octave version 4.0.3 manual: a highlevel interactive language for numerical computations. http://www:gnu:org/software/octave/octave:pdf, 2016. Accessed: 2016-09-22. |
| [16] | 15. T. M. Errington, E. Iorns, W. Gunn, F. E. Tan, J. Lomax, and B. A. Nosek. An open investigation of the reproducibility of cancer biology research. eLife, 3:e04333, 2014. URL http://dx:doi:org/10:7554/eLife:04333. |
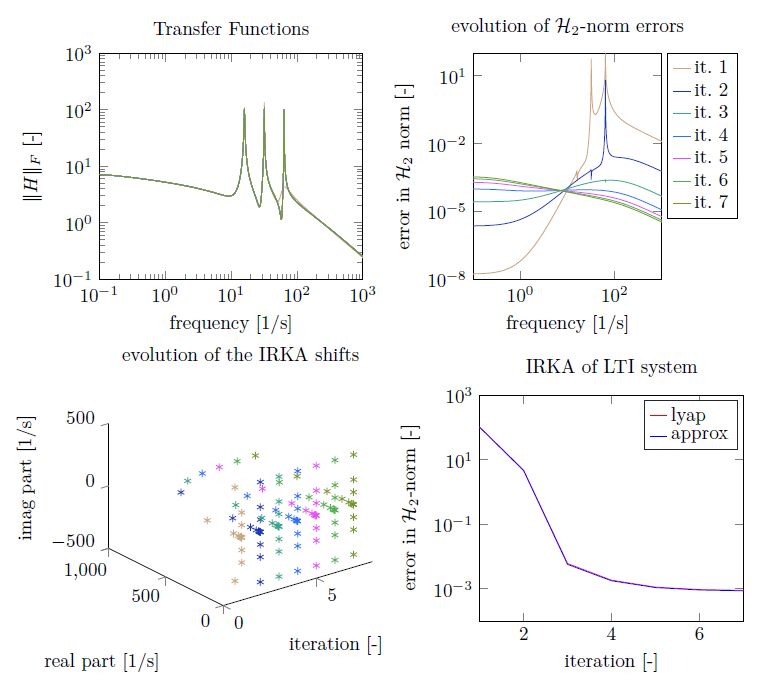
| [17] | 16. J. Fehr and J. Saak. Iterative rational Krylov algorithm (IRKA). DOI 10.5281/zenodo.49965, 2016. URL http://dx:doi:org/10:5281/zenodo:49965. |
| [18] | 17. S. Fomel and J. F. Claerbout. Guest editors’ introduction: Reproducible research. Computing in Science & Engineering, 11(1):5–7, 2009. URL http://dx:doi:org/10:1109/ MCSE:2009:14. |
| [19] | 18. Interoperability Solutions for European Public Administrations. Asset Description Metadata Schema for Software, 2012. URL http://joinup:ec:europa:eu/asset/adms_foss/asset_release/admssw-100. Accessed: 2016-09-22. |
| [20] | 19. I. P. Gent. The recomputation manifesto. cs.GL 1304.3674, arXiv, 3. URL http://arxiv:org/abs/1304:3674. |
| [21] | 20. T. Glatard, L. B. Lewis, R. F. da Silva, R. Adalat, N. Beck, C. Lepage, P. Rioux, M.-E.br>Rousseau, T. Sherif, E. Deelman, N. Khalili-Mahani, and A. C. Evans. Reproducibility of neuroimagingbr>analyses across operating systems. Frontiers in Neuroinformatics, 9, 2015. URL http://dx:doi:org/10:3389/fninf:2015:00012. |
| [22] | 21. S. Gugercin, A. C. Antoulas, and C. A. Beattie. H2 Model reduction for large-scale linear dynamical systems. SIAM Journal on Matrix Analysis and Applications, 30(2):609–638, 2008. URL http://dx:doi:org/10:1137/060666123. |
| [23] | 22. M. A. Heroux and J. M. Willenbring. Barely su cient software engineering: 10 practices to improve your CSE software. In ICSE Workshop on Software Engineering for Computational Science and Engineering, pages 15–21, 2009. URL http://dx:doi:org/10:1109/ SECSE:2009:5069157. |
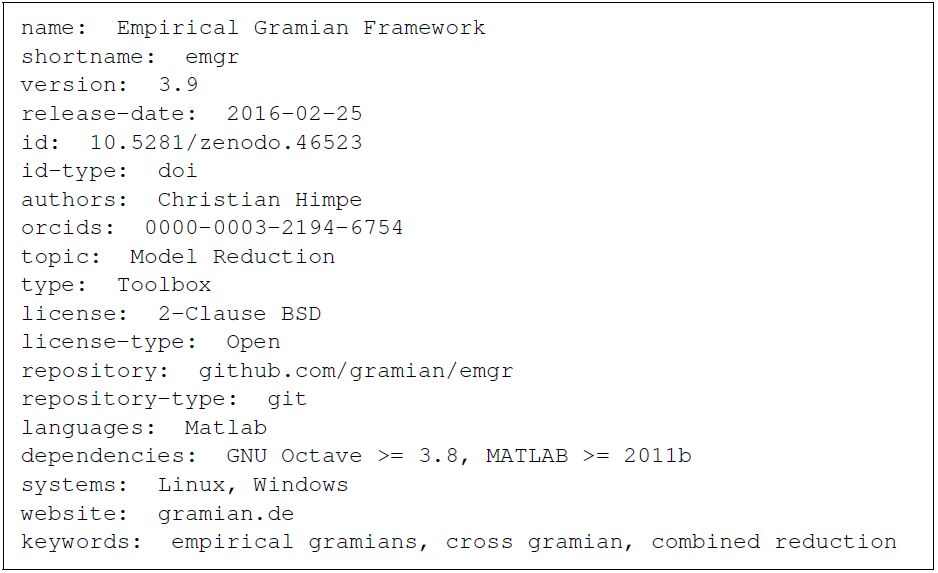
| [24] | 23. C. Himpe. emgr - Empirical Gramian framework (Version 3.9). gramian:de, 2016. URL http://dx:doi:org/10:5281/zenodo:46523. |
| [25] | 24. The Mathworks Inc. Matlab, Product Help, Matlab Release 2014b. Mathworks Inc., Natick MA, USA, 2014. |
| [26] | 25. D. C. Ince, L. Hatton, and J. Graham-Cumming. The case for open computer programs. Nature, 482:485–488, 2012. URL http://dx:doi:org/10:1038/nature10836. |
| [27] | 26. ipol. IPOL Journal - Image Processing On Line. URL http://www:ipol:im. Accessed: 2016-09-22. |
| [28] | 27. D. Irving. A minimum standard for publishing computational results in the weather and climate sciences. Bulletin of the American Meteorological Society, 2015. URL http://dx:doi:org/ 10:1175/BAMS-D-15-00010:1. |
| [29] | 28. ISO 646 - Information technology – ISO 7-bit coded character set for information interchange. ISO, International Organization for Standardization, 1991. URL http://www:iso:org/cate/ d4777:html. Accessed: 2016-09-22. |
| [30] | 29. ISO 8601 - Data elements and interchange formats – Information interchange – Representation of dates and times. ISO, International Organization for Standardization, 2004. URL http:// www:iso:org/iso/iso8601. Accessed: 2016-09-22. |
| [31] | 30. D. James, N. Wilkins-Diehr, V. Stodden, D. Colbry, and C. Rosales. Standing together for reproducibility in large-scale computing. In XSEDE14 Workshop, volume reproducibility@ XSEDE, 2014. URL http://xsede:org/documents/659353/d90df1cb-62b5- 47c7-9936-2de11113a40f. Accessed: 2016-09-22. |
| [32] | 31. L. K. John, G. Loewenstein, and D. Prelec. Measuring the prevalence of questionable research practices with incentives for truth telling. Psychological Science, 23(5):524–5 2012. URL http://dx:doi:org/10:1177/0956797611430953. |
| [33] | 32. L. N. Joppa, D. Gavaghan, R. Harper, K. Takeda, and S. Emmott. Optimizing peer review of software code – response. Science, 341(6143):237, 2013a. URL http://dx:doi:org/10:1126/ science:341:6143:237-a. |
| [34] | 33. L. N. Joppa, G. McInerny, R. Harper, L. Salido, K. Takeda, K. O’Hara, D. Gavaghan, and S. Emmott. Troubling trends in scientific software use. Science, (6134):814–815, 2013b. URL http://dx:doi:org/10:1126/science:1231535. |
| [35] | 34. D. Joyner and W. Stein. Open source mathematical software. Notices – American Mathematical Society, 54(10):1279, 2007. URL http://www:ams:org/notices/200710/ tx071001279p:pdf. Accessed: 2016-09-22. |
| [36] | 35. D. S. Katz and A. M. Smith. Transitive credit and JSON-LD. Journal of Open Research Software, 3(1), 2015. URL http://dx:doi:org/10:5334/jors:by. |
| [37] | 36. D. Kelly, D. Hook, and R. Sanders. Five recommended practices for computational scientists who write software. Computing in Science & Engineering, 11(5):48–53, 2009. URL http: //dx:doi:org/10:1109/MCSE:2009:139. |
| [38] | 37. S. Krishnamurthi and J. Vitek. The real software crisis: Repeatability as a core value. Communications of the ACM, 58(3):34–36, 2015. URL http://dx:doi:org/10:1145/2658987. |
| [39] | 38. R. J. LeVeque. Top ten reasons to not share your code (and why you should anyway). SIAM News, 46(3), 2013. URL http://archive:is/eAr7z. |
| [40] | 39. G. Marcus. The crisis in social psychology that isn’t. www:newyorker:com/tech/ elements/the-crisis-in-social-psychology-that-isnt, 2013. URL http: //archive:is/yBJy1. |
| [41] | 40. B. Marwick. Computational reproducibility in archaeological research: Basic principles and a case study of their implementation. Journal of Archaeological Method and Theory, pages 1–27, 2016. URL http://dx:doi:org/10:1007/s10816-015-9272-9. |
| [42] | 41. D. McCa erty. Should code be released? Communications of the ACM, 53(10):16–17, 2010. URL http://dx:doi:org/10:1145/1831407:1831415. |
| [43] | 42. Z. Merali. Computational science: ...error. Nature, 467:775–777, 2010. URL http:// dx:doi:org/10:1038/467775a. |
| [44] | 43. O. Mesnard and L. A. Barba. Reproducible and replicable CFD: it’s harder than you think. physics.comp-ph 1605.04339, arXiv, 2016. URL http://arxiv:org/abs/1605:04339. |
| [45] | 44. nature14. Code share. Nature, 514:536, 2014. URL http://dx:doi:org/10:1038/ 516a. |
| [46] | 45. nature15. Ctrl alt share. Scientific Data, 2, 2015. URL http://dx:doi:org/10:1038/ sdata:2015:4. |
| [47] | 46. J. Nitsche. Über ein Variationsprinzip zur Lösung von Dirichlet-Problemen bei Verwendung von Teilräumen, die keinen Randbedingungen unterworfen sind. Abhandlungen aus dem Mathematischen Seminar der Universität Hamburg, 36(1):9–15, 1971. URL http://dx:doi:org/ 10:1007/BF02995904. |
| [48] | 47. Open Science Collaboration. Estimating the reproducibility of psychological science. Science, 349 (6251), 2015. URL http://dx:doi:org/10:1126/science:aac4716. |
| [49] | 48. H. K. F. Panzer. Model Order Reduction by Krylov Subspace Methods with Global Error Bounds and Automatic Choice of Parameters. Dissertation, Technische Universität München, 2014. URL http://nbn-resolving:de/urn/resolver:pl?urn:nbn:de:bvb:91- diss-20140916-1207822-0-0. |
| [50] | 49. T. Penzl. Lyapack Users Guide. Technical report, Sonderforschungsbereich 393 Numerische Simulation auf massiv parallelen Rechnern, TU Chemnitz, 2000. URL http://www:netlib:org/ lyapack/guide:pdf. Accessed: 2016-09-22. |
| [51] | 50. K. R. Popper. The Logic of Scientific Discovery. Classics Series. Routledge, 2002. ISBN 9780415278447. |
| [52] | 51. A. Prli´c and J. B. Procter. Ten simple rules for the open development of scientific software. PLoS Computational Biology, 8(12):1–3, 2012. URL http://dx:doi:org/10:1371/ journal:pcbi:1002802. |
| [53] | 52. R Core Team. R: A Language and Environment for Statistical Computing. R Foundation for Statistical Computing, Vienna, Austria, 2014. URL http://R-project:org. |
| [54] | 53. Y. Saad and M. H. Schultz. GMRES: A generalized minimal residual algorithm for solving nonsymmetric linear systems. SIAM Journal on Scientific and Statistical Computing, 7(3):856–869, 1986. URL http://dx:doi:org/10:1137/0907058. |
| [55] | 54. T. C. Schulthess. Programming revisited. Nature Physics, 11(5):369–373, 2015. URL http: //dx:doi:org/10:1038/nphys3294. |
| [56] | 55. science. Publication policies: Data and materials availability after publication. www:sciencemag:org/authors/science-editorial-policies#publicationpolicies, 2016. URL http://archive:is/e4GT7. |
| [57] | 56. P. Sliz and A. Morin. Optimizing peer review of software code. Science, 341(6143):236–237, 2013. URL http://dx:doi:org/10:1126/science:341:6143:236-b. |
| [58] | 57. A. M. Smith. JSON-LD for software discovery, reuse and credit. www:arfon:org/json-ldfor- software-discovery-reuse-and-credit, 2014. URL http://archive:is/ BgMsx. |
| [59] | 58. V. Stodden. Enabling reproducible research: Open licensing for scientific innovation. International Journal of Communications Law and Policy, pages 1–55, 2009a. URL http://ssrn:com/ abstract=1362040. Accessed: 2016-09-22. |
| [60] | 59. V. Stodden. The legal framework for reproducible scientific research: Licensing and copyright. Computer in Science & Engineering, 11(1):35–40, 2009b. URL http://dx:doi:org/ 10:1109/MCSE:2009:19. |
| [61] | 60. V. Stodden and S. Miguez. Best practices for computational science: Software infrastructure and environments for reproducible and extensible research. Journal of Open Research Software, 2(1), 2014. URL http://dx:doi:org/10:5334/jors:ay. |
| [62] | 61. V. Stodden, D. H. Bailey, J. Borwein, R. J. LeVeque, W. Rider, and W. Stein. Setting the default to reproducible: Reproducibility in computational and experimental mathematics. Technical report, ICERM Report, 2013a. URL http://icerm:brown:edu/tw12-5-rcem/ icerm_report:pdf. Accessed: 2016-09-22. |
| [63] | 62. V. Stodden, J. Borwein, and D. H. Bailey. “Setting the default to reproducible” in computational science research. SIAM News, 46:4–6, 2013b. URL http://archive:is/ESi5J. |
| [64] | 63. D. L. Vaux, F. Fidler, and G. Cumming. Replicates and repeats—what is the di erence and is it significant? EMBO reports, 13(4):291–296, 2012. URL http://dx:doi:org/10:1038/ embor:2012:36. |
| [65] | 64. J. Vitek and T. Kalibera. Repeatability, reproducibility, and rigor in systems research. In Proceedings of the 9th ACM International Conference on Embedded Software, pages 33–38, 2011. URL http://dx:doi:org/10:1145/2038642:2038. |
| [66] | 65. G. Wilson, D. A. Aruliah, C. T. Brown, N. P. C. Hong, M. Davis, R. T. Guy, S. H. D. Haddock, K. D. Hu , I. M. Mitchell, M. D. Plumbley, B. Waugh, E. P. White, and P. Wilson. Best practices for scientific computing. PLoS Biology, 12(1), 2014. URL http://dx:doi:org/10:1371/ journal:pbio:1001745. |
| [67] | 66. G. Wilson, J. Bryan, K. Cranston, J. Kitzes, L. Nederbragt, and T. K. Teal. Good enough practices in scientific computing. cs.SE 1609.00037, arXiv, 2016. URL http://arxiv:org/abs/ 1609:00037 |

Figures(4)

Jörg Fehr, Jan Heiland, Christian Himpe, Jens Saak. Best practices for replicability, reproducibility and reusability of computer-based experiments exemplified by model reduction software[J]. AIMS Mathematics, 2016, 1(3): 261-281. doi: 10.3934/Math.2016.3.261







 DownLoad:
DownLoad: