Bankruptcy prediction is an important problem in finance, since successful predictions would allow stakeholders to take early actions to limit their economic losses. In recent years many studies have explored the application of machine learning models to bankruptcy prediction with financial ratios as predictors. This study extends this research by applying machine learning techniques to a quarterly data set covering financial ratios for a large sample of public U.S. firms from 1970–2019. We find that tree-based ensemble methods, especially XGBoost, can achieve a high degree of accuracy in out-of-sample bankruptcy prediction. We next apply our best model, using XGBoost, to the problem of predicting the overall bankruptcy rate in USA in the second half of 2020, after the COVID-19 pandemic had necessitated a lockdown, leading to a deep recession. Our model supports the prediction, made by leading economists, that the rate of bankruptcies will rise substantially in 2020, but it also suggests that this elevated level will not be much higher than 2010.
Citation: Aditya Narvekar, Debashis Guha. Bankruptcy prediction using machine learning and an application to the case of the COVID-19 recession[J]. Data Science in Finance and Economics, 2021, 1(2): 180-195. doi: 10.3934/DSFE.2021010
Bankruptcy prediction is an important problem in finance, since successful predictions would allow stakeholders to take early actions to limit their economic losses. In recent years many studies have explored the application of machine learning models to bankruptcy prediction with financial ratios as predictors. This study extends this research by applying machine learning techniques to a quarterly data set covering financial ratios for a large sample of public U.S. firms from 1970–2019. We find that tree-based ensemble methods, especially XGBoost, can achieve a high degree of accuracy in out-of-sample bankruptcy prediction. We next apply our best model, using XGBoost, to the problem of predicting the overall bankruptcy rate in USA in the second half of 2020, after the COVID-19 pandemic had necessitated a lockdown, leading to a deep recession. Our model supports the prediction, made by leading economists, that the rate of bankruptcies will rise substantially in 2020, but it also suggests that this elevated level will not be much higher than 2010.

| [1] | Altman EI (1968) The Prediction of Corporate Bankruptcy: A Discriminant Analysis. J Financ 23: 193-194. |
| [2] |
Barboza F, Kimura H, Altman E (2017) Machine learning models and bankruptcy prediction. Expert Syst Appl 83: 405-417. doi: 10.1016/j.eswa.2017.04.006

|
| [3] |
Beaver WH (1966) Financial Ratios As Predictors of Failure. J Account Res 4: 71-111. doi: 10.2307/2490171
|
| [4] | Bellovary JL, Giacomino DE, Akers MD (2007) A Review of Bankruptcy Prediction Studies: 1930 to Present. J Financ Educ 33: 1-42. |
| [5] | Beretta L, Santaniello A (2016) Nearest neighbor imputation algorithms: a critical evaluation. BMC Med Inf Decis Making 16: 197-208. |
| [6] | Cao B, Zhan D, Wu X (2009) Application of svm in financial research, In: CSO international joint conference on computational sciences and optimization, 2: 507-511. |
| [7] |
Chava S, Jarrow RA (2004) Bankruptcy Prediction with Industry Effects. Rev Financ 8: 537-569. doi: 10.1093/rof/8.4.537
|
| [8] |
Chawla NV, Bowyer KW, Hall LO, et al. (2002) SMOTE: Synthetic Minority Over-sampling Technique. J Artif Intell Res 16: 321-357. doi: 10.1613/jair.953
|
| [9] | Chen T, Guestrin C (2016) XGBoost: A scalable tree boosting system, In: Proc. of KDD'16, 785-794. |
| [10] | Chen WM, Ma CQ, Feng GB (2008) Application of SVM based on KMOD function in credit scoring. Math Econ 25: 24-27. |
| [11] |
Chen MY (2011) Bankruptcy prediction in firms with statistical and intelligent techniques and a comparison of evolutionary computation approaches. Comput Math Appl 62: 4514-4524. doi: 10.1016/j.camwa.2011.10.030
|
| [12] | Cortes C, Vapnik V (1995) Support-vector networks. Mach Learn 20: 273-297. |
| [13] |
Deakin EB (1972) A Discriminant Analysis of Predictors of Business Failure. J Account Res 10: 167-179. doi: 10.2307/2490225
|
| [14] |
Du Jardin P (2016) A two-stage classification technique for bankruptcy prediction. Eur J Oper Res 254: 236-252. doi: 10.1016/j.ejor.2016.03.008
|
| [15] |
Edmister RO (1972) An Empirical Test of Financial Ratio Analysis for Small Business Failure Prediction. J Financ Quant Anal 7: 1477-1493. doi: 10.2307/2329929
|
| [16] |
Fama, EF, French KR (1993) Common risk factors in the returns on stocks and bonds. J Financ Econ 33: 3-56. doi: 10.1016/0304-405X(93)90023-5
|
| [17] |
Fedorova E, Gilenko E, Dovzhenko S (2013) Bankruptcy prediction for Russian companies: Application of combined classifiers. Expert Syst Appl 40: 7285-7293. doi: 10.1016/j.eswa.2013.07.032
|
| [18] |
García V, Marqués AI, Sánchez JS (2015) An insight into the experimental design for credit risk and corporate bankruptcy prediction systems. J Intell Inf Syst 44: 159-189. doi: 10.1007/s10844-014-0333-4
|
| [19] | Gil Press (2021) Andrew Ng Launches A Campaign For Data-Centric AI. Forbes. Available from: https://www.forbes.com/sites/gilpress/2021/06/16/andrew-ng-launches-a-campaign-for-data-centric-ai/?sh=1b802f8d74f5. |
| [20] | Gnip P, Drotár P (2019) Ensemble methods for strongly imbalanced data: bankruptcy prediction, In: 2019 IEEE 17th International Symposium on Intelligent Systems and Informatics (SISY), 155-160. |
| [21] | He H, Bai Y, Garcia EA, et al. (2008) ADASYN: Adaptive synthetic sampling approach for imbalanced learning, In: 2008 IEEE International Joint Conference on Neural Networks (IEEE World Congress on Computational Intelligence), 1322-1328. |
| [22] |
Heo J, Yang JY (2014) AdaBoost based bankruptcy forecasting of Korean construction companies. Appl Soft Comput 24: 494-499. doi: 10.1016/j.asoc.2014.08.009
|
| [23] |
Huang W, Nakamori Y, Wang SY (2005) Forecasting stock market movement direction with support vector machine. Comput Oper Res 32: 2513-2522. doi: 10.1016/j.cor.2004.03.016
|
| [24] |
Huang Z, Chen H, Hsu CJ, et al. (2004) Credit rating analysis with support vector machines and neural networks: a market comparative study. Decis Support Syst 37: 543-558. doi: 10.1016/S0167-9236(03)00086-1
|
| [25] | Joshi S, Ramesh R, Tahsildar S (2018) A Bankruptcy Prediction Model Using Random Forest, In: Second International Conference on Intelligent Computing and Control Systems (ICICCS), 1-6. |
| [26] | Lyandres E, Zhdanov A (2007) Investment Opportunities and Bankruptcy Prediction. SSRN Electronic Journal. Available from: https://doi.org/10.2139/ssrn.946240. |
| [27] |
Min JH, Lee YC (2005) Bankruptcy prediction using support vector machine with optimal choice of kernel function parameters. Expert Syst Appl 28: 603-614. doi: 10.1016/j.eswa.2004.12.008
|
| [28] |
Nguyen HM, Cooper EW, Kamei K (2011) Borderline over-sampling for imbalanced data classification. Int J Knowl Eng Soft Data Paradigms 3: 4-21. doi: 10.1504/IJKESDP.2011.039875
|
| [29] |
Ohlson JA (1980) Financial Ratios and the Probabilistic Prediction of Bankruptcy. J Account Res 18: 109-131. doi: 10.2307/2490395
|
| [30] | Perboli G, Arabnezhad E (2021) A Machine Learning-based DSS for mid and long-term company crisis prediction. Expert Syst Appl 174: 114758. |
| [31] | Rustam Z, Saragih GS (2018) Predicting Bank Financial Failures using Random Forest. In 2018 International Workshop on Big Data and Information Security (IWBIS), 81-86. |
| [32] | Shi L, Xi L, Ma X, et al. (2009) Bagging of Artificial Neural Networks for Bankruptcy Prediction. 2009 International Conference on Information and Financial Engineering, Singapore, 154-156. |
| [33] | Song JK, Zhang ZX, Zhang Y (2008) Financial distress early-warning of companies based on multiclassification SVM. China Manage 4: 47-49. |
| [34] |
Wang G, Ma J, Yang S (2014) An improved boosting based on feature selection for corporate bankruptcy prediction. Expert Syst Appl 41: 2353-2361. doi: 10.1016/j.eswa.2013.09.033
|
| [35] | Wang H, Liu X (2021) Undersampling bankruptcy prediction: Taiwan bankruptcy data. PLoS ONE 16: e0254030. |
| [36] |
Wilson RL, Sharda R (1994) Bankruptcy prediction using neural networks. Decis Support Syst 11: 545-557. doi: 10.1016/0167-9236(94)90024-8
|
 DSFE-01-02-010-s001.pdf DSFE-01-02-010-s001.pdf |
 |

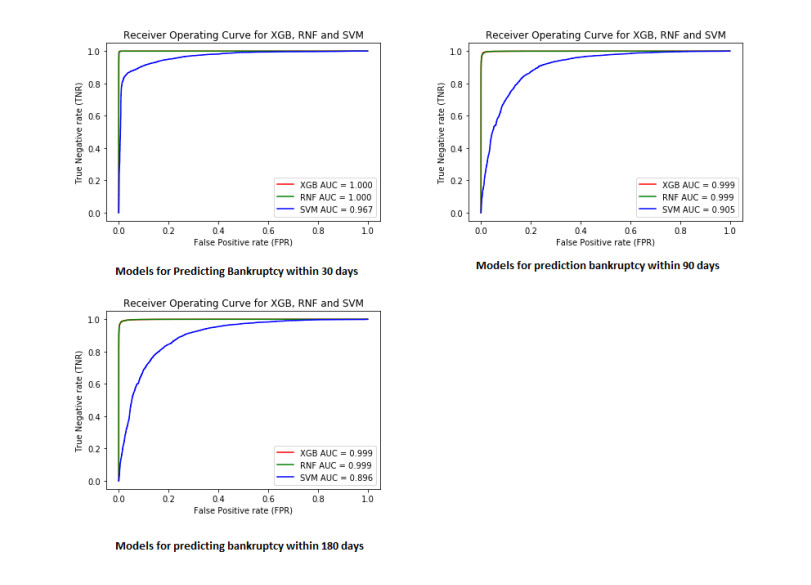
Figures(2) / Tables(7)
Aditya Narvekar, Debashis Guha. Bankruptcy prediction using machine learning and an application to the case of the COVID-19 recession[J]. Data Science in Finance and Economics, 2021, 1(2): 180-195. doi: 10.3934/DSFE.2021010







 DownLoad:
DownLoad: