Citation: Daniele Agostinelli, Roberto Cerbino, Juan C. Del Alamo, Antonio DeSimone, Stephanie Höhn, Cristian Micheletti, Giovanni Noselli, Eran Sharon, Julia Yeomans. MicroMotility: State of the art, recent accomplishments and perspectives on the mathematical modeling of bio-motility at microscopic scales[J]. Mathematics in Engineering, 2020, 2(2): 230-252. doi: 10.3934/mine.2020011

| [1] |
Agostinelli D, Alouges F, DeSimone A (2018) Peristaltic waves as optimal gaits in metameric bio-inspired robots. Front in Robot AI 5: 99. doi: 10.3389/frobt.2018.00099

|
| [2] | Agostinelli D, Lucantonio A, Noselli G, et al. (2019) Nutations in growing plant shoots: The role of elastic deformations due to gravity loading. J Mech Phys Solids 2019: 103702. DOI: 10.1016/j.jmps.2019.103702. |
| [3] |
Agostiniani V, DeSimone A, Lucantonio A, et al. (2018) Foldable structures made of hydrogel bilayers. Mathematics in Engineering 1: 204-223. doi: 10.3934/Mine.2018.1.204
|
| [4] |
Aguilar J, Zhang T, Qian F, et al. (2016) A review on locomotion robophysics: The study of movement at the intersection of robotics, soft matter and dynamical systems. Rep Prog Phys 79: 110001. doi: 10.1088/0034-4885/79/11/110001
|
| [5] | Alberts B, Watson J, Lewis J, et al. (2014) Molecular Biology of the Cell, New York: Garland Science. |
| [6] |
Alouges F, DeSimone A, Giraldi L, et al. (2019) Energy-optimal strokes for multi-link microswimmers: Purcell's loops and Taylor's waves reconciled. New J Phys 21: 043050. doi: 10.1088/1367-2630/ab1142
|
| [7] |
Alouges F, DeSimone A, Lefebvre A (2008) Optimal strokes for low reynolds number swimmers: An example. J Nonlinear Sci 18: 277-302. doi: 10.1007/s00332-007-9013-7
|
| [8] |
Armon S, Efrati E, Kupferman R, et al. (2011) Geometry and mechanics in the opening of chiral seed pods. Science 333: 1726-1730. doi: 10.1126/science.1203874
|
| [9] |
Armon S, Yanai O, Ori N, et al. (2014) Quantitative phenotyping of leaf margins in three dimensions, demonstrated on knotted and tcp trangenics in arabidopsis. J Exp Bot 65: 2071-2077. doi: 10.1093/jxb/eru062
|
| [10] |
Arsuaga J, Vazquez M, McGuirk P, et al. (2005) Dna knots reveal a chiral organization of dna in phage capsids. P Natl Acad Sci 102: 9165-9169. doi: 10.1073/pnas.0409323102
|
| [11] | Aydin YO, Rieser JM, Hubicki CM, et al. (2019) 6-physics approaches to natural locomotion: Every robot is an experiment, In: Walsh S.M. and Stran M.S., Robotic Systems and Autonomous Platforms, Woodhead Publishing in Materials, 109-127. |
| [12] |
Bertinetti L, Fischer FD, Fratzl P (2013) Physicochemical basis for water-actuated movement and stress generation in nonliving plant tissues. Phys Rev Lett 111: 238001. doi: 10.1103/PhysRevLett.111.238001
|
| [13] |
Buskermolen AB, Suresh H, Shishvan SS, et al. (2019) Entropic forces drive cellular contact guidance. Biophys J 116: 1994-2008. doi: 10.1016/j.bpj.2019.04.003
|
| [14] |
Bustamante C (2017) Molecular machines one molecule at a time. Protein Sci 26: 1245-1248. doi: 10.1002/pro.3205
|
| [15] |
Bustamante C, Keller D, Oster G (2001) The physics of molecular motors. Accounts Chem Res 34: 412-420. doi: 10.1021/ar0001719
|
| [16] |
Cavagna A, Giardina I, Grigera TS (2018) The physics of flocking: Correlation as a compass from experiments to theory. Phys Rep 728: 1-62. doi: 10.1016/j.physrep.2017.11.003
|
| [17] | Charras G, Paluch E (2008) Blebs lead the way: How to migrate without lamellipodia. Nat Rev Mol cell bio 9: 730-736. |
| [18] |
Chauvet H, Moulia B, Legué V, et al. (2019) Revealing the hierarchy of processes and time-scales that control the tropic response of shoots to gravi-stimulations. J Exp Bot 70: 1955-1967. doi: 10.1093/jxb/erz027
|
| [19] |
Cheung KJ, Gabrielson E, Werb Z, et al. (2013) Collective invasion in breast cancer requires a conserved basal epithelial program. Cell 155: 1639-1651. doi: 10.1016/j.cell.2013.11.029
|
| [20] |
Cicconofri G, DeSimone A (2015) A study of snake-like locomotion through the analysis of a flexible robot model. P Roy Soc A Math Phys Eng Sci 471: 20150054. doi: 10.1098/rspa.2015.0054
|
| [21] |
Cicconofri G, DeSimone A (2019) Modelling biological and bio-inspired swimming at microscopic scales: Recent results and perspectives. Comput Fluids 179: 799-805. doi: 10.1016/j.compfluid.2018.07.020
|
| [22] |
Danson CM, Pocha SM, Bloomberg GB, et al. (2007) Phosphorylation of wave2 by map kinases regulates persistent cell migration and polarity. J Cell Sci 120: 4144-4154. doi: 10.1242/jcs.013714
|
| [23] | Darwin C (1880) The Power of Movement in Plants, London: John Murray. |
| [24] |
Del Alamo JC, Meili R, Alonso-Latorre B, et al. (2007) Spatio-temporal analysis of eukaryotic cell motility by improved force cytometry. P Natl Acad Sci 104: 13343-13348. doi: 10.1073/pnas.0705815104
|
| [25] |
Doostmohammadi A, Ignes-Mullol J, Yeomans JM et al. (2018) Active nematics. Nat Commun 9: 3246. doi: 10.1038/s41467-018-05666-8
|
| [26] |
Efrati E, Sharon E, Kupferman R (2009) Buckling transition and boundary layer in non-euclidean plates. Phys Rev E 80: 016602. doi: 10.1103/PhysRevE.80.016602
|
| [27] |
Efrati E, Sharon E, Kupferman R (2009) Elastic theory of unconstrained non-euclidean plates. J Mech Phys Solids 57: 762-775. doi: 10.1016/j.jmps.2008.12.004
|
| [28] |
Frangipane G, Dell'Arciprete D, Petracchini S, et al. (2018) Dynamic density shaping of photokinetic E. coli. Elife 7: e36608. doi: 10.7554/eLife.36608
|
| [29] |
Fratzl P, Barth FG (2009) Biomaterial systems for mechanosensing and actuation. Nature 462: 442-448. doi: 10.1038/nature08603
|
| [30] |
Geyer VF, Sartori P, Friedrich BM, et al. (2016) Independent control of the static and dynamic components of the chlamydomonas flagellar beat. Curr Biol 26: 1098-1103. doi: 10.1016/j.cub.2016.02.053
|
| [31] |
Giavazzi F, Malinverno C, Corallino S, et al. (2017) Giant fluctuations and structural effects in a flocking epithelium. J Phys D Appl Phys 50: 384003. doi: 10.1088/1361-6463/aa7f8e
|
| [32] |
Giavazzi F, Paoluzzi M, Macchi M, et al. (2018) Flocking transitions in confluent tissues. Soft matter 14: 3471-3477. doi: 10.1039/C8SM00126J
|
| [33] |
Giedroc DP, Cornish PV (2009) Frameshifting rna pseudoknots: Structure and mechanism. Virus Res 139: 193-208. doi: 10.1016/j.virusres.2008.06.008
|
| [34] |
Giomi L, Bowick MJ, Ma X, et al. (2013) Defect annihilation and proliferation in active nematics. Phys Rev Lett 110: 228101. doi: 10.1103/PhysRevLett.110.228101
|
| [35] |
Giomi L, Bowick MJ, Mishra P, et al. (2014) Defect dynamics in active nematics. Philos T Roy Soc A 372: 20130365. doi: 10.1098/rsta.2013.0365
|
| [36] |
Gladman AS, Matsumoto EA, Nuzzo RG, et al. (2016) Biomimetic 4d printing. Nat Mater 15: 413-418. doi: 10.1038/nmat4544
|
| [37] |
Goldstein RE, van de Meent JW (2015) A physical perspective on cytoplasmic streaming. Interface Focus 5: 20150030. doi: 10.1098/rsfs.2015.0030
|
| [38] |
Guasto JS, Rusconi R, Stocker R (2012) Fluid mechanics of planktonic microorganisms. Annu Rev Fluid Mech 44: 373-400. doi: 10.1146/annurev-fluid-120710-101156
|
| [39] |
Haas PA, Höhn SS, Honerkamp-Smith AR, et al. (2018) The noisy basis of morphogenesis: Mechanisms and mechanics of cell sheet folding inferred from developmental variability. PLoS Biol 16: e2005536. doi: 10.1371/journal.pbio.2005536
|
| [40] |
Hakim V, Silberzan P (2017) Collective cell migration: A physics perspective. Rep Prog Phys 80: 076601. doi: 10.1088/1361-6633/aa65ef
|
| [41] |
Hofhuis H, Moulton D, Lessinnes T, et al. (2016) Morphomechanical innovation drives explosive seed dispersal. Cell 166: 222-233. doi: 10.1016/j.cell.2016.05.002
|
| [42] |
Höhn S, Hallmann A (2011) There is more than one way to turn a spherical cellular monolayer inside out: Type B embryo inversion in volvox globator. BMC biol 9: 89. doi: 10.1186/1741-7007-9-89
|
| [43] |
Höhn S, Hallmann A (2016) Distinct shape-shifting regimes of bowl-shaped cell sheets-embryonic inversion in the multicellular green alga pleodorina. BMC Dev Biol 16: 35. doi: 10.1186/s12861-016-0134-9
|
| [44] |
Höhn S, Honerkamp-Smith AR, Haas PA, et al. (2015) Dynamics of a volvox embryo turning itself inside out. Phys Rev Lett 114: 178101. doi: 10.1103/PhysRevLett.114.178101
|
| [45] |
Hosoi A, Goldman DI (2015) Beneath our feet: Strategies for locomotion in granular media. Annu Rev Fluid Mech 47: 431-453. doi: 10.1146/annurev-fluid-010313-141324
|
| [46] |
Huss JC, Spaeker O, Gierlinger N, et al. (2018) Temperature-induced self-sealing capability of banksia follicles. J R Soc Interface 15: 20180190. doi: 10.1098/rsif.2018.0190
|
| [47] |
Ilievski F, Mazzeo AD, Shepherd RF, et al. (2011) Soft robotics for chemists. Angew Chem Int Edit 50: 1890-1895. doi: 10.1002/anie.201006464
|
| [48] |
Ishimoto K, Gadêlha H, Gaffney EA, et al. (2017) Coarse-graining the fluid flow around a human sperm. Phys Rev Lett 118: 124501. doi: 10.1103/PhysRevLett.118.124501
|
| [49] | Kawaguchi K, Kageyama R, Sano M (2009) Topological defects control collective dynamics in neural progenitor cell cultures. Nature 545: 327-331. |
| [50] |
Keller D, Bustamante C (2000) The mechanochemistry of molecular motors. Biophys J 78: 541-556. doi: 10.1016/S0006-3495(00)76615-X
|
| [51] |
Keller R, Davidson LA, Shook DR (2003) How we are shaped: The biomechanics of gastrulation. Differentiation 71: 171-205. doi: 10.1046/j.1432-0436.2003.710301.x
|
| [52] |
Khalil AA, Ilina O, Gritsenko PG, et al. (2017) Collective invasion in ductal and lobular breast cancer associates with distant metastasis. Clin Exp Metastas 34: 421-429. doi: 10.1007/s10585-017-9858-6
|
| [53] |
Kim J, Hanna JA, Hayward RC, et al. (2012) Thermally responsive rolling of thin gel strips with discrete variations in swelling. Soft Matter 8: 2375-2381. doi: 10.1039/c2sm06681e
|
| [54] |
Kim J, Hanna JA, Byun M, et al. (2012) Designing responsive buckled surfaces by halftone gel lithography. Science 335: 1201-1205. doi: 10.1126/science.1215309
|
| [55] |
Kim S, Laschi C, Trimmer B (2013) Soft robotics: A bioinspired evolution in robotics. Trends Biotechnol 31: 287-294. doi: 10.1016/j.tibtech.2013.03.002
|
| [56] |
Klein Y, Efrati E, Sharon E (2007) Shaping of elastic sheets by prescription of non-euclidean metrics. Science 315: 1116-1120. doi: 10.1126/science.1135994
|
| [57] |
Klein Y, Venkataramani S, Sharon E (2011) Experimental study of shape transitions and energy scaling in thin non-euclidean plates. Phys Rev Lett 106: 118303. doi: 10.1103/PhysRevLett.106.118303
|
| [58] | Laschi C, Mazzolai B (2016) Lessons from animals and plants: The symbiosis of morphological computation and soft robotics. IEEE Robot Autom Mag 23: 107-114. |
| [59] |
Latorre E, Kale S, Casares L, et al. (2018) Active superelasticity in three-dimensional epithelia of controlled shape. Nature 563: 203-208. doi: 10.1038/s41586-018-0671-4
|
| [60] |
Lauga E, Powers TR (2009) The hydrodynamics of swimming microorganisms. Rep Prog Phys 72: 096601. doi: 10.1088/0034-4885/72/9/096601
|
| [61] |
Lewis OL, Zhang S, Guy RD, et al. (2015) Coordination of contractility, adhesion and flow in migrating physarum amoebae. J R Soc Interface 12: 20141359. doi: 10.1098/rsif.2014.1359
|
| [62] |
Malinverno C, Corallino S, Giavazzi F, et al. (2017) Endocytic reawakening of motility in jammed epithelia. Nat Mater 16: 587-596. doi: 10.1038/nmat4848
|
| [63] |
Marchetti MC, Joanny JF, Ramaswamy S, et al. (2013) Hydrodynamics of soft active matter. Rev Mod Phys 85: 1143-1189. doi: 10.1103/RevModPhys.85.1143
|
| [64] |
Marenduzzo D, Micheletti C, Orlandini E, et al. (2013) Topological friction strongly affects viral dna ejection. P Natl Acad Sci 110: 20081-20086. doi: 10.1073/pnas.1306601110
|
| [65] |
Matt G, Umen J (2016) Volvox: A simple algal model for embryogenesis, morphogenesis and cellular differentiation. Dev Biol 419: 99-113. doi: 10.1016/j.ydbio.2016.07.014
|
| [66] |
Michor F, Liphardt J, Ferrari M, et al. (2011) What does physics have to do with cancer? Nat Rev Cancer 11: 657-670. doi: 10.1038/nrc3092
|
| [67] |
Moshe M, Sharon E, Kupferman R (2013) Pattern selection and multiscale behaviour in metrically discontinuous non-euclidean plates. Nonlinearity 26: 3247. doi: 10.1088/0951-7715/26/12/3247
|
| [68] |
Mueller R, Yeomans JM, Doostmohammadi A (2019) Emergence of active nematic behavior in monolayers of isotropic cells. Phys Rev Lett 122: 048004. doi: 10.1103/PhysRevLett.122.048004
|
| [69] |
Noselli G, Arroyo M, DeSimone A (2019) Smart helical structures inspired by the pellicle of euglenids. J Mech Phys Solids 123: 234-246. doi: 10.1016/j.jmps.2018.09.036
|
| [70] |
Noselli G, Beran A, Arroyo M, et al. (2019) Swimming euglena respond to confinement with a behavioural change enabling effective crawling. Nat Phys 15: 496-502. doi: 10.1038/s41567-019-0425-8
|
| [71] |
Olavarrieta L, Hernandez P, Krimer DB, et al (2002) Dna knotting caused by head-on collision of transcription and replication. J Mol biol 322: 1-6. doi: 10.1016/S0022-2836(02)00740-4
|
| [72] |
Palamidessi A, Malinverno C, Frittoli E, et al. (2019) Unjamming overcomes kinetic and proliferation arrest in terminally differentiated cells and promotes collective motility of carcinoma. Nat Mater 18: 1252-1263. doi: 10.1038/s41563-019-0425-1
|
| [73] |
Park JA, Kim JH, Bi D, et al. (2015) Unjamming and cell shape in the asthmatic airway epithelium. Nature Mater 14: 1040-1048. doi: 10.1038/nmat4357
|
| [74] |
Peng C, Turiv T, Guo Y, et al. (2016) Command of active matter by topological defects and patterns. Science 354: 882-885. doi: 10.1126/science.aah6936
|
| [75] |
Plesa C, Verschueren D, Pud S, et al. (2016) Direct observation of dna knots using a solid-state nanopore. Nature Nanotechnol 11: 1093-1097. doi: 10.1038/nnano.2016.153
|
| [76] |
Radszuweit M, Alonso S, Engel H, et al. (2013) Intracellular mechanochemical waves in an active poroelastic model. Phys Rev Lett 110: 138102. doi: 10.1103/PhysRevLett.110.138102
|
| [77] |
Renkawitz J, Kopf A, Stopp J, et al. (2019) Nuclear positioning facilitates amoeboid migration along the path of least resistance. Nature 569: 546-550. doi: 10.1038/s41586-019-1193-4
|
| [78] |
Rosa A, Di Ventra M, Micheletti C (2012) Topological jamming of spontaneously knotted polyelectrolyte chains driven through a nanopore. Phys Rev Lett 109: 118301. doi: 10.1103/PhysRevLett.109.118301
|
| [79] |
Rossi M, Cicconofri G, Beran A, et al. (2017) Kinematics of flagellar swimming in euglena gracilis: Helical trajectories and flagellar shapes. P Natl Acady Sci 114: 13085-13090. doi: 10.1073/pnas.1708064114
|
| [80] |
Sahaf M, Sharon E (2016) The rheology of a growing leaf: Stress-induced changes in the mechanical properties of leaves. J Exp Bot 67: 5509-5515. doi: 10.1093/jxb/erw316
|
| [81] |
Sanchez T, Chen DT, DeCamp SJ, et al. (2012) Spontaneous motion in hierarchically assembled active matter. Nature 491: 431-434. doi: 10.1038/nature11591
|
| [82] |
Sartori P, Geyer VF, Howard J, et al. (2016) Curvature regulation of the ciliary beat through axonemal twist. Phys Rev E 94: 042426. doi: 10.1103/PhysRevE.94.042426
|
| [83] |
Sartori P, Geyer VF, Scholich A, et al. (2016) Dynamic curvature regulation accounts for the symmetric and asymmetric beats of Chlamydomonas flagella. eLife 5: e13258. doi: 10.7554/eLife.13258
|
| [84] |
Saw TB, Doostmohammadi A, Nier V, et al. (2017) Topological defects in epithelia govern cell death and extrusion. Nature 544: 212-216. doi: 10.1038/nature21718
|
| [85] | Sharon E, Roman B, Marder M, et al. (2002) Mechanics: Buckling cascades in free sheets. Nature 419: 579. |
| [86] |
Shishvan SS, Vigliotti A, Deshpande VS (2018) The homeostatic ensemble for cells. Biomech Model Mechan 17: 1631-1662. doi: 10.1007/s10237-018-1048-1
|
| [87] |
Steinbock L, Radenovic A (2015) The emergence of nanopores in next-generation sequencing. Nanotechnology 26: 074003. doi: 10.1088/0957-4484/26/7/074003
|
| [88] |
Suma A, Micheletti C (2017) Pore translocation of knotted dna rings. P Natl Acad Sci 114: E2991-E2997. doi: 10.1073/pnas.1701321114
|
| [89] |
Suma A, Rosa A, Micheletti C (2015) Pore translocation of knotted polymer chains: How friction depends on knot complexity. ACS Macro Lett 4: 1420-1424. doi: 10.1021/acsmacrolett.5b00747
|
| [90] |
Tada M, Heisenberg CP (2012) Convergent extension: Using collective cell migration and cell intercalation to shape embryos. Development 139: 3897-3904. doi: 10.1242/dev.073007
|
| [91] |
Thampi SP, Golestanian R, Yeomans JM (2013) Velocity correlations in an active nematic. Phys Rev Lett 111: 118101. doi: 10.1103/PhysRevLett.111.118101
|
| [92] |
Thampi SP, Yeomans JM (2016) Active turbulence in active nematics. Eur Phys J Spec Top 225: 651-662. doi: 10.1140/epjst/e2015-50324-3
|
| [93] |
Tovo A, Suweis S, Formentin M, et al. (2017) Upscaling species richness and abundances in tropical forests. Sci Adv 3: e1701438. doi: 10.1126/sciadv.1701438
|
| [94] |
Vizsnyiczai G, Frangipane G, Maggi C, et al. (2017) Light controlled 3D micromotors powered by bacteria. Nat Commun 8: 15974. doi: 10.1038/ncomms15974
|
| [95] |
Wolf K, Mazo I, Leung H, et al. (2003) Compensation mechanism in tumor cell migration: mesenchymal-amoeboid transition after blocking of pericellular proteolysis. J Cell Biol 160: 267-277. doi: 10.1083/jcb.200209006
|
| [96] |
Yeh YT, Serrano R, François J, et al. (2018) Three-dimensional forces exerted by leukocytes and vascular endothelial cells dynamically facilitate diapedesis. P Natl Acad Sci 115: 133-138. doi: 10.1073/pnas.1717489115
|
| [97] |
Zhang AT, Montgomery MG, Leslie AGW, et al. (2019) The structure of the catalytic domain of the atp synthase from mycobacterium smegmatis is a target for developing antitubercular drugs. P Natl Acad Sci 116: 4206-4211. doi: 10.1073/pnas.1817615116
|
| [98] |
Zhang S, Guy RD, Lasheras JC, et al. (2017) Self-organized mechano-chemical dynamics in amoeboid locomotion of physarum fragments. J Phys D Appl Phys 50: 204004. doi: 10.1088/1361-6463/aa68be
|
| [99] |
Zhang S, Skinner D, Joshi P, et al. (2019) Quantifying the mechanics of locomotion of the schistosome pathogen with respect to changes in its physical environment. J R Soc Interface 16: 20180675. doi: 10.1098/rsif.2018.0675
|
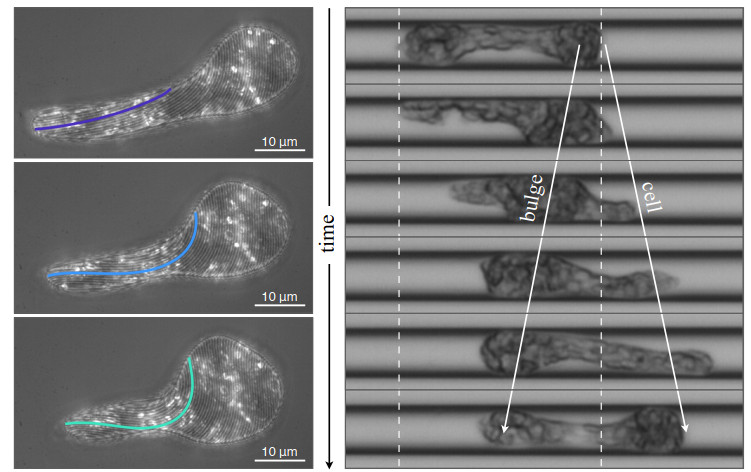

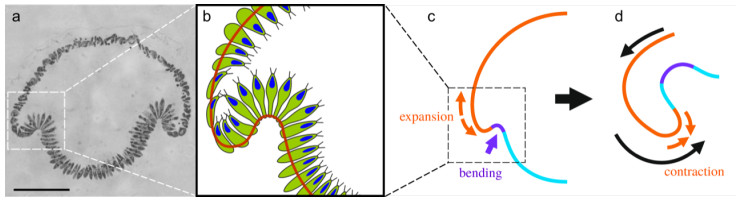
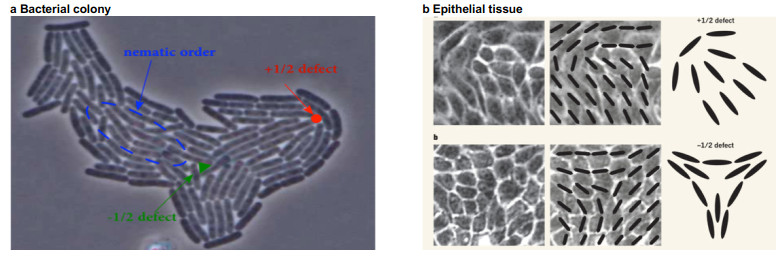
Figures(4)

Daniele Agostinelli, Roberto Cerbino, Juan C. Del Alamo, Antonio DeSimone, Stephanie Höhn, Cristian Micheletti, Giovanni Noselli, Eran Sharon, Julia Yeomans. MicroMotility: State of the art, recent accomplishments and perspectives on the mathematical modeling of bio-motility at microscopic scales[J]. Mathematics in Engineering, 2020, 2(2): 230-252. doi: 10.3934/mine.2020011







 DownLoad:
DownLoad: