Citation: Kai Zhang, Yunpeng Ji, Qiuwei Pan, Yumei Wei, Yong Ye, Hua Liu. Sensitivity analysis and optimal treatment control for a mathematical model of Human Papillomavirus infection[J]. AIMS Mathematics, 2020, 5(3): 2646-2670. doi: 10.3934/math.2020172

| [1] | J. G. Baseman, L. A. Koutsky. The epidemiology of human papillomavirus infections, J. Clin. Virol., 32 (2005), 16-24. |
| [2] |
F. X. Bosch, A. Lorincz, N. Munoz, et al. The causal relation between human papillomavirus and cervical cancer, J. Clin. Pathol., 55 (2002), 244-265. doi: 10.1136/jcp.55.4.244

|
| [3] |
D. Parkin, F. Bray, J. Ferlay, et al. Estimating the world cancer burden: Globocan 2000, Int. J. Cancer, 94 (2001), 153-156. doi: 10.1002/ijc.1440
|
| [4] |
D. M. Parkin, F. Bray, J. Ferlay, et al. Global cancer statistics, 2002, CA: A Cancer Journal for Clinicians, 55 (2005), 74-108. doi: 10.3322/canjclin.55.2.74
|
| [5] |
L. Bruni, M. Diaz, X. Castellsagué, et al. Cervical human papillomavirus prevalence in 5 continents: meta-analysis of 1 million women with normal cytological findings, The Journal of Infections Disease, 202 (2010), 1789-1799. doi: 10.1086/657321
|
| [6] | D. Foreman, C. de Martel, C. J. Lacey, et al. Global burden of human papillomavirus and related diseases, Vaccine, 30 (2012), F12-F23. |
| [7] |
F. X. Bosch, A. Lorincz, N. Munoz, et al. The causal relation between human papillomavirus and cervical cancer, J. Clin. Pathol., 55 (2002), 244-265. doi: 10.1136/jcp.55.4.244
|
| [8] |
J. M. Walboomers, M. V. Jacobs, M. M. Manos, et al. Human papillomavirus is a necessary cause of invasive cervical cancer worldwide, The Journal of Pathology, 189 (1999), 12-19. doi: 10.1002/(SICI)1096-9896(199909)189:1<12::AID-PATH431>3.0.CO;2-F
|
| [9] | K. Syrjanen, M. Hakama, S. Saarikoski, et al. Prevalence, incidence, and estimated life-time risk of cervical human papillomavirus infections in a nonselected Finnish female population, Sex. Transm. Dis., 17 (1990), 15-19. |
| [10] |
G. Y. F. Ho, R. Bierman, L. Beardsley, et al. Natural history of cervicovaginal papillomavirus infection in young women, New Engl. J. Med., 338 (1998), 423-428. doi: 10.1056/NEJM199802123380703
|
| [11] | A. B. Mosciki, S. Shiboski, J. Broering, et al. The natural history of human papillomavirus infection as measured by repeated DNA testing in adolescent and young women, Journal of Pediatrics, 2 (1998), 277-284. |
| [12] |
S. B. Cantor, E. N. Atkinson, M. Cardenas-Turanzas, et al. Natural history of cervical intraepithelial neoplasia: a meta-analysis, Acta Cytol., 49 (2005), 405-415. doi: 10.1159/000326174
|
| [13] | H. W. Chesson, J. M. Blandford, T. L. Gift, et al. The estimated direct medical costs of sexually transmitted diseases among American youth, 2000, Perspect Sex Reprod Health, 6 (2004), 11-19. |
| [14] |
H. N. Coleman, W. W. Greenfield, S. L. Stratton, et al. Human papillomavirus type 16 viral load is decreased following a therapeutic vaccination, Cancer Immunol Immunother, 65 (2016), 563-573. doi: 10.1007/s00262-016-1821-x
|
| [15] | H. Gemma, H. Karin, D. Lucy, Therapeutic HPV vaccines, Best Practice & Research Clinical Obstetrics and Gynaecology, 47 (2018), 59-72. |
| [16] | A. Omame, R. A. Umana, D. Okuonghae, et al. Mathematical analysis of a two-sex Human Papillomavirus (HPV) model, Int. J. Biomath., 7 (2018), 43. |
| [17] |
Elamin H, Elbasha, E. J. Dasbach, R. P. Insinga, A Multi-Type HPV Transmission Model, B. Math. Biol., 70 (2008), 2126-2176. doi: 10.1007/s11538-008-9338-x
|
| [18] |
Elamin H, Elbasha, Global Stability of Equilibria in a Two-Sex HPV Vaccination Model, B. Math. Biol., 70 (2008), 894-909. doi: 10.1007/s11538-007-9283-0
|
| [19] |
A. Mo'tassem, S. Robert, An age-structured model of human papilloma virus vaccination, Math. Comput. Simulat., 82 (2011), 629-652. doi: 10.1016/j.matcom.2011.10.006
|
| [20] | E. B. M. Bashier, K. C. Patidar, Optimal control of an epidemiological model with multiple time delays, Appl. Math. Comput., 292 (2017), 47-56. |
| [21] |
X. Wang, H. Peng, S. Yang, et al. Optimal vaccination strategy of a constrained time-varying SEIR epidemic model, Commun. Nonlinear Sci., 67 (2019), 37-48. doi: 10.1016/j.cnsns.2018.07.003
|
| [22] |
T. K. Kar, AshimBatabyal, Stability analysis and optimal control of an SIR epidemic model with vaccination, Biosystems, 104 (2011), 127-135. doi: 10.1016/j.biosystems.2011.02.001
|
| [23] |
Y. Yang, S. Y. Tang, X. H. Ren, et al. Global stability and optimal control for a tuberculosis model with vaccination and treatment, Discrete and continuous dynamical systems series B, 21 (2016), 1009-1022. doi: 10.3934/dcdsb.2016.21.1009
|
| [24] | F. X. Bosch, A. Lorincz, N. Munoz, et al. The causal relation between human papillomavirus and cervical cancer, J. Clin. Pathol., 55 (2002), 244. |
| [25] | S. Lakshmikantham, S. Leela, A. A. Martynyuk, Stability Analysis of Nonlinear Systems, Marcel Dekker, New York. 1989. |
| [26] |
H. W. Hethcote, The mathematics of infectious diseases, Siam Rev., 42 (2000), 599-653. doi: 10.1137/S0036144500371907
|
| [27] |
P. van den Driessche, J. Watmough, Reproduction numbers and sub-threshold endemic equilibria for compartmental models of disease transmission, Math. Biosci., 180 (2002), 29-48. doi: 10.1016/S0025-5564(02)00108-6
|
| [28] |
O. Sharomi, C. N. Podder, A. B. Gumel, et al. Modelling the Transmission Dynamics and Control of Novel 2009 Swine Influenza (H1N1) Pandemic, B. Math. Biol., 73 (2011), 515-548. doi: 10.1007/s11538-010-9538-z
|
| [29] | L. Perko, Differential Equations and Dynamical Systems, Springer, New York, 1996. |
| [30] | CIA World Factbook, South Africa Demographics Profile, 2016. |
| [31] |
M. T. Malik, J. Reimer, A. B. Gumel, et al. The impact of an imperfect vaccine and pap cytology screening on the transmission of human papillomavirus and occurrence of associated cervical dysplasia and cancer, Math. Biosci. Eng., 10 (2013), 1173-1205. doi: 10.3934/mbe.2013.10.1173
|
| [32] |
A. A. Alsaleh, A. B. Gumel, Dynamics of a vaccination model for HPV transmission, J. Biol. Syst., 22 (2014), 555-599. doi: 10.1142/S0218339014500211
|
| [33] |
A. A. Alsaleh, A. B. Gumel, Analysis of a risk-structured vaccination model for the dynamics of oncogenic and warts-causing HPV types, B. Math. Biol., 76 (2014), 1670-1726. doi: 10.1007/s11538-014-9972-4
|
| [34] |
H. Huo, L. X. Feng, Global stability for an HIV/AIDS epidemic model with different latent stages and treatment, Appl. Math. Model., 37 (2013), 1480-1489. doi: 10.1016/j.apm.2012.04.013
|
| [35] |
M. Simeone, B. H. Ian, J. R. Christian, et al. A methodology for performing global uncertainty and sensitivity analysis in systems biology, J. Theor. Biol., 254 (2008), 178-196. doi: 10.1016/j.jtbi.2008.04.011
|
| [36] | S. M. Blower, H. Dowlatabadi, Sensitivity and uncertainty analysis of complex models of disease transmission: An HIV model, as an example, Int. Stat. Rev., 2 (1994), 229-243. |
| [37] |
R. Jan, Y. N. Xiao, Effect of partial immunity on transmission dynamics of dengue disease with optimal control, Mathematical Methods in the Applied Sciences, 42 (2019), 1967-1983. doi: 10.1002/mma.5491
|
| [38] | W. Wang, Backward bifurcation of an epidemic model with treatment, Math. Biosci., 201 (2016), 58-71. |
| [39] |
M. H. A. Biswas, L. T. Paiva, M. Do Rosario de Pinho, A SEIR model for control of infectious diseases with constraints, Math. Biosci. Eng., 11 (2014), 761-784. doi: 10.3934/mbe.2014.11.761
|
| [40] |
H. Peng, X. Wang, B. Shi, et al. Stabilizing constrained chaotic system using a symplectic psuedospectral method, Commun. Nonlinear Sci., 56 (2018), 77-92. doi: 10.1016/j.cnsns.2017.07.028
|
| [41] |
X. Wang, H. Peng, S. Zhang, et al. A symplectic pseudospectral method for nonlinear optimal control problems with inequality constraints, ISA T., 68 (2017), 335-352. doi: 10.1016/j.isatra.2017.02.018
|
| [42] |
X. Wang, J. Liu, Y. Zhang, et al. A unified symplectic pseudospectral method for motion planning and tracking control of 3D underactuated overhead cranes, International Journal of Robust Nonlinear Control, 29 (2019), 2236-2253. doi: 10.1002/rnc.4488
|
| [43] | X. Wang, H. Peng, D. Jiang, et al. Optimal Path Planning of Two-Wheeled Mobile Robots in the Presence of Dynamic Obstacles, The 36th Chinese Control Conference, IEEE, 2017. |
| [44] | J. Liu, W. Han, X. Wang, et al. Research on Cooperative Trajectory Planning and Tracking Problem for Multiple Carrier Aircraft on the Deck, IEEE System Journal, 2019. |
| [45] | C. Castillo-Chavez, B. Song, Dynamical models of tuberculosis and their applications, Math. Biosci. Eng., 2 (2004), 361-404. |
| [46] | J. Carr, Applications Centre Manifold Theory, New York: Springer, 1981. |
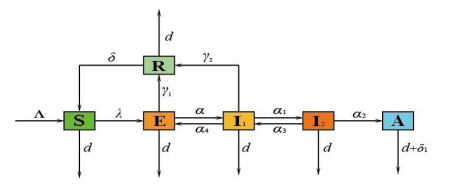
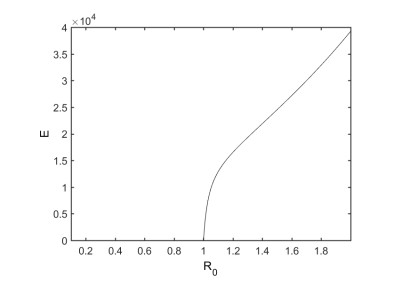
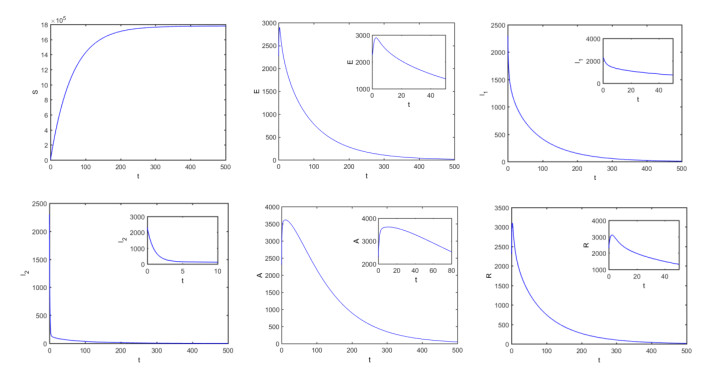
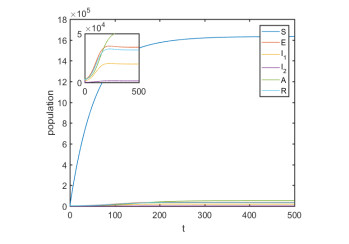
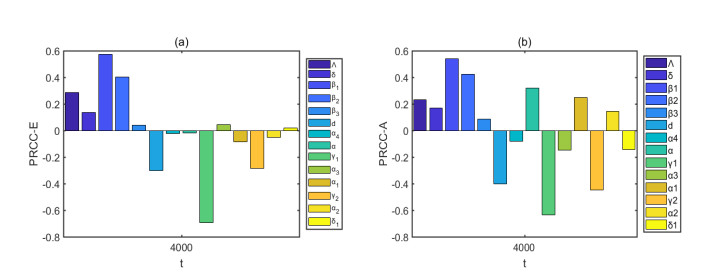
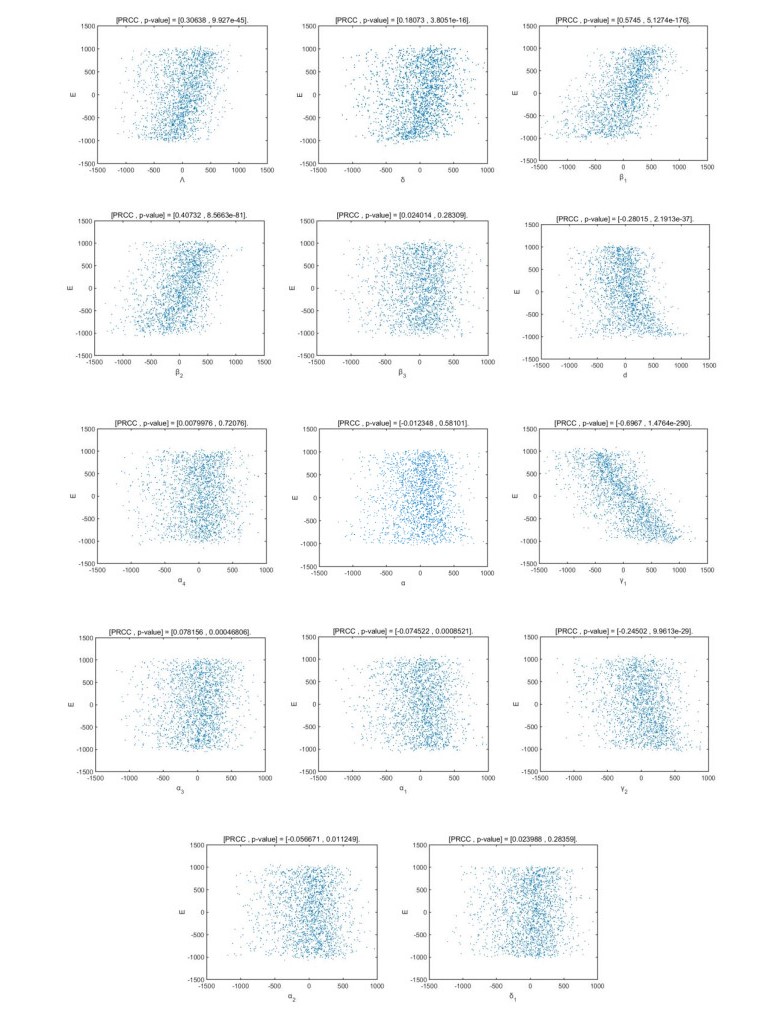
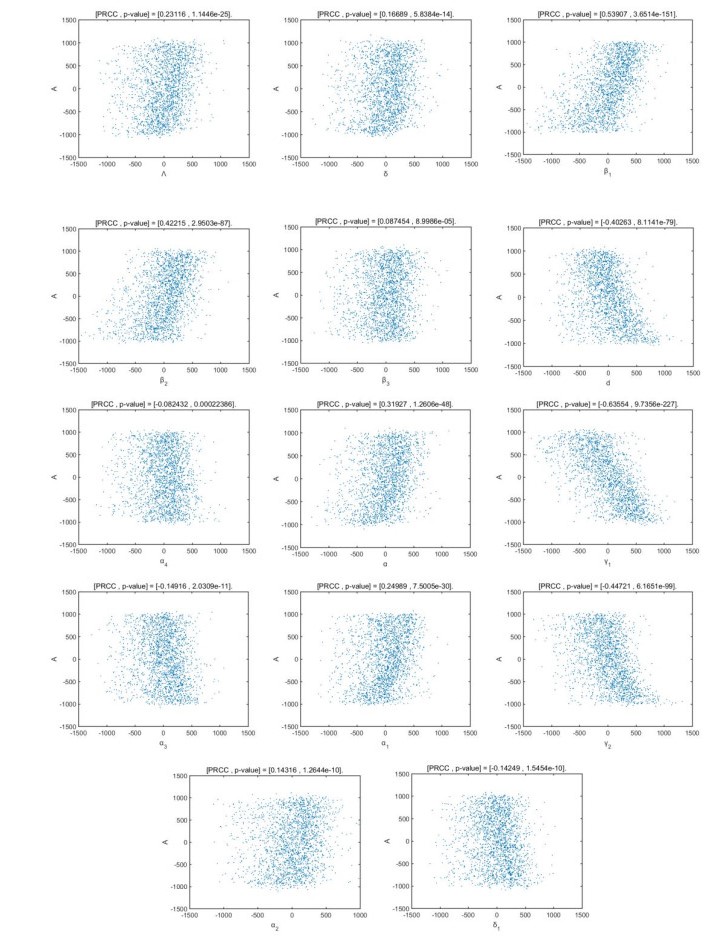
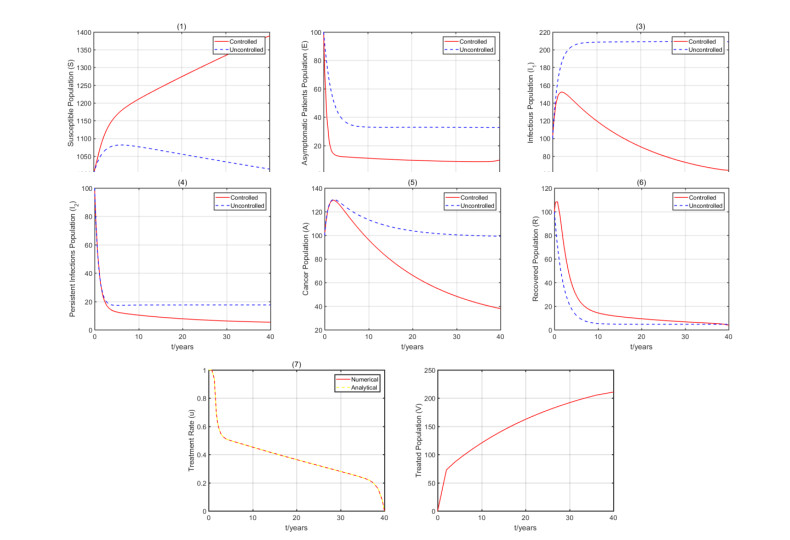
Figures(12) / Tables(6)

Kai Zhang, Yunpeng Ji, Qiuwei Pan, Yumei Wei, Yong Ye, Hua Liu. Sensitivity analysis and optimal treatment control for a mathematical model of Human Papillomavirus infection[J]. AIMS Mathematics, 2020, 5(3): 2646-2670. doi: 10.3934/math.2020172







 DownLoad:
DownLoad: