Citation: Wanchun Fan, Yan Jiang, Songyang Huang, Weiguo Liu. Research and prediction of opioid crisis based on BP neural network and Markov chain[J]. AIMS Mathematics, 2019, 4(5): 1357-1368. doi: 10.3934/math.2019.5.1357

| [1] | X. Xianhai, Fisher ordered clustering method and its application in extraction of temperature anomalies in furnace tubes, Guangxi Dianli, (2005), 15-17. |
| [2] | H. Dan, A review of sociological theories on drug abuse abroad-a case study of relevant research results in the United States, Realism, (2010), 86-89. |
| [3] |
C. S. Davis, A. J. Lieberman, H. Hernandez-Delgado, et al. Laws limiting the prescribing or dispensing of opioids for acute pain in the United States:A national systematic legal review., Drug Alcohol Depen., 194 (2019), 166-172. doi: 10.1016/j.drugalcdep.2018.09.022

|
| [4] | W. Ke, P. Hemin, G. Jiatai, Research on the spread of opioid abuse and its trend prediction, Journal of Technology Wind, (2019), 244. |
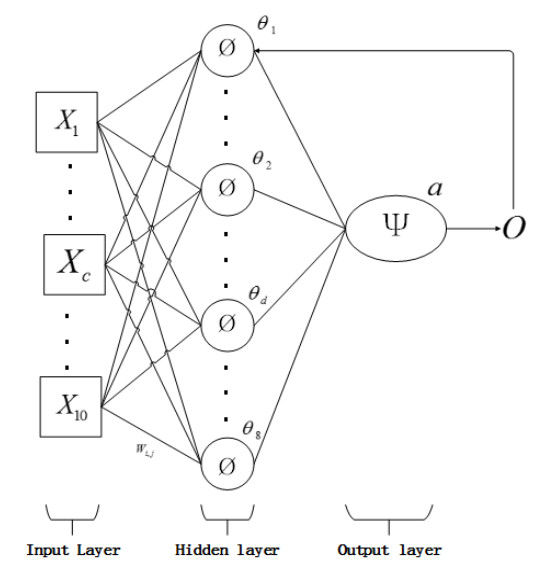
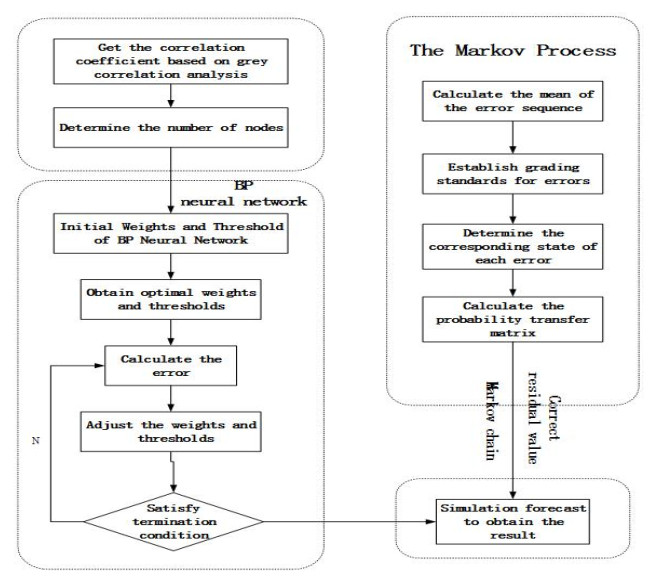
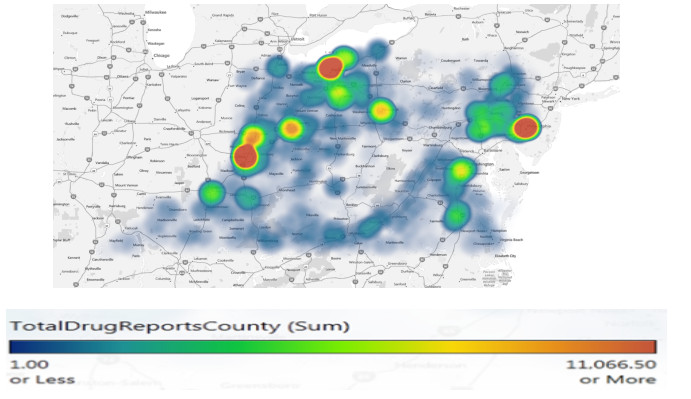
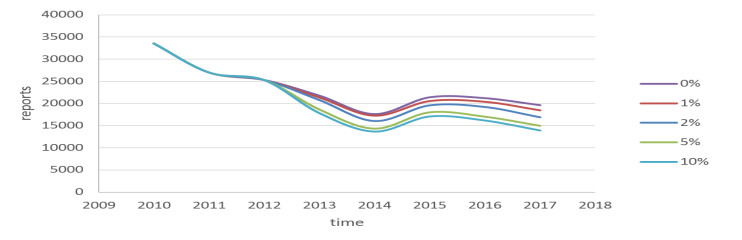
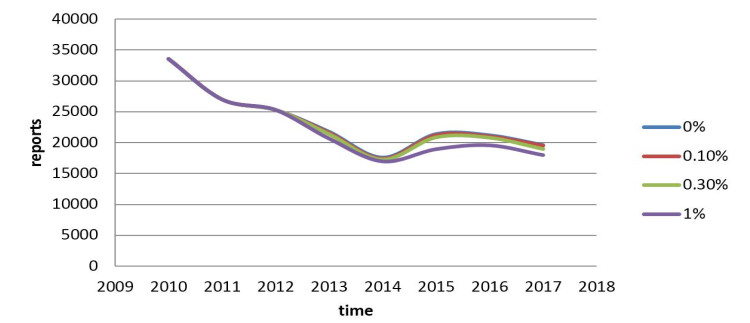
Figures(5) / Tables(8)

Wanchun Fan, Yan Jiang, Songyang Huang, Weiguo Liu. Research and prediction of opioid crisis based on BP neural network and Markov chain[J]. AIMS Mathematics, 2019, 4(5): 1357-1368. doi: 10.3934/math.2019.5.1357







 DownLoad:
DownLoad: