Citation: Missag Hagop Parseghian. What is the role of histone H1 heterogeneity? A functional model emerges from a 50 year mystery[J]. AIMS Biophysics, 2015, 2(4): 724-772. doi: 10.3934/biophy.2015.4.724

| [1] | Kinkade JM, Cole RD (1966) The resolution of four lysine-rich histones derived from calf thymus. J Biol Chem 241: 5790-5797. |
| [2] |
Parseghian MH, Hamkalo BA (2001) A compendium of the histone H1 family of somatic subtypes: An elusive cast of characters and their characteristics. Biochem Cell Biol 79: 289-304. doi: 10.1139/o01-099

|
| [3] | Ausio J (2000) Are linker histones (histone H1) dispensable for survival? BioEssays 22: 873-877. |
| [4] |
Takami Y, Nishi R, Nakayama T (2000) Histone H1 variants play individual roles in transcription regulation in the DT40 chicken B cell line. Biochem Biophys Res Commun 268: 501-508. doi: 10.1006/bbrc.2000.2172
|
| [5] |
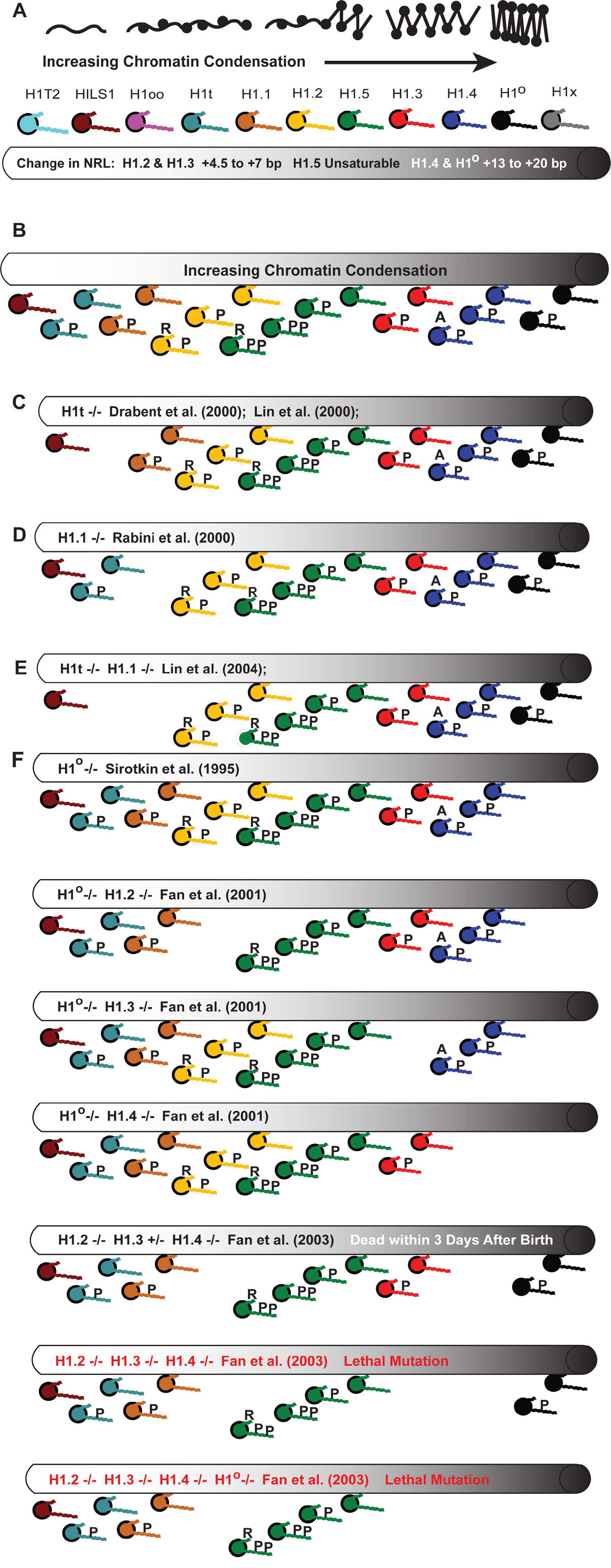
Fan Y, Nikitina T, Morin-Kensicki EM, et al. (2003) H1 linker histones are essential for mouse development and affect nucleosome spacing in vivo. Mol Cell Biol 23: 4559-4572. doi: 10.1128/MCB.23.13.4559-4572.2003
|
| [6] |
Alami R, Fan Y, Pack S, et al. (2003) Mammalian linker-histone subtypes differentially affect gene expression in vivo. Proc Natl Acad Sci U S A 100: 5920-5925. doi: 10.1073/pnas.0736105100
|
| [7] |
Sancho M, Diani E, Beato M, et al. (2008) Depletion of human histone H1 variants uncovers specific roles in gene expression and cell growth. PLoS Genet 4: e1000227. doi: 10.1371/journal.pgen.1000227
|
| [8] | Luger K, Mader AW, Richmond RK, et al. (1997) Crystal structure of the nucleosome core particle at 2.8 Angstrom resolution. Nature 389: 251-260. |
| [9] |
Bednar J, Horowitz RA, Grigoryev SA, et al. (1998) Nucleosomes, linker DNA, and linker histone form a unique structural motif that directs the higher-order folding and compaction of chromatin. Proc Natl Acad Sci U S A 95: 14173-14178. doi: 10.1073/pnas.95.24.14173
|
| [10] | Bazett-Jones DP, Eskiw CH (2004) Chromatin structure and function: Lessons from imaging techniques. In Chromatin Structure and Dynamics: State-of-the-Art (Zlatanova, J.S. & Leuba, S.H., eds), pp. 343-368. Elsevier, Amsterdam. |
| [11] | Langowski J, Schiessel H (2004) Theory and computational modeling of the 30 nm chromatin fiber. In Chromatin Structure and Dynamics: State-of-the-Art (Zlatanova, J.S. & Leuba, S.H., eds), pp. 397-420. Elsevier, Amsterdam. |
| [12] | Thoma F, Koller T, Klug A (1979) Involvement of histone H1 in the organization of the nucleosome and the salt-dependent superstructures of chromatin. J Cell Biol 83: 402-427. |
| [13] |
Strahl BD, Allis CD (2000) The language of covalent histone modifications. Nature 403: 41-45. doi: 10.1038/47412
|
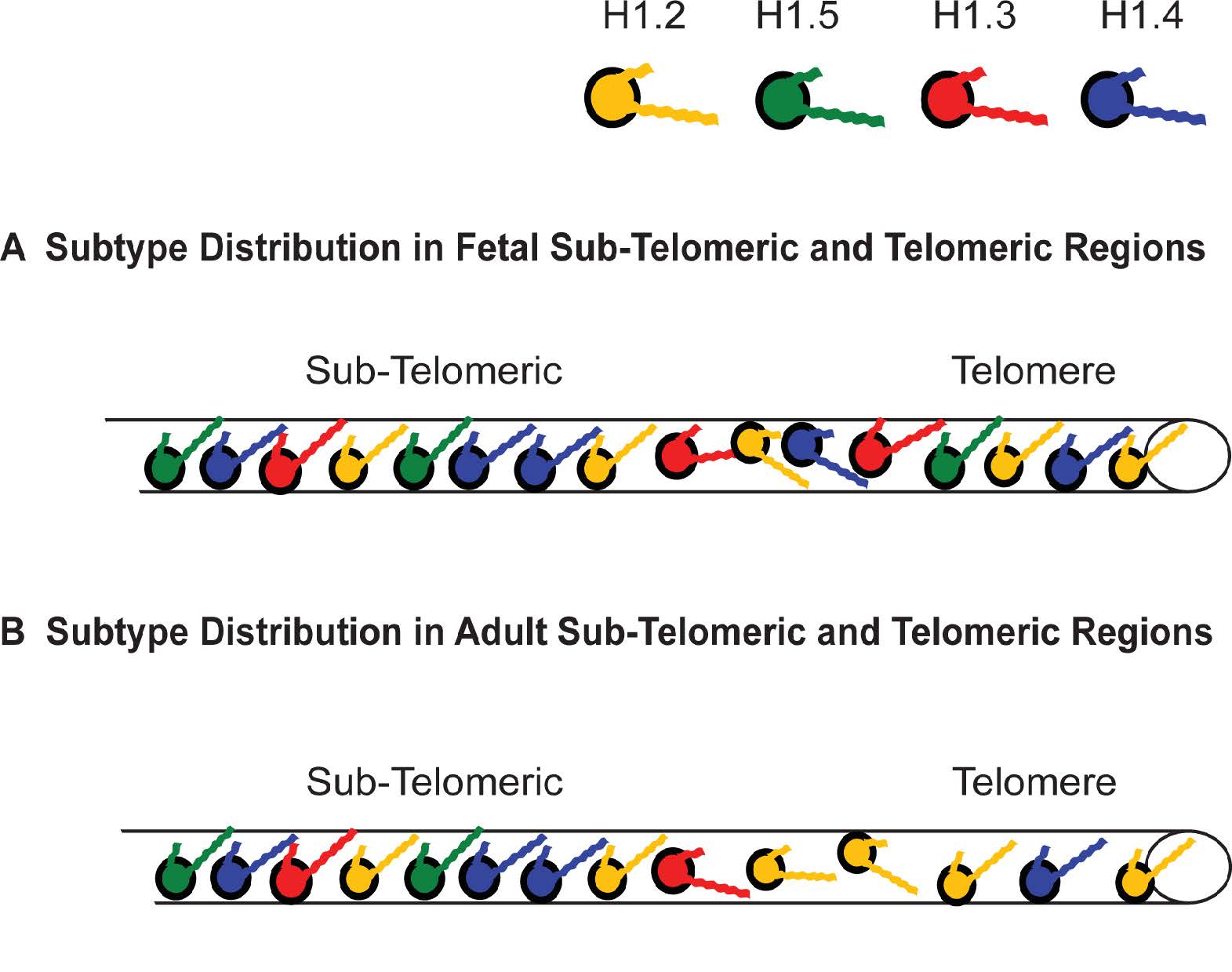
| [14] | Parseghian MH, Newcomb RL, Winokur ST, et al. (2000) The distribution of somatic H1 subtypes is non-random on active vs. inactive chromatin: Distribution in human fetal fibroblasts. Chromosome Res 8: 405-424. |
| [15] | Parseghian MH, Newcomb RL, Hamkalo BA (2001) The distribution of somatic H1 subtypes is non-random on active vs. inactive chromatin II: Distribution in human adult fibroblasts. J Cell Biochem 83: 643-659. |
| [16] | Eick S, Nicolai M, Mumberg D, et al. (1989) Human H1 histones: Conserved and varied sequence elements in two H1 subtype genes. Eur J Cell Bio 49: 110-115. |
| [17] |
Albig W, Kardalinou E, Drabent B, et al. (1991) Isolation and characterization of two human H1 histone genes within clusters of core histone genes. Genomics 10: 940-948. doi: 10.1016/0888-7543(91)90183-F
|
| [18] | Albig W, Meergans T, Doenecke D (1997) Characterization of the H1.5 gene completes the set of human H1 subtype genes. Gene 184: 141-148. |
| [19] | Bustin M, Cole RD (1968) Species and organ specificity in very lysine-rich histones. J Biol Chem 243: 4500-4505. |
| [20] | Bustin M, Cole RD (1969) A study of the multiplicity of lysine-rich histones. J Biol Chem 244: 5286-5290. |
| [21] |
Bradbury EM, Crane-Robinson C, Johns EW (1972) Specific conformations and interactions in chicken erythrocyte histone F2C. Nat New Biol 238: 262-264. doi: 10.1038/newbio238262a0
|
| [22] |
Smith BJ, Walker JM, Johns EW (1980) Structural homology between a mammalian H1(0) subfraction and avian erythrocyte-specific histone H5. FEBS Lett 112: 42-44. doi: 10.1016/0014-5793(80)80122-0
|
| [23] | Seyedin SM, Kistler WS (1979) H1 histone subfractions of mammalian testes. 1. Organ specificity in the rat. Biochemistry 18: 1371-1375. |
| [24] | Seyedin SM, Kistler WS (1979) H1 histone subfractions of mammalian testes. 2. Organ specificity in mice and rabbits. Biochemistry 18: 1376-1379. |
| [25] | Seyedin SM, Kistler WS (1980) Isolation and characterization of rat testis H1t: an H1 histone variant associated with spermatogenesis. J Biol Chem 255: 5949-5954. |
| [26] |
Yamamoto T, Horikoshi M (1996) Cloning of the cDNA encoding a novel subtype of histone H1. Gene 173: 281-285. doi: 10.1016/0378-1119(96)00020-0
|
| [27] | Tanaka M, Hennebold JD, Macfarlane J, et al. (2001) A mammalian oocyte-specific linker histone gene H1oo: Homology with the genes for the oocyte-specific cleavage stage histone (cs-H1) of sea urchin and the B4/H1M histone of the frog. Development 128: 655-664. |
| [28] |
Yan W, Ma L, Burns KH, et al. (2003) HILS1 is a spermatid-specific linker histone H1-like protein implicated in chromatin remodeling during mammalian spermiogenesis. Proc Natl Acad Sci U S A 100: 10546-10551. doi: 10.1073/pnas.1837812100
|
| [29] |
Martianov I, Brancorsini S, Catena R, et al. (2005) Polar nuclear localization of H1T2, a histone H1 variant, required for spermatid elongation and DNA condensation during spermiogenesis. Proc Natl Acad Sci U S A 102: 2808-2813. doi: 10.1073/pnas.0406060102
|
| [30] | Parseghian MH, Henschen AH, Krieglstein KG, et al. (1994) A proposal for a coherent mammalian histone H1 nomenclature correlated with amino acid sequences. Protein Sci 3: 575-587. |
| [31] |
Schlissel MS, Brown DD (1984) The transcriptional regulation of Xenopus 5S RNA genes in chromatin: The roles of active stable transcription complexes and histone H1. Cell 37: 903-913. doi: 10.1016/0092-8674(84)90425-2
|
| [32] |
Shimamura A, Sapp M, Rodriguez-Campos A, et al. (1989) Histone H1 represses transcription from minichromosomes assembled in vitro. Mol Cell Biol 9: 5573-5584. doi: 10.1128/MCB.9.12.5573
|
| [33] |
Lu ZH, Sittman DB, Romanowski P, et al. (1998) Histone H1 reduces the frequency of initiation in Xenopus egg extract by limiting the assembly of prereplication complexes on sperm chromatin. Molec Bio Cell 9: 1163-1176. doi: 10.1091/mbc.9.5.1163
|
| [34] |
Laybourn PJ, Kadonaga JT (1991) Role of nucleosomal cores and histone H1 in regulation of transcription by RNA polymerase II. Science 254: 238-245. doi: 10.1126/science.1718039
|
| [35] |
Lu ZH, Xu H, Leno GH (1999) DNA replication in quiescent cell nuclei: Regulation by the nuclear envelope and chromatin structure. Molec Bio Cell 10: 4091-4106. doi: 10.1091/mbc.10.12.4091
|
| [36] |
Carruthers LM, Bednar J, Woodcock CL, et al. (1998) Linker histones stabilize the intrinsic salt-dependent folding of nucleosomal arrays: Mechanistic ramifications for higher-order chromatin folding. Biochemistry 37: 14776-14787. doi: 10.1021/bi981684e
|
| [37] |
Parseghian MH, Luhrs KA (2006) Beyond the Walls of the Nucleus: The Role of Histones in Cellular Signaling and Innate Immunity. Biochem Cell Biol 84: 589-604. doi: 10.1139/o06-082
|
| [38] |
Sirotkin AM, Edelmann W, Cheng G, et al. (1995) Mice develop normally without the H1° linker histone. Proc Natl Acad Sci U S A 92: 6434-6438. doi: 10.1073/pnas.92.14.6434
|
| [39] |
Lin Q, Sirotkin AM, Skoultchi AI (2000) Normal spermatogenesis in mice lacking the testis-specific linker histone H1t. Mol Cell Biol 20: 2122-2128. doi: 10.1128/MCB.20.6.2122-2128.2000
|
| [40] |
Fan Y, Sirotkin AM, Russell RG, et al. (2001) Individual somatic H1 subtypes are dispensable for mouse development even in mice lacking the H1° replacement subtype. Mol Cell Biol 21: 7933-7943. doi: 10.1128/MCB.21.23.7933-7943.2001
|
| [41] |
Allan J, Hartman PG, Crane-Robinson C, et al. (1980) The structure of histone H1 and its location in chromatin. Nature 288: 675-679. doi: 10.1038/288675a0
|
| [42] |
Hartman PG, Chapman GE, MossT, et al. (1977) Studies on the role and mode of operation of the very-lysine-rich histone H1 in eukaryote chromatin. Eur J Biochem 77: 45-51. doi: 10.1111/j.1432-1033.1977.tb11639.x
|
| [43] | Izzo A, Kamieniarz K, Schneider R (2008) The histone H1 family: specific members, specific functions? Biol Chem 389: 333-343. |
| [44] |
Ramakrishnan V, Finch JT, Graziano V, et al. (1993) Crystal structure of globular domain of histone H5 and its implications for nucleosome binding. Nature 362: 219-223. doi: 10.1038/362219a0
|
| [45] |
Cerf C, Lippens G, Muyldermans S, et al. (1993) Homo- and heteronuclear two-dimensional NMR studies of the globular domain of histone H1: sequential assignment and secondary structure. Biochemistry 32: 11345-11351. doi: 10.1021/bi00093a011
|
| [46] |
Zhou BR, Feng H, Kato H, et al. (2013) Structural insights into the histone H1-nucleosome complex. Proc Natl Acad Sci U S A 110: 19390-19395. doi: 10.1073/pnas.1314905110
|
| [47] |
Zhou BR, Jiang J, Feng H, et al. (2015) Structural Mechanisms of Nucleosome Recognition by Linker Histones. Mol Cell 59: 628-638. doi: 10.1016/j.molcel.2015.06.025
|
| [48] |
Syed SH, Goutte-Gattat D, Becker N, et al. (2010) Single-base resolution mapping of H1-nucleosome interactions and 3D organization of the nucleosome. Proc Natl Acad Sci U S A 107: 9620-9625. doi: 10.1073/pnas.1000309107
|
| [49] | Fan L, Roberts VA (2006) Complex of linker histone H5 with the nucleosome and its implications for chromatin packing. Proc Natl Acad Sci U S A 103: 8384-8389. |
| [50] |
An W, Leuba SH, van Holde KE, et al. (1998) Linker histone protects linker DNA on only one side of the core particle and in a sequence-dependent manner. Proc Natl Acad Sci U S A 95: 3396-3401. doi: 10.1073/pnas.95.7.3396
|
| [51] |
Thomas JO (1999) Histone H1: Location and role. Curr Opin Cell Biol 11: 312-317. doi: 10.1016/S0955-0674(99)80042-8
|
| [52] |
Brown DT, Izard T, Misteli T (2006) Mapping the interaction surface of linker histone H1(0) with the nucleosome of native chromatin in vivo. Nat Struct Mol Biol 13: 250-255. doi: 10.1038/nsmb1050
|
| [53] |
Song F, Chen P, Sun D, et al. (2014) Cryo-EM study of the chromatin fiber reveals a double helix twisted by tetranucleosomal units. Science 344: 376-380. doi: 10.1126/science.1251413
|
| [54] |
George EM, Izard T, Anderson SD, et al. (2010) Nucleosome interaction surface of linker histone H1c is distinct from that of H1(0). J Biol Chem 285: 20891-20896. doi: 10.1074/jbc.M110.108639
|
| [55] |
Vila R, Ponte I, Collado M, et al. (2001) DNA-induced a-helical structure in the NH2 -terminal domain of histone H1. J Biol Chem 276: 46429-46435. doi: 10.1074/jbc.M106952200
|
| [56] | Vila R, Ponte I, Jiménez MA, et al. (2002) An inducible helix Gly-Gly helix motif in the N-terminal domain of histone H1e: A CD and NMR study. Protein Sci 11: 214-220. |
| [57] |
Becker M, Becker A, Miyara F, et al. (2005) Differential in vivo binding dynamics of somatic and oocyte-specific linker histones in oocytes and during ES cell nuclear transfer. Mol Biol Cell 16: 3887-3895. doi: 10.1091/mbc.E05-04-0350
|
| [58] |
Vyas P, Brown DT (2012) N- and C-terminal domains determine differential nucleosomal binding geometry and affinity of linker histone isotypes H1(0) and H1c. J Biol Chem 287: 11778-11787. doi: 10.1074/jbc.M111.312819
|
| [59] | Kalashnikova AA, Winkler DD, McBryant SJ, et al. (2013) Linker histone H1.0 interacts with an extensive network of proteins found in the nucleolus. Nucleic Acids Res 41: 4026-4035. |
| [60] |
Caterino TL, Hayes JJ (2011) Structure of the H1 C-terminal domain and function in chromatin condensation. Biochem Cell Biol 89: 35-44. doi: 10.1139/O10-024
|
| [61] | Hill CS, Martin SR, Thomas JO (1989) A stable a-helical element in the carboxy-terminal domain of free and chromatin-bound histone H1 from sea urchin sperm. EMBO J 8: 2591-2599. |
| [62] | Vila R, Ponte I, Jiménez MA, et al. (2000) A helix-turn motif in the C-terminal domain of histone H1. Protein Sci 9: 627-636. |
| [63] |
Vila R, Ponte I, Collado M, et al. (2001) Induction of secondary structure in a COOH-terminal peptide of histone H1 by interaction with the DNA. J Biol Chem 276: 30898-30903. doi: 10.1074/jbc.M104189200
|
| [64] |
Roque A, Iloro I, Ponte I, et al. (2005) DNA-induced secondary structure of the carboxyl-terminal domain of histone H1. J Biol Chem 280: 32141-32147. doi: 10.1074/jbc.M505636200
|
| [65] |
Hendzel MJ, Lever MA, Crawford E, et al. (2004) The C-terminal domain is the primary determinant of histone H1 binding to chromatin in vivo. J Biol Chem 279: 20028-20034. doi: 10.1074/jbc.M400070200
|
| [66] | Clausell J, Happel N, Hale TK, et al. (2009) Histone H1 subtypes differentially modulate chromatin condensation without preventing ATP-dependent remodeling by SWI/SNF or NURF. PLoS ONE 4: e0007243. |
| [67] |
Lu X, Hansen JC (2004) Identification of specific functional subdomains within the linker histone H1° C-terminal domain. J Biol Chem 279: 8701-8707. doi: 10.1074/jbc.M311348200
|
| [68] |
De S, Brown DT, Lu ZH, et al. (2002) Histone H1 variants differentially inhibit DNA replication through an affinity for chromatin mediated by their carboxyl-terminal domains. Gene 292: 173-181. doi: 10.1016/S0378-1119(02)00675-3
|
| [69] |
Hansen JC, Lu X, Ross ED, et al. (2006) Intrinsic protein disorder, amino acid composition, and histone terminal domains. J Biol Chem 281: 1853-1856. doi: 10.1074/jbc.R500022200
|
| [70] |
Finn RM, Ellard K, Eirin-Lopez JM, et al. (2012) Vertebrate nucleoplasmin and NASP: egg histone storage proteins with multiple chaperone activities. FASEB J 26: 4788-4804. doi: 10.1096/fj.12-216663
|
| [71] |
Karetsou Z, Sandaltzopoulos R, Frangou-Lazaridis M, et al. (1998) Prothymosin a modulates the interaction of histone H1 with chromatin. Nucl Acids Res 26: 3111-3118. doi: 10.1093/nar/26.13.3111
|
| [72] |
Lu X, Hamkalo BA, Parseghian MH, et al. (2009) Chromatin condensing functions of the linker histone C-terminal domain are mediated by specific amino acid composition and intrinsic protein disorder. Biochemistry 48: 164-172. doi: 10.1021/bi801636y
|
| [73] |
Widlak P, Kalinowska M, Parseghian MH, et al. (2005) The histone H1 C-terminal domain binds to the apoptotic nuclease, DNA Fragmentation Factor (DFF40/CAD) and stimulates DNA cleavage. Biochemistry 44: 7871-7878. doi: 10.1021/bi050100n
|
| [74] |
Roque A, Orrego M, Ponte I, et al. (2004) The preferential binding of histone H1 to DNA scaffold-associated regions is determined by its C-terminal domain. Nucleic Acids Res 32: 6111-6119. doi: 10.1093/nar/gkh945
|
| [75] |
Stasevich TJ, Mueller F, Brown DT, et al. (2010) Dissecting the binding mechanism of the linker histone in live cells: an integrated FRAP analysis. EMBO J 29: 1225-1234. doi: 10.1038/emboj.2010.24
|
| [76] | Wisniewski JR, Zougman A, Kruger S, et al. (2007) Mass spectrometric mapping of linker histone H1 variants reveals multiple acetylations, methylations, and phosphorylation as well as differences between cell culture and tissue. Mol Cell Proteomics 6: 72-87. |
| [77] | Ajiro K, Shibata K, Nishikawa Y (1990) Subtype-specific cyclic AMP-dependent histone H1 phosphorylation at the differentiation of mouse neuroblastoma cells. J Biol Chem 265: 6494-6500. |
| [78] | Hill CS, Rimmer JM, Green BN, et al. (1991) Histone-DNA interactions and their modulation by phosphorylation of Ser-Pro-X-Lys/Arg motifs. EMBO J 10: 1939-1948. |
| [79] |
Sarg B, Helliger W, Talasz H, et al. (2006) Histone H1 phosphorylation occurs site-specifically during interphase and mitosis: identification of a novel phosphorylation site on histone H1. J Biol Chem 281: 6573-6580. doi: 10.1074/jbc.M508957200
|
| [80] | Suzuki M (1989) SPKK, a new nucleic acid-binding unit of protein found in histone. EMBO J 8: 797-804. |
| [81] |
Lopez R, Sarg B, Lindner H, et al. (2015) Linker histone partial phosphorylation: effects on secondary structure and chromatin condensation. Nucleic Acids Res 43: 4463-4476. doi: 10.1093/nar/gkv304
|
| [82] |
Talasz H, Helliger W, Puschendorf B, et al. (1996) In vivo phosphorylation of histone H1 variants during the cell cycle. Biochemistry 35: 1761-1767. doi: 10.1021/bi951914e
|
| [83] | Riquelme PT, Burzio LO, Koide SS (1979) ADP ribosylation of rat liver lysine-rich histone in vitro. J Biol Chem 254: 3018-3028. |
| [84] |
D'Erme M, Zardo G, Reale A, et al. (1996) Co-operative interactions of oligonucleosomal DNA with the H1e histone variant and its poly(ADP-ribosyl)ated isoform. Biochem J 316: 475-480. doi: 10.1042/bj3160475
|
| [85] | de Murcia G, Huletsky A, Lamarre D, et al. (1986) Modulation of chromatin superstructure induced by poly(ADP-ribose) synthesis and degradation. J Biol Chem 261: 7011-7017. |
| [86] |
Vaquero A, Scher M, Lee D, et al. (2004) Human SirT1 interacts with histone H1 and promotes formation of facultative heterochromatin. Mol Cell 16: 93-105. doi: 10.1016/j.molcel.2004.08.031
|
| [87] |
Kuzmichev A, Jenuwein T, Tempst P, et al. (2004) Different Ezh2-containing complexes target methylation of histone H1 or nucleosomal histone H3. Molec Cell 14: 183-193. doi: 10.1016/S1097-2765(04)00185-6
|
| [88] |
Weiss T, Hergeth S, Zeissler U, et al. (2010) Histone H1 variant-specific lysine methylation by G9a/KMT1C and Glp1/KMT1D. Epigenetics Chromatin 3: 7. doi: 10.1186/1756-8935-3-7
|
| [89] |
Th'ng JPH, Sung R, Ye M, et al. (2005) H1 family histones in the nucleus: Control of binding and localization by the C-terminal domain. J Biol Chem 280: 27809-27814. doi: 10.1074/jbc.M501627200
|
| [90] | Izzo A, Kamieniarz-Gdula K, Ramirez F, et al. (2013) The genomic landscape of the somatic linker histone subtypes H1.1 to H1.5 in human cells. Cell Rep 3: 2142-2154. |
| [91] |
Cao K, Lailler N, Zhang Y, et al. (2013) High-resolution mapping of h1 linker histone variants in embryonic stem cells. PLoS Genet. 9: e1003417. doi: 10.1371/journal.pgen.1003417
|
| [92] |
Appels R, Bolund L, Ringertz NR (1974) Biochemical analysis of reactivated chick erythrocyte nuclei isolated from chick/HeLa heterokaryons. J Mol Biol 87: 339-355. doi: 10.1016/0022-2836(74)90154-5
|
| [93] |
Gao S, Chung YG, Parseghian MH, et al. (2004) Rapid H1 linker histone transitions following fertilization or somatic cell nuclear transfer: evidence for a uniform developmental program in mice. Dev Biol 266: 62-75. doi: 10.1016/j.ydbio.2003.10.003
|
| [94] | Dimitrov S, Wolffe AP (1996) Remodeling somatic nuclei in Xenopus laevis egg extracts: molecular mechanisms for the selective release of histones H1 and H1° from chromatin and the acquisition of transcriptional competence. EMBO J 15: 5897-5906. |
| [95] |
Teranishi T, Tanaka M, Kimoto S, et al. (2004) Rapid replacement of somatic linker histones with the oocyte-specific linker histone H1foo in nuclear transfer. Dev Biol 266: 76-86. doi: 10.1016/j.ydbio.2003.10.004
|
| [96] |
Misteli T, Gunjan A, Hock R, et al. (2000) Dynamic binding of histone H1 to chromatin in living cells. Nature 408: 877-881. doi: 10.1038/35048610
|
| [97] |
Phair RD, Scaffidi P, Elbi C, et al. (2004) Global nature of dynamic protein-chromatin interactions in vivo: Three dimensional genome scanning and dynamic interaction networks of chromatin proteins. Mol Cell Biol 24: 6393-6402. doi: 10.1128/MCB.24.14.6393-6402.2004
|
| [98] |
Bustin M, Catez F, Lim J-H (2005) The dynamics of histone H1 function in chromatin. Molec Cell 17: 617-620. doi: 10.1016/j.molcel.2005.02.019
|
| [99] |
Raghuram N, Carrero G, Stasevich TJ, et al. (2010) Core histone hyperacetylation impacts cooperative behavior and high-affinity binding of histone H1 to chromatin. Biochemistry 49: 4420-4431. doi: 10.1021/bi100296z
|
| [100] |
Kimura H, Cook PR (2001) Kinetics of core histones in living human cells: Little exchange of H3 and H4 and some rapid exchange of H2B. J Cell Biology 153: 1341-1353. doi: 10.1083/jcb.153.7.1341
|
| [101] |
Contreras A, Hale TK, Stenoien DL, et al. (2003) The dynamic mobility of histone H1 is regulated by Cyclin/CDK Phosphorylation. Mol Cell Biol 23: 8626-8636. doi: 10.1128/MCB.23.23.8626-8636.2003
|
| [102] |
Yellajoshyula D, Brown DT (2006) Global modulation of chromatin dynamics mediated by dephosphorylation of linker histone H1 is necessary for erythroid differentiation. Proc Natl Acad Sci U S A 103: 18568-18573. doi: 10.1073/pnas.0606478103
|
| [103] | Takata H, Matsunaga S, Morimoto A, et al. (2007) H1.X with different properties from other linker histones is required for mitotic progression. FEBS Lett 581: 3783-3788. |
| [104] | Lever MA, Th'ng JPH, Sun X, et al. (2000) Rapid exchange of histone H1.1 on chromatin in living human cells. Nature 408: 873-876. |
| [105] |
Christophorou MA, Castelo-Branco G, Halley-Stott RP, et al. (2014) Citrullination regulates pluripotency and histone H1 binding to chromatin. Nature 507: 104-108. doi: 10.1038/nature12942
|
| [106] | Liao LW, Cole RD (1981) Condensation of dinucleosomes by individual subfractions of H1 histone. J Biol Chem 256: 10124-10128. |
| [107] |
Khadake JR, Rao MR (1995) DNA- and chromatin-condensing properties of rat testes H1a and H1t compared to those of rat liver H1bdec; H1t is a poor condenser of chromatin. Biochemistry 34: 15792-15801. doi: 10.1021/bi00048a025
|
| [108] |
Talasz H, Sapojnikova N, Helliger W, et al. (1998) In vitro binding of H1 histone subtypes to nucleosomal organized mouse mammary tumor virus long terminal repeat promotor. J Biol Chem 273: 32236-32243. doi: 10.1074/jbc.273.48.32236
|
| [109] |
Hannon R, Bateman E, Allan J, et al. (1984) Control of RNA polymerase binding to chromatin by variations in linker histone composition. J Mol Biol 180: 131-149. doi: 10.1016/0022-2836(84)90434-0
|
| [110] |
Orrego M, Ponte I, Roque A, et al. (2007) Differential affinity of mammalian histone H1 somatic subtypes for DNA and chromatin. BMC Biol 5: 22. doi: 10.1186/1741-7007-5-22
|
| [111] |
Brown DT, Alexander BT, Sittman DB (1996) Differential effect of H1 variant overexpression on cell cycle progression and gene expression. Nucl Acids Res 24: 486-493. doi: 10.1093/nar/24.3.486
|
| [112] |
Bhan S, May W, Warren SL, et al. (2008) Global gene expression analysis reveals specific and redundant roles for H1 variants, H1c and H1(0), in gene expression regulation. Gene 414: 10-18. doi: 10.1016/j.gene.2008.01.025
|
| [113] |
Funayama R, Saito M, Tanobe H, et al. (2006) Loss of linker histone H1 in cellular senescence. J. Cell Biol 175: 869-880. doi: 10.1083/jcb.200604005
|
| [114] |
Kasinsky HE, Lewis JD, Dacks JB, et al. (2001) Origin of H1 linker histones. FASEB J 15: 34-42. doi: 10.1096/fj.00-0237rev
|
| [115] |
Wu M, Allis CD, Richman R, et al. (1986) An intervening sequence in an unusual histone H1 gene of Tetrahymena thermophila. Proc Natl Acad Sci U S A 83: 8674-8678. doi: 10.1073/pnas.83.22.8674
|
| [116] | Schulze E, Schulze B (1995) The vertebrate linker histones H1°, H5 and H1M are descendants of invertebrate ""orphon"" histone H1 genes. J Mol Evol 41: 833-840. |
| [117] |
Ponte I, Vidal-Taboada JM, Suau P (1998) Evolution of the vertebrate H1 histone class: Evidence for the functional differentiation of the subtypes. Mol Biol Evol 15: 702-708. doi: 10.1093/oxfordjournals.molbev.a025973
|
| [118] |
Downs JA, Kosmidou E, Morgan A, et al. (2003) Suppression of homologous recombination by the Saccharomyces cerevisiae linker histone. Molec Cell 11: 1685-1692. doi: 10.1016/S1097-2765(03)00197-7
|
| [119] | Hellauer K, Sirard E, Turcotte B (2001) Decreased expression of specific genes in yeast cells lacking histone H1. J Biol Chem 276: 13587-13592. |
| [120] |
Shen X, Gorovsky MA (1996) Linker histone H1 regulates specific gene expression but not global transcription in vivo. Cell 86: 475-483. doi: 10.1016/S0092-8674(00)80120-8
|
| [121] | Nalabothula N, McVicker G, Maiorano J, et al. (2014) The chromatin architectural proteins HMGD1 and H1 bind reciprocally and have opposite effects on chromatin structure and gene regulation. BMC. Genomics. 15, 92. |
| [122] |
Meergans T, Albig W, Doenecke D (1997) Varied expression patterns of human H1 histone genes in different cell lines. DNA Cell Biol 16: 1041-1049. doi: 10.1089/dna.1997.16.1041
|
| [123] |
Pina B, Martinez P, Suau P (1987) Changes in H1 complement in differentiating rat-brain cortical neurons. Eur J Biochem 164: 71-76. doi: 10.1111/j.1432-1033.1987.tb10994.x
|
| [124] | Kamieniarz K, Izzo A, Dundr M, et al. (2012) A dual role of linker histone H1.4 Lys 34 acetylation in transcriptional activation. Genes Dev 26: 797-802. |
| [125] | Huang H-C, Cole RD (1984) The distribution of H1 histone is nonuniform in chromatin and correlates with different degrees of condensation. J Biol Chem 259: 14237-14242. |
| [126] |
Gunjan A, Alexander BT, Sittman DB, et al. (1999) Effects of H1 histone variant overexpression on chromatin structure. J Biol Chem 274: 37950-37956. doi: 10.1074/jbc.274.53.37950
|
| [127] |
Krishnakumar R, Gamble MJ, Frizzell KM, et al. (2008) Reciprocal binding of PARP-1 and histone H1 at promoters specifies transcriptional outcomes. Science. 319: 819-821. doi: 10.1126/science.1149250
|
| [128] |
Parseghian MH, Harris DA, Rishwain DR, et al. (1994) Characterization of a set of antibodies specific for three human histone H1 subtypes. Chromosoma 103: 198-208. doi: 10.1007/BF00368013
|
| [129] |
Boulikas T, Bastin B, Boulikas P, et al. (1990) Increase in histone poly(ADP-ribosylation) in mitogen-activated lymphoid cells. Exp Cell Res 187: 77-84. doi: 10.1016/0014-4827(90)90119-U
|
| [130] | Parseghian MH, Henschen AH, Krieglstein KG, et al. (1994) A proposal for a coherent mammalian histone H1 nomenclature correlated with amino acid sequences. Protein Sci 3: 575-587. |
| [131] | Higurashi M, Adachi H, Ohba Y (1987) Synthesis and degradation of H1 histone subtypes in mouse lymphoma L5178Y cells. J Biol Chem 262: 13075-13080. |
| [132] |
Cheng G, Nandi A, Clerk S, et al. (1989) Different 3'-end processing produces two independently regulated mRNAs from a single H1 histone gene. Proc Natl Acad Sci U S A 86: 7002-7006. doi: 10.1073/pnas.86.18.7002
|
| [133] |
Routh A, Sandin S, Rhodes D (2008) Nucleosome repeat length and linker histone stoichiometry determine chromatin fiber structure. Proc Natl Acad Sci U S A 105: 8872-8877. doi: 10.1073/pnas.0802336105
|
| [134] |
Beshnova DA, Cherstvy AG, Vainshtein Y, et al. (2014) Regulation of the nucleosome repeat length in vivo by the DNA sequence, protein concentrations and long-range interactions. PLoS Comput Biol 10: e1003698. doi: 10.1371/journal.pcbi.1003698
|
| [135] |
Chadee DN, Taylor WR, Hurta RAR, et al. (1995) Increased phosphorylation of histone H1 in mouse fibroblasts transformed with oncogenes or constitutively active mitogen-activated protein kinase kinase. J Biol Chem 270: 20098-20105. doi: 10.1074/jbc.270.34.20098
|
| [136] |
Chadee DN, Allis CD, Wright JA, et al. (1997) Histone H1b phosphorylation is dependent upon ongoing transcription and replication in normal and ras-transformed mouse fibroblasts. J Biol Chem 272: 8113-8116. doi: 10.1074/jbc.272.13.8113
|
| [137] | Li JY, Patterson M, Mikkola HK, et al. (2012) Dynamic distribution of linker histone H1.5 in cellular differentiation. PLoS Genet. 8: e1002879. |
| [138] |
Lee H, Habas R, Abate-Shen C (2004) Msx1 cooperates with histone H1b for inhibition of transcription and myogenesis. Science 304: 1675-1678. doi: 10.1126/science.1098096
|
| [139] |
Wang X, Peng Y, Ma Y, et al. (2004) Histone H1-like protein participates in endothelial cell-specific activation of the von Willebrand factor promoter. Blood 104: 1725-1732. doi: 10.1182/blood-2004-01-0082
|
| [140] | Kaludov NK, Pabon-Pena L, Seavy M, et al. (1997) A mouse histone H1 variant, H1b, binds preferentially to a regulatory sequence within a mouse H3.2 replication-dependent histone gene. J Biol Chem 272: 15120-15127. |
| [141] |
Oberg C, Izzo A, Schneider R, et al. (2012) Linker histone subtypes differ in their effect on nucleosomal spacing in vivo. J Mol Biol 419: 183-197. doi: 10.1016/j.jmb.2012.03.007
|
| [142] |
Pehrson JR, Cole RD (1982) Histone H1 subfractions and H1° turnover at different rates in nondividing cells. Biochemistry 21: 456-460. doi: 10.1021/bi00532a006
|
| [143] | Zlatanova JS, Doenecke D (1994) Histone H1°: A major player in cell differentiation? FASEB J 8: 1260-1268. |
| [144] | Gabrilovich DI, Cheng P, Fan Y, et al. (2002) H1(0) histone and differentiation of dendritic cells. A molecular target for tumor-derived factors. J Leukoc Biol 72: 285-296. |
| [145] | Lennox RW, Cohen LH (1983) The histone H1 complements of dividing and nondividing cells of the mouse. J Biol Chem 258: 262-268. |
| [146] | Rasheed BKA, Whisenant EC, Ghai RD, et al. (1989) Biochemical and immunocytochemical analysis of a histone H1 variant from the mouse testis. J Cell Sci 94: 61-71. |
| [147] |
Franke K, Drabent B, Doenecke D (1998) Expression of murine H1 histone genes during postnatal development. Biochim Biophys Acta 1398: 232-242. doi: 10.1016/S0167-4781(98)00062-1
|
| [148] | Lennox RW (1984) Differences in evolutionary stability among mammalian H1 subtypes: Implications for the roles of H1 subtypes in chromatin. J Biol Chem 259: 669-672. |
| [149] | Lennox RW, Cohen LH (1984) The alterations in H1 histone complement during mouse spermatogenesis and their significance for H1 subtype function. Dev Biol 103, 80-84. |
| [150] |
Rabini S, Franke K, Saftig P, et al. (2000) Spermatogenesis in mice is not affected by histone H1.1 deficiency. Exp Cell Res 255: 114-124. doi: 10.1006/excr.1999.4767
|
| [151] |
Oko RJ, Jando V, Wagner CL, et al. (1996) Chromatin reorganization in rat spermatids during the disappearance of testis-specific histone, H1t, and the appearance of transition proteins TP1 and TP2. Biol Reprod 54: 1141-1157. doi: 10.1095/biolreprod54.5.1141
|
| [152] |
de Lucia F, Faraone-Mennella MR, D'Erme M, et al. (1994) Histone-induced condensation of rat testis chromatin: Testis-specific H1t versus somatic H1 variants. Biochem Biophys Res Commun 198: 32-39. doi: 10.1006/bbrc.1994.1005
|
| [153] |
Catena R, Ronfani L, Sassone-Corsi P, et al. (2006) Changes in intranuclear chromatin architecture induce bipolar nuclear localization of histone variant H1T2 in male haploid spermatids. Dev Biol 296: 231-238. doi: 10.1016/j.ydbio.2006.04.458
|
| [154] |
Tanaka H, Iguchi N, Isotani A, et al. (2005) HANP1/H1T2, a novel histone H1-like protein involved in nuclear formation and sperm fertility. Mol Cell Biol 25: 7107-7119. doi: 10.1128/MCB.25.16.7107-7119.2005
|
| [155] |
Saeki H, Ohsumi K, Aihara H, et al. (2005) Linker histone variants control chromatin dynamics during early embryogenesis. Proc Natl Acad Sci U S A 102: 5697-5702. doi: 10.1073/pnas.0409824102
|
| [156] |
Tanaka M, Kihara M, Hennebold JD, et al. (2005) H1FOO is coupled to the initiation of oocytic growth. Biol Reprod 72: 135-142. doi: 10.1095/biolreprod.104.032474
|
| [157] |
Nazarov IB, Shlyakhtenko LS, Lyubchenko YL, et al. (2008) Sperm chromatin released by nucleases. Syst Biol Reprod Med 54: 37-46. doi: 10.1080/19396360701876849
|
| [158] |
Sanchez-Vazquez ML, Flores-Alonso JC, Merchant-Larios H, et al. (2008) Presence and release of bovine sperm histone H1 during chromatin decondensation by heparin-glutathione. Syst Biol Reprod Med 54: 221-230. doi: 10.1080/19396360802357087
|
| [159] |
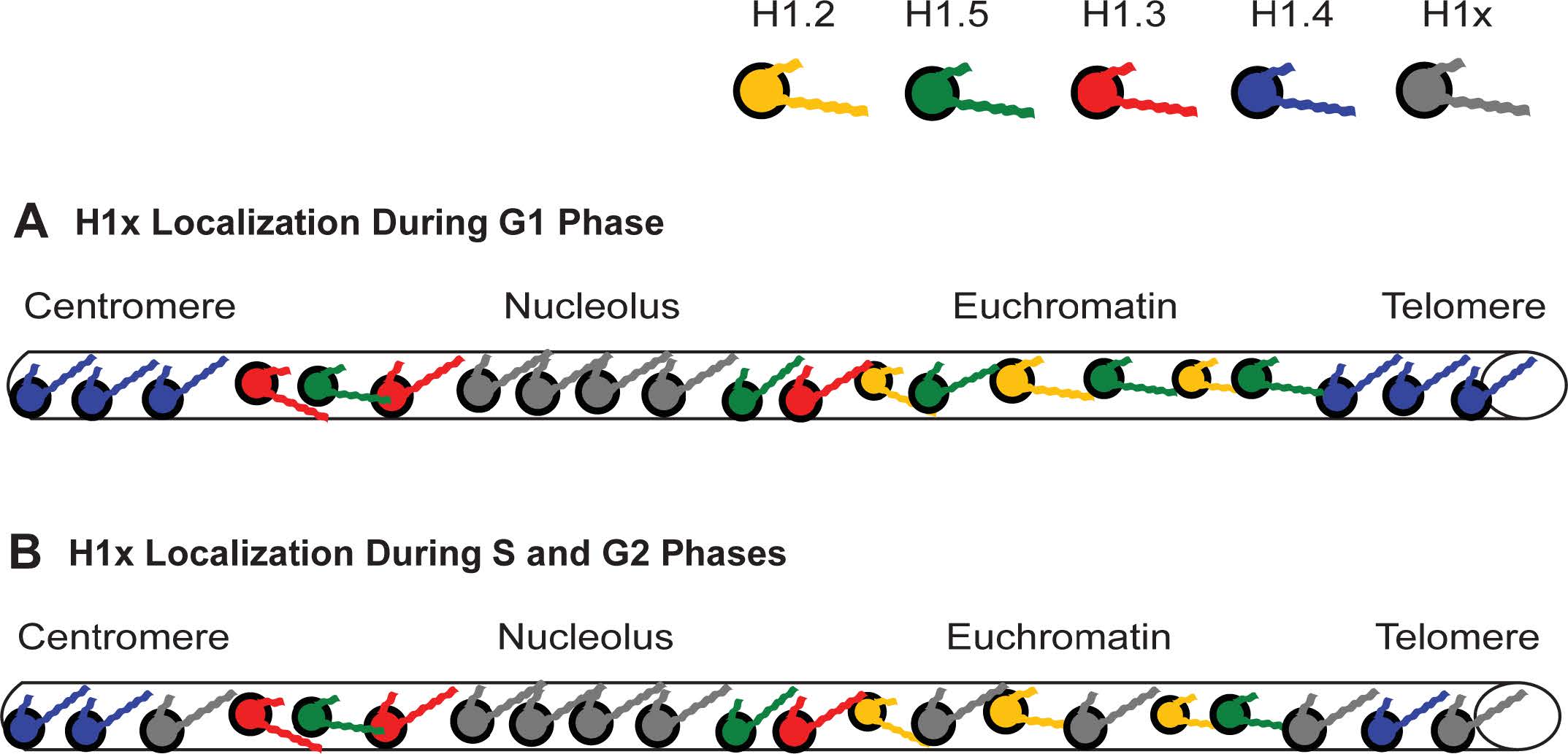
Stoldt S, Wenzel D, Schulze E, et al. (2007) G1 phase-dependent nucleolar accumulation of human histone H1x. Biol Cell 99: 541-552. doi: 10.1042/BC20060117
|
| [160] | Mayor R, Izquierdo-Bouldstridge A, Millan-Arino L, et al. (2015) Genome distribution of replication-independent histone H1 variants shows H1.0 associated with nucleolar domains and H1X associated with RNA polymerase II-enriched regions. J Biol Chem 290: 7474-7491. |
| [161] | Happel N, Schulze E, Doenecke D (2005) Characterization of human histone H1x. Biol Chem 386: 541-551. |
| [162] | Drabent B, Saftig P, Bode C, et al. (2000) Spermatogenesis proceeds normally in mice without linker histone H1t. Histochem. Cell Biol 113: 433-442. |
| [163] | Drabent B, Benavente R, Hoyer-Fender S (2003) Histone H1t is not replaced by H1.1 or H1.2 in pachytene spermatocytes or spermatids of H1t-deficient mice. Cytogenet Genome Res 103: 307-313. |
| [164] |
Lin Q, Inselman A, Han X, et al. (2004) Reductions in linker histone levels are tolerated in developing spermatocytes but cause changes in specific gene expression. J Biol Chem 279: 23525-23535. doi: 10.1074/jbc.M400925200
|
| [165] |
Fan Y, Nikitina T, Zhao J, et al. (2005) Histone H1 depletion in mammals alters global chromatin structure but causes specific changes in gene regulation. Cell 123: 1199-1212. doi: 10.1016/j.cell.2005.10.028
|
| [166] |
Zhang Y, Cooke M, Panjwani S, et al. (2012) Histone h1 depletion impairs embryonic stem cell differentiation. PLoS Genet 8: e1002691. doi: 10.1371/journal.pgen.1002691
|
| [167] |
Cherstvy AG, Teif VB (2014) Electrostatic effect of H1-histone protein binding on nucleosome repeat length. Phys Biol 11: 044001. doi: 10.1088/1478-3975/11/4/044001
|
| [168] |
Woodcock CL, Skoultchi AI, Fan Y (2006) Role of linker histone in chromatin structure and function: H1 stoichiometry and nucleosome repeat length. Chromosome Res 14: 17-25. doi: 10.1007/s10577-005-1024-3
|
| [169] |
Schiessel H (2003) The physics of chromatin. J Phys Condens Matter 15: R699-R774. doi: 10.1088/0953-8984/15/19/203
|
| [170] |
Bedoyan JK, Lejnine S, Makarov VL, et al. (1996) Condensation of rat telomere-specific nucleosomal arrays containing unusually short DNA repeats and histone H1. J Biol Chem 271: 18485-18493. doi: 10.1074/jbc.271.31.18485
|
| [171] |
Ascenzi R, Gantt JS (1999) Subnuclear distribution of the entire complement of linker histone variants in Arabidopsis thaliana. Chromosoma 108: 345-355. doi: 10.1007/s004120050386
|
| [172] |
O'Sullivan RJ, Karlseder J (2012) The great unravelling: chromatin as a modulator of the aging process. Trends Biochem Sci 37: 466-476. doi: 10.1016/j.tibs.2012.08.001
|
| [173] |
Oberdoerffer P, Michan S, McVay M, et al. (2008) SIRT1 redistribution on chromatin promotes genomic stability but alters gene expression during aging. Cell 135: 907-918. doi: 10.1016/j.cell.2008.10.025
|
| [174] |
O'Sullivan RJ, Kubicek S, Schreiber SL, et al. (2010) Reduced histone biosynthesis and chromatin changes arising from a damage signal at telomeres. Nat Struct Mol Biol 17: 1218-1225. doi: 10.1038/nsmb.1897
|
| [175] |
Feser J, Truong D, Das C, et al. (2010) Elevated histone expression promotes life span extension. Mol Cell 39: 724-735. doi: 10.1016/j.molcel.2010.08.015
|
| [176] |
Winokur ST, Bengtsson U, Feddersen J, et al. (1994) The DNA rearrangement associated with facioscapulohumeral muscular dystrophy involves a heterochromatin-associated repetitive element: Implications for a role of chromatin structure in the pathogenesis of the disease. Chromosome Res 2: 225-234. doi: 10.1007/BF01553323
|
| [177] |
Makarov VL, Lejnine S, Bedoyan JK, et al. (1993) Nucleosomal organization of telomere-specific chromatin in rat. Cell 73: 775-787. doi: 10.1016/0092-8674(93)90256-P
|
| [178] |
Pina B, Martinez P, Simon L, et al. (1984) Differential kinetics of histone H1° accumulation in neuronal and glial cells from rat cerebral cortex during postnatal development. Biochem Biophys Res Commun 123: 697-702. doi: 10.1016/0006-291X(84)90285-7
|
| [179] | Drabent B, Kardalinou E, Doenecke D (1991) Structure and expression of the human testicular H1 histone (H1t) gene. GENBANK. |
| [180] | Alberts B, Johnson A, Lewis J, et al. (1994) Molecular Biology of the Cell, 3 edn. Garland Science, New York. |
| [181] |
Vickaryous MK, Hall BK (2006) Human cell type diversity, evolution, development, and classification with special reference to cells derived from the neural crest. Biol Rev Camb Philos Soc 81: 425-455. doi: 10.1017/S1464793106007068
|
| [182] | Margulis L, Chapman MJ (2009) Kingdoms and Domains: An Illustrated Guide to the Phyla of Life on Earth, 4 edn. Academic Press/Elsevier, Amsterdam. |
| [183] | Lyndon RF (1990) Plant Development. Unwin Hyman Ltd, London. |
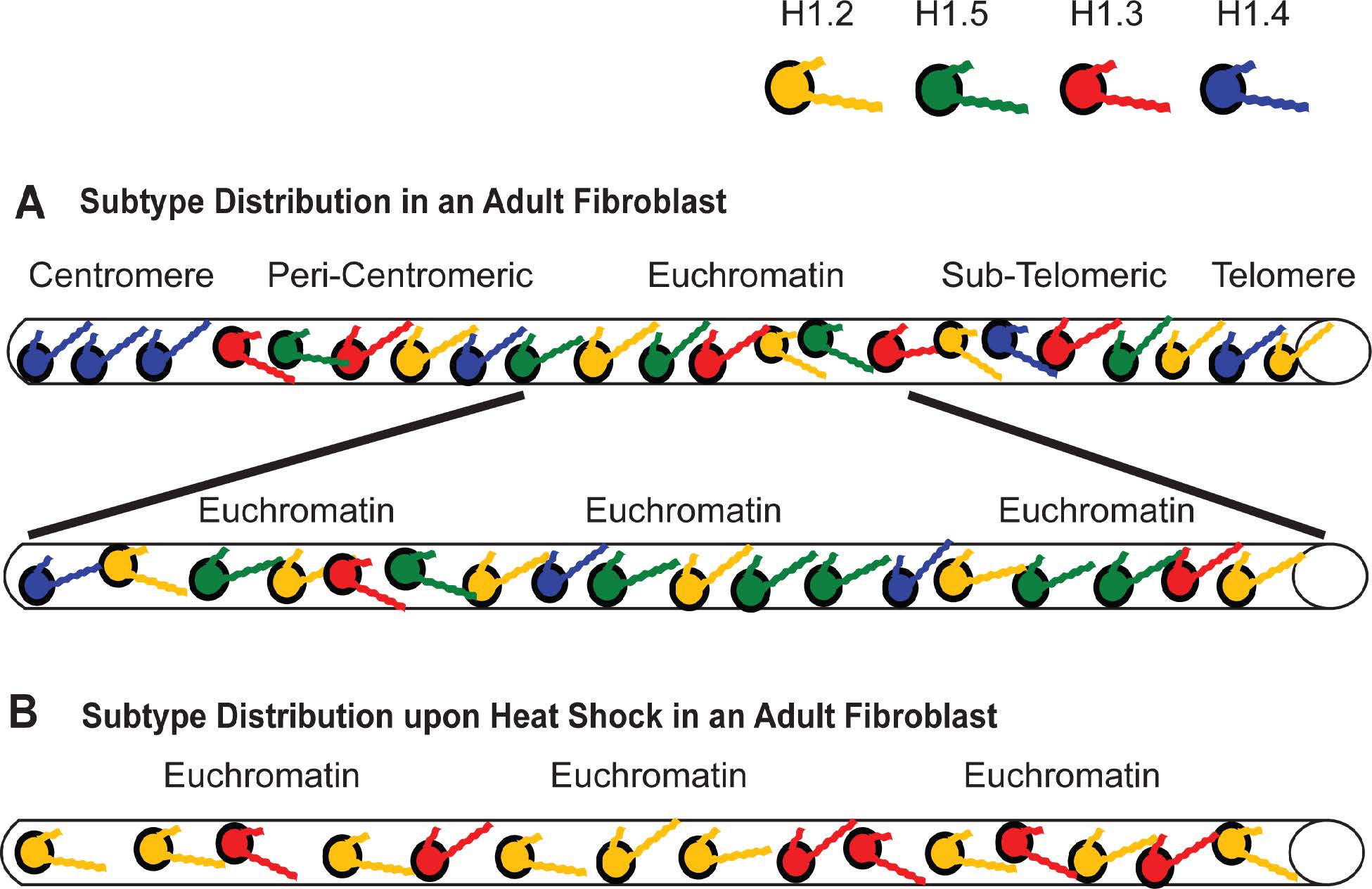
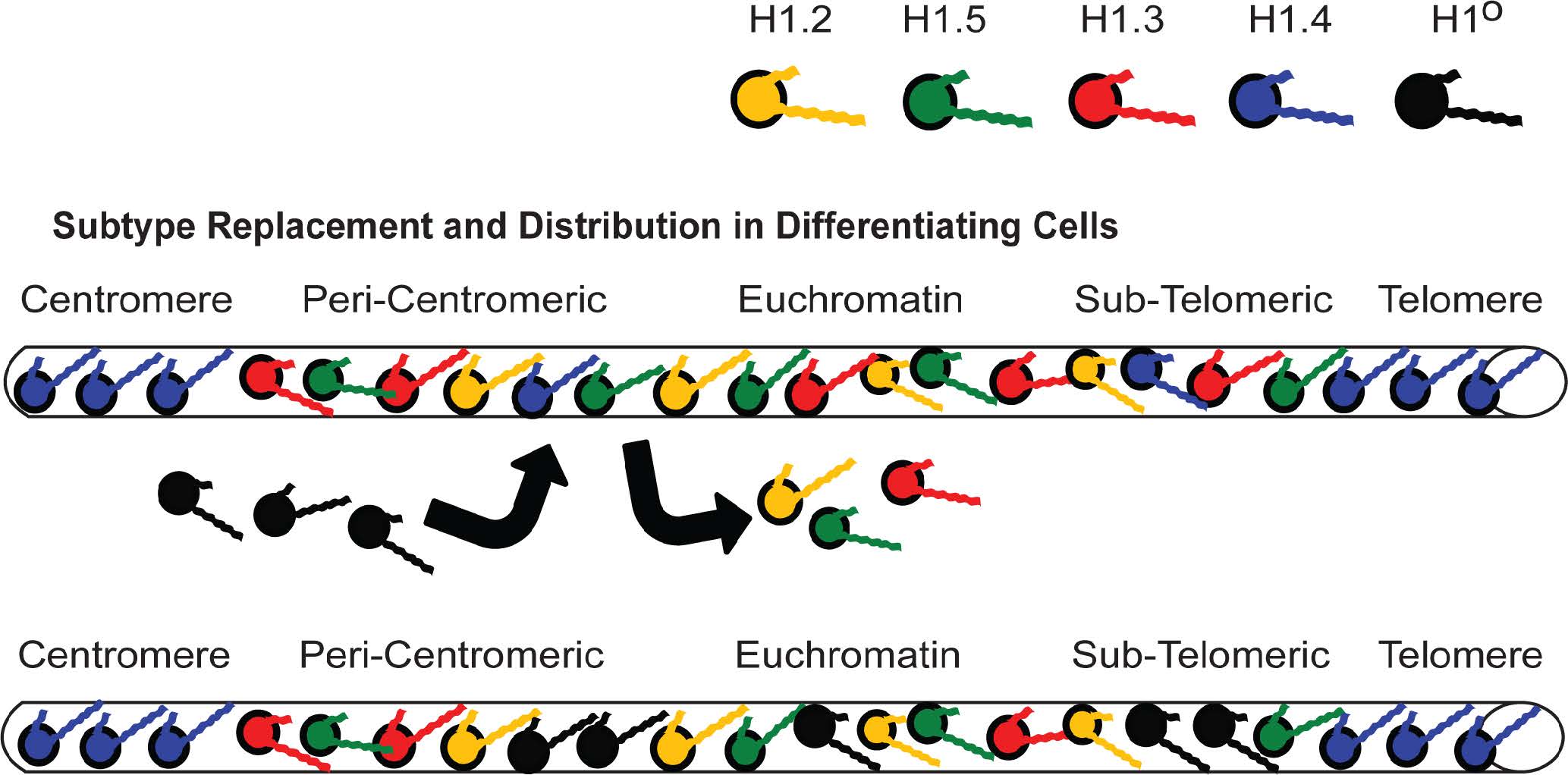
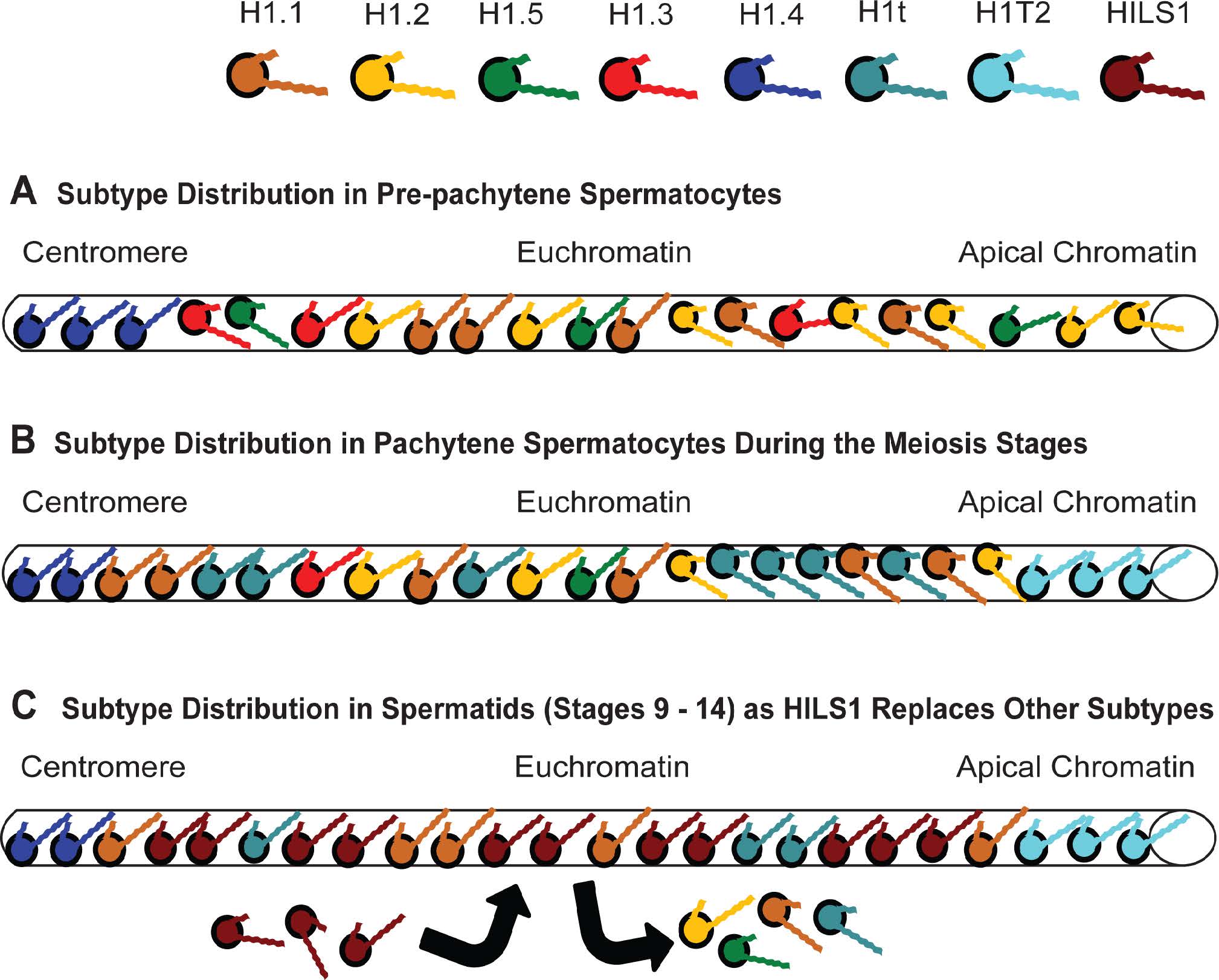
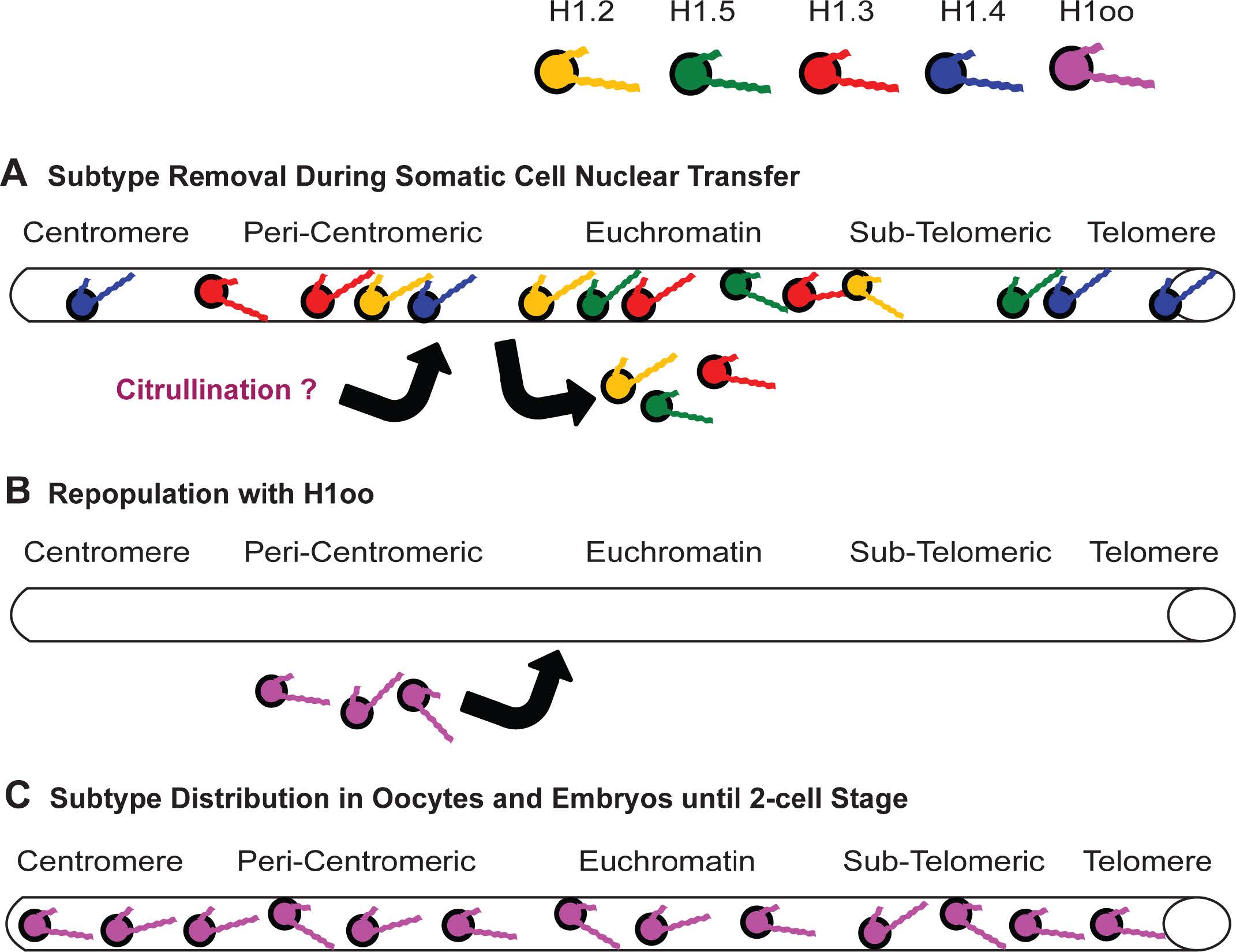
Figures(11) / Tables(4)

Missag Hagop Parseghian. What is the role of histone H1 heterogeneity? A functional model emerges from a 50 year mystery[J]. AIMS Biophysics, 2015, 2(4): 724-772. doi: 10.3934/biophy.2015.4.724







 DownLoad:
DownLoad: