Citation: Théo Lebeaupin, Hafida Sellou, Gyula Timinszky, Sébastien Huet. Chromatin dynamics at DNA breaks: what, how and why?[J]. AIMS Biophysics, 2015, 2(4): 458-475. doi: 10.3934/biophy.2015.4.458

| [1] | Woodcock CL, Ghosh RP (2010) Chromatin higher-order structure and dynamics. Cold Spring Harb Perspect Biol 2: a000596. |
| [2] |
Sexton T, Cavalli G (2015) The role of chromosome domains in shaping the functional genome. Cell 160: 1049–1059. doi: 10.1016/j.cell.2015.02.040

|
| [3] |
Miné-Hattab J, Rothstein R (2012) Increased chromosome mobility facilitates homology search during recombination. Nat Cell Biol 14: 510–517. doi: 10.1038/ncb2472
|
| [4] |
Khurana S, Kruhlak MJ, Kim J, et al. (2014) A macrohistone variant links dynamic chromatin compaction to BRCA1-dependent genome maintenance. Cell Rep 8: 1049–1062. doi: 10.1016/j.celrep.2014.07.024
|
| [5] |
Robinson PJJ, Fairall L, Huynh VAT, et al. (2006) EM measurements define the dimensions of the “30-nm” chromatin fiber: evidence for a compact, interdigitated structure. Proc Natl Acad Sci U S A 103: 6506–6511. doi: 10.1073/pnas.0601212103
|
| [6] |
Schalch T, Duda S, Sargent DF, et al. (2005) X-ray structure of a tetranucleosome and its implications for the chromatin fibre. Nature 436: 138–141. doi: 10.1038/nature03686
|
| [7] | Joti Y, Hikima T, Nishino, et al. (2012) Chromosomes without a 30-nm chromatin fiber. Nucl Austin Tex 3: 404–410. |
| [8] |
Fussner E, Ahmed K, Dehghani, et al. (2010) Changes in chromatin fiber density as a marker for pluripotency. Cold Spring Harb Symp Quant. Biol 75: 245–249. doi: 10.1101/sqb.2010.75.012
|
| [9] |
Yokota H, van den Engh G, Hearst JE, et al. (1995) Evidence for the organization of chromatin in megabase pair-sized loops arranged along a random walk path in the human G0/G1 interphase nucleus. J Cell Biol 130: 1239–1249. doi: 10.1083/jcb.130.6.1239
|
| [10] |
Petrascheck M, Escher D, Mahmoudi T et al. (2005) DNA looping induced by a transcriptional enhancer in vivo. Nucleic Acids Res. 33: 3743–3750. doi: 10.1093/nar/gki689
|
| [11] | Pombo A, Dillon N (2015) Three-dimensional genome architecture: players and mechanisms. Nat Rev Mol Cell Biol 16: 245–257. |
| [12] |
Dixon JR, Selvaraj S, Yue F, et al. (2012) Topological domains in mammalian genomes identified by analysis of chromatin interactions. Nature 485: 376–380. doi: 10.1038/nature11082
|
| [13] |
Nora EP, Lajoie BR, Schulz EG, et al. (2012) Spatial partitioning of the regulatory landscape of the X-inactivation centre. Nature 485: 381–385. doi: 10.1038/nature11049
|
| [14] |
Sexton T, Yaffe E, Kenigsberg E, et al. (2012) Three-dimensional folding and functional organization principles of the Drosophila genome. Cell 148: 458–472. doi: 10.1016/j.cell.2012.01.010
|
| [15] |
Lieberman-Aiden E, van Berkum NL, Williams L, et al. (2009) Comprehensive mapping of long-range interactions reveals folding principles of the human genome. Science 326: 289–293. doi: 10.1126/science.1181369
|
| [16] |
Bolzer A, Kreth G, Solovei I, et al. (2005) Three-dimensional maps of all chromosomes in human male fibroblast nuclei and prometaphase rosettes. PLoS Biol 3: e157. doi: 10.1371/journal.pbio.0030157
|
| [17] | Cremer T, Cremer M (2010) Chromosome territories. Cold Spring Harb Perspect Biol 2: a003889. |
| [18] | Kinney NA, Onufriev AV, Sharakhov IV (2015) Quantified effects of chromosome-nuclear envelope attachments on 3D organization of chromosomes. Nucl Austin Tex 6: 212–224. |
| [19] |
Heun P, Laroche T, Shimada K, et al. (2001) Chromosome dynamics in the yeast interphase nucleus. Science 294: 2181–2186. doi: 10.1126/science.1065366
|
| [20] |
Levi V, Ruan Q, Plutz M, et al. (2005) Chromatin dynamics in interphase cells revealed by tracking in a two-photon excitation microscope. Biophys J 89: 4275–4285. doi: 10.1529/biophysj.105.066670
|
| [21] | Hubner M, Spector D (2010) Chromatin Dynamics. Annu Rev Biophys 39: 471–489. |
| [22] | Javer A, Long Z, Nugent E, et al. (2013) Short-time movement of E. coli chromosomal loci depends on coordinate and subcellular localization. Nat Commun. 4: 3003. |
| [23] |
Gibcus JH, Dekker J (2013) The hierarchy of the 3D genome. Mol Cell 49: 773–782. doi: 10.1016/j.molcel.2013.02.011
|
| [24] |
Weber SC, Spakowitz AJ, Theriot JA (2012) Nonthermal ATP-dependent fluctuations contribute to the in vivo motion of chromosomal loci. Proc Natl Acad Sci U S A 109: 7338–7343. doi: 10.1073/pnas.1119505109
|
| [25] | Pliss A, Malyavantham KS, Bhattacharya S, et al. (2013) Chromatin dynamics in living cells: identification of oscillatory motion. J Cell Physiol 228, 609–616. |
| [26] |
Gerlich D, Beaudouin J, Kalbfuss B, et al. (2003) Global chromosome positions are transmitted through mitosis in mammalian cells. Cell 112: 751–764. doi: 10.1016/S0092-8674(03)00189-2
|
| [27] |
Walter J, Schermelleh L, Cremer M, et al. (2003) Chromosome order in HeLa cells changes during mitosis and early G1, but is stably maintained during subsequent interphase stages. J Cell Biol 160: 685–697. doi: 10.1083/jcb.200211103
|
| [28] |
Müller I, Boyle S, Singer RH, et al. (2010) Stable morphology, but dynamic internal reorganisation, of interphase human chromosomes in living cells. PloS One 5: e11560. doi: 10.1371/journal.pone.0011560
|
| [29] |
Kruhlak MJ, Celeste A, Dellaire G, et al. (2006) Changes in chromatin structure and mobility in living cells at sites of DNA double-strand breaks. J Cell Biol 172: 823–834. doi: 10.1083/jcb.200510015
|
| [30] |
Zink D, Cremer T, Saffrich R, et al. (1998) Structure and dynamics of human interphase chromosome territories in vivo. Hum Genet 102: 241–251. doi: 10.1007/s004390050686
|
| [31] |
Jackson DA, Pombo A (1998) Replicon clusters are stable units of chromosome structure: evidence that nuclear organization contributes to the efficient activation and propagation of S phase in human cells. J Cell Biol 140: 1285–1295. doi: 10.1083/jcb.140.6.1285
|
| [32] |
Robinett CC, Straight A, Li G, et al. (1996) In vivo localization of DNA sequences and visualization of large-scale chromatin organization using lac operator/repressor recognition. J Cell Biol 135: 1685–1700. doi: 10.1083/jcb.135.6.1685
|
| [33] |
Jacome A, Fernandez-Capetillo O (2011) Lac operator repeats generate a traceable fragile site in mammalian cells. EMBO Rep 12: 1032–1038. doi: 10.1038/embor.2011.158
|
| [34] |
Dubarry M, Loïodice I, Chen CL, et al. (2011) Tight protein-DNA interactions favor gene silencing. Genes Dev 25: 1365–1370. doi: 10.1101/gad.611011
|
| [35] |
Saad H, Gallardo F, Dalvai M, et al. (2014) DNA dynamics during early double-strand break processing revealed by non-intrusive imaging of living cells. PLoS Genet 10: e1004187. doi: 10.1371/journal.pgen.1004187
|
| [36] |
Chen B, Gilbert LA, Cimini BA, et al. (2013) Dynamic imaging of genomic loci in living human cells by an optimized CRISPR/Cas system. Cell 155: 1479–1491. doi: 10.1016/j.cell.2013.12.001
|
| [37] |
Miyanari Y, Ziegler-Birling C, Torres-Padilla M-E (2013) Live visualization of chromatin dynamics with fluorescent TALEs. Nat Struct Mol Biol 20: 1321–1324. doi: 10.1038/nsmb.2680
|
| [38] |
Zidovska A, Weitz DA, Mitchison TJ (2013) Micron-scale coherence in interphase chromatin dynamics. Proc Natl Acad Sci U S A 110: 15555–15560. doi: 10.1073/pnas.1220313110
|
| [39] |
Hinde E, Kong X, Yokomori K, et al. (2014) Chromatin dynamics during DNA repair revealed by pair correlation analysis of molecular flow in the nucleus. Biophys J 107: 55–65. doi: 10.1016/j.bpj.2014.05.027
|
| [40] |
Marshall WF, Straight A, Marko JF, et al. (1997) Interphase chromosomes undergo constrained diffusional motion in living cells. Curr Biol CB 7: 930–939. doi: 10.1016/S0960-9822(06)00412-X
|
| [41] |
Bornfleth H, Edelmann P, Zink D, et al. (1999) Quantitative motion analysis of subchromosomal foci in living cells using four-dimensional microscopy. Biophys J 77: 2871–2886. doi: 10.1016/S0006-3495(99)77119-5
|
| [42] | Qian H, Sheetz MP, Elson EL (1991) Single particle tracking. Analysis of diffusion and flow in two-dimensional systems. Biophys J 60: 910–921. |
| [43] |
Rosa A, Everaers R (2008) Structure and dynamics of interphase chromosomes. PLoS Comput Biol 4: e1000153. doi: 10.1371/journal.pcbi.1000153
|
| [44] | Hajjoul H, Mathon J, Ranchon H, et al. (2013) High-throughput chromatin motion tracking in living yeast reveals the flexibility of the fiber throughout the genome. Genome Res 23: 1829–1838. |
| [45] |
Havlin S, Ben-Avraham D (2002) Diffusion in disordered media. Adv Phys 51: 187–292. doi: 10.1080/00018730110116353
|
| [46] | Doi M (1996) Introduction to polymer physics Oxford University Press. |
| [47] |
Bronstein I, Israel Y, Kepten E, et al. (2009) Transient anomalous diffusion of telomeres in the nucleus of mammalian cells. Phys Rev Lett 103: 018102. doi: 10.1103/PhysRevLett.103.018102
|
| [48] |
Dion V, Kalck V, Seeber A, et al. (2013) Cohesin and the nucleolus constrain the mobility of spontaneous repair foci. EMBO Rep 14: 984–991. doi: 10.1038/embor.2013.142
|
| [49] |
Gartenberg MR, Neumann FR, Laroche T, et al. (2004) Sir-mediated repression can occur independently of chromosomal and subnuclear contexts. Cell 119: 955–967. doi: 10.1016/j.cell.2004.11.008
|
| [50] |
Hu Y, Kireev I, Plutz M, et al. (2009) Large-scale chromatin structure of inducible genes: transcription on a condensed, linear template. J Cell Biol 185: 87–100. doi: 10.1083/jcb.200809196
|
| [51] |
Neumann FR, Dion V, Gehlen LR, et al. (2012) Targeted INO80 enhances subnuclear chromatin movement and ectopic homologous recombination. Genes Dev 26: 369–383. doi: 10.1101/gad.176156.111
|
| [52] | Chuang C-H, Carpenter AE, Fuchsova B, et al. (2006) Long-range directional movement of an interphase chromosome site. Curr Biol 16: 825–831. |
| [53] | Khanna N, Hu Y, Belmont AS (2014) HSP70 transgene directed motion to nuclear speckles facilitates heat shock activation. Curr Biol 24: 1138–1144. |
| [54] | Chubb JR, Boyle S, Perry P, et al. (2002) Chromatin motion is constrained by association with nuclear compartments in human cells. Curr Biol 12: 439–445. |
| [55] |
Lucas JS, Zhang Y, Dudko OK, et al. (2014) 3D trajectories adopted by coding and regulatory DNA elements: first-passage times for genomic interactions. Cell 158: 339–352. doi: 10.1016/j.cell.2014.05.036
|
| [56] |
Daley JM, Gaines WA, Kwon Y, et al. (2014) Regulation of DNA pairing in homologous recombination. Cold Spring Harb Perspect Biol 6: a017954. doi: 10.1101/cshperspect.a017954
|
| [57] |
Lieber MR (2010) The mechanism of double-strand DNA break repair by the nonhomologous DNA end-joining pathway. Annu Rev Biochem 79: 181–211. doi: 10.1146/annurev.biochem.052308.093131
|
| [58] |
Sonoda E, Hochegger H, Saberi A, et al. (2006) Differential usage of non-homologous end-joining and homologous recombination in double strand break repair. DNA Repair 5: 1021–1029. doi: 10.1016/j.dnarep.2006.05.022
|
| [59] |
Dion V, Kalck V, Horigome C, et al. (2012) Increased mobility of double-strand breaks requires Mec1, Rad9 and the homologous recombination machinery. Nat Cell Biol 14: 502–509. doi: 10.1038/ncb2465
|
| [60] |
Seeber A, Dion V, Gasser SM (2013) Checkpoint kinases and the INO80 nucleosome remodeling complex enhance global chromatin mobility in response to DNA damage. Genes Dev 27: 1999–2008. doi: 10.1101/gad.222992.113
|
| [61] |
Lisby M, Mortensen UH, Rothstein R (2003) Colocalization of multiple DNA double-strand breaks at a single Rad52 repair centre. Nat Cell Biol 5: 572–577. doi: 10.1038/ncb997
|
| [62] |
Nagai S, Dubrana K, Tsai-Pflugfelder M, et al. (2008) Functional targeting of DNA damage to a nuclear pore-associated SUMO-dependent ubiquitin ligase. Science 322: 597–602. doi: 10.1126/science.1162790
|
| [63] | Kalocsay M, Hiller NJ, Jentsch S (2009) Chromosome-wide Rad51 spreading and SUMO-H2A.Z-dependent chromosome fixation in response to a persistent DNA double-strand break. Mol Cell 33: 335–343. |
| [64] |
Krawczyk PM, Borovski T, Stap J, et al. (2012) Chromatin mobility is increased at sites of DNA double-strand breaks. J Cell Sci 125: 2127–2133. doi: 10.1242/jcs.089847
|
| [65] |
Aten JA, Stap J, Krawczyk PM, et al. (2004) Dynamics of DNA double-strand breaks revealed by clustering of damaged chromosome domains. Science 303: 92–95. doi: 10.1126/science.1088845
|
| [66] |
Dimitrova N, Chen Y-CM, Spector DL, et al. (2008) 53BP1 promotes non-homologous end joining of telomeres by increasing chromatin mobility. Nature 456: 524–528. doi: 10.1038/nature07433
|
| [67] |
Jakob B, Splinter J, Conrad S, et al. (2011) DNA double-strand breaks in heterochromatin elicit fast repair protein recruitment, histone H2AX phosphorylation and relocation to euchromatin. Nucleic Acids Res 39: 6489–6499. doi: 10.1093/nar/gkr230
|
| [68] | Ježková L, Falk M, Falková I, et al. (2014) Function of chromatin structure and dynamics in DNA damage, repair and misrepair: γ-rays and protons in action. Appl Radiat Isot Data Instrum Methods Use Agric Ind Med 83: 128–136. |
| [69] |
Chiolo I, Minoda A, Colmenares SU, et al. (2011) Double-strand breaks in heterochromatin move outside of a dynamic HP1a domain to complete recombinational repair. Cell 144: 732–744. doi: 10.1016/j.cell.2011.02.012
|
| [70] |
Nelms BE, Maser RS, MacKay JF, et al. (1998) In situ visualization of DNA double-strand break repair in human fibroblasts. Science 280: 590–592. doi: 10.1126/science.280.5363.590
|
| [71] |
Jakob B, Splinter J, Durante M, et al. (2009) Live cell microscopy analysis of radiation-induced DNA double-strand break motion. Proc Natl Acad Sci U S A 106: 3172–3177. doi: 10.1073/pnas.0810987106
|
| [72] |
Soutoglou E, Dorn JF, Sengupta K, et al. (2007) Positional stability of single double-strand breaks in mammalian cells. Nat Cell Biol 9: 675–682. doi: 10.1038/ncb1591
|
| [73] |
Roukos V, Voss TC, Schmidt CK, et al. (2013) Spatial dynamics of chromosome translocations in living cells. Science 341: 660–664. doi: 10.1126/science.1237150
|
| [74] |
Smerdon MJ, Lieberman MW (1978) Nucleosome rearrangement in human chromatin during UV-induced DNA- reapir synthesis. Proc Natl Acad Sci U S A 75: 4238–4241. doi: 10.1073/pnas.75.9.4238
|
| [75] |
Ziv Y, Bielopolski D, Galanty Y, et al. (2006) Chromatin relaxation in response to DNA double-strand breaks is modulated by a novel ATM- and KAP-1 dependent pathway. Nat Cell Biol 8: 870–876. doi: 10.1038/ncb1446
|
| [76] |
Burgess RC, Burman B, Kruhlak MJ, et al. (2014) Activation of DNA damage response signaling by condensed chromatin. Cell Rep 9: 1703–1717. doi: 10.1016/j.celrep.2014.10.060
|
| [77] |
Smeenk G, Wiegant WW, Marteijn JA, et al. (2013) Poly(ADP-ribosyl)ation links the chromatin remodeler SMARCA5/SNF2H to RNF168-dependent DNA damage signaling. J Cell Sci 126: 889–903. doi: 10.1242/jcs.109413
|
| [78] |
Baldeyron C, Soria G, Roche D, et al. (2011) HP1alpha recruitment to DNA damage by p150CAF-1 promotes homologous recombination repair. J Cell Biol 193: 81–95. doi: 10.1083/jcb.201101030
|
| [79] |
Ayrapetov MK, Gursoy-Yuzugullu O, Xu C, et al. (2014) DNA double-strand breaks promote methylation of histone H3 on lysine 9 and transient formation of repressive chromatin. Proc Natl Acad Sci U S A 111: 9169–9174. doi: 10.1073/pnas.1403565111
|
| [80] |
Zhu L, Brangwynne CP (2015) Nuclear bodies: the emerging biophysics of nucleoplasmic phases. Curr Opin Cell Biol 34: 23–30. doi: 10.1016/j.ceb.2015.04.003
|
| [81] |
Chubb JR, Bickmore WA (2003) Considering nuclear compartmentalization in the light of nuclear dynamics. Cell 112: 403–406. doi: 10.1016/S0092-8674(03)00078-3
|
| [82] |
Lemaître C, Soutoglou E (2015) DSB (Im)mobility and DNA repair compartmentalization in mammalian cells. J Mol Biol 427: 652–658. doi: 10.1016/j.jmb.2014.11.014
|
| [83] |
Klein IA, Resch W, Jankovic M, et al. (2011) Translocation-capture sequencing reveals the extent and nature of chromosomal rearrangements in B lymphocytes. Cell 147: 95–106. doi: 10.1016/j.cell.2011.07.048
|
| [84] |
Murr R, Loizou JI, Yang Y-G, et al. (2006) Histone acetylation by Trrap-Tip60 modulates loading of repair proteins and repair of DNA double-strand breaks. Nat Cell Biol 8: 91–99. doi: 10.1038/ncb1343
|
| [85] |
Verschure PJ, van der Kraan I, Manders EMM, et al. (2003) Condensed chromatin domains in the mammalian nucleus are accessible to large macromolecules. EMBO Rep 4: 861–866. doi: 10.1038/sj.embor.embor922
|
| [86] |
Bancaud A, Huet S, Daigle N, et al. (2009) Molecular crowding affects diffusion and binding of nuclear proteins in heterochromatin and reveals the fractal organization of chromatin. EMBO J 28: 3785–3798. doi: 10.1038/emboj.2009.340
|
| [87] |
Dinant C, de Jager M, Essers J, et al. (2007) Activation of multiple DNA repair pathways by sub-nuclear damage induction methods. J Cell Sci 120: 2731–2740. doi: 10.1242/jcs.004523
|
| [88] |
Kong X, Mohanty SK, Stephens J, et al. (2009) Comparative analysis of different laser systems to study cellular responses to DNA damage in mammalian cells. Nucleic Acids Res 37: e68. doi: 10.1093/nar/gkp221
|
| [89] |
Gilbert N, Allan J (2014) Supercoiling in DNA and chromatin. Curr Opin Genet Dev 25: 15–21. doi: 10.1016/j.gde.2013.10.013
|
| [90] |
Elbel T, Langowski J (2015) The effect of DNA supercoiling on nucleosome structure and stability. J Phys Condens Matter Inst Phys J 27: 064105. doi: 10.1088/0953-8984/27/6/064105
|
| [91] |
Polo SE (2015) Reshaping chromatin after DNA damage: the choreography of histone proteins. J Mol Biol 427: 626–636. doi: 10.1016/j.jmb.2014.05.025
|
| [92] |
Downs JA, Lowndes NF, Jackson SP (2000) A role for Saccharomyces cerevisiae histone H2A in DNA repair. Nature 408: 1001–1004. doi: 10.1038/35050000
|
| [93] |
Heo K, Kim H, Choi SH, et al. (2008) FACT-mediated exchange of histone variant H2AX regulated by phosphorylation of H2AX and ADP-ribosylation of Spt16. Mol Cell 30: 86–97. doi: 10.1016/j.molcel.2008.02.029
|
| [94] | Li A, Yu Y, Lee S-C, et al. (2010) Phosphorylation of histone H2A.X by DNA-dependent protein kinase is not affected by core histone acetylation, but it alters nucleosome stability and histone H1 binding. J Biol Chem 285: 17778–17788. |
| [95] |
Golia B, Singh HR, Timinszky G (2015) Poly-ADP-ribosylation signaling during DNA damage repair. Front Biosci Landmark Ed 20: 440–457. doi: 10.2741/4318
|
| [96] |
Poirier GG, de Murcia G, Jongstra-Bilen J, et al. (1982) Poly(ADP-ribosyl)ation of polynucleosomes causes relaxation of chromatin structure. Proc Natl Acad Sci U S A 79: 3423–3427. doi: 10.1073/pnas.79.11.3423
|
| [97] | de Murcia G, Huletsky A, Lamarre D, et al. (1986) Modulation of chromatin superstructure induced by poly(ADP-ribose) synthesis and degradation. J Biol Chem 261: 7011–7017. |
| [98] | Xu Y, Ayrapetov MK, Xu C, et al. (2012) Histone H2A.Z controls a critical chromatin remodeling step required for DNA double-strand break repair. Mol Cell 48: 723–733. |
| [99] |
Clapier CR, Cairns BR (2009) The biology of chromatin remodeling complexes. Annu Rev Biochem 78: 273–304. doi: 10.1146/annurev.biochem.77.062706.153223
|
| [100] |
Cheezum MK, Walker WF, Guilford WH (2001) Quantitative comparison of algorithms for tracking single fluorescent particles. Biophys J 81: 2378–2388. doi: 10.1016/S0006-3495(01)75884-5
|
| [101] |
Wombacher R, Heidbreder M, van de Linde S, et al. (2010) Live-cell super-resolution imaging with trimethoprim conjugates. Nat Methods 7: 717–719. doi: 10.1038/nmeth.1489
|
| [102] |
Benke A, Manley S (2012) Live-cell dSTORM of cellular DNA based on direct DNA labeling. Chembiochem Eur J Chem Biol 13: 298–301. doi: 10.1002/cbic.201100679
|
| [103] |
Hihara S, Pack C-G, Kaizu K, et al. (2012) Local nucleosome dynamics facilitate chromatin accessibility in living mammalian cells. Cell Rep 2: 1645–1656. doi: 10.1016/j.celrep.2012.11.008
|
| [104] | Récamier V, Izeddin I, Bosanac L, et al. (2014) Single cell correlation fractal dimension of chromatin: a framework to interpret 3D single molecule super-resolution. Nucl Austin Tex 5: 75–84. |
| [105] |
Ricci MA, Manzo C, García-Parajo MF, et al. (2015) Chromatin fibers are formed by heterogeneous groups of nucleosomes in vivo. Cell 160: 1145–1158. doi: 10.1016/j.cell.2015.01.054
|
| [106] |
Zhang Y, Máté G, Müller P, et al. (2015) Radiation induced chromatin conformation changes analysed by fluorescent localization microscopy, statistical physics, and graph theory. PloS One 10: e0128555. doi: 10.1371/journal.pone.0128555
|
| [107] |
Llères D, James J, Swift S, et al. (2009) Quantitative analysis of chromatin compaction in living cells using FLIM-FRET. J Cell Biol 187: 481–496. doi: 10.1083/jcb.200907029
|
| [108] |
Emanuel M, Radja NH, Henriksson A, et al. (2009) The physics behind the larger scale organization of DNA in eukaryotes. Phys Biol 6: 025008. doi: 10.1088/1478-3975/6/2/025008
|
| [109] |
Rouse P (1953) A Theory of the Linear Viscoelastic Properties of Dilute Solutions of Coiling Polymers. J Chem Phys 21: 1272–1280. doi: 10.1063/1.1699180
|
| [110] |
Weber SC, Spakowitz AJ, Theriot JA (2010) Bacterial chromosomal loci move subdiffusively through a viscoelastic cytoplasm. Phys Rev Lett 104: 238102. doi: 10.1103/PhysRevLett.104.238102
|
| [111] | Metzler R, Jeon J-H, Cherstvy AG, et al. (2014) Anomalous diffusion models and their properties: non-stationarity, non-ergodicity, and ageing at the centenary of single particle tracking. Phys Chem Chem Phys 16: 24128–24164. |
| [112] | Mirny LA (2011) The fractal globule as a model of chromatin architecture in the cell. Chromosome Res Int J Mol Supramol Evol Asp Chromosome Biol 19: 37–51. |
| [113] |
Huet S, Lavelle C, Ranchon H, et al. (2014) Relevance and limitations of crowding, fractal, and polymer models to describe nuclear architecture. Int Rev Cell Mol Biol 307: 443–479. doi: 10.1016/B978-0-12-800046-5.00013-8
|
| [114] |
Barbieri M, Chotalia M, Fraser J, et al. (2012) Complexity of chromatin folding is captured by the strings and binders switch model. Proc Natl Acad Sci U S A 109: 16173–16178. doi: 10.1073/pnas.1204799109
|
| [115] |
Mateos-Langerak J, Bohn M, de Leeuw W, et al. (2009) Spatially confined folding of chromatin in the interphase nucleus. Proc Natl Acad Sci U S A 106: 3812–3817. doi: 10.1073/pnas.0809501106
|
| [116] |
Bohn M, Heermann DW (2010) Diffusion-driven looping provides a consistent framework for chromatin organization. PloS One 5: e12218. doi: 10.1371/journal.pone.0012218
|
| [117] |
Jerabek H, Heermann DW (2014) How chromatin looping and nuclear envelope attachment affect genome organization in eukaryotic cell nuclei. Int Rev Cell Mol Biol 307: 351–381. doi: 10.1016/B978-0-12-800046-5.00010-2
|
| [118] | Cook PR, Marenduzzo D (2009) Entropic organization of interphase chromosomes. J Cell Biol 186: 825–834. |
| [119] |
Bohn M, Heermann DW (2011) Repulsive forces between looping chromosomes induce entropy-driven segregation. PloS One 6: e14428. doi: 10.1371/journal.pone.0014428
|
| [120] |
Jost D, Carrivain P, Cavalli G, et al. (2014) Modeling epigenome folding: formation and dynamics of topologically associated chromatin domains. Nucleic Acids Res 42: 9553–9561. doi: 10.1093/nar/gku698
|
| [121] |
Finan K, Cook PR, Marenduzzo D (2011) Non-specific (entropic) forces as major determinants of the structure of mammalian chromosomes. Chromosome Res Int J Mol Supramol Evol Asp Chromosome Biol 19: 53–61. doi: 10.1007/s10577-010-9150-y
|
| [122] |
Zhang B, Wolynes PG (2015) Topology, structures, and energy landscapes of human chromosomes. Proc Natl. Acad Sci U S A 112: 6062–6067. doi: 10.1073/pnas.1506257112
|
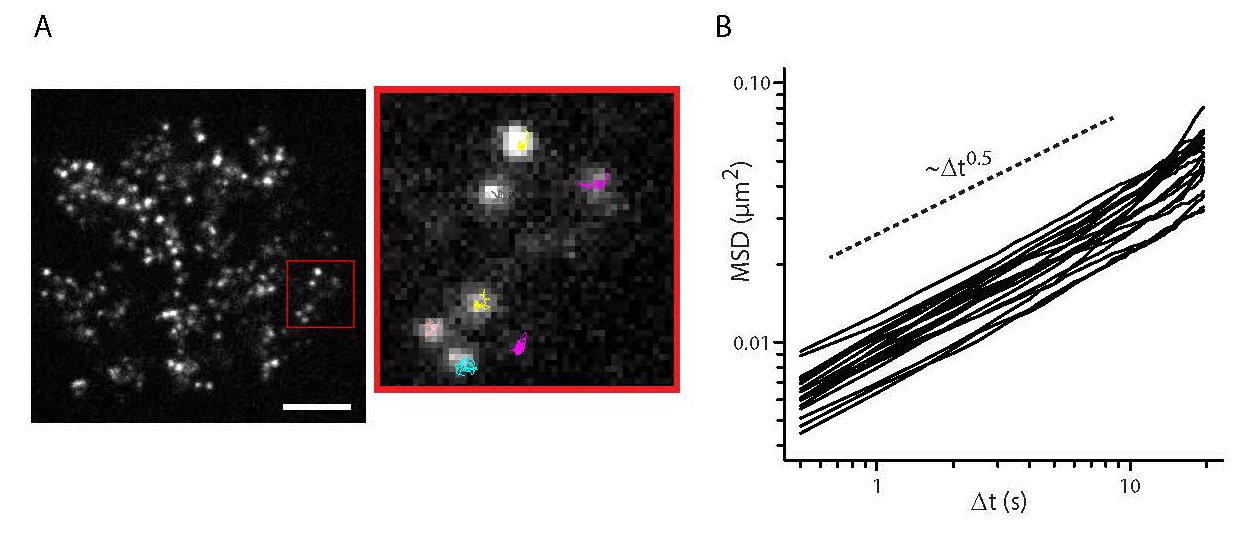
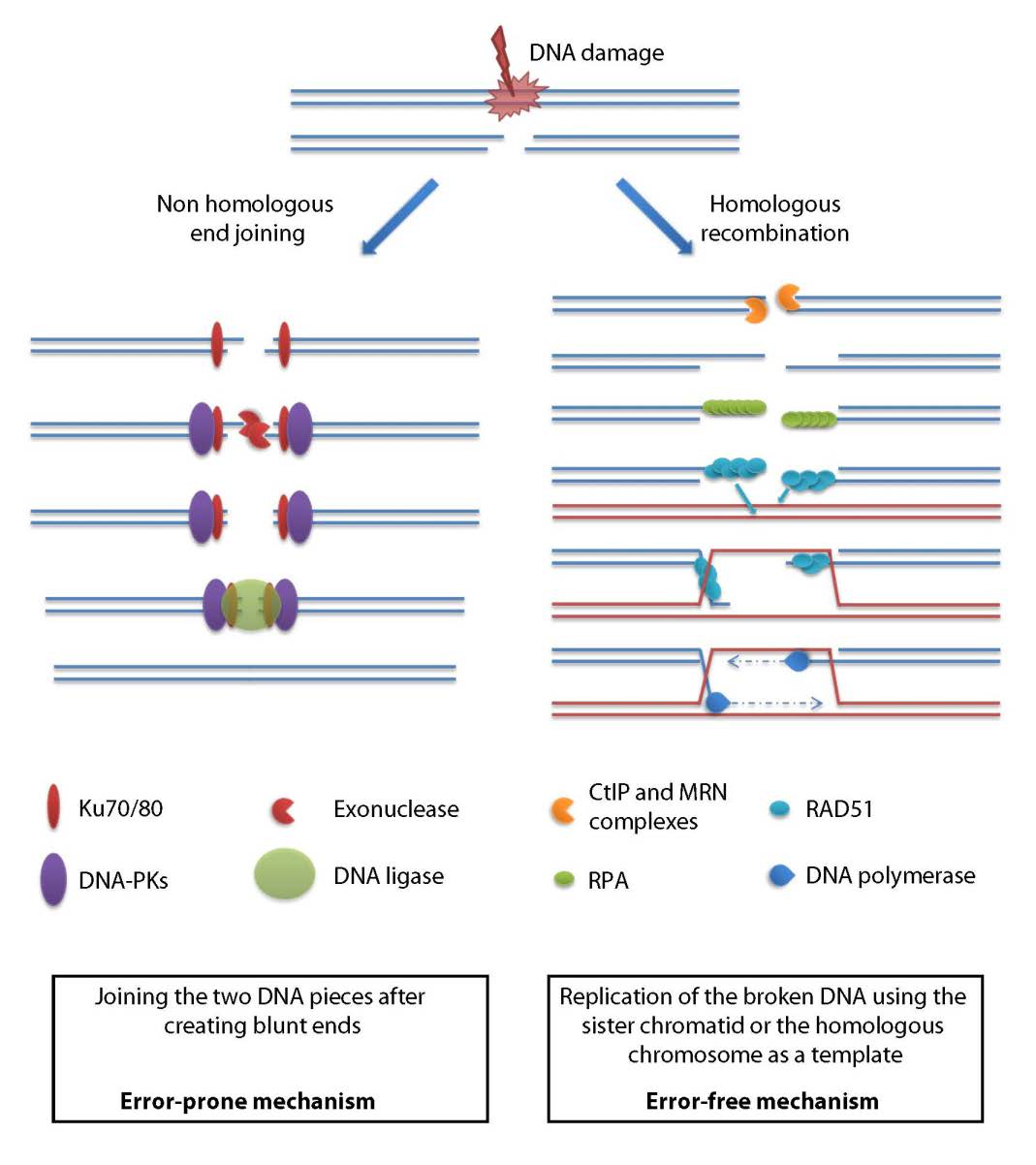
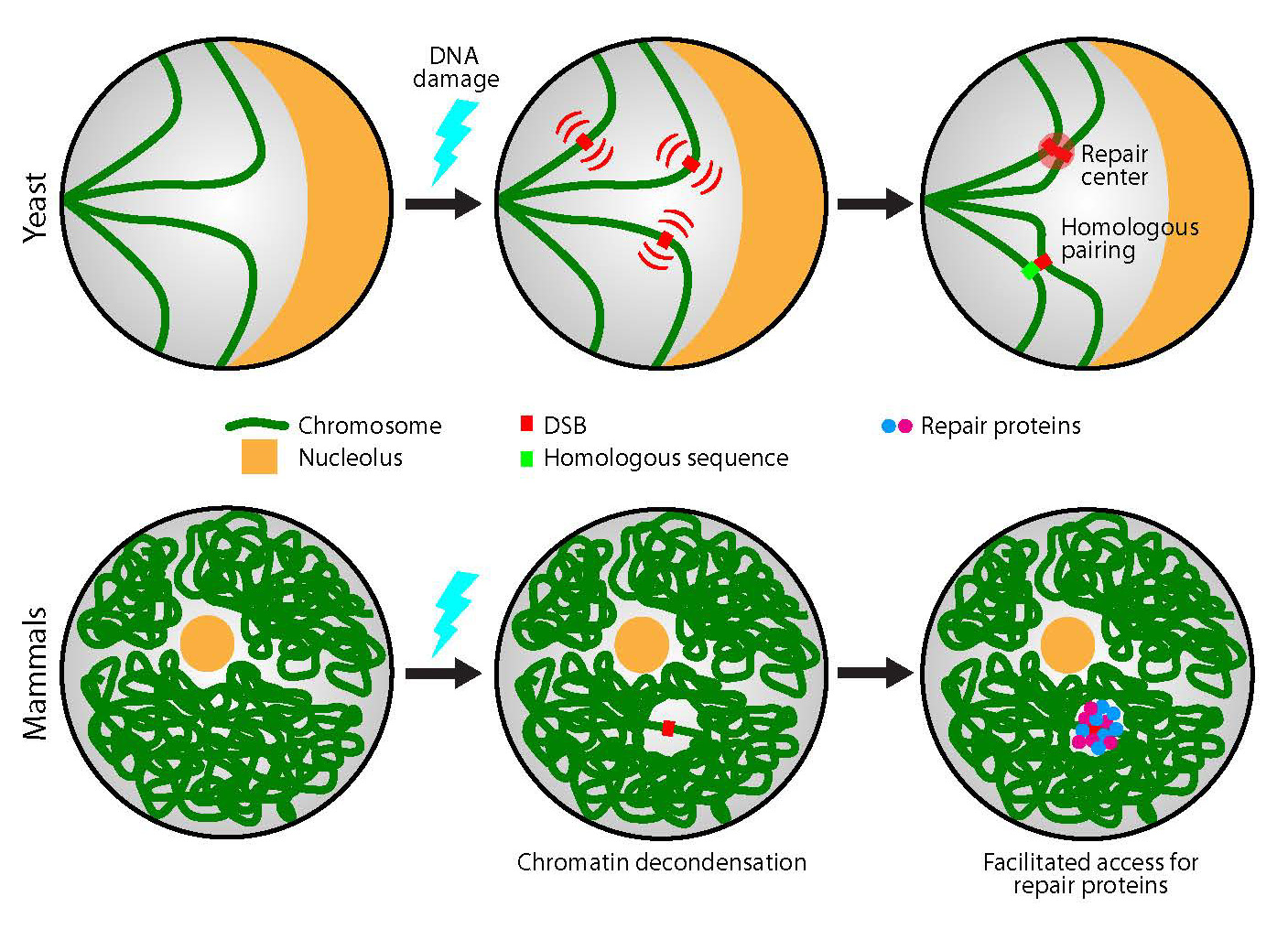
Figures(3)

Théo Lebeaupin, Hafida Sellou, Gyula Timinszky, Sébastien Huet. Chromatin dynamics at DNA breaks: what, how and why?[J]. AIMS Biophysics, 2015, 2(4): 458-475. doi: 10.3934/biophy.2015.4.458







 DownLoad:
DownLoad: