Citation: Vered Tzin, Ilana Rogachev, Sagit Meir, Michal Moyal Ben Zvi, Tania Masci, Alexander Vainstein, Asaph Aharoni, Gad Galili. Altered Levels of Aroma and Volatiles by Metabolic Engineering of Shikimate Pathway Genes in Tomato Fruits[J]. AIMS Bioengineering, 2015, 2(2): 75-92. doi: 10.3934/bioeng.2015.2.75

| [1] |
Ioannidi E, Kalamaki MS, Engineer C, et al. (2009) Expression profiling of ascorbic acid-related genes during tomato fruit development and ripening and in response to stress conditions. J Exp Bot 60: 663-678. doi: 10.1093/jxb/ern322

|
| [2] | Petro-Turza M (1987) Flavor of tomato and tomato products. Food Rev Int 2: 309-351. |
| [3] |
Buttery R, Takeoka G, Teranishi R, et al. (1990) Tomato aroma components: identification of glycoside hydrolysis volatiles. J Agr Food Chem 38: 2050-2053. doi: 10.1021/jf00101a010
|
| [4] |
Klee HJ, Giovannoni JJ (2011) Genetics and control of tomato fruit ripening and quality attributes. Annu Rev Genet 45: 41-59. doi: 10.1146/annurev-genet-110410-132507
|
| [5] |
Zanor MI, Rambla JL, Chaib J, et al. (2009) Metabolic characterization of loci affecting sensory attributes in tomato allows an assessment of the influence of the levels of primary metabolites and volatile organic contents. J Exp Bot 60: 2139-2154. doi: 10.1093/jxb/erp086
|
| [6] |
Goff SA, Klee HJ (2006) Plant volatile compounds: sensory cues for health and nutritional value? Science (New York, N Y ) 311: 815-819. doi: 10.1126/science.1112614
|
| [7] |
Dudareva N, Pichersky E, Gershenzon J (2004) Biochemistry of plant volatiles. Plant Physiol 135: 1893-1902. doi: 10.1104/pp.104.049981
|
| [8] | Tikunov Y, Lommen A, De Vos R, et al. (2005) A novel approach for non targeted data analysis for metabolomics: large-scale profiling of tomato fruit volatiles. Plant Physiology: 1125-1137. |
| [9] |
Vogt T (2010) Phenylpropanoid biosynthesis. Mol Plant 3: 2-20. doi: 10.1093/mp/ssp106
|
| [10] | Tzin V, Galili G, Aharoni A (2012) Shikimate pathway and aromatic amino acid biosynthesis. eLS ohn Wiley & Sons Ltd. |
| [11] |
Tzin V, Galili G (2010) New insights into the shikimate and aromatic amino acids biosynthesis pathways in plants. Mol Plant 3: 956-972. doi: 10.1093/mp/ssq048
|
| [12] |
Oliva M, Ovadia R, Perl A, et al. (2015) Enhanced formation of aromatic amino acids increases fragrance without affecting flower longevity or pigmentation in Petunia × hybrida. Plant Biotechnology Journal 13: 125-136. doi: 10.1111/pbi.12253
|
| [13] |
Colquhoun TA, Clark DG (2011) Unraveling the regulation of floral fragrance biosynthesis. Plant Signal Behav 6: 378-381. doi: 10.4161/psb.6.3.14339
|
| [14] |
Pratelli R, Pilot G (2014) Regulation of amino acid metabolic enzymes and transporters in plants. J Exp Bot 65: 5535-5556. doi: 10.1093/jxb/eru320
|
| [15] |
Voll LM, Allaire EE, Fiene G, et al. (2004) The Arabidopsis phenylalanine insensitive growth mutant exhibits a deregulated amino acid metabolism. . Plant Physiology 136: 3058-3069. doi: 10.1104/pp.104.047506
|
| [16] |
Pratelli R, Voll LM, Horst RJ, et al. (2010) Stimulation of nonselective amino acid export by glutamine dumper proteins. Plant Physiol 152: 762-773. doi: 10.1104/pp.109.151746
|
| [17] |
Galili G, Amir R (2013) Fortifying plants with the essential amino acids lysine and methionine to improve nutritional quality. Plant Biotechnol J 11: 211-222. doi: 10.1111/pbi.12025
|
| [18] |
Vivancos PD, Driscoll SP, Bulman CA, et al. (2011) Perturbations of amino Acid metabolism associated with glyphosate-dependent inhibition of shikimic Acid metabolism affect cellular redox homeostasis and alter the abundance of proteins involved in photosynthesis and photorespiration. Plant Physiology 157: 256-268. doi: 10.1104/pp.111.181024
|
| [19] |
Tzin V, Malitsky S, Ben Zvi MM, et al. (2012) Expression of a bacterial feedback-insensitive 3-deoxy-D-arabino-heptulosonate 7-phosphate synthase of the shikimate pathway in Arabidopsis elucidates potential metabolic bottlenecks between primary and secondary metabolism. New Phytol 194: 430-439. doi: 10.1111/j.1469-8137.2012.04052.x
|
| [20] |
Baldwin GS, Davidson BE (1981) A kinetic and structural comparison of chorismate mutase/prephenate dehydratase from mutant strains of Escherichia coli K 12 defective in the PheA gene. Arch Biochem Biophys 211: 66-75. doi: 10.1016/0003-9861(81)90430-6
|
| [21] |
Tzin V, Rogachev I, Meir S, et al. (2013) Tomato fruits expressing a bacterial feedback-insensitive 3-deoxy-D-arabino-heptulosonate 7-phosphate synthase of the shikimate pathway possess enhanced levels of multiple specialized metabolites and upgraded aroma. J Exp Bot 64: 4441-4452. doi: 10.1093/jxb/ert250
|
| [22] |
Langer KM, Jones CR, Jaworski EA, et al. (2014) PhDAHP1 is required for floral volatile benzenoid/phenylpropanoid biosynthesis in Petunia × hybrida cv ‘Mitchell Diploid’. Phytochemistry 103: 22-31. doi: 10.1016/j.phytochem.2014.04.004
|
| [23] |
Maeda H, Shasany AK, Schnepp J, et al. (2010) RNAi Suppression of Arogenate Dehydratase1 Reveals That Phenylalanine Is Synthesized Predominantly via the Arogenate Pathway in Petunia Petals. Plant Cell 22: 832-849. doi: 10.1105/tpc.109.073247
|
| [24] |
Tzin V, Malitsky S, Aharoni A, et al. (2009) Expression of a bacterial bi-functional chorismate mutase/prephenate dehydratase modulates primary and secondary metabolism associated with aromatic amino acids in Arabidopsis. Plant J 60: 156-167. doi: 10.1111/j.1365-313X.2009.03945.x
|
| [25] | Yoo H, Widhalm JR, Qian YC, et al. (2013) An alternative pathway contributes to phenylalanine biosynthesis in plants via a cytosolic tyrosine:phenylpyruvate aminotransferase. Nature Communications 4. |
| [26] |
Adato A, Mandel T, Mintz-Oron S, et al. (2009) Fruit-surface flavonoid accumulation in tomato is controlled by a SlMYB12-regulated transcriptional network. PLoS Genetics 5: e1000777. doi: 10.1371/journal.pgen.1000777
|
| [27] |
Deikman J, Kline R, Fischer RL (1992) Organization of Ripening and Ethylene Regulatory Regions in a Fruit-Specific Promoter from Tomato (Lycopersicon esculentum). Plant Physiology 100: 2013-2017. doi: 10.1104/pp.100.4.2013
|
| [28] |
Zhao L, Lu L, Zhang L, et al. (2009) Molecular evolution of the E8 promoter in tomato and some of its relative wild species. J Biosciences 34: 71-83. doi: 10.1007/s12038-009-0010-x
|
| [29] |
Shaul O, Galili G (1993) Concerted regulation of lysine and threonine synthesis in tobacco plants expressing bacterial feedback-insensitive aspartate kinase and dihydrodipicolinate synthase. Plant Molecular Biology 23: 759-768. doi: 10.1007/BF00021531
|
| [30] | McCormick S (1991) Transformation of tomato with Agrobacterium tumefaciens; Lindsey K, editor: Kluwer. |
| [31] |
Filati J, Kiser J, Rose R, et al. (1987) Efficient transfer of a glyphosphate tolerance gene into tomato using a binary Agrobacterium tumefaciens vector. Biotechnology 5: 726-730. doi: 10.1038/nbt0787-726
|
| [32] |
Mintz-Oron S, Mandel T, Rogachev I, et al. (2008) Gene expression and metabolism in tomato fruit surface tissues. Plant Physiology 147: 823-851. doi: 10.1104/pp.108.116004
|
| [33] |
Smith CA, Want EJ, O'Maille G, et al. (2006) XCMS: processing mass spectrometry data for metabolite profiling using nonlinear peak alignment, matching, and identification. Anal Chem 78: 779-787. doi: 10.1021/ac051437y
|
| [34] | Saeed AI, Sharov V, White J, et al. (2003) TM4: a free, open-source system for microarray data management and analysis. Biotechniques 34: 374-378. |
| [35] |
Scholz M, Gatzek S, Sterling A, et al. (2004) Metabolite fingerprinting: detecting biological features by independent component analysis. Bioinformatics 20: 2447-2454. doi: 10.1093/bioinformatics/bth270
|
| [36] |
Spitzer-Rimon B, Marhevka E, Barkai O, et al. (2010) EOBII, a Gene Encoding a Flower-Specific Regulator of Phenylpropanoid Volatiles' Biosynthesis in Petunia. Plant Cell 22: 1961-1976. doi: 10.1105/tpc.109.067280
|
| [37] |
Davidovich-Rikanati R, Sitrit Y, Tadmor Y, et al. (2007) Enrichment of tomato flavor by diversion of the early plastidial terpenoid pathway. Nat Biotechnol 25: 899-901. doi: 10.1038/nbt1312
|
| [38] |
Hu C, Jiang P, Xu J, et al. (2003) Mutation analysis of the feedback inhibition site of phenylalanine-sensitive 3-deoxy-D-arabino-heptulosonate 7-phosphate synthase of Escherichia coli. J Basic Microb 43: 399-406. doi: 10.1002/jobm.200310244
|
| [39] | Zhang S, Pohnert G, Kongsaeree P, et al. (1998) Chorismate mutase-prephenate dehydratase from Escherichia coli. Study of catalytic and regulatory domains using genetically engineered proteins. J Biol Chem 273: 6248-6253. |
| [40] |
Carrari F, Baxter C, Usadel B, et al. (2006) Integrated analysis of metabolite and transcript levels reveals the metabolic shifts that underlie tomato fruit development and highlight regulatory aspects of metabolic network behavior. Plant Physiology 142: 1380-1396. doi: 10.1104/pp.106.088534
|
| [41] |
Osorio S, Vallarino JG, Szecowka M, et al. (2013) Alteration of the interconversion of pyruvate and malate in the plastid or cytosol of ripening tomato fruit invokes diverse consequences on sugar but similar effects on cellular organic acid, metabolism, and transitory starch accumulation. Plant Physiol 161: 628-643. doi: 10.1104/pp.112.211094
|
| [42] | Rogachev I, Aharoni A (2012) UPLC-MS-based metabolite analysis in tomato. Methods Mol Biol (Clifton, N J ) 860: 129-144. |
| [43] | Baldwin E, Scott J, Einstein M, et al. (1998) Relationship between sensory and instrumental analysis for tomato flavor. J Am Soc Hortic Sci 906-915. |
| [44] |
Dal Cin V, Tieman DM, Tohge T, et al. (2011) Identification of Genes in the Phenylalanine Metabolic Pathway by Ectopic Expression of a MYB Transcription Factor in Tomato Fruit. Plant Cell 23: 2738-2753. doi: 10.1105/tpc.111.086975
|
| [45] |
Kaminaga Y, Schnepp J, Peel G, et al. (2006) Plant phenylacetaldehyde synthase is a bifunctional homotetrameric enzyme that catalyzes phenylalanine decarboxylation and oxidation. J Biol Chem 281: 23357-23366. doi: 10.1074/jbc.M602708200
|
| [46] |
Zvi MMB, Shklarman E, Masci T, et al. (2012) PAP1 transcription factor enhances production of phenylpropanoid and terpenoid scent compounds in rose flowers. New Phytol 195: 335-345. doi: 10.1111/j.1469-8137.2012.04161.x
|
| [47] | Baldwin EA, Scott JW, Shewmaker CK, et al. (2000) Flavor trivia and tomato aroma: Biochemistry and possible mechanisms for control of important aroma components. Hortscience 35: 1013-1022. |
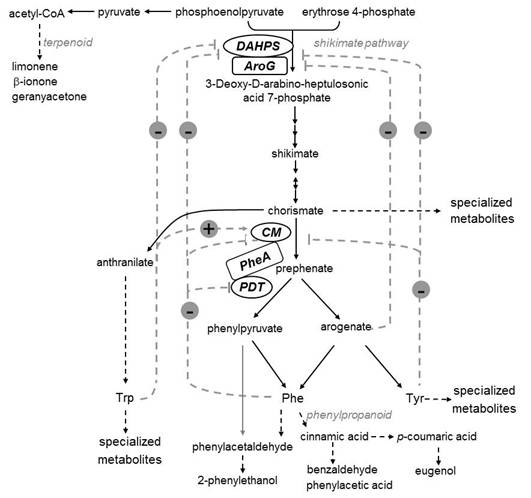
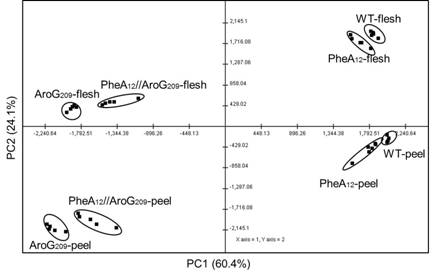
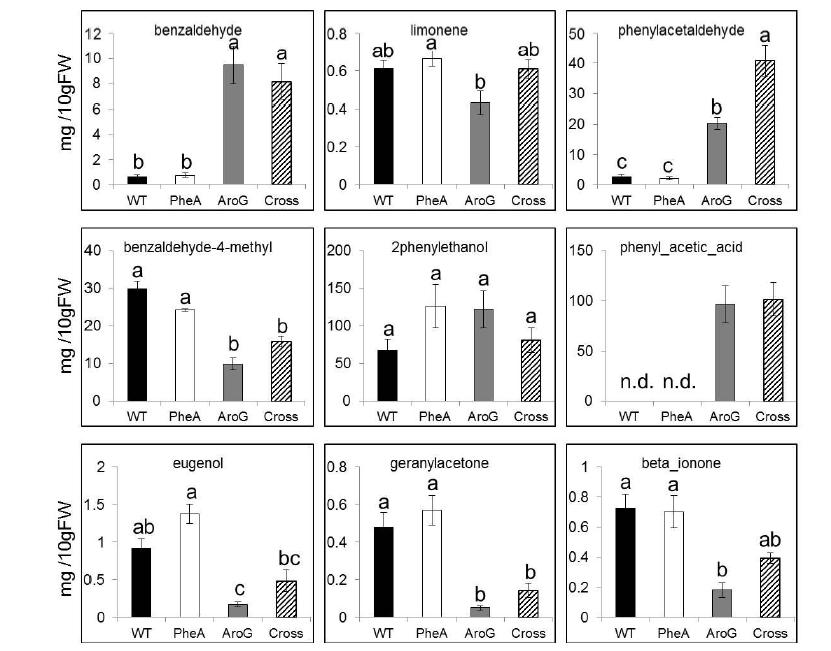
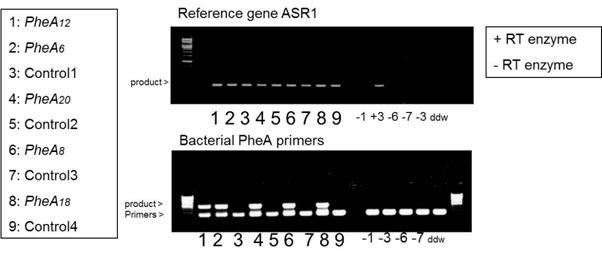
Figures(6)

Vered Tzin, Ilana Rogachev, Sagit Meir, Michal Moyal Ben Zvi, Tania Masci, Alexander Vainstein, Asaph Aharoni, Gad Galili. Altered Levels of Aroma and Volatiles by Metabolic Engineering of Shikimate Pathway Genes in Tomato Fruits[J]. AIMS Bioengineering, 2015, 2(2): 75-92. doi: 10.3934/bioeng.2015.2.75







 DownLoad:
DownLoad: