Citation: Kazushige Yokoyama, Christa D. Catalfamo, Minxuan Yuan. Reversible peptide oligomerization over nanoscale gold surfaces[J]. AIMS Biophysics, 2015, 2(4): 649-665. doi: 10.3934/biophy.2015.4.649

| [1] | Zahs KR, Ashe KH (2013) β-Amyloid oligomers in aging and Alzheimer's disease. Front Aging Neurosci 5: 28. |
| [2] | Ramamoorthy A, Lim MH (2013) Structural Characterization and Inhibition of Toxic Amyloid-β Oligomeric Intermediates. Biophys J 105: 287-288. |
| [3] | Pham JD, Chim N, Goulding CW, et al. (2013) Structures of Oligomers of a Peptide from β-Amyloid. J Am Chem Soc 135: 12460-12467. |
| [4] |
Hendrik H, Farmer BL, Pandey RB, et al. (2009) Nature of molecular interactions of peptides with gold, palladium, and Pd-Au bimetal surfaces in aqueous solution. J Am Chem Soc 131: 9704-9714. doi: 10.1021/ja900531f

|
| [5] | Nooren IM, Thornton JM (2003) Structural characterisation and functional significance of transient protein-protein interactions. J Mol Biol 325: 991-1018. |
| [6] | Nooren IM, Thornton JM (2003) Diversity of protein-protein interactions. EMBO J 14: 3486-3492. |
| [7] |
Goodsell DS, Olson AJ (1993) Soluble Proteins: Size, Shape and Function. Trends Biochem Sci 18: 65-68. doi: 10.1016/0968-0004(93)90153-E
|
| [8] | Long M, Betrán E, Thornton K, et al. (2003) The origin of new genes: glimpses from the young and old. Nat Rev Genet 4: 865-875. |
| [9] | Chothia C, Gough J, Vogel C, et al. (2003) Evolution of the protein repertoire. Science 300: 1701-1703. |
| [10] | Liu Y, Eisenberg D (2002) 3D domain swapping: as domains continue to swap. Protein Sci 11: 1285-1299. |
| [11] |
Gill S, Beck K (1965) Differential heat capacity calorimeter for polymer transition studies. Rev Sci Instrum 36: 274. doi: 10.1063/1.1719552
|
| [12] | Goodsell DS, Olson AJ (2000) Structural Symmetry and Protein Function. Annu Rev Biophys Biomol Struct 29: 105-153. |
| [13] |
Jones S, Thornton JM (1996) Principles of protein-protein interactions. Proc Natl Acad Sci U S A 93: 13-20. doi: 10.1073/pnas.93.1.13
|
| [14] |
Searle MS, Ciani B (2004) Design of β-sheet systems for understanding the thermodynamics and kinetics of protein folding. Curr Opin Struct Biol 14: 458-464. doi: 10.1016/j.sbi.2004.06.001
|
| [15] |
Snow CD, Nguyen H, Pande VS, et al. (2002) Absolute comparison of simulated and experimental protein-folding dynamics. Nature 420: 102-106. doi: 10.1038/nature01160
|
| [16] | Zagrovic B, Pande VS (2003) Structural correspondence between the alpha-helix... proteins can have native-like properties. Nat Struct Biol 10: 955-961. |
| [17] | Qiu L, Pabit SA, Roitberg AE, et al. (2002) Smaller and Faster: The 20-Residue Trp-Cage Protein Folds in 4 μs. J Am Chem Soc 124: 12952-12953. |
| [18] | Snow CD, Zagrovic B, Pande VS (2002) Folding kinetics and unfolded state topology via molecular dynamics simulations. J Am Chem Soc 124: 14548-14549. |
| [19] | Hartl FU, Hayer-Hartl M (2002) Molecular chaperones in the cytosol: from nascent chain to folded protein. Science 295: 1852-1858. |
| [20] | Dobson CM (2003) Protein folding and misfolding. Nature 426: 884-890. |
| [21] | Dobson CM ( 2004) Principles of protein folding, misfolding and aggregation. Semin Cell Dev Biol 15: 3-16. |
| [22] | Daggett V, Fersht A (2003) The present view of the mechanism of protein folding. Nat Rev Mol Cell Biol 4: 497-502. |
| [23] |
Shea J-E, Brooks CL, III (2001) From folding theories to folding proteins: a review and assessment of simulation studies of protein folding and unfolding. Annu Rev Phys Chem 52: 499-535. doi: 10.1146/annurev.physchem.52.1.499
|
| [24] | Saunders JA, Scheraga HA (2003) Ab initio structure prediction of two alpha-helical oligomers with a multiple-chain-united residue force field and global search. Biopolymers 68: 300-317. |
| [25] |
Zitzewitz JA, Bilsel O, Luo J, et al. (1995) Probing the folding mechanism of a leucine zipper peptide by stopped-flow circular dichroism spectroscopy. Biochemistry 34: 12812-12819. doi: 10.1021/bi00039a042
|
| [26] |
Dürr E, Jelesarov I, Bosshard HR (1999) Extremely fast folding of a very stable leucine zipper with a strengthened hydrophobic core and lacking electrostatic interactions between helices. Biochemistry 38: 870-880. doi: 10.1021/bi981891e
|
| [27] | Ibarra-Molero B, Makhatadze GI, Matthews CR (2001) Mapping the energy surface for the folding reaction of the coiled-coil peptide GCN4-p1 Biochemistry 40: 719-731. |
| [28] |
Zhu H, Celinski SA, Scholtz JM, et al. (2001) An engineered leucine zipper a position mutant with an unusual three-state unfolding pathway. Protein Sci 10: 24-33. doi: 10.1110/ps.30901
|
| [29] |
Wendt H, Leder L, Härmä H, et al. (1997) Very rapid, ionic strength-dependent association and folding of a heterodimeric leucine zipper. Biochemistry 36: 204-213. doi: 10.1021/bi961672y
|
| [30] |
Jang H, Hall CK, Zhou Y (2004) Thermodynamics and stability of a beta-sheet complex: molecular dynamics simulations on simplified off-lattice protein models. Protein Sci 13: 40-53. doi: 10.1110/ps.03162804
|
| [31] |
Dürr E, Jelesarov I (2000) Thermodynamic Analysis of Cavity Creating Mutations in an Engineered Leucine Zipper and Energetics of Glycerol-Induced Coiled Coil Stabilization. Biochemistry 39: 4472-4482. doi: 10.1021/bi992948f
|
| [32] |
Norde W (2008) My voyage of discovery to proteins in flatland and beyond. Colloids and Surfaces B: Biointerfaces 61: 1-9. doi: 10.1016/j.colsurfb.2007.09.029
|
| [33] | Sarkar B, Das AK, Maiti S (2013 ) Thermodynamically stable amyloid-β monomers have much lower membrane affinity than the small oligomers. Front Physiol 4: 84. |
| [34] | Zhu X, Yan D, Fang Y (2001) In situ FTIR spectroscopic study of the conformational change of isotactic polypropylene during the crystallization process. J Phys Chem B 105: 12461-12463. |
| [35] | Harper SM, Neil LC, Gardner KH (2003) Structural basis of a phototropin light switch. Science 301: 1541-1544. |
| [36] | Ohba S, Hosomi H, Ito Y (2001) In situ X-ray observation of pedal-like conformational change and dimerization of trans-cinnamamide in cocrystals with phthalic acid. J Am Chem Soc 123: 6349-6352. |
| [37] | Gupta R, Ahmad F (1999) Protein stability: functional dependence of denaturational gibbs energy on urea concentration. Biochemistry 38: 2471-2479. |
| [38] | Aisenbrey C, Borowik T, Bystrom R, et al. (2008) How is protein aggregation in amyloidogenic diseases modulated by biological membranes? Eur Biophys J 37: 247-255. |
| [39] | Lepère M, Chevallard C, Hernandez JF, et al. (2007) Multiscale surface self-assembly of an amyloid-like peptide. Langmuir 23: 8150-8155. |
| [40] | Kusumoto Y, Lomakin A, Teplow DB, et al. (1998) Temperature dependence of amyloid beta-protein fibrillization. Proc Natl Acad Sci U S A 95: 12277-12282. |
| [41] | Coles M, Bicknell W, Watson AA, et al. (1998) Solution structure of amyloid beta-peptide (1-40) in a water-micelle environment. Is the membrane spanning domain where we think it is?. Biochemistry 37: 11064-11077. |
| [42] | Shao HY, Jao SC, Ma K, et al. (1999) Solution structures of micelle-bound amylois beta-(1-40) and beta-(1-42) peptides of Alzhimer's disease. J Mol Biol 285: 755-773. |
| [43] | Giacomelli CE, Norde W (2005) Conformational changes of the amyloid beta-peptide (1-40) adsorbed on solid surfaces. Macromolecular Bioscience 5: 401-407. |
| [44] | Rocha S, Krastev R, Thunemann AF, et al. (2005) Adsorption of amyloid beta-peptide at polymer surfaces: a neutron reflectivity study. Chem Phys Chem 6: 2527-2534. |
| [45] | Kowalewski T, Holtzman DM (1999) In situ atomic force microscopy study of Alzheimer's beta-amyloid peptide on different substrates: new insights into mechanism of beta-sheet formation. Proc Natl Acad Sci U S A 96: 3688-3693. |
| [46] | Schladitz C, Vieira EP, Hermel H, et al. (1999) Amyloid-beta-sheet formation at the air-water interface. Biophys J 77: 3305-3310. |
| [47] | Rocha S, Thünemann AF, Pereira MC, et al. (2008) Influence of fluorinated and hydrogenated nanoparticles on the structure and fibrillogenesis of amyloid beta-peptide. Biophys Chem 137: 35-42. |
| [48] | Yokoyama K (2010) Nanoscale Surface Size Dependence in Protein Conjugation. In: Chen EJ, Peng N, editors. Advances in Nanotechnology: Nova Publisher, 65-104. |
| [49] | Yokoyama K (2011) Modeling of Reversible Protein Conjugation on Nanoscale Surface. In: Musa SM, editor. Computational Nanotechnology: Modeling and Applications with MATLAB: CRC Press-Taylor and Francis Group, LLC. |
| [50] | Yokoyama K (2012) Nano Size Dependent Properties of Colloidal Surfaces. In: Ray PC, editor. Colloids: Classification, Properties and Applications: Nova Science Publishing. |
| [51] | Yokoyama K (2010) Nanoscale Surface Size Dependence in Protein Conjugation In: Chen EJ, Peng N, editors. Advances in Nanotechnology: Nova Publisher, 65-104. |
| [52] | Yokoyama K (2011) Modeling of Reversible Protein Conjugation on Nanoscale Surface In: Musa SM, editor. Computational Nanotechnology: Modeling and Applications with MATLAB: CRC Press-Taylor and Francis Group, LLC. |
| [53] | Yokoyama K (2012) Nano Size Dependent Properties of Colloidal Surfaces In: Ray PC, editor. Colloids: Classification, Properties and Applications Nova Science Publishing. |
| [54] | Yokoyama K, Briglio NM, Sri Hartati D, et al. (2008) Nanoscale size dependence in the conjugation of amyloid beta and ovalbumin proteins on the surface of gold colloidal particles. Nanotechnology 19: 375101-375108. |
| [55] | Yokoyama K, Welchons DR (2007) The conjugation of amyloid beta protein on the gold colloidal nanoparticles' surfaces. Nanotechnology 18: 105101-105107. |
| [56] | Andrieux K, Couvreur P (2013) Nanomedicine as a promising approach for the treatment and diagnosis of brain diseases: the example of Alzheimer's disease. Ann Pharm Fr 71: 225-233. |
| [57] |
Politi J, Spadavecchia J, Iodice M, et al. (2015) Oligopeptide-heavy metal interaction monitoring by hybrid gold nanoparticle based assay. Analyst 140: 149-155. doi: 10.1039/C4AN01491J
|
| [58] | Yokoyama K (2011) Modeling of Reversible Protein Conjugation on Nanoscale Surface In: Musa SM, editor. Computational Nanotechnology: Modeling and Applications with MATLAB: CRC Press, 381-409. |
| [59] | Yokoyama K (2012) Nano Size Dependent Properties of Colloidal Surfaces. In: Ray PC, editor. Colloids: Classification, Properties and Applications: Nova Publishers, 25-58 |
| [60] | Yokoyama K (2013) Controlling Reversible Self Assembly Path of Amyloid Beta Peptide over Gold Colloidal nanoparticle’s Surface. In: Musa SM, editor. Nanoscale Spectroscopy with Applications CRC Press-Taylor and Francis Group, LLC, 279-304. |
| [61] | Link S, El-Sayed M (1999) Spectral properties and relaxation dynamics of surface plasmon electronic oscillations in gold and silver nanodots and nanorods J Phys Chem B 103: 8410-8426. |
| [62] | Kelly KL, Coronado E, Zhao LL, et al. (2003) The optical properties of metal nanoparticles: the influence of size, shape, and dielectric environment J Phys Chem B 10:7 668-677. |
| [63] | Jensen TR, Schatz GC, Van Duyne RP (1999) Nanosphere lithography: surface plasmon resonance spectrum of a periodic array of silver nanoparticles by ultraviolet-visible extinction spectroscopy and electrodynamic modeling. J Phys Chem B 103: 2394-2401. |
| [64] | Ackermann T (1969) The calorimeters: adiabatic calorimeters; Brown HD, Ed., editor. New York: Academic Press. |
| [65] | Barrow CJ, Yasuda A, Kenny PT, et al. (1992) Solution conformations and aggregational properties of synthetic amyloid beta-peptides of Alzheimer's disease. Analysis of circular dichroism spectra. J Mol Biol 225: 1075-1093. |
| [66] | Wood SJ, Maleeff B, Hart T, et al. (1996) Physical, morphological and functional differences between pH 5.8 and 7.4 aggregates of the Alzheimer's amyloid peptide Abeta. J Mol Biol 256: 870-877. |
| [67] | Jang S, Shin S (2008) Computational study on the structural diversity of amyloid beta-peptide (Aβ10-35) oligomers. J Phys Chem B 112: 3479-3484. |
| [68] | Nichols MR, Moss MA, Reed DK, et al. (2005) Amyloid-beta aggregates formed at polar-nonpolar interfaces differ from amyloid-beta protofibrils produced in aqueous buffers. Microsc Res Tech 67: 164-174. |
| [69] |
Bucciantini M, Giannoni E, Chiti F, et al. (2002) Inherent toxicity of aggregates implies a common mechanism for protein misfolding diseases. Nature 416: 507-511. doi: 10.1038/416507a
|
| [70] |
Brovchenko I, Burri RR, Krukau A, et al. (2009) Thermal expansivity of amyloid β16-22 peptides and their aggregates in water. Phys Chem Chem Phys 11 11: 5035-5040. doi: 10.1039/b820340g
|
| [71] | Melquiond A, Dong X, Mousseau N, et al. (2008) Role of the region 23-28 in Abeta fibril formation. Curr Alzheimer Res 5: 244-250. |
| [72] | Meier M, Seelig J (2008) Length dependence of the coil - β-sheet transition in a membrane environement. J Am Chem Soc 130: 1017-1024. |
| [73] |
Yokoyama K, Gaulin NB, Cho H, et al. (2010) Temperature Dependence of Conjugation of Amyloid Beta Peptide on the Gold Colloidal Nanoparticles. J Phys Chem A 114: 1521-1528. doi: 10.1021/jp907880f
|
| [74] |
Sabate R, Estelrich J (2003) Pinacyanol as effective probe of fibrillar beta-amyloid peptide; Comparative study with Congo Red. Biopolymers 72: 455-463. doi: 10.1002/bip.10485
|
| [75] | Carrotta R, Manno M, Bulone D, et al. (2005) Protofibril formation of amyloid beta-protein at low pH via a non-cooperative elongation mechanism. J Biol Chem 280: 30001-30008. |
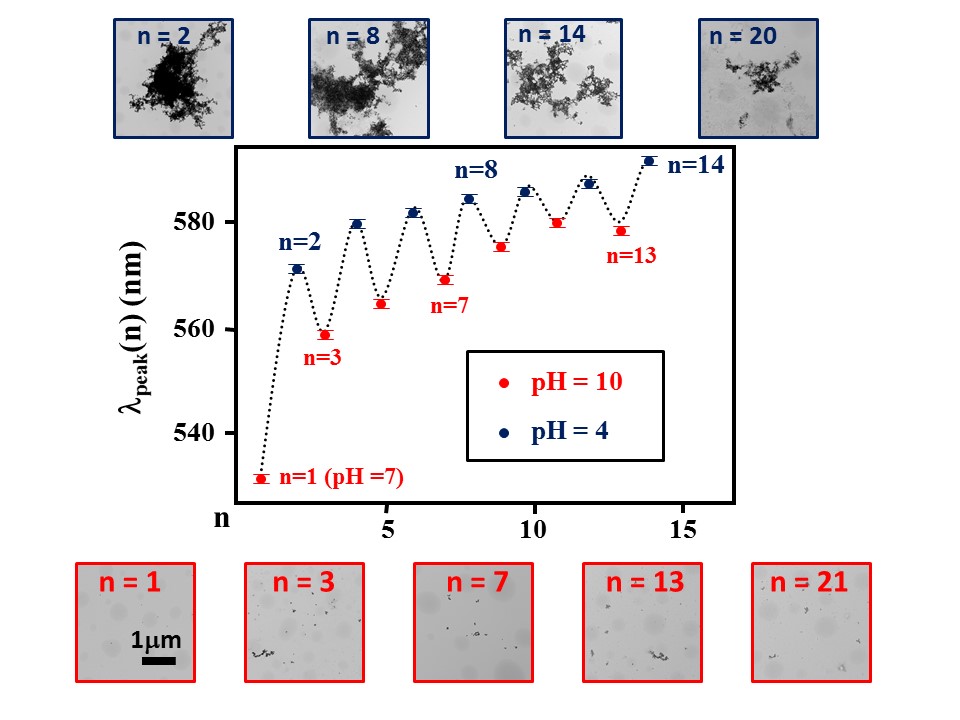
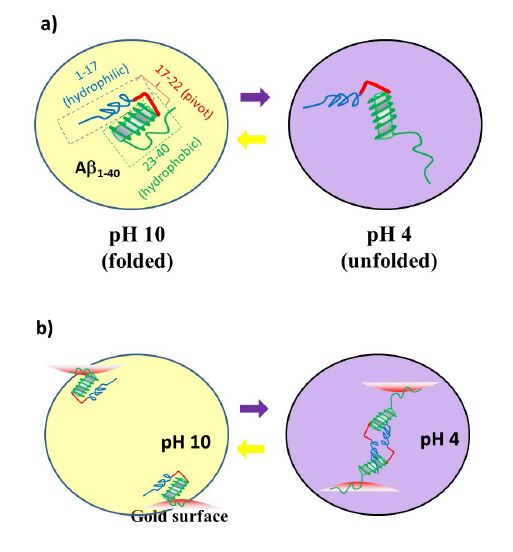
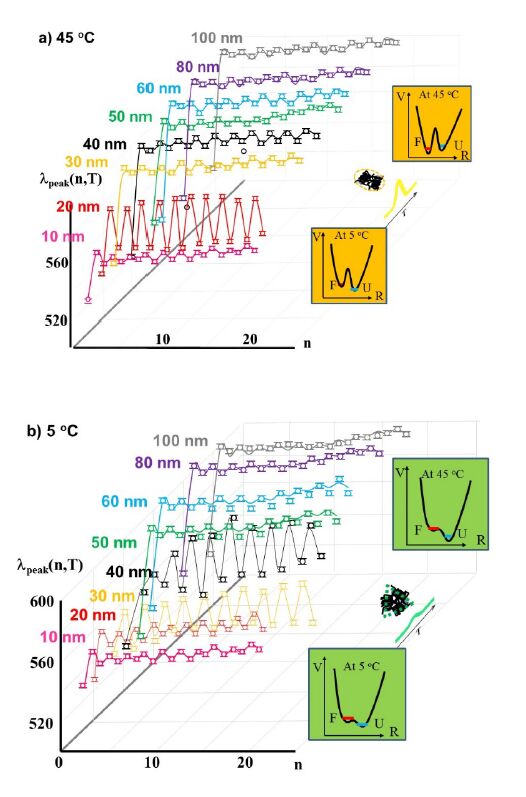
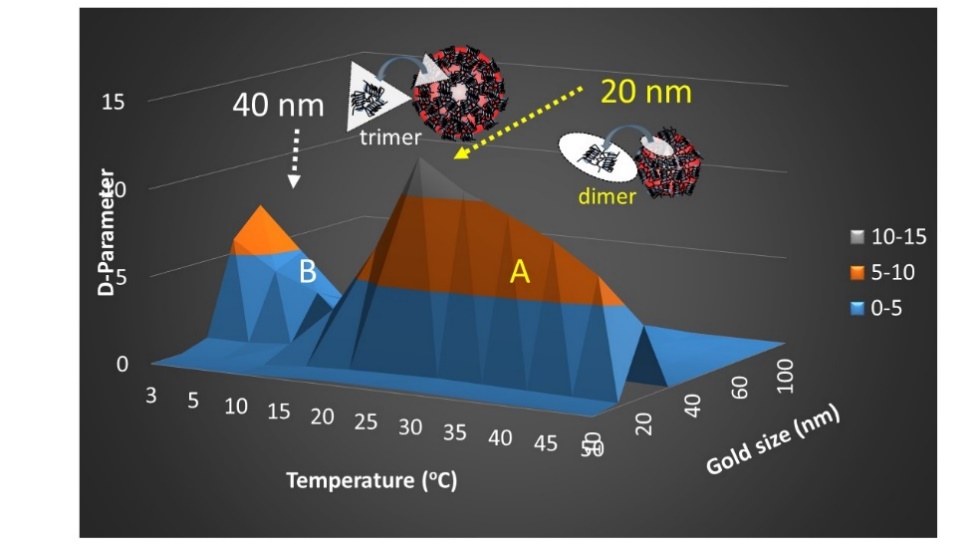
Figures(8) / Tables(1)

Kazushige Yokoyama, Christa D. Catalfamo, Minxuan Yuan. Reversible peptide oligomerization over nanoscale gold surfaces[J]. AIMS Biophysics, 2015, 2(4): 649-665. doi: 10.3934/biophy.2015.4.649







 DownLoad:
DownLoad: