Citation: Wei Xue, Pengcheng Wan, Qiao Li, Ping Zhong, Gaohang Yu, Tao Tao. An online conjugate gradient algorithm for large-scale data analysis in machine learning[J]. AIMS Mathematics, 2021, 6(2): 1515-1537. doi: 10.3934/math.2021092

| [1] |
J. Barzilai, J. M. Borwein, Two-point step size gradient methods, IMA J. Numer. Anal., 8 (1988), 141-148. doi: 10.1093/imanum/8.1.141

|
| [2] | E. Bisong, Batch vs. online larning, Building Machine Learning and Deep Learning Models on Google Cloud Platform, 2019. |
| [3] |
L. Bottou, F. E. Curtis, J. Nocedal, Optimization methods for large-scale machine learning, SIAM Rev., 60 (2018), 223-311. doi: 10.1137/16M1080173
|
| [4] | Y. H. Dai, Y. Yuan, Nonlinear conjugate gradient methods, Shanghai: Shanghai Scientific Technical Publishers, 2000. |
| [5] |
D. Davis, B. Grimmer, Proximally guided stochastic subgradient method for nonsmooth, nonconvex problems, SIAM J. Optim., 29 (2019), 1908-1930. doi: 10.1137/17M1151031
|
| [6] |
R. Dehghani, N. Bidabadi, H. Fahs, M. M. Hosseini, A conjugate gradient method based on a modified secant relation for unconstrained optimization, Numer. Funct. Anal. Optim., 41 (2020), 621-634. doi: 10.1080/01630563.2019.1669641
|
| [7] |
P. Faramarzi, K. Amini, A modified spectral conjugate gradient method with global convergence, J. Optim. Theory Appl., 182 (2019), 667-690. doi: 10.1007/s10957-019-01527-6
|
| [8] |
R. Fletcher, C. M. Reeves, Function minimization by conjugate gradients, Comput. J., 7 (1964), 149-154. doi: 10.1093/comjnl/7.2.149
|
| [9] |
J. C. Gilbert, J. Nocedal, Global convergence properties of conjugate gradient methods for optimization, SIAM J. Optim., 2 (1992), 21-42. doi: 10.1137/0802003
|
| [10] |
W. W. Hager, H. Zhang, Algorithm 851: CG DESCENT, a conjugate gradient method with guaranteed descent, ACM Trans. Math. Software, 32 (2006), 113-137. doi: 10.1145/1132973.1132979
|
| [11] |
A. S. Halilu, M. Y. Waziri, Y. B. Musa, Inexact double step length method for solving systems of nonlinear equations, Stat. Optim. Inf. Comput., 8 (2020), 165-174. doi: 10.19139/soic-2310-5070-532
|
| [12] |
H. Jiang, P. Wilford, A stochastic conjugate gradient method for the approximation of functions, J. Comput. Appl. Math., 236 (2012), 2529-2544. doi: 10.1016/j.cam.2011.12.012
|
| [13] |
X. Jiang, J. Jian, Improved Fletcher-Reeves and Dai-Yuan conjugate gradient methods with the strong Wolfe line search, J. Comput. Appl. Math., 348 (2019), 525-534. doi: 10.1016/j.cam.2018.09.012
|
| [14] | X. B. Jin, X. Y. Zhang, K. Huang, G. G. Geng, Stochastic conjugate gradient algorithm with variance reduction, IEEE Trans. Neural Networks Learn. Syst., 30 (2018), 1360-1369. |
| [15] | R. Johnson, T. Zhang, Accelerating stochastic gradient descent using predictive variance reduction, Advances in Neural Information Processing Systems, 2013. |
| [16] |
X. L. Li, Preconditioned stochastic gradient descent, IEEE Trans. Neural Networks Learn. Syst., 29 (2018), 1454-1466. doi: 10.1109/TNNLS.2017.2672978
|
| [17] |
Y. Liu, X. Wang, T. Guo, A linearly convergent stochastic recursive gradient method for convex optimization, Optim. Lett., 2020. Doi: 10.1007/s11590-020-01550-x. doi: 10.1007/s11590-020-01550-x
|
| [18] |
M. Lotfi, S. M. Hosseini, An efficient Dai-Liao type conjugate gradient method by reformulating the CG parameter in the search direction equation, J. Comput. Appl. Math., 371 (2020), 112708. doi: 10.1016/j.cam.2019.112708
|
| [19] | S. Mandt, M. D. Hoffman, D. M. Blei, Stochastic gradient descent as approximate Bayesian inference, J. Mach. Learn. Res., 18 (2017), 4873-4907. |
| [20] | P. Moritz, R. Nishihara, M. I. Jordan, A linearly-convergent stochastic L-BFGS algorithm, Proceedings of the 19th International Conference on Artificial Intelligence and Statistics, 2016. |
| [21] | L. M. Nguyen, J. Liu, K. Scheinberg, M. Takáč, SARAH: A novel method for machine learning problems using stochastic recursive gradient, Proceedings of the 34th International Conference on Machine Learning, 2017. |
| [22] | A. Nitanda, Accelerated stochastic gradient descent for minimizing finite sums, Proceedings of the 19th International Conference on Artificial Intelligence and Statistics, 2016. |
| [23] |
H. Robbins, S. Monro, A stochastic approximation method, Ann. Math. Statist., 22 (1951), 400-407. doi: 10.1214/aoms/1177729586
|
| [24] | N. N. Schraudolph, T. Graepel, Combining conjugate direction methods with stochastic approximation of gradients, Proceedings of the 9th International Workshop on Artificial Intelligence and Statistics, 2003. |
| [25] | G. Shao, W. Xue, G. Yu, X. Zheng, Improved SVRG for finite sum structure optimization with application to binary classification, J. Ind. Manage. Optim., 16 (2020), 2253-2266. |
| [26] | C. Tan, S. Ma, Y. H. Dai, Y. Qian, Barzilai-Borwein step size for stochastic gradient descent, Advances in Neural Information Processing Systems, 2016. |
| [27] | P. Toulis, E. Airoldi, J. Rennie, Statistical analysis of stochastic gradient methods for generalized linear models, Proceedings of the 31th International Conference on Machine Learning, 2014. |
| [28] | V. Vapnik, The nature of statistical learning theory, New York: Springer, 1995. |
| [29] |
L. Xiao, T. Zhang, A proximal stochastic gradient method with progressive variance reduction, SIAM J. Optim., 24 (2014), 2057-2075. doi: 10.1137/140961791
|
| [30] | Z. Xu, Y. H. Dai, A stochastic approximation frame algorithm with adaptive directions, Numer. Math. Theory Methods Appl., 1 (2008), 460-474. |
| [31] | W. Xue, J. Ren, X. Zheng, Z. Liu, Y. Ling, A new DY conjugate gradient method and applications to image denoising, IEICE Trans. Inf. Syst., 101 (2018), 2984-2990. |
| [32] |
Q. Zheng, X. Tian, N. Jiang, M. Yang, Layer-wise learning based stochastic gradient descent method for the optimization of deep convolutional neural network, J. Intell. Fuzzy Syst., 37 (2019), 5641-5654. doi: 10.3233/JIFS-190861
|


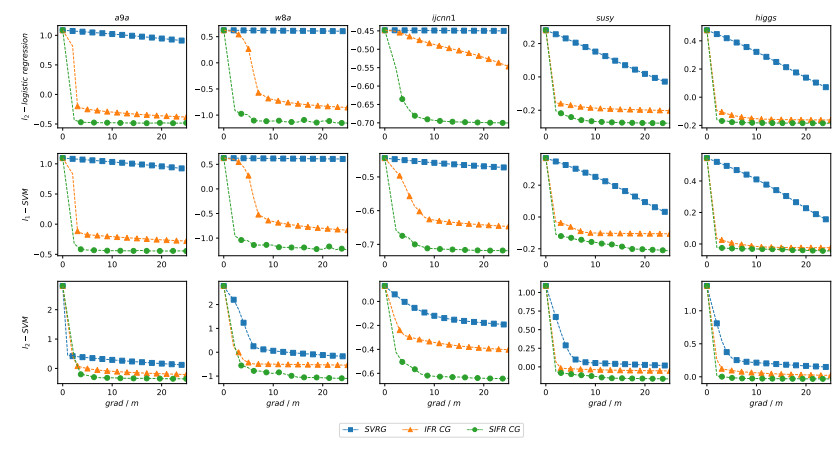
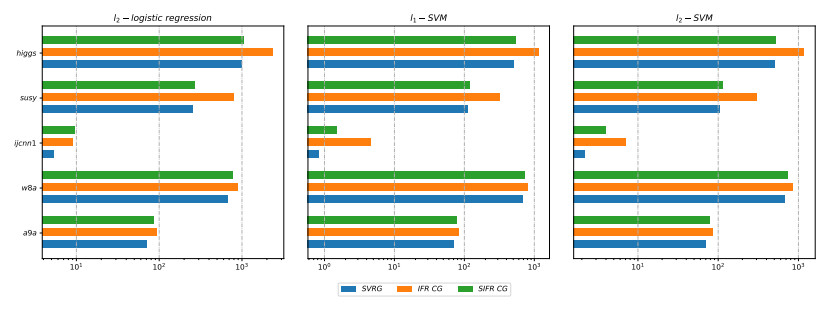
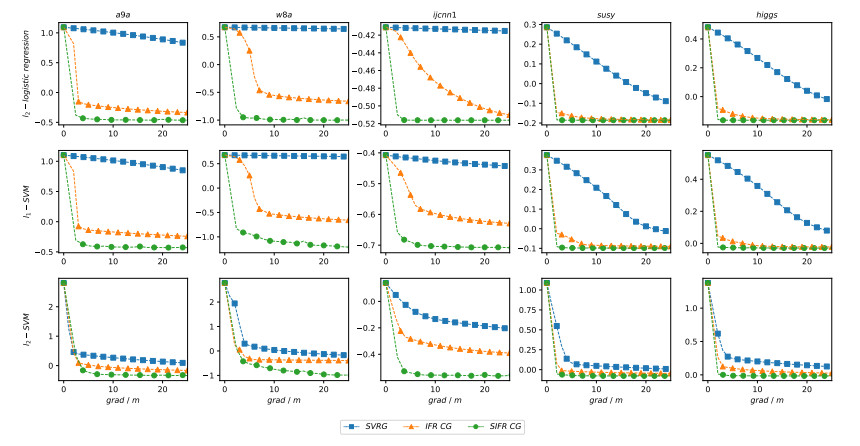

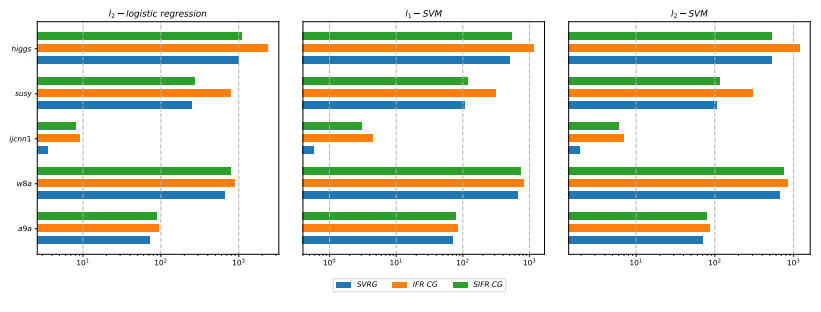
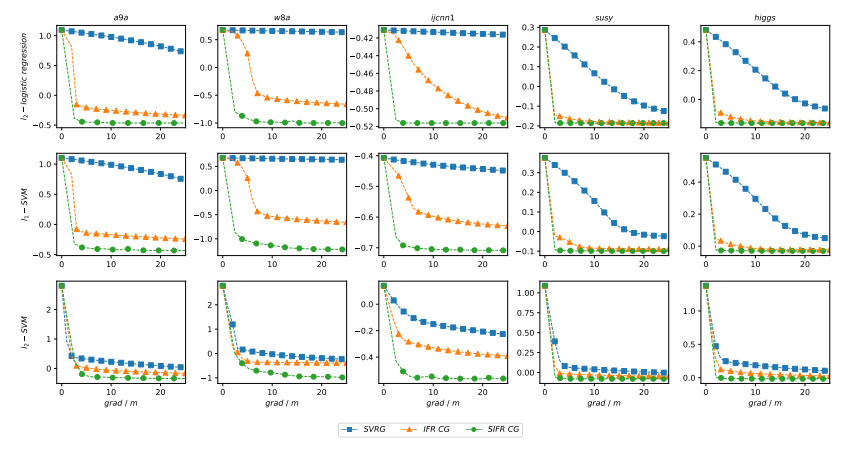

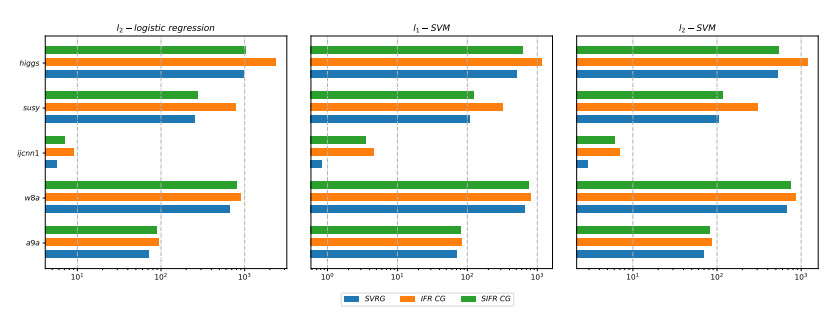
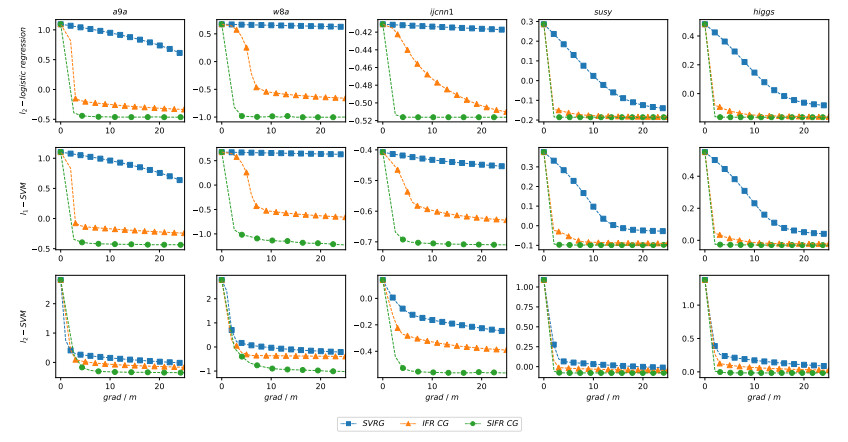
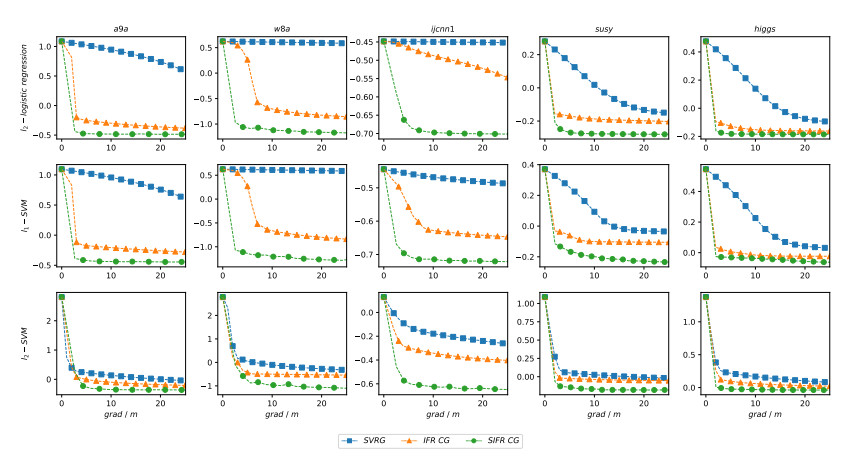
Figures(17) / Tables(3)

Wei Xue, Pengcheng Wan, Qiao Li, Ping Zhong, Gaohang Yu, Tao Tao. An online conjugate gradient algorithm for large-scale data analysis in machine learning[J]. AIMS Mathematics, 2021, 6(2): 1515-1537. doi: 10.3934/math.2021092







 DownLoad:
DownLoad: