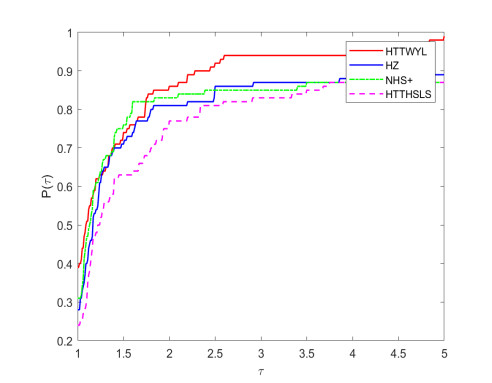
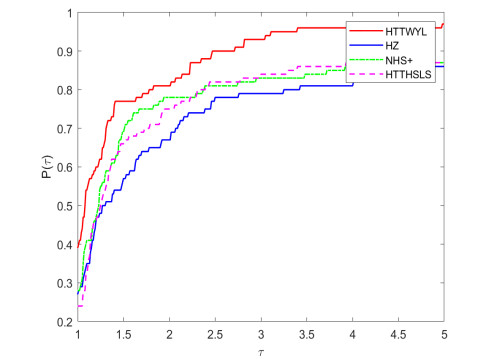
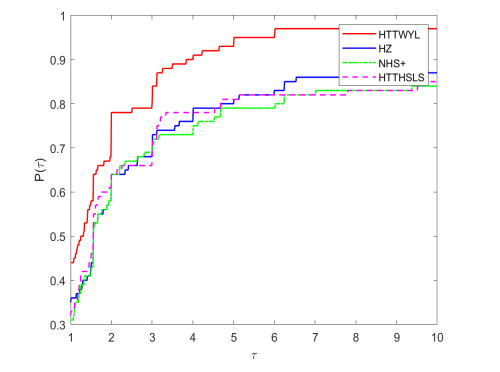
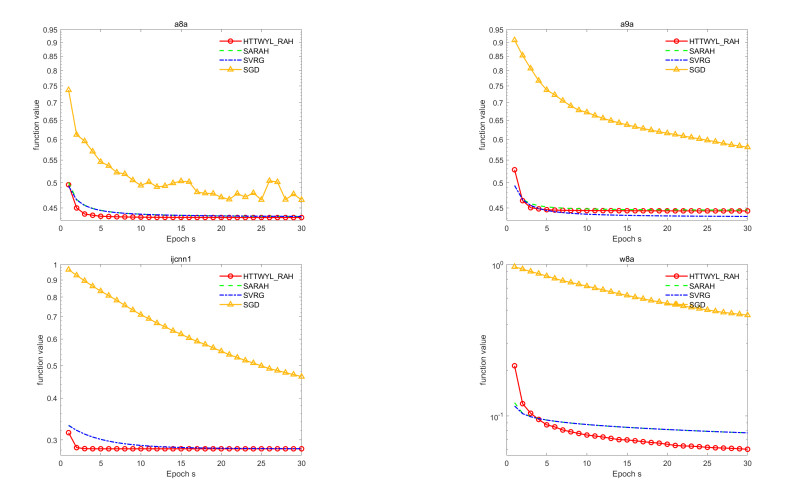
A new hybrid conjugate gradient algorithm for solving the unconstrained optimization problem was presented. The algorithm could be considered as a modification of the memoryless Broyden-Fletcher-Goldfarb-Shanno (BFGS) quasi-Newton method. Based on a normalized gradient difference, we introduced a new combining conjugate gradient direction close to the direction of the memoryless BFGS quasi-Newton direction. It was shown that the search direction satisfied the sufficient descent property independent of the line search. For general nonlinear functions, the global convergence of the algorithm was proved under standard assumptions. Numerical experiments indicated a potential performance of the new algorithm, especially for solving the large-scale problems. In addition, the proposed method was used in practical application problems for image restoration and machine learning.
Citation: Xiyuan Zhang, Yueting Yang. A new hybrid conjugate gradient method close to the memoryless BFGS quasi-Newton method and its application in image restoration and machine learning[J]. AIMS Mathematics, 2024, 9(10): 27535-27556. doi: 10.3934/math.20241337
A new hybrid conjugate gradient algorithm for solving the unconstrained optimization problem was presented. The algorithm could be considered as a modification of the memoryless Broyden-Fletcher-Goldfarb-Shanno (BFGS) quasi-Newton method. Based on a normalized gradient difference, we introduced a new combining conjugate gradient direction close to the direction of the memoryless BFGS quasi-Newton direction. It was shown that the search direction satisfied the sufficient descent property independent of the line search. For general nonlinear functions, the global convergence of the algorithm was proved under standard assumptions. Numerical experiments indicated a potential performance of the new algorithm, especially for solving the large-scale problems. In addition, the proposed method was used in practical application problems for image restoration and machine learning.

| [1] |
H. Adeli, S. L. Hung, An adaptive conjugate gradient learning algorithm for efficient training of neural networks, Appl. Math. Comput., 62 (1994), 82–102. https://doi.org/10.1016/0096-3003(94)90134-1 doi: 10.1016/0096-3003(94)90134-1

|
| [2] |
S. Rong, W. X. Li, Z. M. Li, Y. Sun, T. Y. Zheng, Optimal allocation of Thermal-Electric decoupling systems based on the national economy by an improved conjugate gradient method, Energies., 9 (2015), 17. https://doi.org/10.3390/en9010017 doi: 10.3390/en9010017
|
| [3] |
C. Decker, D. M. Falcao, E. Kaszkurewicz, Conjugate gradient methods for power system dynamic simulation on parallel computers, EEE Trans. Power Syst., 11 (1996), 1218–1227. https://doi.org/10.1109/59.535593 doi: 10.1109/59.535593
|
| [4] |
P. Vivek, B. Addisu, M. G. A. Sayeed, J. K. Nand, K. S. Gyanendra, An application of conjugate gradient technique for determination of thermal conductivity as an inverse engineering problems, Mater. Today Proc., 47 (2021), 3082–3087. https://doi.org/10.1016/j.matpr.2021.06.073 doi: 10.1016/j.matpr.2021.06.073
|
| [5] |
Z. C. Liu, S. P. Zhu, Y. Ge, F. Shan, L. P. Zeng, W. Liu, Geometry optimization of two-stage thermoelectric generators using simplified conjugate-gradient method, Appl. Energ., 190 (2017), 540–552. https://doi.org/10.1016/j.apenergy.2017.01.002 doi: 10.1016/j.apenergy.2017.01.002
|
| [6] |
R. Fletcher, C. Reeves, Function minimization by conjugate gradierent, Comput. J., 7 (1964), 149–154. https://doi.org/10.1093/comjnl/7.2.149 doi: 10.1093/comjnl/7.2.149
|
| [7] |
E. Polak, G. Ribière, Note sur la convergence methodes de direction conjugées, Math. Model. Numer. Anal., 3 (1969), 35–43. https://doi.org/10.1051/M2AN/196903R100351 doi: 10.1051/M2AN/196903R100351
|
| [8] |
B. T. Polyak, The conjugate gradient method in extreme problems, USSR Comput. Math. Math. Phys., 9 (1969), 94–112. https://doi.org/10.1016/0041-5553(69)90035-4 doi: 10.1016/0041-5553(69)90035-4
|
| [9] | M. R. Hestenes, E. Stiefel, Method of conjugate gradient for solving linear equations, Res. Nat. Bur. Stand., 49 (1952), 409–436. |
| [10] |
Y. Dai, Y. Yuan. A nonlinear conjugate gradient with a strong global convergence properties, SIAM. Optim., 10 (2000), 177–182. https://doi.org/10.1137/S1052623497318992 doi: 10.1137/S1052623497318992
|
| [11] |
Y. Liu, C. Storey. Efficient generalized conjugate gradient algorithms, part 1: Theory, J. Optim. Theory Appl., 69 (1991), 129–137. https://doi.org/10.1007/BF00940464 doi: 10.1007/BF00940464
|
| [12] |
L. Zhang, An improved Wei-Yao-Liu nonlinear conjugate gradient method for optimization computation, Appl. Math. Comput., 215 (2009), 2269–2274. https://doi.org/10.1016/j.amc.2009.08.016 doi: 10.1016/j.amc.2009.08.016
|
| [13] |
H. Huang, S. H. Lin, A modified Wei-Yao-Liu conjugate gradient method for unconstrained optimization, Appl. Math. Comput., 231 (2014), 179–186. https://doi.org/10.1016/j.amc.2014.01.012 doi: 10.1016/j.amc.2014.01.012
|
| [14] |
Y. P. Hu, Z. X. Wei, Wei-Yao-Liu conjugate gradient projection algorithm for nonlinear monotone equations with convex constraints, J. Comput. Math., 92 (2014), 2261–2272. https://doi.org/10.1080/00207160.2014.977879 doi: 10.1080/00207160.2014.977879
|
| [15] |
M. Li, A modified Hestense-Stiefel conjugate gradient method close to the memoryless BFGS quasi-Newton method, Optim. Methods Softw., 22 (2018), 336–353. https://doi.org/10.1080/10556788.2017.1325885 doi: 10.1080/10556788.2017.1325885
|
| [16] | S. W. Yao, B. Qin, A hybrid of DL and WYL nonlinear conjugate gradient methods, Abstr. Appl. Anal., 2014, 279891. http://dx.doi.org/10.1155/2014/279891 |
| [17] |
P. Kumam, A. B. Abubakar, M. Malik, A. H. Ibrahim, A hybrid HS-LS conjugate gradient algorithm for unconstrained optimization with applications in motion control and image recovery, J. Comput. Appl. Math., 433 (2023), 115304. https://doi.org/10.1016/j.cam.2023.115304 doi: 10.1016/j.cam.2023.115304
|
| [18] |
Z. X. Wei, S. W. Yao, L. Y. Liu, The convergence properties of some new conjugate gradient methods, Appl. Math. Comput., 183 (2006), 1341–1350. https://doi.org/10.1016/j.amc.2006.05.150 doi: 10.1016/j.amc.2006.05.150
|
| [19] |
H. Huang, Z. X. Wei, S. W. Yao, The proof of the sufficient descent condition of the Wei-Yao-Liu conjugate gradient method under the strong Wolfe-Powell line search, Appl. Math. Comput., 189 (2007), 1241–1245. https://doi.org/10.1016/j.amc.2006.12.006 doi: 10.1016/j.amc.2006.12.006
|
| [20] |
J. Nocedal, Updating quasi-Newton matrices with limited storage, Math. Comp., 35 (1980), 773–782. https://doi.org/10.1090/S0025-5718-1980-0572855-7 doi: 10.1090/S0025-5718-1980-0572855-7
|
| [21] |
D. Luo, Y. Li, J. Y. Lu, G. L. Yuan, A conjugate gradient algorithm based on double parameter scaled Broyden-Fletcher-Goldfarb-Shanno update for optimization problems and image restoration, Neural Comput. Appl., 34 (2022), 535–553. https://doi.org/10.1007/s00521-021-06383-y doi: 10.1007/s00521-021-06383-y
|
| [22] |
X. Z. Jiang, X. M. Ye, Z. F. Huang, M. X. Liu, A family of hybrid conjugate gradient method with restart procedure for unconstrained optimizations and image restorations, Comput. Oper. Res., 159 (2023), 106341. https://doi.org/10.1016/j.cor.2023.106341 doi: 10.1016/j.cor.2023.106341
|
| [23] |
X. Z. Jiang, L. G. Pan, M. X. Liu, J. B. Jian, A family of spectral conjugate gradient methods with strong convergence and its applications in image restoration and machine learning, J. Franklin Inst., 361 (2024), 107033. https://doi.org/10.1016/j.jfranklin.2024.107033 doi: 10.1016/j.jfranklin.2024.107033
|
| [24] |
G. L. Yuan, T. T. Li, W. J. Hu, A conjugate gradient algorithm for large scale nonlinear equations and image restoration problems, Appl. Numer. Math., 147 (2020), 129–141. https://doi.org/10.1016/j.apnum.2019.08.022 doi: 10.1016/j.apnum.2019.08.022
|
| [25] |
G. L. Yuan, J. Y. Lu, Z. Wang, The PRP conjugate gradient algorithm with a modified WWP line search and its application in the image restoration problems, Appl. Numer. Math., 152 (2020), 1–11. https://doi.org/10.1016/j.apnum.2020.01.019 doi: 10.1016/j.apnum.2020.01.019
|
| [26] |
J. H. Yin, J. B. Jian, X. Z. Jiang, A generalized hybrid CGPM-based algorithm for solving large-scale convex constrained equations with applications to image restoration, J. Comput. Appl. Math., 391 (2021), 113–423. https://doi.org/10.1016/j.cam.2021.113423 doi: 10.1016/j.cam.2021.113423
|
| [27] |
J. Y. Cao, J. Z. Wu, A conjugate gradient algorithm and its applications in image restoration, Appl. Math. Comput., 183 (2020), 243–252. https://doi.org/10.1016/j.apnum.2019.12.002 doi: 10.1016/j.apnum.2019.12.002
|
| [28] |
W. W. Hager, H. C. Zhang, A survey of nonlinear conjugate gradient methods, Pacific J. Optim., 2 (2006), 35–58. https://doi.org/10.1006/jsco.1995.1040 doi: 10.1006/jsco.1995.1040
|
| [29] |
N. I. M. Gould, D. Orban, P. L. Toint, CUTEr and SifDec: A constrained and unconstrained testing environment, ACM Trans. Math. Soft., 29 (2003), 373–394. https://doi.org/10.1145/962437.962439 doi: 10.1145/962437.962439
|
| [30] | N. Andrei, An unconstrained optimization test functions collection, Adv. Model. Optim., 10 (2008), 147–161. |
| [31] |
J. J. Moré, B. S. Garbow, K. E. Hillstrom, Testing unconstrained optimization software, ACM Trans. Math. Software., 7 (1981), 17–41. https://doi.org/10.1145/355934.35593 doi: 10.1145/355934.35593
|
| [32] |
E. D. Dolan, J. J. More, Benchmarking optimization software with performance profiles, Math. Program., 91 (2002), 201–213. https://doi.org/10.1007/s101070100263 doi: 10.1007/s101070100263
|
| [33] | J. F. Cai, R. Chan, B. Morini, Minimization of an edge-preserving regularization functional by conjugate gradient type methods, Image Proc. Based Part. Diff. Equat., 2007,109–122. https://doi.org/10.1007/978-3-540-33267-1 |
| [34] |
H. Hwang, R. A. Haddad, Adaptive median filters: New algorithms and results, IEEE Trans. Image Process., 4 (1995), 499–502. https://doi.org/10.1109/83.370679 doi: 10.1109/83.370679
|
| [35] | A. Bovik, Handbook of image and video processing, Academic Press, San Diego., 2005, https://doi.org/10.1016/B978-0-12-119792-6.X5062-1 |
| [36] | L. M. Nguyen, J. Liu, K. Scheinberg, M. Takáč, SARAH: A novel method for machine learning problems using stochastic recursive gradient, Int. Conf. Mach. Lear., 2017, 2613–2621. https://doi.org/10.48550/arXiv.1703.00102 |
| [37] | R. Johnson, T. Zhang, Accelerating stochastic gradient descent using predictive variance reduction, Adv. Neural Inf. Process. Syst., 2013,315–323. |
| [38] |
L. Bottou, Large-scale machine learning with stochastic gradient descent, Proc. COMPSTAT., 12 (2010), 177–186. https://doi.org/10.1007/978-3-7908-2604-3_16 doi: 10.1007/978-3-7908-2604-3_16
|


Figures(6) / Tables(4)

Xiyuan Zhang, Yueting Yang. A new hybrid conjugate gradient method close to the memoryless BFGS quasi-Newton method and its application in image restoration and machine learning[J]. AIMS Mathematics, 2024, 9(10): 27535-27556. doi: 10.3934/math.20241337







 DownLoad:
DownLoad: