Agent-based negotiation aims at automating the negotiation process on behalf of humans to save time and effort. While successful, the current research considers communication between negotiation agents through offer exchange. In addition to the simple manner, many real-world settings tend to involve linguistic channels with which negotiators can express intentions, ask questions, and discuss plans. The information bandwidth of traditional negotiation is therefore restricted and grounded in the action space. Against this background, a negotiation agent called MCAN (multiple channel automated negotiation) is described that models the negotiation with multiple communication channels problem as a Markov decision problem with a hybrid action space. The agent employs a novel deep reinforcement learning technique to generate an efficient strategy, which can interact with different opponents, i.e., other negotiation agents or human players. Specifically, the agent leverages parametrized deep Q-networks (P-DQNs) that provides solutions for a hybrid discrete-continuous action space, thereby learning a comprehensive negotiation strategy that integrates linguistic communication skills and bidding strategies. The extensive experimental results show that the MCAN agent outperforms other agents as well as human players in terms of averaged utility. A high human perception evaluation is also reported based on a user study. Moreover, a comparative experiment shows how the P-DQNs algorithm promotes the performance of the MCAN agent.
Citation: Siqi Chen, Ran Su. An autonomous agent for negotiation with multiple communication channels using parametrized deep Q-network[J]. Mathematical Biosciences and Engineering, 2022, 19(8): 7933-7951. doi: 10.3934/mbe.2022371
Agent-based negotiation aims at automating the negotiation process on behalf of humans to save time and effort. While successful, the current research considers communication between negotiation agents through offer exchange. In addition to the simple manner, many real-world settings tend to involve linguistic channels with which negotiators can express intentions, ask questions, and discuss plans. The information bandwidth of traditional negotiation is therefore restricted and grounded in the action space. Against this background, a negotiation agent called MCAN (multiple channel automated negotiation) is described that models the negotiation with multiple communication channels problem as a Markov decision problem with a hybrid action space. The agent employs a novel deep reinforcement learning technique to generate an efficient strategy, which can interact with different opponents, i.e., other negotiation agents or human players. Specifically, the agent leverages parametrized deep Q-networks (P-DQNs) that provides solutions for a hybrid discrete-continuous action space, thereby learning a comprehensive negotiation strategy that integrates linguistic communication skills and bidding strategies. The extensive experimental results show that the MCAN agent outperforms other agents as well as human players in terms of averaged utility. A high human perception evaluation is also reported based on a user study. Moreover, a comparative experiment shows how the P-DQNs algorithm promotes the performance of the MCAN agent.

| [1] | X. Gao, S. Chen, Y. Zheng, J. Hao, A deep reinforcement learning-based agent for negotiation with multiple communication channels, in 2021 IEEE 33nd International Conference on Tools with Artificial Intelligence (ICTAI), IEEE, (2021), 868–872. https://doi.org/10.1109/ICTAI52525.2021.00139 |
| [2] | M. Oudah, T. Rahwan, T. Crandall, J. Crandall, How AI wins friends and influences people in repeated games with cheap talk, in Proceedings of the AAAI Conference on Artificial Intelligence, (2018). |
| [3] |
N. R. Jennings, P. Faratin, A. R. Lomuscio, S. Parsons, C. Sierra, M. Wooldridge, Automated negotiation: Prospects, methods and challenges, Int. J. Group Decis. Negot., 10 (2001), 199–215. https://doi.org/10.1023/A:1008746126376 doi: 10.1023/A:1008746126376

|
| [4] | S. Chen, Y. Cui, C. Shang, J. Hao, G. Weiss, ONECG: Online negotiation environment for coalitional games, in Proceedings of the 18th International Conference on Autonomous Agents and MultiAgent Systems, AAMAS '19, Montreal, QC, Canada, May 13-17, 2019, (2019), 2348–2350. |
| [5] |
S. Chen and G. Weiss, An approach to complex agent-based negotiations via effectively modeling unknown opponents. Expert Syst. Appl., 42 (2015), 2287–2304. https://doi.org/10.1016/j.eswa.2014.10.048 doi: 10.1016/j.eswa.2014.10.048
|
| [6] | R. M. Coehoorn, N. R. Jennings, Learning on opponent's preferences to make effective multi-issue negotiation trade-offs, in Proceedings of the 6th International Conference on Electronic Commerce, (2004), 59–68. https://doi.org/10.1145/1052220.1052229 |
| [7] |
R. Lin, S. Kraus, J. Wilkenfeld, J. Barry, Negotiating with bounded rational agents in environments with incomplete information using an automated agent, Artif. Intell., 172 (2008), 823–851. https://doi.org/10.1016/j.artint.2007.09.007 doi: 10.1016/j.artint.2007.09.007
|
| [8] | J. Bakker, A. Hammond, D. Bloembergen, T. Baarslag, Rlboa: A modular reinforcement learning framework for autonomous negotiating agents, in Proceedings of the 18th international conference on Autonomous Agents and Multiagent Systems, (2019), 260–268. |
| [9] | H. C. H. Chang, Multi-issue bargaining with deep reinforcement learning, preprint, arXiv: 2002.07788. |
| [10] | C. Jonker, R. Aydogan, T. Baarslag, K. Fujita, T. Ito, K. Hindriks, Automated negotiating agents competition (anac), in Proceedings of the AAAI Conference on Artificial Intelligence, (2017). |
| [11] | A. Sengupta, Y. Mohammad, S. Nakadai, An autonomous negotiating agent framework with reinforcement learning based strategies and adaptive strategy switching mechanism, preprint, arXiv: 2102.03588. |
| [12] | H. He, D. Chen, A. Balakrishnan, P. Liang, Decoupling strategy and generation in negotiation dialogues, in Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, (2018), 2333–2343. |
| [13] | R. Joshi, V. Balachandran, S. Vashishth, A. Black, Y. Tsvetkov, Dialograph: Incorporating interpretable strategy-graph networks into negotiation dialogues, preprint, arXiv: 2106.00920. |
| [14] |
S. Chen, Y. Yang, R. Su, Deep reinforcement learning with emergent communication for coalitional negotiation games, Math. Biosci. Eng., 19 (2022), 4592–4609. https://doi.org/10.3934/mbe.2022212 doi: 10.3934/mbe.2022212
|
| [15] | Y. Zhou, H. He, A. W. Black, Y. Tsvetkov, A dynamic strategy coach for effective negotiation, in Proceedings of the 20th Annual SIGdial Meeting on Discourse and Dialogue, (2019), 367–378. https://doi.org/10.18653/v1/W19-5943 |
| [16] | R. Aydoğan, D. Festen, K. V. Hindriks, C. M. Jonker, Alternating offers protocols for multilateral negotiation, in Modern Approaches to Agent-Based Complex Automated Negotiation, Springer, (2017), 153–167. https://doi.org/10.1007/978-3-319-51563-2_10 |
| [17] |
A. Rubinstein, Perfect equilibrium in a bargaining model, Econometric Soc., 50 (1982), 97–109. https://doi.org/10.2307/1912531 doi: 10.2307/1912531
|
| [18] |
S. Chen, G. Weiss, An intelligent agent for bilateral negotiation with unknown opponents in continuous-time domains, ACM Trans. Auton. Adapt. Sys., 9 (2014), 1–24. https://doi.org/10.1145/2629577 doi: 10.1145/2629577
|
| [19] | S. Chen, H. B. Ammar, K. Tuyls, G. Weiss, Using conditional restricted Boltzmann machine for highly competitive negotiation tasks, in Proceedings of the 23th International Joint Conference on Artificial Intelligence, (2013), 69–75. |
| [20] |
Q. Jin, H. Cui, C. Sun, Z. Meng, R. Su, Free-form tumor synthesis in computed tomography images via richer generative adversarial network, Knowl.-Based Syst., 218 (2021), 106753. https://doi.org/10.1016/j.knosys.2021.106753 doi: 10.1016/j.knosys.2021.106753
|
| [21] |
J. Liu, R. Su, J. Zhang, L. Wei, Classification and gene selection of triple-negative breast cancer subtype embedding gene connectivity matrix in deep neural network, Brief. Bioinf., 22, (2021). https://doi.org/10.1093/bib/bbaa395 doi: 10.1093/bib/bbaa395
|
| [22] |
Q. Jin, Z. Meng, T. D. Pham, Q. Chen, L. Wei, R. Su, DUNet: A deformable network for retinal vessel segmentation, Knowl.-Based Syst., 178, (2019), 149–162. https://doi.org/10.1016/j.knosys.2019.04.025 doi: 10.1016/j.knosys.2019.04.025
|
| [23] |
R. Su, X. Liu, L. Wei, Q. Zou, Deep-Resp-Forest: A deep forest model to predict anti-cancer drug response, Methods, 166 (2019), 91–102. https://doi.org/10.1016/j.ymeth.2019.02.009 doi: 10.1016/j.ymeth.2019.02.009
|
| [24] | T. P. Lillicrap, J. J. Hunt, A. Pritzel, N. Heess, T. Erez, Y. Tassa, et al., Continuous control with deep reinforcement learning, preprint, arXiv: 1509.02971. |
| [25] | T. Haarnoja, A. Zhou, P. Abbeel, S. Levine, Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor, in International Conference on Machine Learning, (2018), 1861–1870. |
| [26] | J. Mell, G. M. Lucas, J. Gratch, An effective conversation tactic for creating value over repeated negotiations., in AAMAS, 15, (2015), 1567–1576. |
| [27] | K. Cao, A. Lazaridou, M. Lanctot, J. Z. Leibo, K. Tuyls, S. Clark, Emergent communication through negotiation, in 6th International Conference on Learning Representations, (2018). |
| [28] | J. Xiong, Q. Wang, Z. Yang, P. Sun, L. Han, Y. Zheng, et al., Parametrized deep q-networks learning: Reinforcement learning with discrete-continuous hybrid action space, preprint, arXiv: 1810.06394. |
| [29] |
T. Baarslag, K. Fujita, E. H. Gerding, K. Hindriks, T. Ito, N. R. Jennings, et al., Evaluating practical negotiating agents: Results and analysis of the 2011 international competition, Artif. Intell., 198 (2013), 73–103. https://doi.org/10.1016/j.artint.2012.09.004 doi: 10.1016/j.artint.2012.09.004
|
| [30] | S. Chen, H. B. Ammar, K. Tuyls, G. Weiss, Optimizing complex automated negotiation using sparse pseudo-input gaussian processes, in Proceedings of the 2013 International Conference on Autonomous Agents and Multi-agent Systems, (2013), 707–714. |
| [31] |
L. Ilany, Y. Gal, Algorithm selection in bilateral negotiation, Auton. Agents Multi-Agent Syst., 30 (2016), 697–723. https://doi.org/10.1007/s10458-015-9302-8 doi: 10.1007/s10458-015-9302-8
|
| [32] |
P. Faratin, C. Sierra, N. R. Jennings, Negotiation decision functions for autonomous agents, Robot. Auton. Syst., 24 (1998), 159–182. https://doi.org/10.1016/S0921-8890(98)00029-3 doi: 10.1016/S0921-8890(98)00029-3
|
| [33] | R. S. Sutton, A. G. Barto, Reinforcement Learning: An Introduction, MIT press, 2018. |
| [34] | M. A. Wiering, M. Van Otterlo, Reinforcement learning, in Adaptation, Learning, and Optimization, (2012). |
| [35] | C. Szepesvári, Algorithms for reinforcement learning, in Synthesis Lectures on Artificial Intelligence and Machine Learning, 4 (2010), 1–103. https://doi.org/10.2200/S00268ED1V01Y201005AIM009 |
| [36] |
B. Song, F. Li, Y. Liu, X. Zeng, Deep learning methods for biomedical named entity recognition: a survey and qualitative comparison, Brief. Bioinf., 22 (2021). https://doi.org/10.1093/bib/bbab282 doi: 10.1093/bib/bbab282
|
| [37] |
A. Lin, W. Kong, S. Wang, Identifying genetic related neuroimaging biomarkers of Alzheimer's disease via diagnosis-guided group sparse multitask learning method, Curr. Bioinf., 16 (2021), 1–1. https://doi.org/10.2174/157489361601210301105859 doi: 10.2174/157489361601210301105859
|
| [38] | J. Dong, M. Zhao, Y. Liu, Y. Su, X. Zeng, Deep learning in retrosynthesis planning: Datasets, models and tools, Brief. Bioinf., 23 (2022), Bbab391. |
| [39] | V. Mnih, K. Kavukcuoglu, D. Silver, A. Graves, I. Antonoglou, D. Wierstraey at al., Playing Atari with deep reinforcement learning, preprint, arXiv: 1312.5602. |
| [40] |
V. Mnih, K. Kavukcuoglu, D. Silver, A. A. Rusu, J. Veness, M. G. Bellemare, et al., Human-level control through deep reinforcement learning, Nature, 518 (2015), 529–533. https://doi.org/10.1038/nature14236 doi: 10.1038/nature14236
|
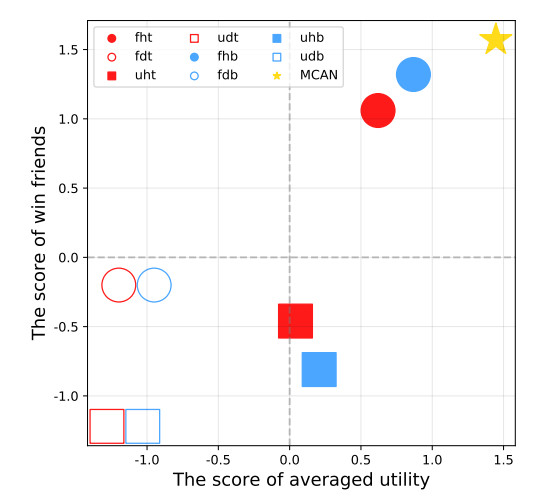
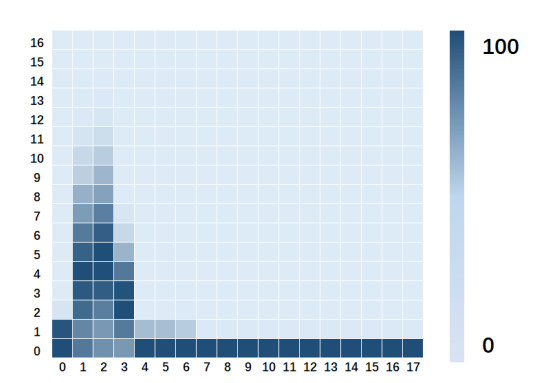
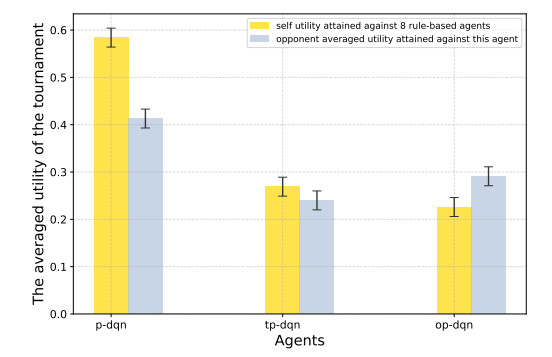
Figures(7) / Tables(2)

Siqi Chen, Ran Su. An autonomous agent for negotiation with multiple communication channels using parametrized deep Q-network[J]. Mathematical Biosciences and Engineering, 2022, 19(8): 7933-7951. doi: 10.3934/mbe.2022371







 DownLoad:
DownLoad: