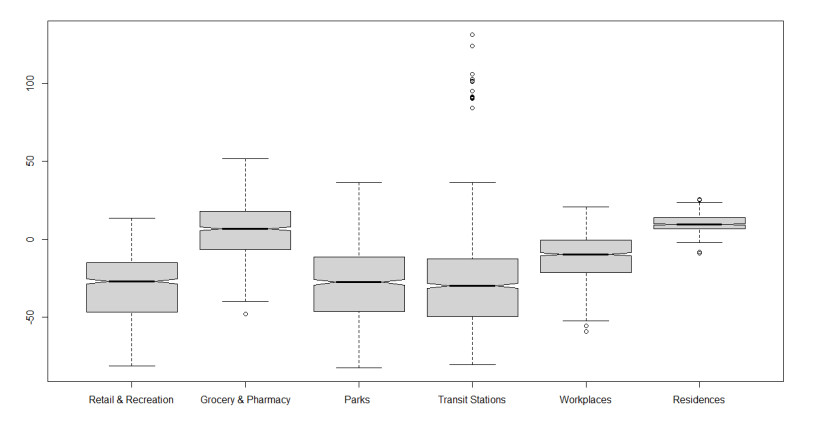
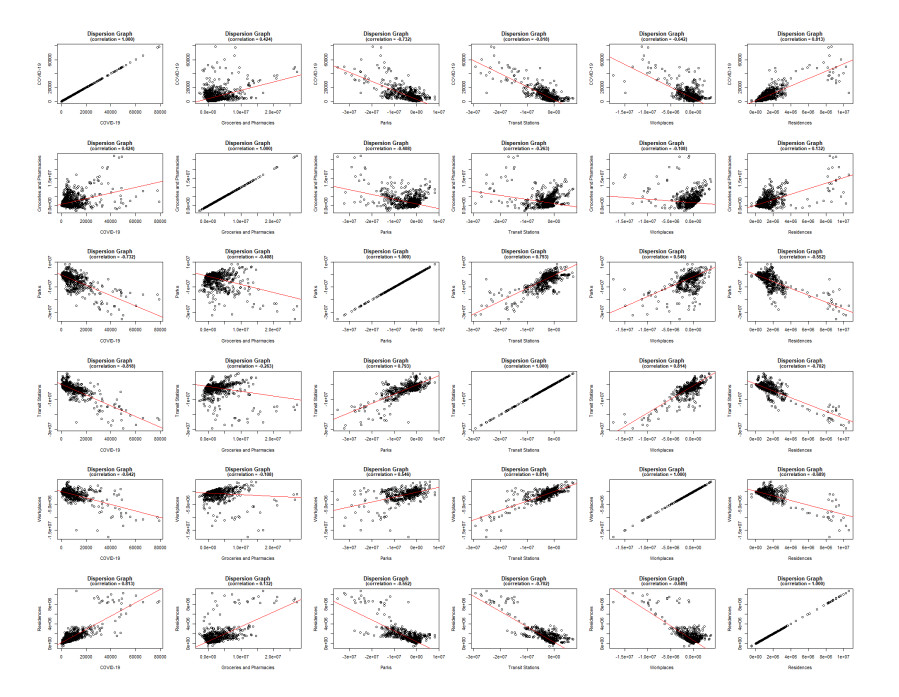
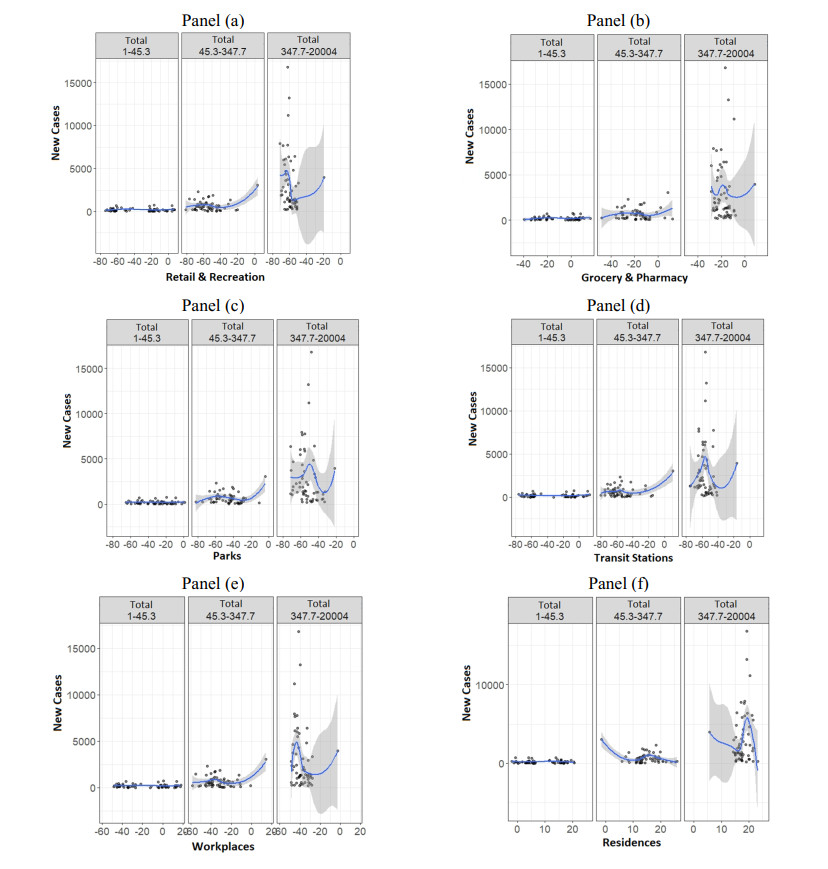
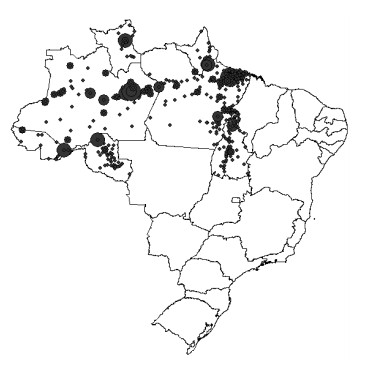
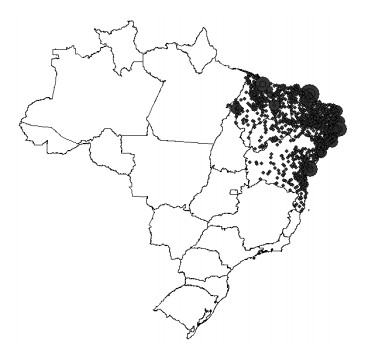
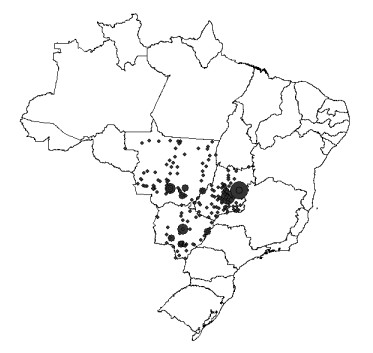
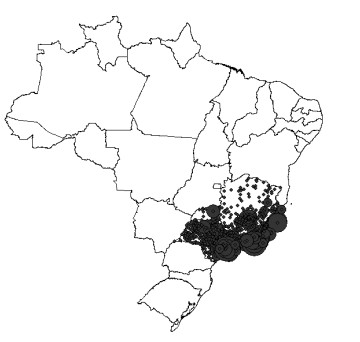
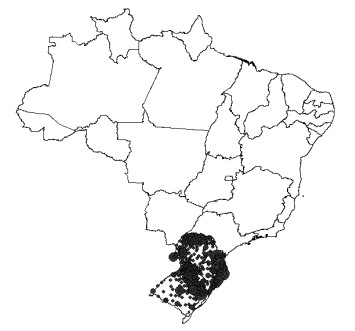
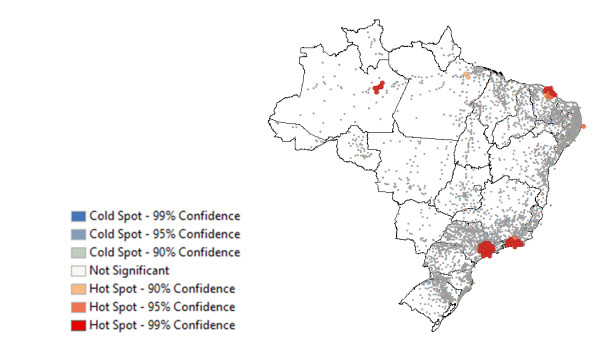
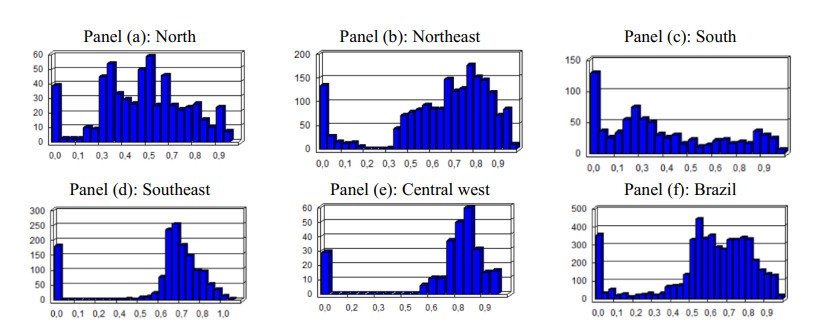
This assessment aims at measuring the impact of different location mobility on the COVID-19 pandemic. Data over time and over the 27 Brazilian federations in 5 regions provided by Google's COVID-19 community mobility reports and classified by place categories (retail and recreation, grocery and pharmacy, parks, transit stations, workplaces, and residences) are autoregressed on the COVID-19 incidence in Brazil using generalized linear regressions to measure the aggregate dynamic impact of mobility on each socioeconomic category. The work provides a novel multicriteria approach for selecting the most appropriate estimation model in the context of this application. Estimations for the time gap between contagion and data disclosure for public authorities' decision-making, estimations regarding the propagation rate, and the marginal mobility contribution for each place category are also provided. We report the pandemic evolution on the dimensions of cases and a geostatistical analysis evaluating the most critical cities in Brazil based on optimized hotspots with a brief discussion on the effects of population density and the carnival.
Citation: Thyago Celso C. Nepomuceno, Thalles Vitelli Garcez, Lúcio Camara e Silva, Artur Paiva Coutinho. Measuring the mobility impact on the COVID-19 pandemic[J]. Mathematical Biosciences and Engineering, 2022, 19(7): 7032-7054. doi: 10.3934/mbe.2022332
This assessment aims at measuring the impact of different location mobility on the COVID-19 pandemic. Data over time and over the 27 Brazilian federations in 5 regions provided by Google's COVID-19 community mobility reports and classified by place categories (retail and recreation, grocery and pharmacy, parks, transit stations, workplaces, and residences) are autoregressed on the COVID-19 incidence in Brazil using generalized linear regressions to measure the aggregate dynamic impact of mobility on each socioeconomic category. The work provides a novel multicriteria approach for selecting the most appropriate estimation model in the context of this application. Estimations for the time gap between contagion and data disclosure for public authorities' decision-making, estimations regarding the propagation rate, and the marginal mobility contribution for each place category are also provided. We report the pandemic evolution on the dimensions of cases and a geostatistical analysis evaluating the most critical cities in Brazil based on optimized hotspots with a brief discussion on the effects of population density and the carnival.

| [1] |
G. Caggiano, E. Castelnuovo, R. Kima, The global effects of COVID-19-induced uncertainty, Econ. Lett., 194 (2020), 109392. https://doi.org/10.1016/j.econlet.2020.109392 doi: 10.1016/j.econlet.2020.109392

|
| [2] |
J. Sun, Z. Shi, H. Xu, Non-pharmaceutical interventions used for COVID-19 had a major impact on reducing influenza in China in 2020, J. Travel Med., 27 (2020), taaa064. https://doi.org/10.1093/jtm/taaa064 doi: 10.1093/jtm/taaa064
|
| [3] | C. M. Herren, T. K. Brownwright, E. Y. Liu, N. E. Amiri, M. Majumder, Democracy and mobility: a preliminary analysis of global adherence to non-pharmaceutical interventions for COVID-19, Soc. Sci. Res. Network, 2020 (2020). https://doi.org/10.2139/ssrn.3570206 |
| [4] |
K. Leung, J. T. Wu, D. Liu, G. M. Leung, First-wave COVID-19 transmissibility and severity in China outside Hubei after control measures, and second-wave scenario planning: a modelling impact assessment, Lancet, 395 (2020), 1382–1393. https://doi.org/10.1016/S0140-6736(20)30746-7 doi: 10.1016/S0140-6736(20)30746-7
|
| [5] | T. C. C. Nepomuceno, W. M. N. Silva, K. T. C. Nepomuceno, I. K. F. Barros, A DEA-based complexity of needs approach for hospital beds evacuation during the COVID-19 outbreak, J. Healthcare Eng., 2020 (2020). https://doi.org/10.1155/2020/8857553 |
| [6] |
T. C. C. Nepomuceno, W. M. N. Silva, S. D. F. Gomes, T. F. O. Rodriguez, Comparative network efficiency analysis of Brazil response to COVID-19 at state level, Value Health, 24 (2021), S175. https://doi.org/10.1016/j.jval.2021.04.868 doi: 10.1016/j.jval.2021.04.868
|
| [7] | N. Ajzenman, T. Cavalcanti, D. da Mata, More than words: leaders' speech and risky behavior during a pandemic, preprint. https://dx.doi.org/10.2139/ssrn.3582908 |
| [8] |
M. B. Neiva, I. Carvalho, E. D. S. Costa, F. Barbosa-Junior, F. A. Bernardi, T. L. M. Sanches, et al., Brazil: the emerging epicenter of COVID-19 pandemic, Rev. Soc. Bras. Med. Trop., 53 (2020). https://doi.org/10.1590/0037-8682-0550-2020 doi: 10.1590/0037-8682-0550-2020
|
| [9] |
H. Xu, C. Yan, Q. Fu, K. Xiao, Y. Yu, D. Han, et al., Possible environmental effects on the spread of COVID-19 in China, Sci. Total Environ., 731 (2020), 139211. https://doi.org/10.1016/j.scitotenv.2020.139211 doi: 10.1016/j.scitotenv.2020.139211
|
| [10] |
P. Byass, Eco-epidemiological assessment of the COVID-19 epidemic in China, January–February 2020, Global Health Action, 13 (2020), 1760490. https://doi.org/10.1080/16549716.2020.1760490 doi: 10.1080/16549716.2020.1760490
|
| [11] |
M. Ujiie, S. Tsuzuki, N. Ohmagari, Effect of temperature on the infectivity of COVID-19, Int. J. Infect. Dis., 95 (2020), 301–303. https://doi.org/10.1016/j.ijid.2020.04.068 doi: 10.1016/j.ijid.2020.04.068
|
| [12] |
Y. Jiang, X. J. Wu, Y. J. Guan, Effect of ambient air pollutants and meteorological variables on COVID-19 incidence, Infect. Control Hosp. Epidemiol., 41 (2020), 1011–1015. https://doi.org/10.1017/ice.2020.222 doi: 10.1017/ice.2020.222
|
| [13] |
A. Altamimi, A. E. Ahmed, Climate factors and incidence of Middle East respiratory syndrome coronavirus, J. Infect. Public Health, 13 (2019), 704–708. https://doi.org/10.1016/j.jiph.2019.11.011. doi: 10.1016/j.jiph.2019.11.011
|
| [14] |
X. Zhang, R. Ma, L. Wang, Predicting turning point, duration and attack rate of COVID-19 outbreaks in major western countries, Chaos Solitons Fractals, 135 (2020), 109829. https://doi.org/10.1016/j.chaos.2020.109829 doi: 10.1016/j.chaos.2020.109829
|
| [15] |
A. Agosto, P. Giudici, A poisson autoregressive model to underaimstand COVID-19 contagion dynamics, Risks, 8 (2020), 77. https://doi.org/10.3390/risks8030077 doi: 10.3390/risks8030077
|
| [16] |
A. Agosto, P. Giudici, COVID-19 contagion and digital finance, Digital Finance, 2 (2020), 159–167. https://doi.org/10.1007/s42521-020-00021-3 doi: 10.1007/s42521-020-00021-3
|
| [17] | Google LLC, Google COVID-19 Community Mobility Reports. Available from: https://www.google.com/covid19/mobility/. |
| [18] | W. Cota, Monitoring the number of COVID-19 cases and deaths in brazil at municipal and federative units level, preprint. https://orcid.org/0000-0002-8582-1531 |
| [19] |
H. Akaike, A new look at the statistical model identification, IEEE Trans. Autom. Control, 19 (1974), 716–723. https://doi.org/10.1109/TAC.1974.1100705 doi: 10.1109/TAC.1974.1100705
|
| [20] |
T. C. C. Nepomuceno, J. A. de Moura, L. C. e Silva, A. P. C. S. Costa, Alcohol and violent behavior among football spectators: An empirical assessment of Brazilian's criminalization, Int. J. Law, Crime Justice, 51 (2017), 34–44. https://doi.org/10.1016/j.ijlcj.2017.05.001 doi: 10.1016/j.ijlcj.2017.05.001
|
| [21] |
R. S. Halinski, L. S. Feldt, The selection of variables in multiple regression analysis, J. Educ. Meas., 7 (1970), 151–157. https://doi.org/10.1111/j.1745-3984.1970.tb00709.x doi: 10.1111/j.1745-3984.1970.tb00709.x
|
| [22] |
F. A. van Eeuwijk, Multiplicative interaction in generalized linear models, Biometrics, 51 (1995), 1017–1032. https://doi.org/10.2307/2533001 doi: 10.2307/2533001
|
| [23] |
J. P. Brans, P. Vincke, A preference ranking organization method, Manage. Sci., 31 (1985), 647–656. https://doi.org/10.1287/mnsc.31.6.647 doi: 10.1287/mnsc.31.6.647
|
| [24] |
F. H. Barron, B. E. Barrett, Decision quality using ranked attribute weights, Manag. Sci., 42 (1996), 1515–1523. https://doi.org/10.1287/mnsc.42.11.1515 doi: 10.1287/mnsc.42.11.1515
|
| [25] | M. Danielson, L. Ekenberg, Trade-offs for ordinal ranking methods in multicriteria decisions, in International Conference on Group Decision and Negotiation, (2016), 16–27. https://doi.org/10.1007/978-3-319-52624-9_2 |
| [26] |
A. T. de Almeida Filho, T. R. N. Clemente, M. D. Costa, A. T. Almeida, Preference modeling experiments with surrogate weighting procedures for the PROMETHEE method, Eur. J. Oper. Res., 264 (2018), 453–461. https://doi.org/10.1016/j.ejor.2017.08.006 doi: 10.1016/j.ejor.2017.08.006
|
| [27] |
F. H. Barron, Selecting a best multi-attribute alternative with partial information about attribute weights, Acta Psychol., 80 (1992), 91–103. https://doi.org/10.1016/0001-6918(92)90042-C doi: 10.1016/0001-6918(92)90042-C
|
| [28] | T. S. Breusch, A. R. Pagan, A simple test for heteroscedasticity and random coefficient variation, Econometrica J. Econometric Soc., (1979), 1287–1294. https://doi.org/10.2307/1911963 |
| [29] |
T. C. C. Nepomuceno, A. P. C. S.Costa, Spatial visualization on patterns of disaggregate robberies, Oper. Res. Int. J., 19 (2019), 857–886. https://doi.org/10.1007/s12351-019-00479-z doi: 10.1007/s12351-019-00479-z
|
| [30] | D. A. Belsley, E. Kuh, R. E. Welsch, Regression Diagnostics: Identifying Influential Data and Sources of Collinearity, John Wiley & Sons, New York, 1980. |
| [31] |
A. Getis, J. K. Ord, The analysis of spatial association by use of distance statistics, Geogr. Anal., 24 (1992), 189–206. https://doi.org/10.1111/j.1538-4632.1992.tb00261.x doi: 10.1111/j.1538-4632.1992.tb00261.x
|
| [32] |
T. Menezes, R. Silveira-Neto, C. Monteiro, J. L. Ratton, Spatial correlation between homicide rates and inequality: evidence from urban neighborhoods, Econ. Lett., 120 (2013), 97–99. https://doi.org/10.1016/j.econlet.2013.03.040. doi: 10.1016/j.econlet.2013.03.040
|
| [33] |
Y. Benjamini, Y. Hochberg, Controlling the false discovery rate: a practical and powerful approach to multiple testing, J. R. Stat. Soc. B, 57 (1995), 289–300. https://doi.org/10.1111/j.2517-6161.1995.tb02031.x doi: 10.1111/j.2517-6161.1995.tb02031.x
|
| [34] | T. C. C. Nepomuceno, A. P. C. Costa, Resource allocation with time series DEA applied to Brazilian federal saving banks, Econ. Bull., 39 (2019), 1384–1392. |
| [35] | T. C. C. Nepomuceno, V. D. H. De Carvalho, A. P. C. S. Costa, Time-series directional efficiency for knowledge benchmarking in service organizations, iin World Conference on Information Systems and Technologies, 2020. https://doi.org/10.1007/978-3-030-45688-7_34 |
| [36] |
T. C. C. Nepomuceno, V. D. H. de Carvalho, K. T. C. Nepomuceno, A. P. C. S. Costa, Exploring knowledge benchmarking using time‐series directional distance functions and bibliometrics, Exp. Syst., 2022 (2022), e12967. https://doi.org/10.1111/exsy.12967 doi: 10.1111/exsy.12967
|
| [37] |
M. Fiori, G. Bello, N. Wschebor, F. Lecumberry, A. Ferragut, E. Mordecki, Decoupling between SARS-CoV-2 transmissibility and population mobility associated with increasing immunity from vaccination and infection in south America, Sci. Rep., 12 (2022), 1–9. https://doi.org/10.1038/s41598-022-10896-4 doi: 10.1038/s41598-022-10896-4
|
| [38] | B. R. G. M. Couto, J. J. da Cunha Junior, C. D. M. Oliveira, H. D. D. de Carvalho, Rhayssa F. A. Rocha, A. L. Alvim, et al., Mobility restrictions for the control of COVID-19 epidemic, preprints. https://doi.org/10.1590/SciELOPreprints.717 |
| [39] |
P. J. Puccinelli, T. S. da Costa, A. Seffrin, C. A. B. de Lira, R. L. Vancini, P. T. Nikolaidis, et al., Correction to: reduced level of physical activity during COVID-19 pandemic is associated with depression and anxiety levels: an internet-based survey, BMC Public Health, 21 (2021), 1–11. https://doi.org/10.1186/s12889-021-10684-1 doi: 10.1186/s12889-021-10684-1
|
| [40] |
P. J. Pérez-Martínez, J. A. Dunck, J. V. de Assunção, P. Connerton, A. D. Slovic, H. Ribeiro, et al., Long-term commuting times and air quality relationship to COVID-19 in São Paulo, J. Transp. Geogr., 2022 (2022), 103349. https://doi.org/10.1016/j.jtrangeo.2022.103349 doi: 10.1016/j.jtrangeo.2022.103349
|
| [41] |
A. P. Rudke, D. S. de Almeida, R. A. Alves, A. Beal, L. D. Martins, J. A. Martins, et al., Impacts of strategic mobility restrictions policies during 2020 COVID-19 outbreak on Brazil's regional air quality, Aerosol Air Qual. Res., 22 (2022), 210351. https://doi.org/10.4209/aaqr.210351 doi: 10.4209/aaqr.210351
|
| [42] |
C. S. Costa, C. S. Pitombo, F. L. U. D. Souza, Travel behavior before and during the COVID-19 pandemic in Brazil: mobility changes and transport policies for a sustainable transportation system in the post-pandemic period, Sustainability, 14 (2022), 4573. https://doi.org/10.3390/su14084573 doi: 10.3390/su14084573
|
| [43] |
L. Ferrante, L. H. Duczmal, E. Capanema, W. A. C. Steinmetz, A. C. L. Almeida, J. Leão, et al., Dynamics of COVID-19 in Amazonia: a history of government denialism and the risk of a third wave, Prev. Med. Rep., 26 (2022), 101752. https://doi.org/10.1016/j.pmedr.2022.101752 doi: 10.1016/j.pmedr.2022.101752
|
| [44] |
S. Ibarra-Espinosa, E. D. de Freitas, K. Ropkins, F. Dominici, A. Rehbein, Negative-binomial and quasi-poisson regressions between COVID-19, mobility and environment in São Paulo, Brazil, Environ. Res., 204 (2022), 112369. https://doi.org/10.1016/j.envres.2021.112369 doi: 10.1016/j.envres.2021.112369
|
| [45] |
M. P. F. de Góis, L. Parente-Ribeiro, P. C. D. C. Gomes, R. A. A. Gomes, T. M. Leite, L. Iorio, et al., Scenarios of social isolation during the first wave of the COVID‐19 pandemic in Rio de Janeiro, Brazil, Geogr. Res., 60 (2022), 29–39. https://doi.org/10.1111/1745-5871.12508 doi: 10.1111/1745-5871.12508
|
| [46] |
S. Banerjee, Y. Lian, Data driven covid-19 spread prediction based on mobility and mask mandate information, Appl. Intell., 52 (2022), 1969–1978. https://doi.org/10.1007/s10489-021-02381-8 doi: 10.1007/s10489-021-02381-8
|
| [47] |
J. Bullock, A. P. Pellegrino, How do COVID-19 stay-at-home restrictions affect crime? Evidence from Rio de Janeiro, Brazil, EconomiA, 22 (2021), 147–163. https://doi.org/10.1016/j.econ.2021.11.002 doi: 10.1016/j.econ.2021.11.002
|
| [48] |
E. T. C. Chagas, P. H. Barros, I. Cardoso-Pereira, I. V. Ponte, P. Ximenes, F. Figueiredo, et al., Effects of population mobility on the COVID-19 spread in Brazil, PloS one, 16 (2021), e0260610. https://doi.org/10.1371/journal.pone.0260610 doi: 10.1371/journal.pone.0260610
|
| [49] |
P. F. Testa, R. Snyder, E. Rios, E. Moncada, A. Giraudy, C. Bennouna, Who stays at home? The politics of social distancing in Brazil, Mexico, and the United States during the COVID-19 pandemic, J. Health Politics Policy Law, 46 (2021), 929–958. https://doi.org/10.1215/03616878-9349100 doi: 10.1215/03616878-9349100
|
| [50] |
M. Cai, C. Guy, M. Héroux, E. Lichtfouse, C. An, The impact of successive COVID-19 lockdowns on people mobility, lockdown efficiency, and municipal solid waste, Environ. Chem. Lett., 19(2021), 3959–3965. https://doi.org/10.1007/s10311-021-01290-z doi: 10.1007/s10311-021-01290-z
|
| [51] |
P. Nouvellet, S. Bhatia, A. Cori, K. E. C. Ainslie, M. Baguelin, S. Bhatt, et al., Reduction in mobility and COVID-19 transmission, Nat. Commun., 12 (2021). https://doi.org/10.1038/s41467-021-21358-2 doi: 10.1038/s41467-021-21358-2
|
| [52] | N. Ayan, A. Ramesh, A. Seetharam, A. A. de A. Rocha, Hierarchical models for detecting mobility clusters during COVID-19, in Proceedings of the 19th ACM International Symposium on Mobility Management and Wireless Access, 2021. https://doi.org/10.1145/3479241.3486690 |
| [53] |
T. T. da Silva, R. Francisquini, M. C. V. Nascimento, Meteorological and human mobility data on predicting COVID-19 cases by a novel hybrid decomposition method with anomaly detection analysis: a case study in the capitals of Brazil, Exp. Syst. Appl., 182 (2021), 115190. https://doi.org/10.1016/j.eswa.2021.115190 doi: 10.1016/j.eswa.2021.115190
|
| [54] |
J. L. Kephart, X. Delclòs-Alió, D. A. Rodríguez, O. L. Sarmiento, T. Barrientos-Gutiérrez, M. Ramirez-Zea, et al., The effect of population mobility on COVID-19 incidence in 314 Latin American cities: a longitudinal ecological study with mobile phone location data, Lancet Digital Health, 3 (2021), e716–e722. https://doi.org/10.1016/S2589-7500(21)00174-6 doi: 10.1016/S2589-7500(21)00174-6
|
| [55] |
D. P. Aragão, D. H. dos Santos, A. Mondini, L. M. G. Gonçalves, National holidays and social mobility behaviors: alternatives for forecasting COVID-19 deaths in Brazil, Int. J. Environ. Res. Public Health, 18 (2021), 11595. https://doi.org/10.3390/ijerph182111595 doi: 10.3390/ijerph182111595
|
 mbe-19-07-332 supplementary.pdf mbe-19-07-332 supplementary.pdf |
 |
Figures(10) / Tables(13)

Thyago Celso C. Nepomuceno, Thalles Vitelli Garcez, Lúcio Camara e Silva, Artur Paiva Coutinho. Measuring the mobility impact on the COVID-19 pandemic[J]. Mathematical Biosciences and Engineering, 2022, 19(7): 7032-7054. doi: 10.3934/mbe.2022332







 DownLoad:
DownLoad: