Generalized additive models provide a flexible and easily-interpretable method for uncovering a nonlinear relationship between response and covariates. In many situations, the effect of a continuous covariate on the response varies across groups defined by the levels of a categorical variable. When confronted with a considerable number of groups defined by the levels of the categorical variable and a factor‐by‐curve interaction is detected in the model, it then becomes important to compare these regression curves. When the null hypothesis of equality of curves is rejected, leading to the clear conclusion that at least one curve is different, we may assume that individuals can be grouped into a number of classes whose members all share the same regression function. We propose a method that allows determining such groups with an automatic selection of their number by means of bootstrapping. The validity and behavior of the proposed method were evaluated through simulation studies. The applicability of the proposed method is illustrated using real data from an experimental study in neurology.
Citation: Javier Roca-Pardiñas, Celestino Ordóñez, Luís Meira Machado. A method for determining groups in nonparametric regression curves: Application to prefrontal cortex neural activity analysis[J]. Mathematical Biosciences and Engineering, 2022, 19(7): 6435-6454. doi: 10.3934/mbe.2022302
Generalized additive models provide a flexible and easily-interpretable method for uncovering a nonlinear relationship between response and covariates. In many situations, the effect of a continuous covariate on the response varies across groups defined by the levels of a categorical variable. When confronted with a considerable number of groups defined by the levels of the categorical variable and a factor‐by‐curve interaction is detected in the model, it then becomes important to compare these regression curves. When the null hypothesis of equality of curves is rejected, leading to the clear conclusion that at least one curve is different, we may assume that individuals can be grouped into a number of classes whose members all share the same regression function. We propose a method that allows determining such groups with an automatic selection of their number by means of bootstrapping. The validity and behavior of the proposed method were evaluated through simulation studies. The applicability of the proposed method is illustrated using real data from an experimental study in neurology.

| [1] | P. McCullagh, J. Nelder, Generalized Linear Models, 2nd edition, Chapman and Hall/CRC, Boca Raton, 1989. https://doi.org/10.1201/9780203753736 |
| [2] | T. J. Hastie, R. J. Tibshirani, Generalized Additive Models, Chapman & Hall/CRC, New York, 1990. |
| [3] | S. Wood, Generalized Additive Models: An Introduction with R, Chapman & Hall/CRC, 2006. https://doi.org/10.1201/9781420010404 |
| [4] |
W. González-Manteiga, R. M. Crujeiras, An updated review of Goodness-of-Fit tests for regression models, Test, 22 (2013), 361–411. https://doi.org/10.1007/s11749-013-0327-5 doi: 10.1007/s11749-013-0327-5

|
| [5] |
H. Dette, A. Munk, Testing heterocedasticity in nonparametric regression, J. R. Stat. Soc. B, 60 (1998), 693–708. https://doi.org/10.1111/1467-9868.00149 doi: 10.1111/1467-9868.00149
|
| [6] |
H. Dette, N. Neumeyer, Nonparametric analysis of covariance, Ann. Stat., 29 (2001), 1361–1400. https://doi.org/10.1214/aos/1013203458 doi: 10.1214/aos/1013203458
|
| [7] |
L. García-Escudero, A. Gordaliza, A proposal for robust curve clustering, J. Classif., 22 (2005), 185–201. https://doi.org/10.1007/s00357-005-0013-8 doi: 10.1007/s00357-005-0013-8
|
| [8] |
E. A. Nadaraya, On estimating regression, Theory Probab. Its Appl., 9 (1964), 141–142. https://doi.org/10.1137/1109020 doi: 10.1137/1109020
|
| [9] |
M. A. Delgado, Testing the equality of nonparametric regression curves, Stat. Probab. Lett., 17 (1993), 199–204. https://doi.org/10.1016/0167-7152(93)90167-H doi: 10.1016/0167-7152(93)90167-H
|
| [10] |
K. B. Kulasekera, Comparison of regression curves using quasi-residuals, J. Am. Stat. Assoc., 90 (1995), 1085–1093. https://doi.org/10.1080/01621459.1995.10476611 doi: 10.1080/01621459.1995.10476611
|
| [11] |
K. B. Kulasekera, J. Wang, Smoothing parameter selection for power optimality in testing of regression curves, J. Am. Stat. Assoc., 92 (1997), 500–511. https://doi.org/10.1080/01621459.1997.10474003 doi: 10.1080/01621459.1997.10474003
|
| [12] |
K. B. Kulasekera, J. Wang, Bandwidth selection for power optimality in a test of equality of regression curves, Stat. Probab. Lett., 37 (1998), 287–293. https://doi.org/10.1016/S0167-7152(97)84155-7 doi: 10.1016/S0167-7152(97)84155-7
|
| [13] | N. Neumeyer, H. Dette, Nonparametric comparison of regression curves: An empirical process approach, Ann. Stat., 31 (2003), 31880–31920. |
| [14] | J. C. Pardo-Fernández, I. Keilegom, W. González-Manteiga, Testing for the equality of k regression curves, Stat. Sin., 17 (2007), 1115–1137. |
| [15] |
S. G. Young, A. W. Bowman, Non-parametric analysis of covariance, Biometrics, 51 (1995), 920–931. https://doi.org/10.2307/2532993 doi: 10.2307/2532993
|
| [16] |
J. C. Pardo-Fernández, M. D. Jiménez-Gamero, A. Ghouch, A non-parametric ANOVA-type test for regression curves based on characteristic functions. Scand. J. Stat., 42 (2015), 197–213. https://doi.org/10.1111/sjos.12102 doi: 10.1111/sjos.12102
|
| [17] |
C. Park, K. Kang, Sizer analysis for the comparison of regression curves, Comput. Stat. Data. Anal., 52 (2008), 3954–3970. https://doi.org/10.1016/j.csda.2008.01.006 doi: 10.1016/j.csda.2008.01.006
|
| [18] |
C. Park, J. Hannig, K. Kang, Nonparametric comparison of multiple regression curves in scale-space, J. Comput. Graphical Stat., 23 (2014), 657–677. https://doi.org/10.1080/10618600.2013.822816 doi: 10.1080/10618600.2013.822816
|
| [19] | W. Lin, K. B. Kulasekera, Testing the equality of linear single-index models, J. Multivar. Anal., 101 (2010), 1156–1167. |
| [20] |
M. Vogt, O. Linton, Classification of non-parametric regression functions in longitudinal data models, J. R. Stat. Soc. Ser. B Stat. Methodol., 79 (2017), 5–27. https://doi.org/10.1111/rssb.12155 doi: 10.1111/rssb.12155
|
| [21] | M. Vogt, O. Linton, Multiscale clustering of nonparametric regression curves, J. Econometrics, 216 (2020), 305–325. |
| [22] |
N. M. Villanueva, M. Sestelo, L. Meira-Machado, A method for determining groups in multiple survival curves, Stat. Med., 38 (2019), 866–877. https://doi.org/10.1002/sim.8016 doi: 10.1002/sim.8016
|
| [23] | P. Hall, J. D. Hart. Bootstrap test for difference between means in nonparametric regression, J. Am. Stat. Assoc., 85 (412), 1039–1049. |
| [24] |
M. C. Rodríguez-Campos, W. González-Manteiga, R. Cao, Testing the hypothesis of a generalized linear regression model using nonparametric regression estimation, J. Stat. Plan. Infer., 67 (1998), 99–122. https://doi.org/10.1016/S0378-3758(97)00098-0 doi: 10.1016/S0378-3758(97)00098-0
|
| [25] |
J. Roca-Pardiñas, C. Cadarso-Suárez, V. Nácher, C. Acuña, Bootstrap-based methods for testing factor-by-curve interactions in Generalized Additive Models: assessing prefrontal cortex neural activity related to decision-making, Stat. Med., 25(2006), 2483–2501. https://doi.org/10.1002/sim.2415 doi: 10.1002/sim.2415
|
| [26] | C. Cadarso-Suárez, J. Roca-Pardiñas, G. Molenberghs, F. Faes, V. Nácher, S. Ojeda, et al., Flexible modelling of neuron firing rates across different experimental conditions. An application to neural activity in the prefrontal cortex during a discrimination task, J. R. Stat. Soc. Ser. C, 55 (2006), 431–447. |
| [27] |
S. Sperlich, D. Tjøstheim, L.Yang, Nonparametric estimation and testing of interaction in additive models, Econom. Theory, 18 (2002), 197–251. https://doi.org/10.1017/S0266466602182016 doi: 10.1017/S0266466602182016
|
| [28] |
L. Yang, S. Sperlich, W. Härdle, Derivative estimation and testing in generalized additive models, J. Stat. Plan. Infer., 115 (2003), 521–542. https://doi.org/10.1016/S0378-3758(02)00163-5 doi: 10.1016/S0378-3758(02)00163-5
|
| [29] | S. Dudoit, M. J. Van Der Laan, Multiple Testing Procedures with Applications to Genomics, Springer, Springer Series in Statistics, New York, 2007. |
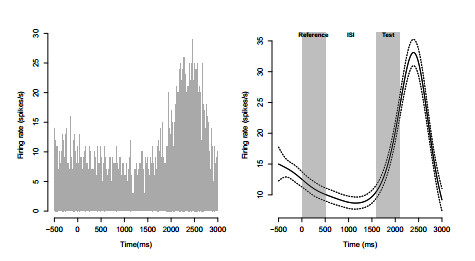
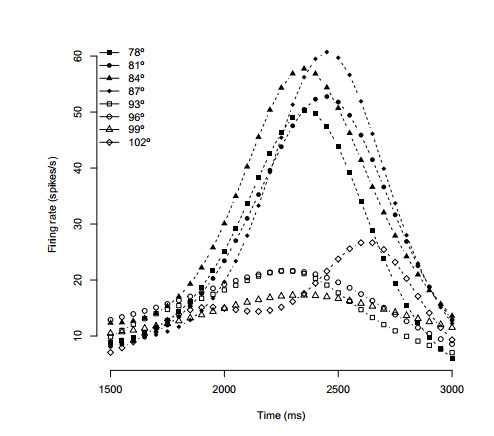
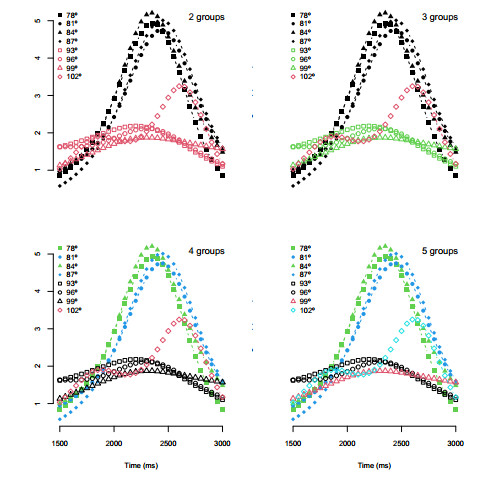
Figures(7) / Tables(7)

Javier Roca-Pardiñas, Celestino Ordóñez, Luís Meira Machado. A method for determining groups in nonparametric regression curves: Application to prefrontal cortex neural activity analysis[J]. Mathematical Biosciences and Engineering, 2022, 19(7): 6435-6454. doi: 10.3934/mbe.2022302







 DownLoad:
DownLoad: